Chatty I/O antipattern
大量 I/O 要求的累積效果可能會對效能和回應能力產生重大影響。
問題說明
相較于計算工作,網路呼叫和其他 I/O 作業原本就很慢。 每個 I/O 要求通常都有顯著的額外負荷,而且許多 I/O 作業的累積效果可能會讓系統變慢。 以下是閒聊 I/O 的一些常見原因。
以不同的要求將個別記錄讀取和寫入資料庫
下列範例會從產品資料庫讀取。 有三個數據表、 Product 、 ProductSubcategory 和 ProductPriceListHistory 。 程式碼會藉由執行一系列查詢,擷取子類別中的所有產品以及定價資訊:
- 從
ProductSubcategory資料表查詢子類別。 - 查詢
Product資料表,以尋找該子類別中的所有產品。 - 針對每個產品,查詢資料表中的
ProductPriceListHistory定價資料。
應用程式會使用 Entity Framework 來查詢資料庫。 您可以在這裡 找到完整的範例 。
public async Task<IHttpActionResult> GetProductsInSubCategoryAsync(int subcategoryId)
{
using (var context = GetContext())
{
// Get product subcategory.
var productSubcategory = await context.ProductSubcategories
.Where(psc => psc.ProductSubcategoryId == subcategoryId)
.FirstOrDefaultAsync();
// Find products in that category.
productSubcategory.Product = await context.Products
.Where(p => subcategoryId == p.ProductSubcategoryId)
.ToListAsync();
// Find price history for each product.
foreach (var prod in productSubcategory.Product)
{
int productId = prod.ProductId;
var productListPriceHistory = await context.ProductListPriceHistory
.Where(pl => pl.ProductId == productId)
.ToListAsync();
prod.ProductListPriceHistory = productListPriceHistory;
}
return Ok(productSubcategory);
}
}
如果 O/RM 一次隱含擷取子記錄,此範例會明確顯示問題,但有時候 O/RM 可以遮罩問題。 這稱為「N+1 問題」。
將單一邏輯作業實作為一系列 HTTP 要求
當開發人員嘗試遵循物件導向的範例時,通常會發生這種情況,並將遠端物件視為記憶體中的本機物件。 這可能會導致太多網路來回行程。 例如,下列 Web API 會透過個別 HTTP GET 方法公開物件的個別屬性 User 。
public class UserController : ApiController
{
[HttpGet]
[Route("users/{id:int}/username")]
public HttpResponseMessage GetUserName(int id)
{
...
}
[HttpGet]
[Route("users/{id:int}/gender")]
public HttpResponseMessage GetGender(int id)
{
...
}
[HttpGet]
[Route("users/{id:int}/dateofbirth")]
public HttpResponseMessage GetDateOfBirth(int id)
{
...
}
}
雖然這種方法在技術上沒有問題,但大部分用戶端可能需要取得每個 User 屬性的數個屬性,因而產生如下的用戶端程式代碼。
HttpResponseMessage response = await client.GetAsync("users/1/username");
response.EnsureSuccessStatusCode();
var userName = await response.Content.ReadAsStringAsync();
response = await client.GetAsync("users/1/gender");
response.EnsureSuccessStatusCode();
var gender = await response.Content.ReadAsStringAsync();
response = await client.GetAsync("users/1/dateofbirth");
response.EnsureSuccessStatusCode();
var dob = await response.Content.ReadAsStringAsync();
讀取和寫入磁片上的檔案
檔案 I/O 牽涉到開啟檔案,並在讀取或寫入資料之前移至適當的點。 作業完成時,可能會關閉檔案以儲存作業系統資源。 持續讀取和寫入少量資訊至檔案的應用程式,將會產生大量的 I/O 額外負荷。 小型寫入要求也會導致檔案片段化,進一步減緩後續 I/O 作業的速度。
下列範例會使用 FileStream 將 物件寫入 Customer 檔案。 建立 會 FileStream 開啟檔案,並將它處置關閉檔案。 (語句 using 會自動處置 FileStream 物件。如果應用程式在新增客戶時重複呼叫此方法,I/O 額外負荷可能會快速累積。
private async Task SaveCustomerToFileAsync(Customer customer)
{
using (Stream fileStream = new FileStream(CustomersFileName, FileMode.Append))
{
BinaryFormatter formatter = new BinaryFormatter();
byte [] data = null;
using (MemoryStream memStream = new MemoryStream())
{
formatter.Serialize(memStream, customer);
data = memStream.ToArray();
}
await fileStream.WriteAsync(data, 0, data.Length);
}
}
如何修正問題
將資料封裝成較大的較少要求,以減少 I/O 要求數目。
從資料庫擷取資料做為單一查詢,而不是數個較小的查詢。 以下是擷取產品資訊的程式碼修訂版本。
public async Task<IHttpActionResult> GetProductCategoryDetailsAsync(int subCategoryId)
{
using (var context = GetContext())
{
var subCategory = await context.ProductSubcategories
.Where(psc => psc.ProductSubcategoryId == subCategoryId)
.Include("Product.ProductListPriceHistory")
.FirstOrDefaultAsync();
if (subCategory == null)
return NotFound();
return Ok(subCategory);
}
}
遵循 Web API 的 REST 設計原則。 以下是先前範例中已修訂的 Web API 版本。 除了每個屬性的個別 GET 方法,還有一個會傳回 User 的單一 GET 方法。 這會導致每個要求產生較大的回應本文,但每個用戶端都可能會進行較少的 API 呼叫。
public class UserController : ApiController
{
[HttpGet]
[Route("users/{id:int}")]
public HttpResponseMessage GetUser(int id)
{
...
