AutoML 中的預測方法概觀
本文著重於 AutoML 用來準備時間序列資料及建置預測模型的方法。 如需在 AutoML 中定型預測模型的指示和範例,請參閱我們的設定 AutoML 以進行時間序列預測一文。
AutoML 使用數種方法來預測時間序列值。 這些方法大致可以指派給兩個類別:
- 使用目標數量記錄值來預測未來的時間序列模型。
- 使用預測器變數來預測目標值的迴歸或說明模型。
例如,請考量下列問題,預測雜貨店特定柳橙汁品牌的每日需求。 讓 $y_t$ 代表該品牌在 $t$ 這一天的需求。 時間序列模型使用記錄需求的一些函數來預測 $t+1$ 的需求,
$y_{t+1} = f(y_t, y_{t-1}, \ldots, y_{t-s})$。
函式 $f$ 通常會有參數,我們會使用過去觀察到的需求來調整。 $f$ 用來進行預測 $s$ 的記錄數量,也可以視為模型的參數。
柳橙汁需求範例中的時間序列模型可能不夠準確,因為其只使用過去需求的相關資訊。 還有其他許多因素可能會影響未來的需求,如價格、星期幾,以及是否為假日。 請考慮使用這些預測器變數的迴歸模型,
$y = g(\text{price}, \text{day of week}, \text{holiday})$。
同樣地,$g$ 通常會有一組參數,包括控管正規化的參數,AutoML 會使用過去的需求值和預測值來進行調整。 我們省略表達式中的 $t$,強調迴歸模型會使用同時定義變數之間的相互關聯模式來進行預測。 也就是說,若要從 $g$ 預測 $y_{t+1}$,我們必須知道 $t+1$ 是星期幾,是否為假日,以及 $t+1 這天的柳橙汁價格。 只要一查行事歷,就能輕鬆找出前兩項資訊。 零售價通常提前設定,因此柳橙汁的價格也許可以提前一天知道。 不過,未來 10 天的價格就不知道了! 請務必了解,此迴歸的效用受限於我們需要預測多久之後的未來,也就是預測範圍,以及我們對預測器未來值的了解程度。
重要
AutoML 的預測迴歸模型假設使用者提供的所有功能在未來都為已知,至少到預測範圍。
AutoML 的預測迴歸模型也可以擴增,以使用目標和預測器的記錄值。 結果將是具有時間序列模型特性和純迴歸模型的混合式模型。 記錄數量是迴歸中的其他預測器變數,我們稱其為延遲的數量。 延隔順序是指值已知的範圍。 例如,在柳橙汁需求範例中,目標順序二延隔的目前值是兩天前觀察到的果汁需求。
時間序列模型與迴歸模型之間的另一個顯著差異,就是其產生預測的方式。 時間序列模型通常由遞迴關聯定義,並一次產生一個預測。 為了預測未來的多個期間,它們會逐一查看直到預測範圍,將先前的預測饋送回模型,視需要產生下一個提前一個期間的預測。 相反地,迴歸模型即所謂的直接預測器,將一次產生直到範圍為止的所有預測。 直接預測工具最好是遞迴預測,因為遞迴模型在將先前的預測饋送回模型時會產生遞迴預測錯誤。 包含延隔特徵時,AutoML 會對定型資料進行一些重要的修改,讓迴歸模型可以做為直接預測器。 如需詳細資料,請參閱延隔特徵一文。
AutoML 中的預測模型
下表列出 AutoML 中實作的預測模型及其所屬類別:
| 時間序列模型 | 迴歸模型 |
|---|---|
