大型语言模型 (LLM)
注释
有关更多详细信息,请参阅 “文本和图像 ”选项卡!
在生成 AI 的核心,大型语言模型(LLM)及其更紧凑的版本——小型语言模型(SLM)——封装了词汇中单词和短语之间的语言和语义关系。 模型可以使用这些关系来推理自然语言输入,并生成有意义的相关响应。
从根本上讲,LLM 经过训练,根据提示生成补全内容。 可以将它们视为许多手机上预测文本功能的极其强大的示例。 提示会启动一系列文本预测,最终生成语义正确的补全内容。 诀窍是,模型理解单词之间的关系,并且它可以识别序列中到目前为止最有可能影响下一个单词的关系:并使用它来预测序列的可能延续。
例如,请考虑以下句子:
我听到一只狗对着猫大声吠叫
现在,假设你只听到前几句话: “我听到一只狗...”。 你知道,其中一些词对于推测下一个可能出现的词来说,比其他词更有用。 你知道,“听到”和“狗”是预测后续内容的有力提示词,而这有助于你缩小可能性范围。 你知道,句子很可能会继续为“我听到一只狗叫声”。
你能够猜出下一个单词,因为:
- 你有大量的词汇可以运用。
- 你学习了常见的语言结构,所以你知道单词在有意义的句子中如何相互关联。
- 你对与单词关联的语义概念有一个理解 - 你知道你 听到 的东西必须是某种声音,你知道有一些特定的声音是由 狗制作的。
那么,如何训练模型来具备这些相同的能力?
标记化
第一步是向模型提供大量字词和短语词汇;我们这里指的是“大量”。 最新一代 LLM 的词汇由数十万个令牌组成,这些词汇基于来自 Internet 和其他来源的大量训练数据。
等一会。 令牌?
虽然我们倾向于从字词的角度理解语言,但 LLM 会将其词汇库拆解为词元。 标记包括单词,但也包括 子词(如“难以置信”和“不太可能”),标点符号和其他常用的字符序列。 因此,训练大型语言模型的第一步是将训练文本分解为其不同的标记,并为每个标记分配唯一的整数标识符,如下所示:
- 我 (1)
- 听到 (2)
- a (3)
- 狗 (4)
- 树皮 (5)
- 大声 (6)
- at (7)
- 已分配 (3)
- 猫 (8)
等等。
添加更多训练数据时,将向词汇和分配的标识符添加更多令牌;因此,你最终可能会得到像 小狗、 滑板、 汽车等单词的令牌。
注释
在此简单示例中,我们基于 单词标记了示例文本。 实际上,还会有子词、标点符号和其他标记。
使用转换器转换令牌
有了一组具有唯一 ID 的令牌后,我们需要找到一种方法来将它们相互关联。 为此,我们为每个标记分配一个 向量 (多个数值数组,如 [1, 23, 45])。 每个向量都有多个数值 元素 或 维度,我们可以使用这些元素来编码令牌的语言和语义属性,以帮助以高效格式提供有关令牌 的含义 及其与其他令牌的关系的大量信息。
我们需要根据令牌在训练数据中显示的上下文,将令牌的初始向量表示形式转换为嵌入了语言和语义特征的新向量。 由于新向量中嵌入了语义值,因此我们称之为 嵌入。
为了完成此任务,我们使用 转换器 模型。 此类模型由两个“块”组成:
- 一个 编码器 块,该块通过应用一种称为 注意的技术来创建嵌入内容。 注意力层依次检查每个令牌,并确定它如何受到周围标记的影响。 为了提高编码过程的效率,使用多头注意力对令牌的多个元素进行并行评估,并分配用于计算新向量元素值的权重。 注意力层的结果将馈送到完全连接的神经网络中,以查找嵌入的最佳矢量表示形式。
- 一个解码器层,它使用编码器计算出的嵌入项,在由提示启动的序列中确定下一个最可能出现的词元。 解码器还使用关注和前馈神经网络进行预测。
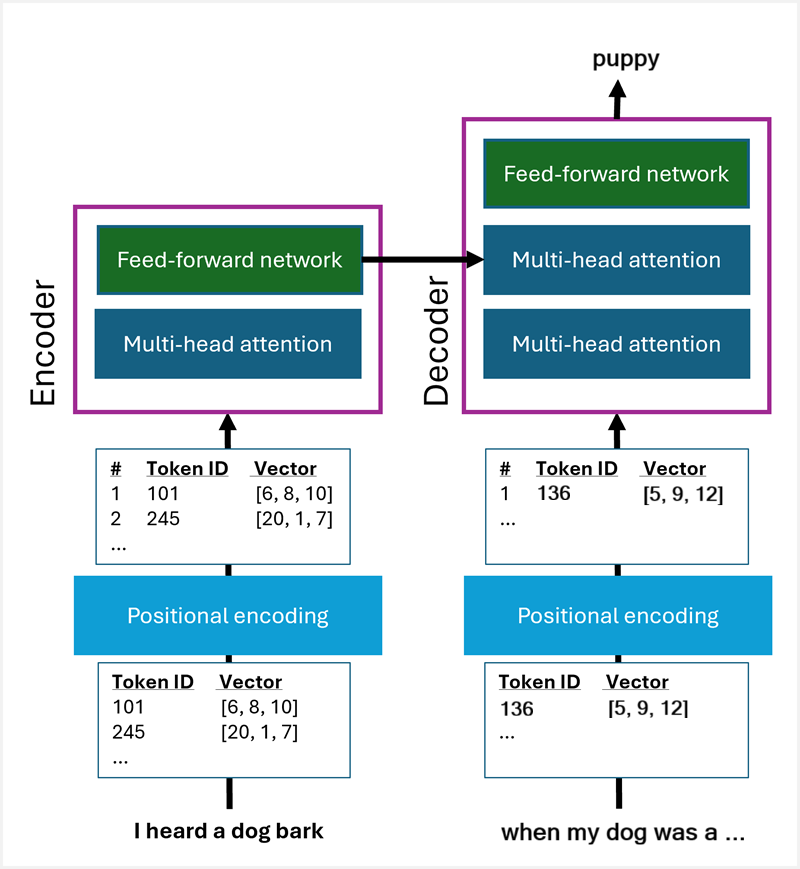
注释
我们在说明和关系图中大大简化了转换器体系结构和过程。 不要过于纠结注意力机制具体是如何运作的 - 关键在于,它有助于根据每个词元所处的语境,捕捉其语言特征和语义特征。 如果想更深入地了解 Transformer 体系结构及其对注意力机制的运用,可阅读原创论文 Attention is all you need(注意力就是你所需要的一切)。
初始矢量和位置编码
最初,token 向量值被随机分配,然后通过 Transformer 处理以创建嵌入向量。 令牌向量将馈送到转换器中,以及一个 位置编码 ,指示令牌出现在训练文本序列中的位置(我们需要执行此作,因为序列中标记出现的顺序与它们彼此的关系相关)。 例如,我们的令牌起初可能是这样的:
| 标记 | 词元 ID | Position | Vector |
|---|---|---|---|
| I | 1 | 1 | [3, 7, 10] |
| 听到 | 2 | 2 | [2, 15, 1] |
| 上午 | 3 | 3 | [9, 11, 1] |
| 狗 | 4 | 4 | [2, 7, 11] |
| 树皮 | 5 | 5 | [9, 12, 0] |
| 高声 | 6 | 6 | [3, 8, 13] |
| at | 7 | 7 | [5, 7, 10] |
| 上午 | 3 | 8 | [9, 11, 1] |
| 猫 | 8 | 9 | [8, -6, 9 ] |
| ... | ... | ... | ... |
| 小狗 | 127 | 45 | [7, 7, -2 ] |
| 汽车 | 128 | 56 | [5, -5, 1 ] |
| 滑板 | 129 | 67 | [4, 7, 14] |
注释
我们通过使用只有三个元素的向量来保持简单(这将帮助我们在三维空间中进行可视化)。 实际上,矢量有数千个元素。
注意和嵌入
若要确定包含嵌入上下文信息的令牌的向量表示形式,转换器使用 关注 层。 注意力层会依次考虑每个词元,结合该词元所处的词元序列上下文进行处理。 当前标记周围的标记经过加权以反映其影响,权重用于计算当前标记的嵌入向量的元素值。 例如,在“我听到一只狗叫”上下文中分析词元“叫”时,“听到”和“狗”这两个词元会被赋予比“我”()或“一只”更高的权重,因为对于 “叫”而言,它们是更有力的提示词。
最初,模型不“知道”哪些标记会影响他人;但是,当它向大量文本公开时,它可以迭代地了解通常出现在一起的标记,并开始查找有助于将值分配给反映令牌语言和语义特征的向量元素的模式,具体取决于令牌的邻近度和使用频率。 通过使用 多头注意力机制 来并行处理向量的不同元素,使该过程更加高效。