}
}
// Client code
HttpResponseMessage response = await client.GetAsync("users/1");
response.EnsureSuccessStatusCode();
var user = await response.Content.ReadAsStringAsync();
針對檔案 I/O,請考慮在記憶體中緩衝資料,然後將緩衝資料寫入檔案作為單一作業。 這種方法可減少重複開啟和關閉檔案的額外負荷,並協助減少磁片上的檔案片段。
// Save a list of customer objects to a file
private async Task SaveCustomerListToFileAsync(List<Customer> customers)
{
using (Stream fileStream = new FileStream(CustomersFileName, FileMode.Append))
{
BinaryFormatter formatter = new BinaryFormatter();
foreach (var customer in customers)
{
byte[] data = null;
using (MemoryStream memStream = new MemoryStream())
{
formatter.Serialize(memStream, customer);
data = memStream.ToArray();
}
await fileStream.WriteAsync(data, 0, data.Length);
}
}
}
// In-memory buffer for customers.
List<Customer> customers = new List<Customers>();
// Create a new customer and add it to the buffer
var customer = new Customer(...);
customers.Add(customer);
// Add more customers to the list as they are created
...
// Save the contents of the list, writing all customers in a single operation
await SaveCustomerListToFileAsync(customers);
考量
前兩個範例會進行 較少的 I/O 呼叫,但每個範例都會擷 取更多資訊 。 您必須考慮這兩個因素之間的取捨。 正確的答案將取決於實際的使用模式。 例如,在 Web API 範例中,用戶端通常只需要使用者名稱。 在此情況下,將它公開為個別 API 呼叫可能很合理。 如需詳細資訊,請參閱 外部擷取 反模式。
讀取資料時,請勿讓您的 I/O 要求太大。 應用程式應該只擷取可能使用的資訊。
有時候,它有助於將物件的資訊分割成兩個區塊、 經常存取的資料,這些資料 占大部分要求,以及 很少使用的資料。 通常最常存取的資料是物件資料總數的一小部分,因此只傳回該部分可以節省大量的 I/O 額外負荷。
寫入資料時,請避免鎖定資源超過必要時間,以減少長時間作業期間爭用的機會。 如果寫入作業跨越多個資料存放區、檔案或服務,則採用最終一致的方法。 請參閱 資料一致性指引 。
如果您在寫入之前緩衝記憶體中的資料,如果進程當機,則資料會很脆弱。 如果資料速率通常具有高載或相對疏鬆,則緩衝外部長期佇列中的資料可能會更安全,例如 事件中樞 。