| 貝氏、季節性貝氏、平均法、季節性平均、ARIMA(X)、指數平滑法 | 線性 SGD、LARS LASSO、彈性網、Prophet、K 最接近像素、決策樹、隨機樹系、極端隨機樹系、漸層提升樹系、LightGBM、XGBoost、TCNForecaster |
每個類別中的模型會按照其能納入的模式複雜度大致列出,也稱為模型容量。 貝利模型用於預測最後一個觀察到的值,具有低容量,而時態性卷積網路 (TCNForecaster) 則是可能有數百萬個可調整參數的深度神經網路,其容量很高。
重要的是,AutoML 也包含集團模型,這些模型會建立最佳執行模型的加權組合,以進一步改善精確度。 針對預測,我們使用軟投票集團,其透過 Caruana 集團選取項目演算法找到組合和加權。
注意
預測模型集團有兩個重要的注意事項:
- TCN 目前不能包含在集團中。
- AutoML 預設會停用另一個集團方法,堆疊集團,其隨附於 AutoML 中的預設迴歸和分類作業。 堆疊集團符合最佳模型預測的中繼模型,可用於尋找集團加權。 在內部基準中,我們發現此策略越來越傾向於過度符合時間序列資料。 這可能導致一般化不佳,因此預設將停用堆疊集團。 不過,如有需要,可以在 AutoML 設定中加以啟用。
AutoML 如何使用您的資料
AutoML 接受表格式「寬」格式的時間序列資料;也就是說,每個變數都必須有自己的對應資料行。 AutoML 需要其中一個資料行成為預測問題的時間軸。 此資料行必須可剖析為日期時間類型。 最簡單的時間序列資料集包含時間資料行和數值的目標資料行。 目標是一個用於預測未來的變數。 以下是此簡單案例中格式的範例:
| timestamp | 數量 |
|---|---|
| 2012-01-01 | 100 |
| 2012-01-02 | 97 |
| 2012-01-03 | 106 |
| ... | ... |
| 2013-12-31 | 347 |
在更複雜的情況下,資料可能包含與時間索引對齊的其他資料行。
| timestamp | SKU | price | 公告 | 數量 |
|---|---|---|---|---|
| 2012-01-01 | JUICE1 | 3.5 | 0 | 100 |
| 2012-01-01 | BREAD3 | 5.76 | 0 | 47 |
| 2012-01-02 | JUICE1 | 3.5 | 0 | 97 |
| 2012-01-02 | BREAD3 | 5.5 | 1 | 68 |
| ... | ... | ... | ... | ... |
| 2013-12-31 | JUICE1 | 3.75 | 0 | 347 |
| 2013-12-31 | BREAD3 | 5.7 | 0 | 94 |
在此範例中,除了時間戳記和目標數量之外,還有 SKU、零售價格和旗標,指出專案是否已公告。 此資料集中顯然有兩個序列 - 一個用於 JUICE1 SKU,另一個用於 BREAD3 SKU;SKU 資料行是一個時間序列識別碼資料行,因為它的分組會為每個群組提供兩個包含單一序列的群組。 在掃掠模型之前,AutoML 會先對輸入設定和資料進行基本驗證,並新增設計的功能。
