使用 Azure) 建置 Real-World 雲端應用程式的暫時性錯誤處理 (
作者 :Rick Anderson、 Tom Dykstra
使用 Azure 電子書建置真實世界雲端應用程式是以 Scott Guthrie 開發的簡報為基礎。 其說明 13 種模式和做法,可協助您成功開發雲端的 Web 應用程式。 如需電子書的相關信息,請參閱 第一章。
當您設計真實世界雲端應用程式時,您必須考慮的其中一件事是如何處理暫時服務中斷。 此問題在雲端應用程式中非常重要,因為您相依於網路連線和外部服務。 您經常可能會遇到一般自我修復的問題,如果您未準備好以智慧方式處理它們,他們就會對您的客戶產生不良體驗。
暫時性失敗的原因
在雲端環境中,您會發現失敗並捨棄 資料庫連結 會定期發生。 這部分是因為相較於 Web 伺服器和資料庫伺服器具有直接實體連線的內部部署環境,您將經歷更多負載平衡器。 此外,有時候,當您相依於多租用戶服務時,會看到服務的呼叫速度較慢或逾時,因為其他使用服務的人正在重載服務。 在其他情況下,您可能是太頻繁點擊服務的使用者,而服務會刻意節流您 – 拒絕連線,以防止您對服務的其他租使用者造成負面影響。
使用智慧型手機重試/倒退邏輯來減輕暫時性失敗的影響
您可以辨識通常是暫時性的錯誤,並自動重試導致錯誤的作業,而不要擲回例外狀況,而是向您的客戶顯示無法使用或錯誤頁面,因為您之前會成功。 在第二次嘗試時,作業大部分都會成功,而且您將從錯誤中復原,而不需要客戶知道發生問題。
有數種方式可以實作智慧重試邏輯。
Microsoft Patterns & Practices 群組具有暫時性錯誤處理應用程式區塊,如果您使用 ADO.NET 進行 SQL Database 存取, (不會透過 Entity Framework) 執行所有動作。 您只需要設定重試原則 – 重試查詢或命令的次數,以及在嘗試之間等候的時間 , 並使用 區塊包裝 您的 SQL 程式代碼。
public void HandleTransients() { var connStr = "some database"; var _policy = RetryPolicy.Create < SqlAzureTransientErrorDetectionStrategy( retryCount: 3, retryInterval: TimeSpan.FromSeconds(5)); using (var conn = new ReliableSqlConnection(connStr, _policy)) { // Do SQL stuff here. } }TFH 也支援 Azure In-Role 快取 和服務 總線。
當您使用 Entity Framework 時,通常不會直接使用 SQL 連線,因此您無法使用此模式和實務套件,但 Entity Framework 6 會直接在架構中建置這種重試邏輯。 以類似的方式指定重試策略,然後 EF 會在存取資料庫時使用該策略。
若要在 [修正 It] 應用程式中使用此功能,我們只需要新增衍生自 DbConfiguration 的 類別,然後開啟重試邏輯。
// EF follows a Code based Configuration model and will look for a class that // derives from DbConfiguration for executing any Connection Resiliency strategies public class EFConfiguration : DbConfiguration { public EFConfiguration() { AddExecutionStrategy(() => new SqlAzureExecutionStrategy()); } }針對架構識別為一般暫時性錯誤的 SQL Database 例外狀況,顯示的程式代碼會指示 EF 重試作業最多 3 次,並在重試之間有指數輪詢延遲,而延遲上限為 5 秒。 指數輪詢表示每次重試失敗之後,它會等待較長的時間再試一次。 如果數據列中有三次嘗試失敗,則會擲回例外狀況。 下列關於斷路器的章節說明為何您想要指數輪詢和有限的重試次數。
當您使用 Azure 記憶體服務時,可能會有類似的問題,因為修正它應用程式適用於 Blob,而 .NET 記憶體用戶端 API 已經實作相同類型的邏輯。 您只要指定重試原則,或者如果您滿意預設設定,就不需要這麼做。
斷路 器
有數個原因導致您不想在太長期間內重試太多次:
