計算
Azure Databricks 計算是指 Azure Databricks 工作區中可用的計算資源選擇。 使用者需要存取計算來執行數據工程、數據科學和數據分析工作負載,例如生產 ETL 管線、串流分析、臨機操作分析和機器學習。
使用者可以連線到現有的計算,或建立新的計算,如果他們具有適當的許可權。
您可以使用工作區的 [計算] 區段來檢視您有權存取 的計算 :
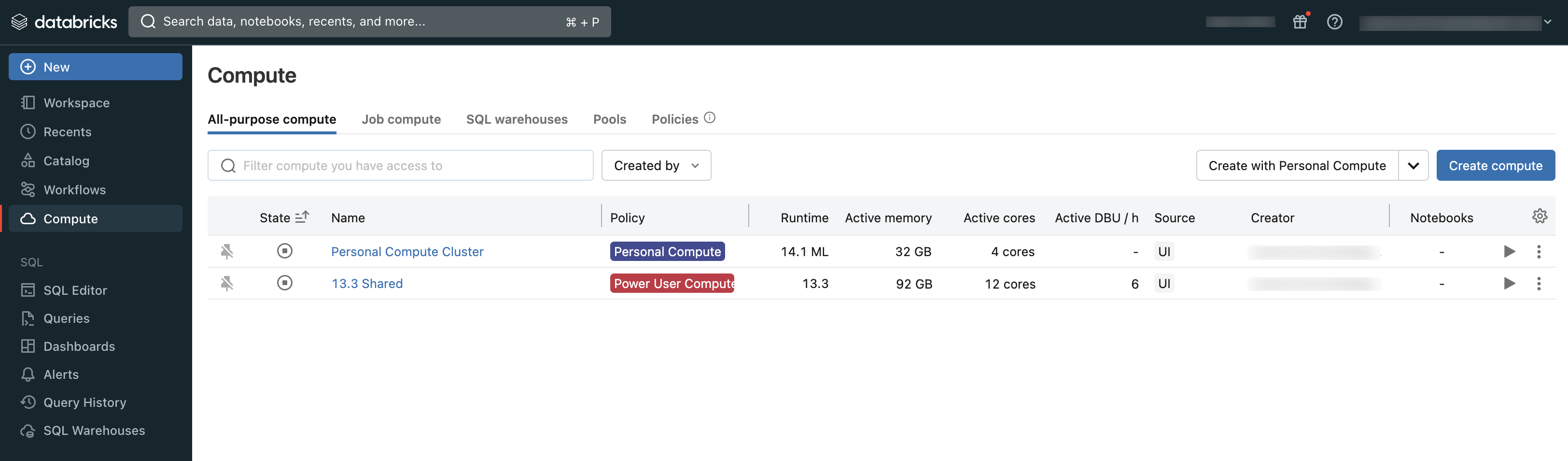
計算類型
這些是 Azure Databricks 中可用的計算類型:
筆記本的無伺服器計算 (公開預覽):隨選、可調整的計算,用來在筆記本中執行 SQL 和 Python 程式代碼。
工作流程的無伺服器計算 (公開預覽):隨選、可調整的計算,用來執行 Databricks 作業,而不需設定及部署基礎結構。
全用途計算:用來分析筆記本中數據的已布建計算。 您可以使用 UI、CLI 或 REST API 來建立、終止和重新啟動此計算。
作業計算:用來執行自動化作業的已布建計算。 每當作業設定為在新計算上執行時,Azure Databricks 作業排程器就會自動建立作業計算。 計算會在作業完成時終止。 您無法重新啟動作業計算。 請參閱 搭配您的作業使用 Azure Databricks 計算。
實例集區:使用閑置、現成可用的實例計算,用來減少啟動和自動調整時間。 您可以使用 UI、CLI 或 REST API 來建立此計算。
無伺服器 SQL 倉儲:隨選彈性計算,用來在 SQL 編輯器或互動式筆記本中的數據物件上執行 SQL 命令。 您可以使用 UI、CLI 或 REST API 來建立 SQL 倉儲。
傳統 SQL 倉儲:用來在 SQL 編輯器或互動式筆記本中的數據物件上執行 SQL 命令的已布建計算。 您可以使用 UI、CLI 或 REST API 來建立 SQL 倉儲。
本節中的文章說明如何使用 Azure Databricks UI 來處理計算資源。 如需其他方法,請參閱 使用命令行 和 Databricks REST API 參考。
Databricks 執行階段
Databricks Runtime 是一組在您的計算上執行的核心元件。 Databricks Runtime 是作業計算但 SQL 倉儲中自動選取之所有用途的可設定設定。
每個 Databricks 執行時間版本都包含可改善巨量數據分析可用性、效能和安全性的更新。 計算上的 Databricks Runtime 會新增許多功能,包括:
- Delta Lake 是建置在 Apache Spark 之上的下一代儲存層,可提供 ACID 交易、優化版面配置和索引,以及建置數據管線的執行引擎改進。 請參閱 什麼是 Delta Lake?。
- 已安裝 Java、Scala、Python 和 R 連結庫。
- Ubuntu 及其隨附的系統連結庫。
- 已啟用 GPU 之叢集的 GPU 連結庫。
- 與平臺其他元件整合的 Azure Databricks 服務,例如筆記本、作業和叢集管理。
如需每個運行時間版本內容的相關信息,請參閱 版本資訊。
運行時間版本控制
Databricks Runtime 版本會定期發行:
- 長期支援 版本是由 LTS 限定符表示(例如 3.5 LTS)。 針對每個主要版本,我們宣告「正式」功能版本,我們提供三年的完整支援。 如需詳細資訊,請參閱 Databricks 運行時間支援生命週期。
- 主要 版本是以小數點之前的版本號碼遞增來表示(例如,從 3.5 跳至 4.0)。 它們會在有重大變更時釋出,其中有些可能與回溯相容。
- 功能 版本是以小數點後面的版本號碼遞增來表示(例如,從3.4跳至3.5)。 每個主要版本都包含多個功能版本。 功能版本在主要版本中一律與舊版回溯相容。
意見反應
即將登場:在 2024 年,我們將逐步淘汰 GitHub 問題作為內容的意見反應機制,並將它取代為新的意見反應系統。 如需詳細資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交並檢視相關的意見反應