請考慮快取您從服務或資料庫擷取的資料。 這可藉由避免重複要求相同的資料,來協助減少 I/O 的數量。 如需詳細資訊,請參閱 快取最佳做法 。
如何偵測問題
閒聊 I/O 的症狀包括高延遲和低輸送量。 使用者可能會報表服務逾時所造成的擴充回應時間或失敗,因為 I/O 資源的爭用增加。
您可以執行下列步驟來協助識別任何問題的原因:
- 執行生產系統的程式監視,以識別回應時間不佳的作業。
- 執行上一個步驟中所識別之每個作業的負載測試。
- 在負載測試期間,收集每個作業所提出資料存取要求的相關遙測資料。
- 收集傳送至資料存放區之每個要求的詳細統計資料。
- 在測試環境中分析應用程式,以在可能發生 I/O 瓶頸的情況下建立。
尋找下列任何徵兆:
- 對相同檔案提出大量小型 I/O 要求。
- 應用程式實例對相同服務提出的大量小型網路要求。
- 應用程式實例對相同資料存放區提出的大量小型要求。
- 應用程式和服務成為 I/O 系結。
診斷範例
下列各節會將這些步驟套用至稍早查詢資料庫的範例。
負載測試應用程式
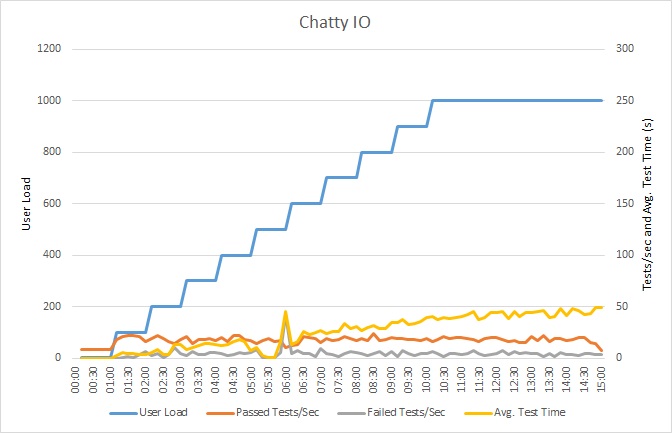
此圖表顯示負載測試的結果。 每個要求的回應時間中位數是以數十秒為單位來測量。 此圖表顯示非常高的延遲。 載入 1000 位使用者時,使用者可能必須等候近一分鐘才能查看查詢的結果。