- 太多用戶持續重試失敗的要求可能會降低其他用戶的體驗。 如果數百萬人都提出重複的重試要求,您可能會將 IIS 分派佇列系結,並防止您的應用程式維護成功處理的要求。
- 如果每個人都因為服務失敗而重試,可能會有太多要求排入佇列,服務在開始復原時就會被填入。
- 如果錯誤是因為節流所造成,而且服務用於節流的時間範圍,則繼續重試可能會將該視窗移出,並導致節流繼續。
- 您可能有使用者等候網頁轉譯。 讓人員等候太長,可能更令人不快地建議他們稍後再試一次。
指數輪詢可藉由限制服務可從您的應用程式取得的重試頻率,解決其中一些問題。 但您也需要有 斷路器:這表示在特定的重試閾值下,您的應用程式會停止重試並採取其他動作,例如下列其中一項:
- 自訂後援。 如果您無法從波羅吉斯取得股票價格,或許您可以從 Bloomberg 取得它;或者,如果您無法從資料庫取得數據,或許可以從快取中取得數據。
- 失敗無訊息。 如果您需要的服務並非應用程式的所有或無專案,只要在無法取得數據時傳回 null。 如果您要顯示 [修正它] 工作,且 Blob 服務沒有回應,則可以顯示工作詳細數據,而不顯示影像。
- 快速失敗。 用戶發生錯誤,以避免因重試要求而造成其他使用者的服務中斷,或延長節流視窗。 您可以顯示易記的「稍後再試」訊息。
沒有一個大小相符的重試原則。 您可以重試更多次,並在異步背景背景工作進程中等候較長的時間,比在等候回應的同步 Web 應用程式中還要長。 您可以等候關係資料庫服務的重試時間比快取服務還要長。 以下是一些建議的重試原則範例,讓您了解數位可能會如何改變。 (「快速優先」表示第一次重試前不會延遲。
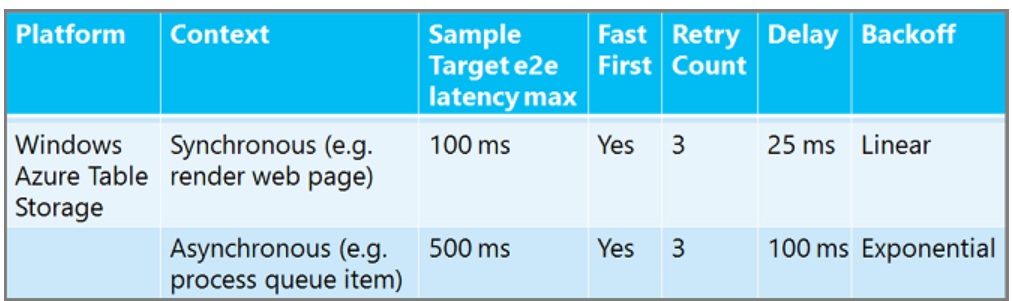
如需 SQL Database 重試原則指引,請參閱針對 SQL Database 的暫時性錯誤和連線錯誤進行疑難解答。
摘要
重試/輪詢策略可協助讓客戶在大部分時間都看不到暫時錯誤,而 Microsoft 提供架構,讓您能夠用來將實作策略的架構降至最低,不論您使用的是 ADO.NET、Entity Framework 或 Azure 記憶體服務。
在下 一章中,我們將探討如何使用分散式快取來改善效能和可靠性。
資源
如需詳細資訊,請參閱下列資源:
文件
- Azure 雲端服務 上 Large-Scale 服務設計的最佳作法。 Mark Simms 和 Michael Thomassy 的白皮書。 類似於 Failsafe 系列,但會深入探討更多操作說明詳細數據。 請參閱遙測和診斷一節。
- Afe:復原雲端架構的指引。 由 Andrew Mercuri、Ulrich Homann 和 Andrew Town 的白皮書。 FailSafe 影片系列的網頁版本。
- Microsoft 模式和做法 - Azure 指引。 請參閱重試模式、排程器代理程式監督員模式。
- Entity Framework - 連線復原/重試邏輯。 如何使用和自定義 Entity Framework 6 的暫時性錯誤處理功能。
- ASP.NET MVC 應用程式中的 Entity Framework 連線復原和命令攔截。 第四個部分的教學課程系列會示範如何為 SQL Database 設定 EF 6 連線復原功能。
影片
- FailSafe:建置可調整、復原 雲端服務。 Ulrich Homann、Marc Mercuri 和 Mark Simms 的九部分系列。 以非常無障礙且有趣的方式呈現高階概念和架構原則,其中包含來自 Microsoft Customer Advisory Team (CAT) 實際客戶經驗的故事。 請參閱從 40:55 開始的第 3 集斷路器的討論。
- 建置巨量:從 Azure 客戶學到的課程 - 第 II 部分。 Mark Simms 會討論設計失敗、暫時性錯誤處理,以及檢測所有專案。
程式碼範例
- Azure 中的雲端服務基本概念。 Microsoft Azure 客戶諮詢小組所建立的範例應用程式,示範如何使用 企業連結庫暫時性錯誤處理區塊 (TFH) 。 如需詳細資訊,請參閱 雲端服務基礎資料存取層 – 暫時性錯誤處理。 建議使用 TFH 直接 ADO.NET (數據庫存取,而不需使用 Entity Framework) 。
意見反應
即將登場:在 2024 年,我們將逐步淘汰 GitHub 問題作為內容的意見反應機制,並將它取代為新的意見反應系統。 如需詳細資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交並檢視相關的意見反應