答案的信賴分數
當使用者查詢與 知識庫 相符時,QnA Maker 會傳回相關的答案,以及信賴分數。 此分數表示答案符合指定使用者查詢的信賴度。
信賴分數是介於 0 到 100 之間的數位。 100 分數可能是完全相符的,而分數為 0 表示找不到相符的答案。 分數越高, 答案的信心就越高。 針對指定的查詢,可能會傳回多個答案。 在此情況下,會傳回答案,以遞減信賴分數的順序傳回。
在下列範例中,您可以看到一個 QnA 實體,其中包含 2 個問題。

針對上述範例,您可以預期不同類型用戶查詢的分數,如以下範例分數範圍:
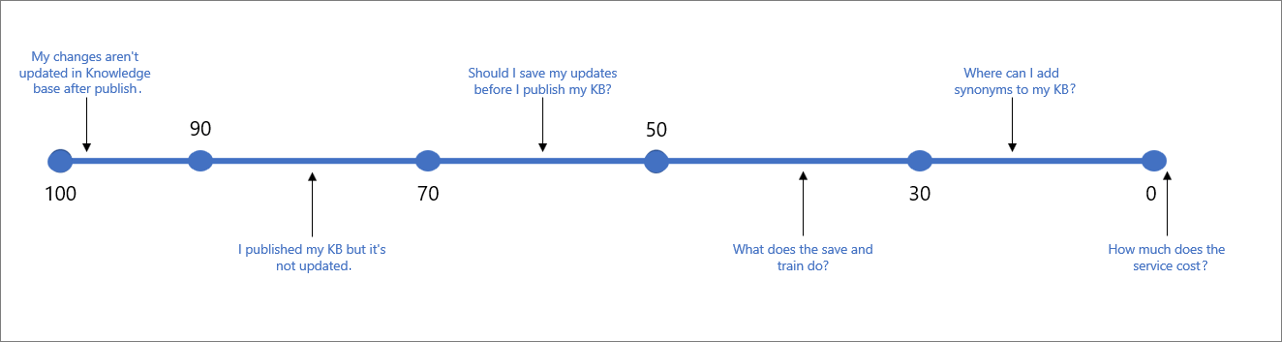
下表指出與指定分數相關聯的一般信賴度。
| 分數值 | 分數意義 | 範例查詢 |
|---|---|---|
| 90 - 100 | 用戶查詢和 KB 問題的接近完全相符專案 | 「發行後,我的變更不會在 KB 中更新」 |
| > 70 | 高信賴度 - 通常是完全回答用戶查詢的好答案 | 「我已發佈知識庫,但未更新」 |
| 50 - 70 | 中等信賴度 - 通常相當不錯的答案,應該回答用戶查詢的主要意圖 | 「我應該在發佈 KB 之前儲存更新嗎? |
| 30 - 50 | 低信賴度 - 通常是相關答案,部分回答用戶的意圖 | 儲存和訓練有何用途? |
| < 30 | 非常低的信心 - 通常不會回答用戶的查詢,但有一些相符的字詞或片語 | “我可以在哪裡將同義字新增至我的 KB” |
| 0 | 沒有相符專案,因此不會傳回答案。 | 「服務成本是多少」 |
選擇分數閾值
上表顯示大部分 KB 的預期分數。 不過,由於每個 KB 都不同,而且有不同類型的文字、意圖和目標,因此建議您測試並選擇最適合您的閾值。 根據預設,閾值會設定為 0,以便傳回所有可能的答案。 建議的臨界值應該適用於大部分 KB,為 50。
選擇閾值時,請記住精確度與涵蓋範圍之間的平衡,並根據需求調整閾值。
如果 精確度(或精確度 )對您的案例更重要,請增加閾值。 如此一來,每次您傳回答案時,這將是一個更自信的情況,而且更有可能是使用者正在尋找的答案。 在此情況下,您最終可能會留下更多未回答的問題。 例如: 如果您將閾值 設為 70,您可能會錯過一些模棱兩可的範例,例如「儲存和定型是什麼?」。
如果 涵蓋範圍 (或召回率)更重要,而且您想要盡可能回答許多問題,即使只有與用戶的問題有部分關聯,則降低閾值。 這表示可能會有更多的情況,答案不會回答用戶的實際查詢,但提供一些其他相關的答案。 例如: 如果您將閾值 設定為 30,您可能會為「我可以在哪裡編輯我的 KB」之類的查詢提供解答?
注意
較新版本的 QnA Maker 包含評分邏輯的改善,並可能會影響您的閾值。 每當您更新服務時,請務必視需要測試及調整臨界值。 您可以在這裡檢查 QnA 服務版本,並瞭解如何在這裡取得最新的更新。
設定臨界值
將臨界值分數設定為 GenerateAnswer API JSON 主體的屬性。 這表示您會針對 GenerateAnswer 的每個呼叫設定它。
從 Bot 架構,使用 C# 或 Node.js 將分數設定為 options 物件的一部分。
改善信賴分數
若要改善特定回應對用戶查詢的信心分數,您可以將用戶查詢新增至 知識庫 做為該回應的替代問題。 您也可以使用不區分大小寫 的字組改變 ,將同義字新增至知識庫中的關鍵詞。
類似的信賴分數
當多個回應具有類似的信賴分數時,查詢可能太泛型,因此與多個答案的相同可能性相符。 請嘗試更妥善地建構 QnA,讓每個 QnA 實體都有不同的意圖。
測試與生產環境之間的信賴分數差異
在測試和發佈的知識庫版本之間,即使內容相同,不過答案的信賴分數可能會略微變化。 這是因為測試的內容和已發佈 知識庫 位於不同的 Azure AI 搜尋服務索引中。
測試索引會保存您 知識庫 的所有 QnA 組。 查詢測試索引時,查詢會套用至整個索引,然後結果會限制為該特定 知識庫 的數據分割。 如果測試查詢結果對驗證 知識庫 的能力產生負面影響,您可以:
- 使用下列其中一項來組織您的 知識庫:
- 1 個限制為 1 KB 的資源:將單一 QnA 資源(以及產生的 Azure AI 搜尋服務測試索引)限制為單一 知識庫。
- 2 個資源 - 1 用於測試,1 用於生產:有兩個 QnA Maker 資源,使用一個進行測試(具有自己的測試和生產索引),另一個用於產品(也有自己的測試和生產索引)
- 和,一律使用相同的參數,例如查詢測試和生產 知識庫
當您發佈 知識庫 時,知識庫 的問題和解答內容會從測試索引移至 Azure 搜尋服務中的生產索引。 查看發佈作業的運作方式。
如果您有不同區域中的 知識庫,每個區域都會使用自己的 Azure AI 搜尋索引。 因為使用不同的索引,因此分數不會完全相同。
找不到相符專案
當排名器找不到任何良好的相符專案時,會傳回 0.0 或 “None” 的信賴分數,而默認回應為「KB 中找不到良好的相符專案」。 您可以在 Bot 或呼叫端點的應用程式程式碼中覆寫此 預設回應 。 或者,您也可以在 Azure 中設定覆寫回應,這會變更在特定 QnA Maker 服務中部署的所有 知識庫 預設值。