注意
應用程式已使用 Azure SQL 資料庫 部署為Azure App 服務 Web 應用程式。 負載測試使用最多 1000 位並行使用者的模擬步驟工作負載。 資料庫已設定為支援最多 1000 個並行連線的連接集區,以減少連線爭用會影響結果的機會。
監視應用程式
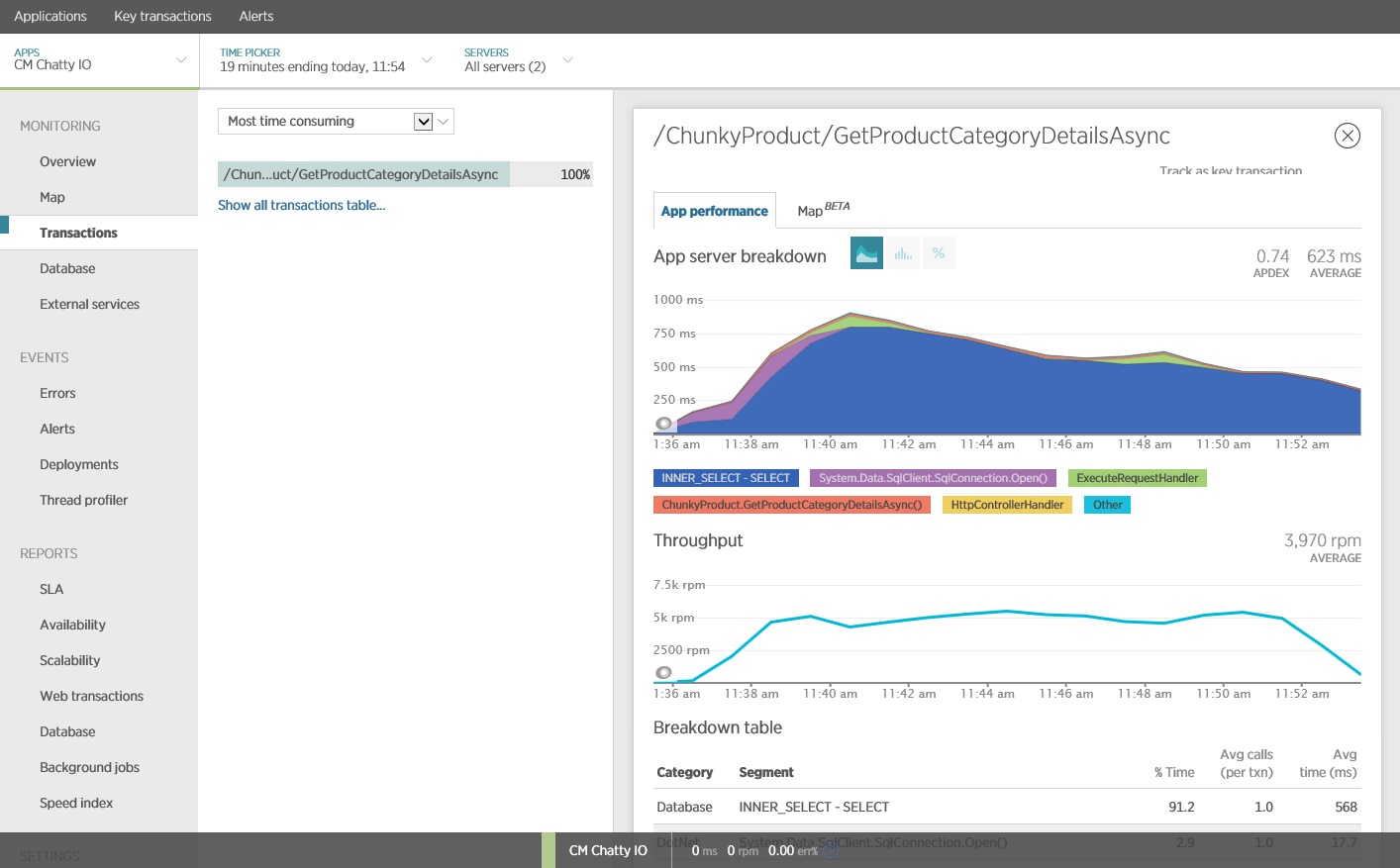
您可以使用應用程式效能監視 (APM) 套件來擷取和分析可能識別閒聊 I/O 的關鍵計量。 哪些計量很重要,將取決於 I/O 工作負載。 在此範例中,有趣的 I/O 要求是資料庫查詢。
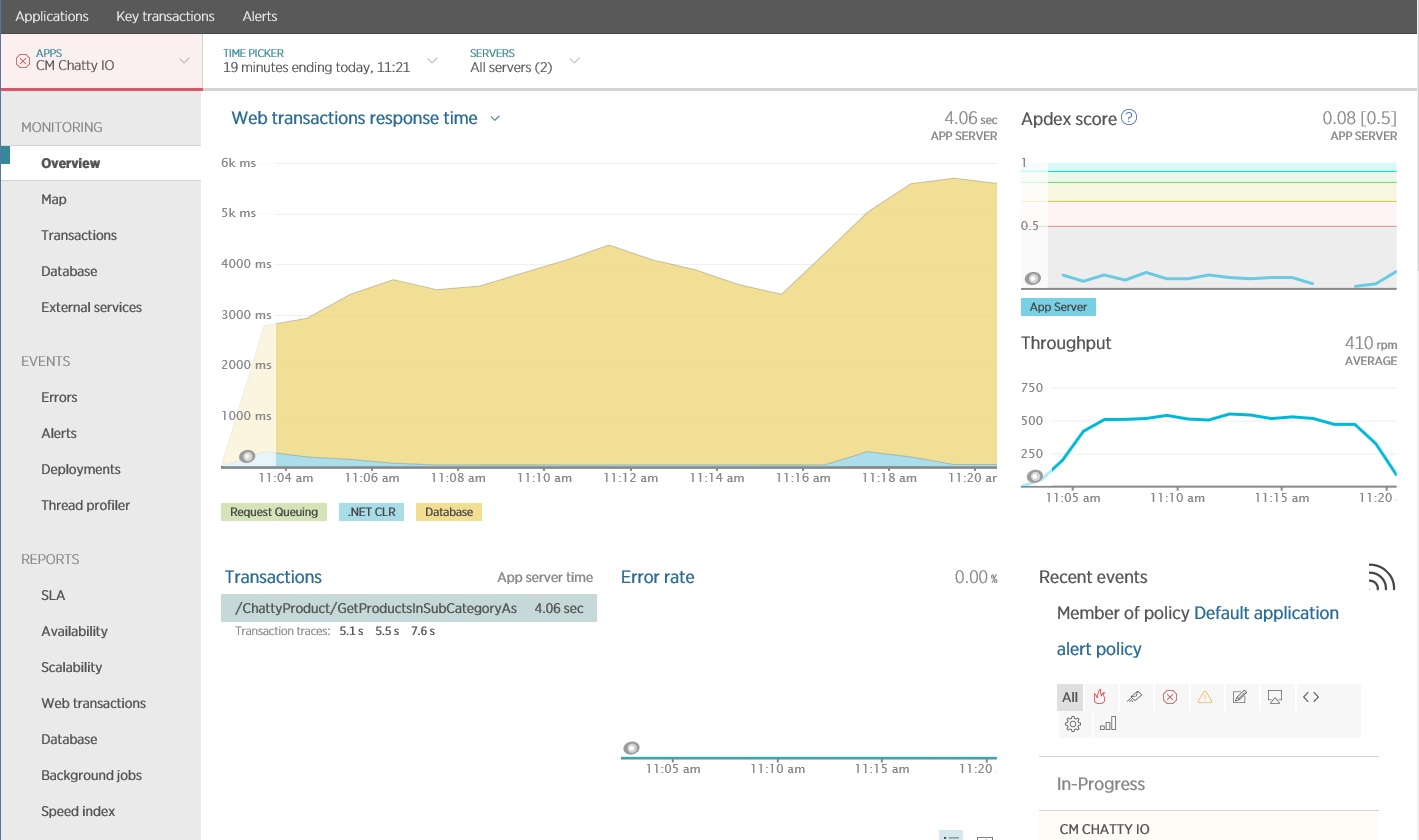
下圖顯示使用 New Relic APM 所產生的結果。 在工作負載上限期間,每個要求的平均回應時間在大約 5.6 秒時達到尖峰。 系統在整個測試中平均每分鐘支援 410 個要求。
收集詳細的資料存取訊號
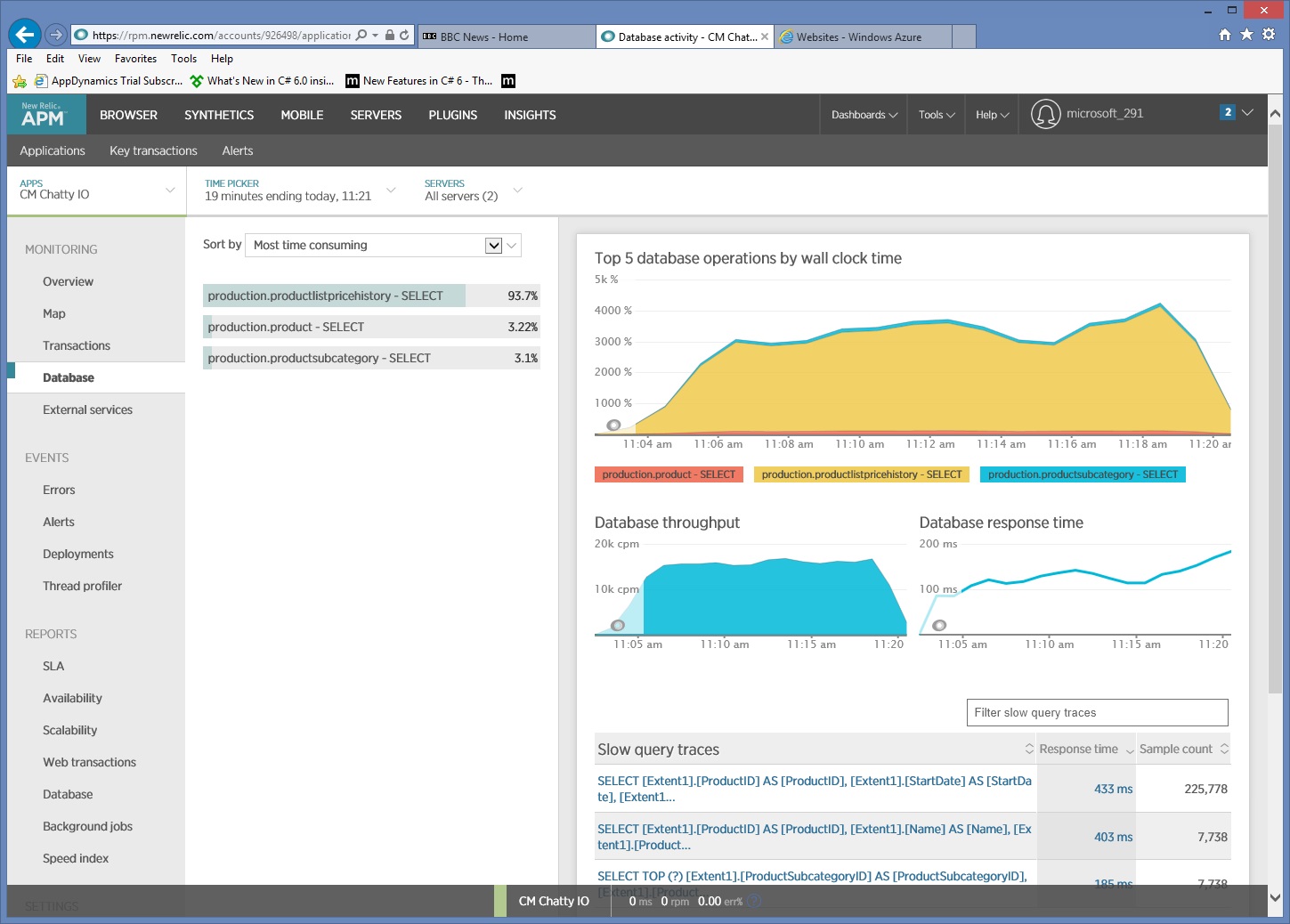
