AutoML 中預測的模型掃掠和選取項目
本文著重於 AutoML 如何搜尋及選取預測模型。 如需更多 AutoML 中關於預測方法的一般資訊,請參閱方法概觀一文。 如需在 AutoML 中定型預測模型的指示和範例,請參閱我們的設定 AutoML 以進行時間序列預測一文。
模型掃掠
AutoML 的核心工作是定型及評估數個模型,並選擇與指定主要計量相關的最佳模型。 這裡的「模型」一詞是指模型類別 (例如 ARIMA 或隨機樹系),以及區分類別內模型的特定超參數設定。 例如,ARIMA 是指共用數學範本和一組統計假設的模型類別。 定型 (或調整) ARIMA 模型需要一份正整數清單,以指定模型的精確數學形式;這些是超參數。 ARIMA(1, 0, 1) 和 ARIMA(2, 1, 2) 具有相同的類別,但卻有不同的超參數,因此可以分別配合定型資料並評估彼此。 AutoML 會以不同的超參數,在不同的模型類別和類別內進行搜尋或掃掠。
下表顯示 AutoML 用於不同模型類別的不同超參數掃掠方法:
| 模型類別群組 | 模型類型 | 超參數掃掠方法 |
|---|---|---|
| 樸素、季節樸素、平均、季節平均 | 時間序列 | 由於模型簡易性起見,類別內沒有掃掠 |
| 指數平滑法、ARIMA(X) | 時間序列 | 網格搜尋類別內掃掠 |
| Prophet | 迴歸 | 類別內沒有掃掠 |
| 線性 SGD、LARS LASSO、彈性網、K 最接近像素、決策樹、隨機樹系、極端隨機樹系、漸層提升樹系、LightGBM、XGBoost | 迴歸 | AutoML 的模型建議服務會動態探索超參數空間 |
| ForecastTCN | 迴歸 | 模型靜態清單,後接透過網路大小隨機搜尋、卸除比率和學習速率。 |
如需不同模型類型的描述,請參閱方法概觀一文的預測模型一節。
AutoML 執行的掃掠量取決於預測作業設定。 您可以將停止準則指定為時間限制或試用版數目的限制,或相當於模型的數目。 如果主要計量未改善,則可以在這兩種情況下,使用早期終止邏輯來停止掃掠。
模型選取
AutoML 預測模型搜尋和選取在下列三個階段中會繼續進行:
- 掃掠時間序列模型,並從每個類別使用處分的可能性方法選取最佳模型。
- 根據驗證集的主要計量值,掃掠迴歸模型並加以排名,以及第 1 階段的最佳時間序列模型。
- 從排名最上層的模型建置集成模型、計算其驗證計量,並將其與其他模型進行排名。
第 3 階段結束時最高排名計量值的模型會指定為最佳模型。
重要
AutoML 模型選取的最後階段一律會依據樣本外資料計算計量。 也就是說,未用來調整模型的資料。 這有助於防止過度調整。
AutoML 有兩個驗證組態 - 交叉驗證和明確的驗證資料。 在交叉驗證案例中,AutoML 會使用輸入組態來建立資料分割至定型和驗證摺疊。 時間順序必須保留在這些分割中,因此 AutoML 會使用所謂的滾動原點交叉驗證,使用原點時間點將序列分割成定型和驗證資料。 滑動時間原點即會產生交叉驗證摺疊。 每個驗證摺疊都包含緊接在指定摺疊原點位置之後的下一個觀察範圍。 此策略會保留時間序列資料完整性,並消除資訊洩漏的風險。
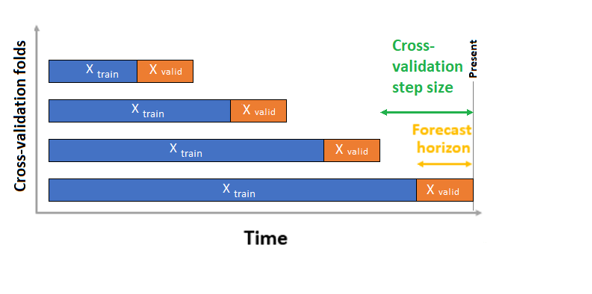
AutoML 遵循一般交叉驗證程序,在每個摺疊上定型個別的模型,並從所有摺疊平均驗證計量。
設定交叉驗證折摺疊,並選擇性地設定兩個連續交叉驗證摺疊之間的時間週期數,來設定預測作業的交叉驗證。 如需詳細資訊和設定交叉驗證預測的範例,請參閱自訂交叉驗證設定指南。
您也可以自備授權驗證資料。 您可以在在 AutoML (SDK v1) 中設定資料分割和交叉驗證一文中深入了解。
下一步
- 深入了解如何設定 AutoML 來定型時間序列預測模型。
- 瀏覽 AutoML 預測的常見問題集。
- 了解 AutoML 中時間序列預測的行事曆功能。
- 了解 AutoML 如何使用機器學習來建置預測模型。