编码过程的结果是一组嵌入向量。这些向量携带有关词汇中的词元如何相互关联的上下文信息。 真正的转换器生成包含数千个元素的嵌入向量,为了简化,我们在示例中仅使用三个元素的向量。 词汇编码过程的结果可能如下所示:
| 标记 | 词元 ID | 嵌入 |
|---|---|---|
| I | 1 | [2, 0, -1 ] |
| 听到 | 2 | [-2, 2, 4 ] |
| 上午 | 3 | [-3, 5, 5 ] |
| 狗 | 4 | [10, 3, 2 ] |
| 树皮 | 5 | [9, 2, 10 ] |
| 高声 | 6 | [-3, 8, 3 ] |
| at | 7 | [-5, -1, 1] |
| 猫 | 8 | [10, 3, 1] |
| 小狗 | 127 | [5, 3, 2 ] |
| 汽车 | 128 | [-2, -2, 1 ] |
| 滑板 | 129 | [-3, -2, 2] |
| 树皮 | 203 | [2, -2, 3 ] |
如果你留心观察,你可能已经发现我们的结果中针对“叫”这个词元包含了两个嵌入项。 请务必了解嵌入项表示特定上下文下的某个词元;而且有些词元可能用于表示多种含义。 例如,狗的“叫”(bark) 与树的“树皮”(bark) 不同! 在多个场合中常用的词元可以生成多个嵌入。
我们可以将嵌入元素视为多维向量空间中的维度。 在我们的简单示例中,嵌入只有三个元素,因此我们可以将其可视化为三维空间中的矢量,如下所示:
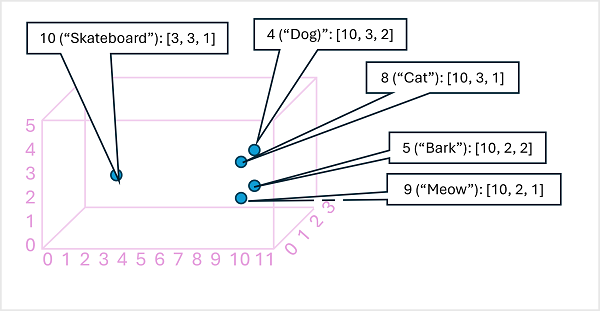
由于维度是根据令牌在语言上相互关联的方式计算的,因此在类似上下文(因此具有相似含义)中使用的标记会导致具有类似方向的向量。 例如,“狗”和“小狗”的嵌入向量或多或少指向相同的方向,这与“猫”的嵌入向量没有太大差异;但与“滑板”或“汽车”的嵌入向量有很大不同。 我们可以通过计算其矢量的 余弦相似性 ,以语义方式测量令牌彼此的接近程度。
从提示中预测完成结果
现在,我们已经有了一组嵌入项来封装词元之间的上下文关系,接下来可以使用转换器的解码器块,基于初始提示迭代预测序列中的下一个词。
再次, 注意 用于在上下文中考虑每个令牌;但这次要考虑的上下文只能包含我们尝试预测的令牌 之前的 令牌。 解码器模型采用一种名为掩码注意力的技术,使用已包含完整序列的数据进行训练;在该技术中,当前词元之后的词元会被忽略。 由于我们在训练期间已经知道下一个令牌,因此转换器可以将它与预测的令牌进行比较,并在以后的训练迭代中调整学习权重,以减少模型中的错误。
预测新的补全内容(此时下一个词元未知)时,注意力层会计算下一个词元的可能向量,而前馈网络则用于帮助确定概率最高的候选词元。 然后,将预测值添加到序列中,整个过程重复以预测 下一 个标记:等等,直到解码器预测序列已结束。
例如,鉴于序列“我的狗是...”,模型将评估序列中到目前为止的标记,使用 注意 来分配权重,并预测下一个最有可能的令牌是“小狗”,而不是说,“猫”或“滑板”。