深入探索監視資料,顯示應用程式會執行三個不同的 SQL SELECT 語句。 這些會對應至 Entity Framework 所產生的要求,以從 ProductListPriceHistory 、 Product 和 ProductSubcategory 資料表擷取資料。 此外,從 ProductListPriceHistory 資料表擷取資料的查詢是迄今為止最常執行的 SELECT 語句,其大小順序。
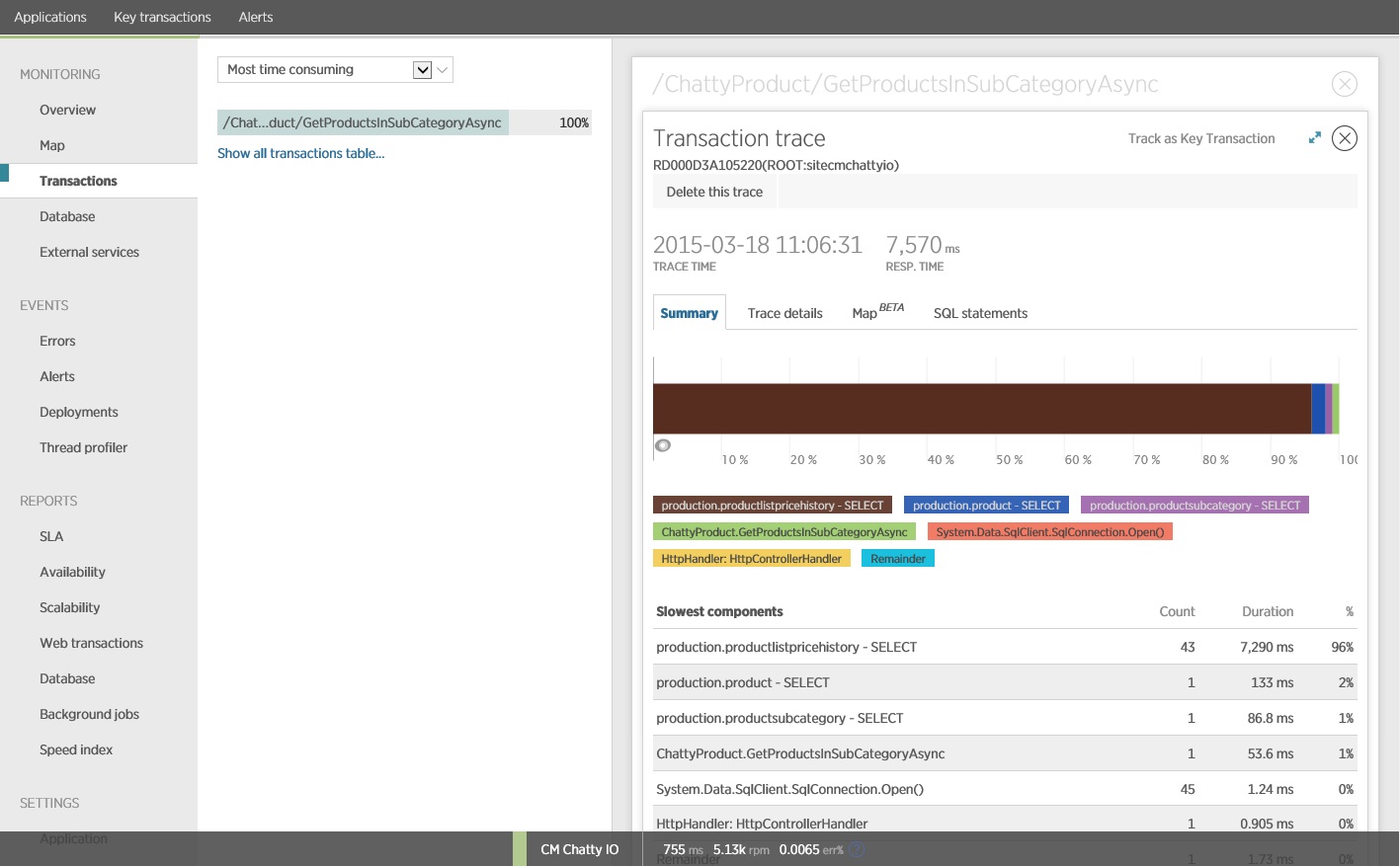
事實證明 GetProductsInSubCategoryAsync ,稍早顯示的 方法會執行 45 個 SELECT 查詢。 每個查詢都會讓應用程式開啟新的 SQL 連線。
注意
此影像顯示負載測試中作業最慢實例的 GetProductsInSubCategoryAsync 追蹤資訊。 在生產環境中,檢查最慢實例的追蹤會很有用,以查看是否有建議問題的模式。 如果您只是查看平均值,您可能會忽略負載會大幅惡化的問題。
下一個影像顯示發出的實際 SQL 語句。 擷取價格資訊的查詢會針對產品子類別中的每個個別產品執行。 使用聯結可大幅減少資料庫呼叫數目。
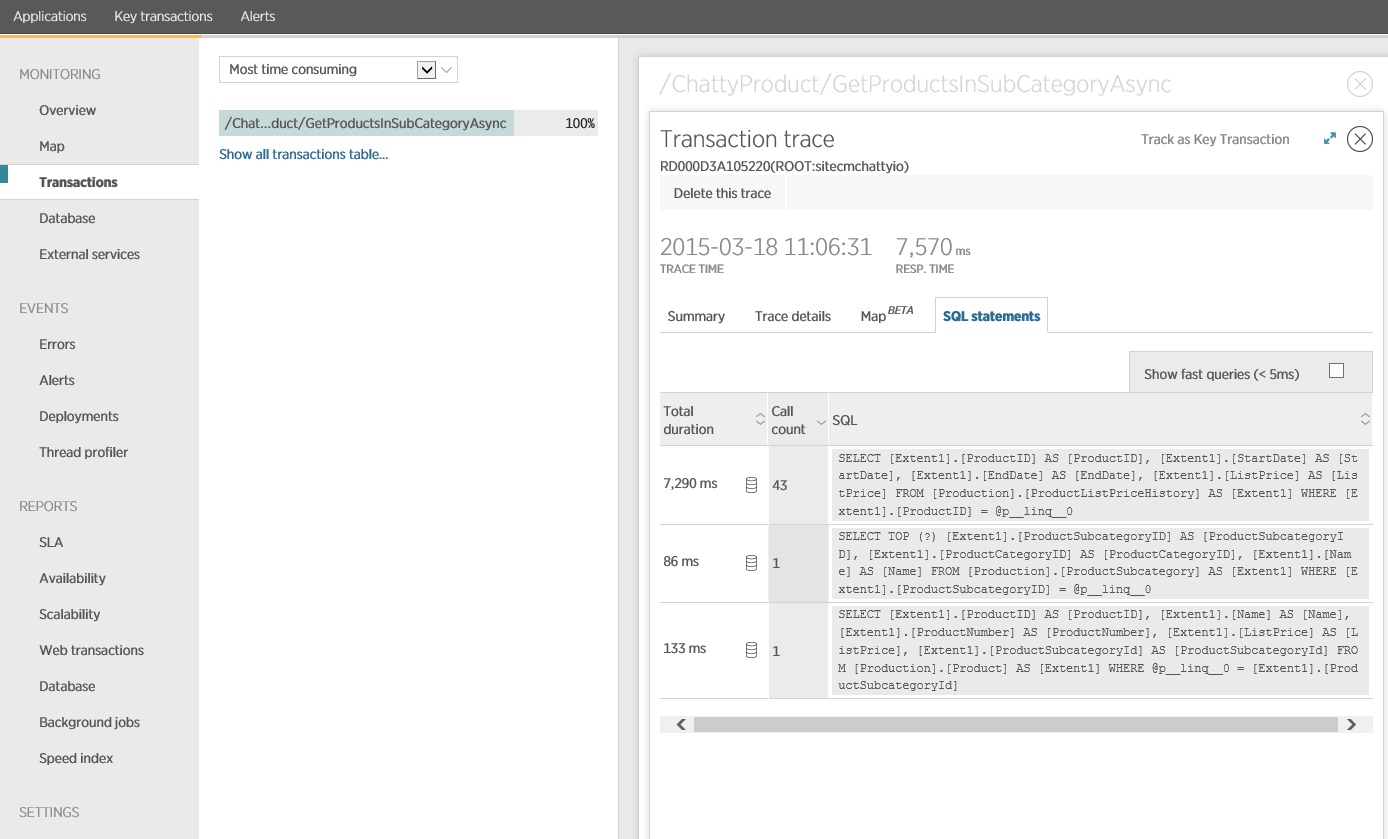