資料長度需求
若要定型預測模型,您必須有足夠的歷史資料量。 此閾值數量會隨著定型設定而有所不同。 如果您已提供驗證資料,則要得到每個時間序列所需的定型觀察最低數目為,
$T_{\text{user validation}} = H + \text{max}(l_{\text{max}}, s_{\text{window}}) + 1$,
其中 $H$ 為預測範圍,$l_{\text{max}}$ 為最大延隔順序,而 $s_{\text{window}}$ 為滾動彙總功能的時段大小。 如果使用交叉驗證,則觀察最低數目為,
$T_{\text{CV}} = 2H + (n_{\text{CV}} - 1) n_{\text{step}} + \text{max}(l_{\text{max}}, s_{\text{window}}) + 1$,
其中 $n_{\text{CV}}$ 為交叉驗證折迭的數目,而 $n_{\text{step}}$ 為 CV 步驟大小,或 CV 折迭之間的位移。 這些公式背後的基本邏輯是,您應該一律在每個時間序列中至少要有定型觀察的範圍,包括延隔和交叉驗證分割的一些填補。 如需預測交叉驗證的詳細資訊,請參閱預測模型選取項目。
遺漏資料處理
AutoML 的時間序列模型需要定期間隔的觀察。 此處指的定期間隔包括每月或每年觀察結果等情況,其中觀察結果之間的天數可能會有所不同。 在模型化之前,AutoML 必須確定沒有遺漏的序列值,且觀察是一般的。 因此,有兩個遺漏的資料案例:
- 表格式資料中部分儲存格遺漏值
- 遺漏資料列,與指定時間序列頻率的預期觀察相對應
在第一個案例中,AutoML 使用一般、可設定的技術來插補遺漏的值。
下表顯示遺漏預期資料列的範例:
| timestamp | 數量 |
|---|---|
| 2012-01-01 | 100 |
| 2012-01-03 | 106 |
| 2012-01-04 | 103 |
| ... | ... |
| 2013-12-31 | 347 |
這個序列表面上有每日頻率,但沒有 2012 年 1 月 2 日的觀察。 在此情況下,AutoML 會嘗試在 2012 年 1 月 2 日新增資料列,以填入資料。 quantity 資料行的新值,以及資料中的其他任何資料行,接著會像其他遺漏值一樣進行插補。 顯然,AutoML 必須知道序列頻率,才能填入這樣的觀察間距。 AutoML 會自動偵測此頻率,或由使用者在設定中提供。
填入遺漏值的插補方法可以在輸入中設定。 下表列出預設方法:
| 資料行類型 | 預設插補方法 |
|---|---|
| Target | 前方填滿 (最後一次觀察往前推) |
| 數值功能 | 中位數 |
類別特徵的遺漏值會在數值編碼期間處理,方法是包含對應至遺漏值的其他類別。 在此案例中,插補是隱含的。
自動化特徵工程
AutoML 通常會將新的資料行新增至使用者資料,以提高模型化精確度。 專案功能可以包含下列專案:
| 功能群組 | 預設/選擇性 |
|---|---|
| 行事曆功能 衍生自時間索引 (例如,星期數) | 預設 |
| 衍生自時間序列識別碼的類別特徵 | 預設 |
| 將類別類型編碼為數值類型 | 預設 |
