迴歸
基於包括特徵和已知標籤的定型資料,對迴歸模型進行定型以預測數位標籤值。 定型迴歸模型 (或者實際上,任何監督式機器學習模型) 的流程涉及多次反覆運算,在多次反覆運算中,您使用適當的演算法 (通常具有一些參數化設定) 來定型模型,評估模型的預測效能,並透過使用不同的演算法和參數重複定型流程來完善模型,直至達到可接受的預測精度水準。
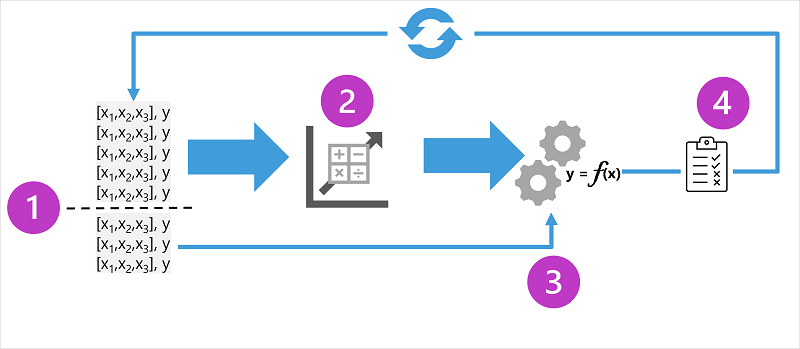
圖標顯示了監督式機器學習模型的定型流程之四個關鍵元素:
- 分割定型資料 (隨機) 以建立資料集,用於定型模型,同時保留將用於驗證定型模型的資料子集。
- 使用演算法將定型資料置入至模型中。 在迴歸模型的情况下,使用迴歸演算法,如線性迴歸。
- 使用您保留的驗證資料,透過預測特徵的標籤來測試模型。
- 將驗證資料集中已知的實際標籤與模型預測的標籤進行比較。 然後將預測和實際標籤值之間的差異進行彙總,以計算計量,其指示模型對驗證資料的預測準確度。
在每次定型、驗證和評估反覆運算之後,您可以使用不同的演算法和參數重複流程,直到取得可接受的評估計量。
範例 - 迴歸
讓我們用簡化的範例來探索迴歸,在這個範例中,我們將定型模型來預測基於單一特徵值 (x) 的數位標籤 (y)。 大多數真實案例都涉及多個特徵值,這加大了複雜性;但準則是一樣的。
對於我們的範例,讓我們繼續使用之前討論過的冰淇淋銷售案例。 對於我們的特徵,我們將考慮溫度 (假設該值是指定一天的最高溫度),我們希望定型模型來預測的標籤是當天售出的冰淇淋數量。 我們將從一些歷程資料開始,其中包括每日溫度 (x) 和冰淇淋銷售 (y) 的記錄:
 |
 |
|---|---|
| 溫度 (x) | 冰淇淋銷售量 (y) |
| 51 | 1 |
| 52 | 0 |
| 67 | 14 |
| 65 | 14 |
| 70 | 23 |
| 69 | 20 |
| 72 | 23 |
| 75 | 26 |
| 73 | 22 |
| 81 | 30 |
| 78 | 26 |
| 83 | 36 |
定型迴歸模型
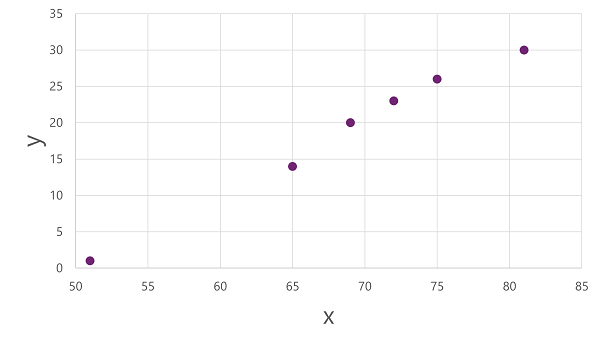
我們將從分割資料開始,並使用其中的一個子集來定型模型。 以下是定型資料集:
| 溫度 (x) | 冰淇淋銷售量 (y) |
|---|---|
| 51 | 1 |
| 65 | 14 |
| 69 | 20 |
| 72 | 23 |
| 75 | 26 |
| 81 | 30 |
為了取得這些 x 和 y 值如何相互關聯的深入解析,我們可以將它們繪製為沿兩個軸的座標,如下所示:
現在,我們準備將演算法套用至定型資料,並將其置入對 x 套用作業來計算 y 的函式。 一種這樣的演算法是線性迴歸,它透過衍生函式來運作,該函式透過 x 和 y 值的交集產生一條直線,同時最小化直線和繪製點之間的平均距離,如下所示:
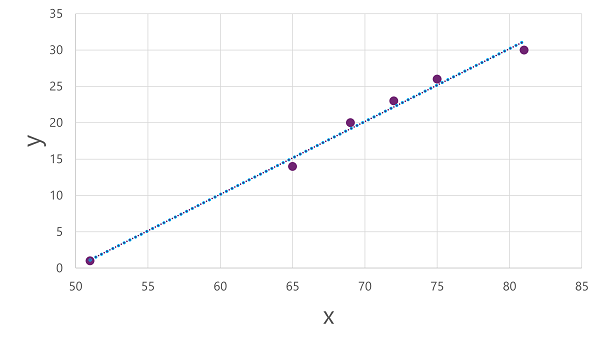
線是函式的視覺化表示,其中線的斜率説明了如何計算指定 x 值的 y 值。 線在 50 處與 x 軸相交,因此當 x 為 50 時,y 為 0。 從繪圖中的軸標記可以看出,線傾斜,因此沿 x 軸每新增 5,沿 y 軸就會新增 5;所以當 x 為 55 時,y 為 5; 當 x 為 60 時,y 為 10,依此類推。 為了計算指定 x 值的 y 值,該函式簡單地减去 50;換句話說,函式可以這樣表示:
f(x) = x-50
您可以使用此函式來預測在任何指定溫度下一天銷售的冰淇淋數量。 例如,假設天氣預報告訴我們明天將是 77 度。 我們可以套用我們的模型計算 77-50,並預測明天我們將賣出 27 個冰淇淋。
但我們的模型到底有多準確?
評估迴歸模型
為了驗證模型並評估其預測效果,我們保留了一些我們知道標籤 (y) 值的資料。 以下是我們保留的資料:
| 溫度 (x) | 冰淇淋銷售量 (y) |
|---|---|
| 52 | 0 |
| 67 | 14 |
| 70 | 23 |
| 73 | 22 |
| 78 | 26 |
| 83 | 36 |
我們可以使用模型根據特徵 (x) 值來預測此資料集中每個觀測值的標籤;然後將預測的標籤 (ŷ) 與已知的實際標籤值 (y) 進行比較。
使用我們之前定型的模型,其封裝了函式 f(x) = x-50,得到以下預測:
| 溫度 (x) | 實際銷售額 (y) | 預測的銷售 (ŷ) |
|---|---|---|
| 52 | 0 | 2 |
| 67 | 14 | 17 |
| 70 | 23 | 20 |
| 73 | 22 | 23 |
| 78 | 26 | 28 |
| 83 | 36 | 33 |
我們可以根據特徵值繪製預測標籤和實際標籤,如下所示:
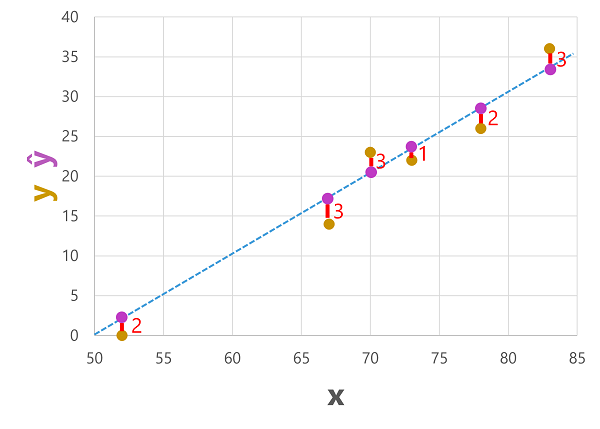
預測標籤是由模型計算的,因此它們在函式線上,但函式計算的 ŷ 值與驗證資料集的實際 y 值之間存在一些差異;它在繪圖上表示為 ŷ 和 y 值之間的一條線,顯示預測與實際值的距離。
迴歸評估計量
根據預測值和實際值之間的差異,可以計算一些用於評估迴歸模型的常用計量。
平均絕對誤差 (MAE)
此範例中的差異表示每個預測有多少冰淇淋是錯誤的。 預測是高於還是低於實際值並不重要 (例如,-3 和 +3 都表示差異為 3)。 此計量被稱為每個預測的絕對誤差,並且可以將整個驗證集摘要為平均絕對誤差 (MAE)。