如果您使用 O/RM,例如 Entity Framework,追蹤 SQL 查詢可以提供 O/RM 如何將程式設計呼叫轉譯成 SQL 語句的深入解析,並指出資料存取可能優化的區域。
實作解決方案並驗證結果
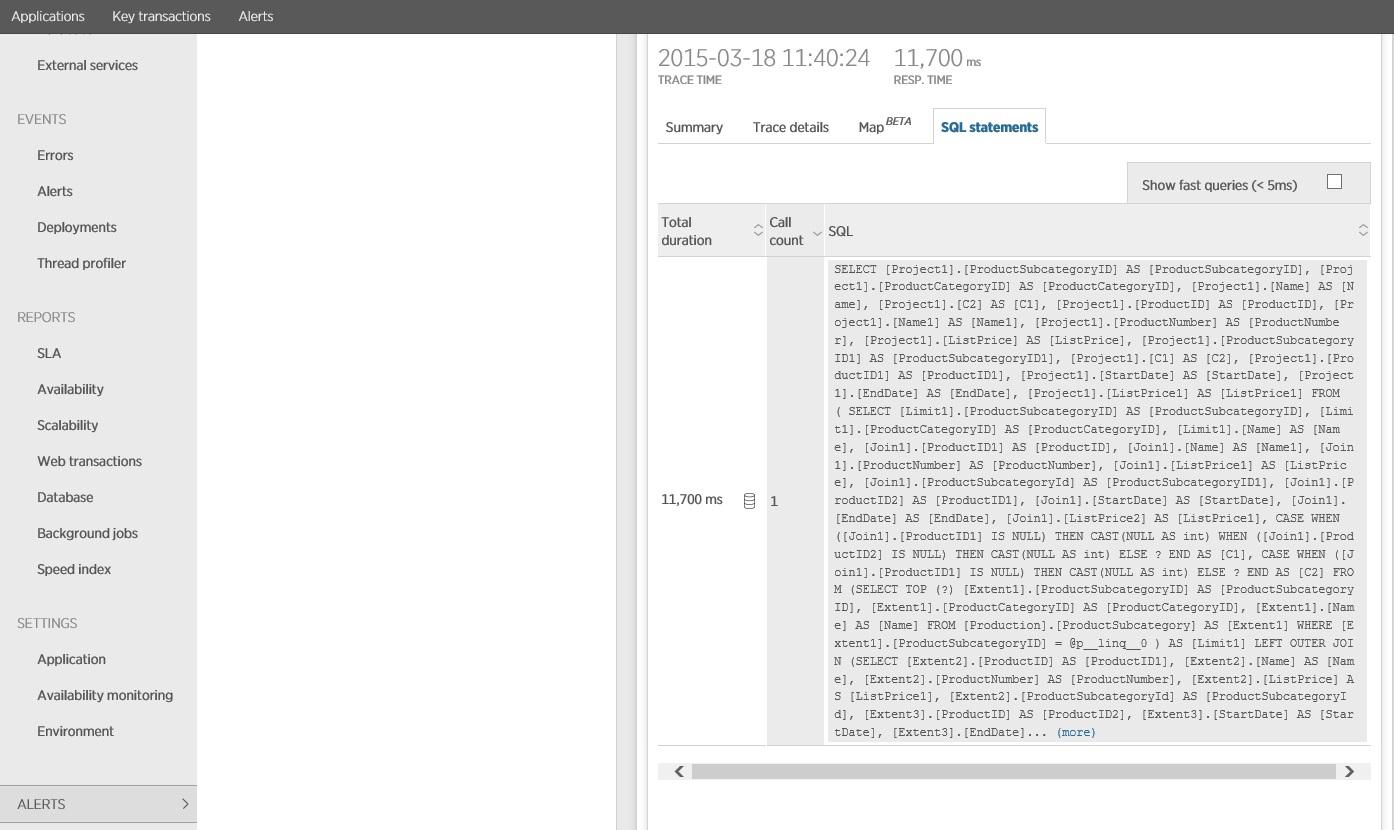
重寫對 Entity Framework 的呼叫會產生下列結果。
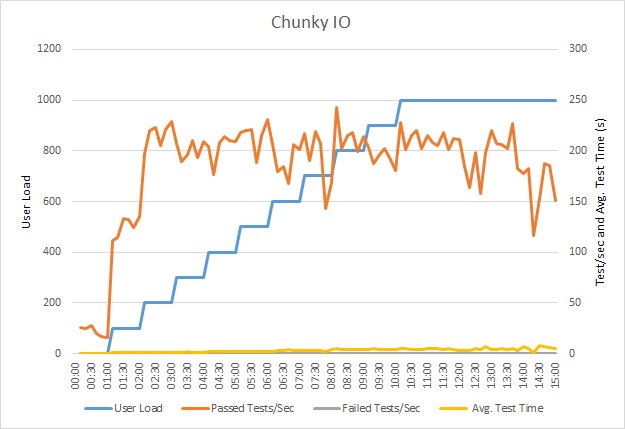
此負載測試是在相同的部署上執行,使用相同的負載設定檔。 這一次圖表會顯示低得多的延遲。 1000 位使用者的平均要求時間介於 5 到 6 秒之間,比近一分鐘減少。
這一次,系統平均每分鐘支援 3,970 個要求,而先前的測試則為 410 個。
追蹤 SQL 語句會顯示在單一 SELECT 語句中擷取所有資料。 雖然此查詢相當複雜,但每個作業只會執行一次。 雖然複雜的聯結可能會變得昂貴,但關係資料庫系統會針對這種類型的查詢進行優化。
相關資源
意見反應
即將登場:在 2024 年,我們將逐步淘汰 GitHub 問題作為內容的意見反應機制,並將它取代為新的意見反應系統。 如需詳細資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交並檢視相關的意見反應