| 與指定國家或地區相關聯的假日指標功能 | 選擇性 |
| 目標數量延隔 | 選擇性 |
| 特徵資料行延隔 | 選擇性 |
| 目標數量的捲動時段彙總 (例如滾動平均) | 選擇性 |
| 季節性分解 (STL) | 選擇性 |
您可以從 AutoML SDK 透過 ForecastingJob 類別,或從 Azure Machine Learning Studio Web 介面設定特徵化。
非恆定時間序列偵測與處理
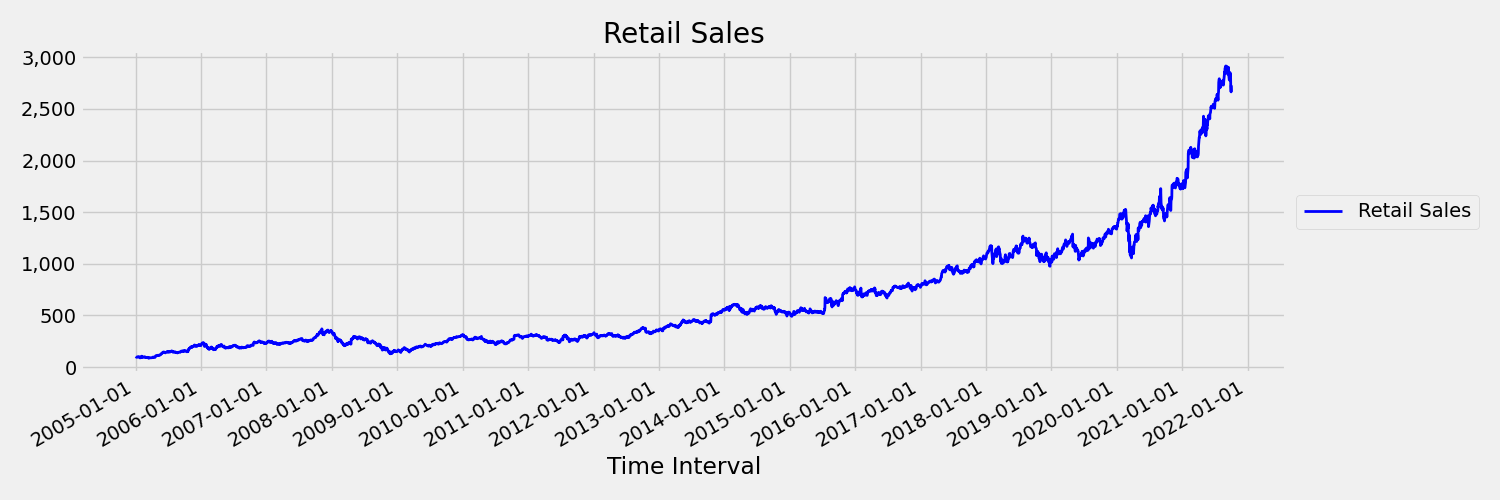
時間序列其平均值和變異數隨著時間的變化稱為非恆定。 例如,表現出隨機趨勢的時間序列本質上不是恆定的。 為了將此視覺化,下圖繪製一般向上趨勢的序列。 現在,計算和比較序列第一個和下半部的平均值 (平均)。 兩者相同嗎? 在這裡,繪圖前半部序列的平均值遠小於後半部序列的平均值。 序列的平均值取決於所查看的時間間隔,也就是時間變化動差的範例。 在這裡,序列的平均值是一級動差。
接下來,讓我們檢查下圖,以第一個差異繪製原始序列,$\Delta y_{t} = y_t - y_{t-1}$。 序列的平均值在時間範圍內大致是常數,而變異數似乎有所不同。 因此,這是一階恆定時間序列的範例。
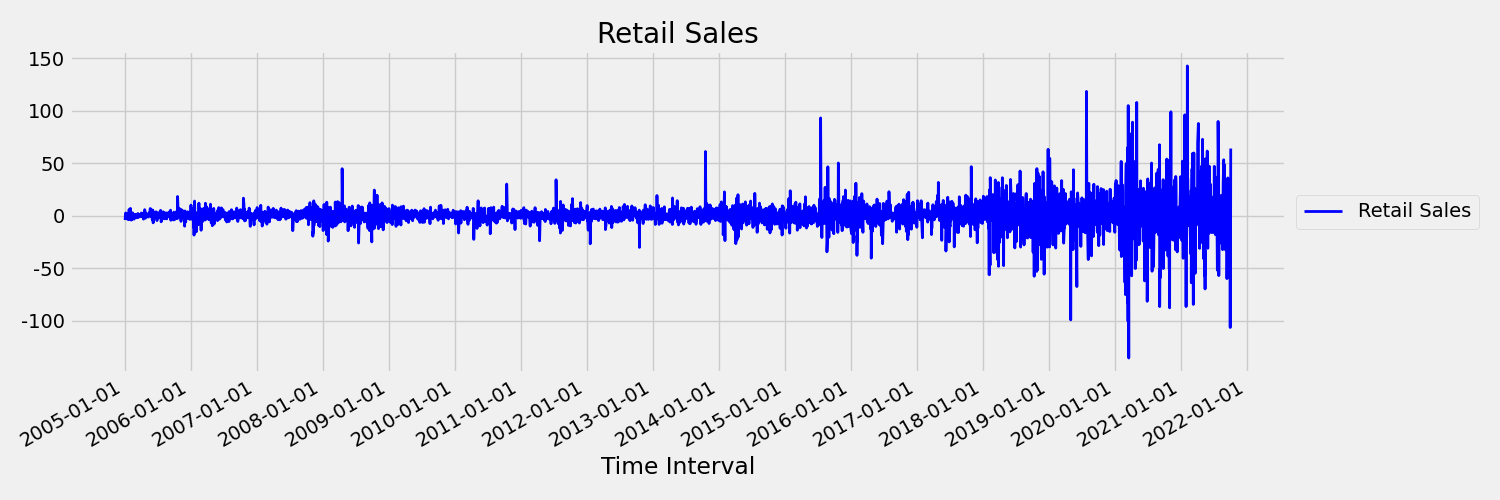
AutoML 迴歸模型原本就無法處理隨機趨勢,或與非恆定時間序列相關的其他已知問題。 因此,如果存在這類趨勢,其樣本外預測精確度就會「不佳」。
AutoML 會自動分析時間序列資料集,以判斷其是否恆定。 偵測到非恆定時間序列時,AutoML 會自動套用差異轉換,以減輕非恆定行為的影響。
模型掃掠
在準備遺漏資料處理和特徵工程的資料之後,AutoML 會使用 模型建議服務來掃掠一組模型和超參數。 模型會根據驗證或交叉驗證計量進行排名,然後選擇性地在集團模型中使用最上層模型。 您可以檢查、下載或部署最佳模型或任何定型模型,視需要產生預測。 如需詳細資訊,請參閱模型掃掠和選取項目一文。
模型群組
當資料集包含一個以上的時間序列時,如指定的資料範例所示,有多種方式可模型化該資料。 例如,我們可以只依時間序列識別碼資料行分組,並針對每個序列定型獨立模型。 更一般的做法是將資料分割成群組,每個群組可能包含多個可能相關的序列,並為每個群組定型模型。 根據預設,AutoML 預測會使用混合方法來建立群組模型。 時間序列模型加上 ARIMAX 和 Prophet,將一個序列指派給一個群組,而其他迴歸模型會將所有序列指派給單一群組。 下表摘要說明兩個類別的模型群組:一對一和多對一:
| 每個序列在自己的群組 (1:1) | 所有序列在單一群組中 (N:1) |
|---|---|
| 貝氏、季節性貝氏、平均法、季節性平均、指數平滑法、ARIMA、ARIMAX、Prophet | 線性 SGD、LARS LASSO、彈性網、K 最接近像素、決策樹、隨機樹系、極端隨機樹系、漸層提升樹系、LightGBM、XGBoost、TCNForecaster |
透過 AutoML 的許多模型解決方案,可以進行更一般模型分組:請參閱我們的許多模型 - 自動化 ML 筆記本。