在冰淇淋範例中,絕對誤差 (2、3、3、1、2 和 3) 的平均值為 2.33。
平均平方誤差 (MSE)
平均絕對誤差計量同等地考慮了預測標籤和實際標籤之間的所有差異。 然而,與誤差較大但較少產生的模型相比,可能誤差較小的模型更理想。 產生計量的方法是透過對平方誤差進行平方並計算平方值的平均值來「放大」較大的誤差。 這個計量被稱為平均平方誤差 (MSE)。
在我們的冰淇淋範例中,絕對值的平方 (分別為 4、9、9、1、4 和 9) 的平均值為 6。
均方根誤差 (RMSE)
平均平方誤差有助於將誤差的大小考慮在內,但由於它對誤差值進行了平方,因此產生的計量不再代表標籤測量的數量。 換句話說,我們可以說模型的 MSE 是 6,但這並不能用預測錯誤的冰淇淋數量來測量它的準確性;6 只是指示驗證預測中的誤差水準的數位分數。
如果我們想衡量冰淇淋數量的誤差,我們需要計算 MSE 的平方根;這會產生名為均方根誤差的計量,這不足為奇。 在這種情況下,√6,即 2.45 (冰淇淋)。
判斷的係數 (R2)
到目前為止,所有的計量都比較了預測值和實際值之間的差異,以評估模型。 然而,在現實中,模型會考慮冰淇淋日銷售額的一些自然隨機變化。 在線性迴歸模型中,定型演算法置入直線,該直線最小化函式和已知標籤值之間的平均差異。 判斷的係數 (通常稱為 R2 或 R 平方) 是測量驗證結果中可以由模型解釋的差異比例之計量,而不是驗證資料的某些異常方面 (例如,由於當地節日,冰淇淋銷售數量極不尋常的一天)。
R2 的計算比以前的計量更複雜。 它將預測標籤和實際標籤之間的平方差之和與實際標籤值和實際標籤值平均值之間的平方差值之和進行比較,如下所示:
R2 = 1- ∑(y-ŷ)2 ÷ ∑(y-ȳ)2
如果這看起來很複雜,不要太擔心;大多數機器學習工具都可以為您計算計量。 重要的一點是,結果是介於 0 和 1 之間的值,它説明了模型解釋的差異比例。 簡單地說,這個值越接近 1,模型就越適合驗證資料。 在冰淇淋迴歸模型的情况下,根據驗證資料計算的 R2 為 0.95。
反覆式定型
上述計量通常用於評估迴歸模型。 在大多數真實案例中,資料科學家將使用反覆式流程來重複定型和評估模型,具體如下:
- 特徵選取項目和準備 (選擇要包含在模型中的特徵,以及套用至這些特徵的計算,以協助確保更適合)。
- 演算法選取項目 (我們在前面的範例中探討了線性迴歸,但還有許多其他迴歸演算法)
- 演算法參數 (控制演算法行為的數位設定,更準確地稱為超參數,以將其與 x 和 y 參數區分開來)。
在多次反覆運算之後,將選取產生特定案例可接受的最佳評估計量的模型。