AutoML 中預測的常見問題
適用於: Python SDK azure-ai-ml v2 (目前)
Python SDK azure-ai-ml v2 (目前)
本文回答有關自動化機器學習 (AutoML) 中預測的常見問題。 如需 AutoML 中關於預測方法的一般資訊,請參閱 AutoML 中的預測方法概觀一文。
如何開始在 AutoML 中建置預測模型?
您可以從閱讀設定 AutoML 以定型時間序列預測模型一文開始。 您也可以在數個 Jupyter 筆記本中找到實際操作範例:
為什麼 AutoML 在處理我的資料時速度很慢?
我們始終致力於讓 AutoML 更快、更具擴充性。 為了作為一般預測平台運作,AutoML 會執行廣泛的資料驗證和複雜的特徵工程,並搜尋大型模型空間。 這種複雜性可能需要大量時間,具體取決於資料和設定。
執行階段緩慢的一個常見原因,是使用包含大量時間序列之資料的預設設定來定型 AutoML。 許多預測方法的成本會隨著序列數目進行調整。 例如,指數平滑和 Prophet 等方法訓練定型資料中每個時間序列的模型。
AutoML 的許多模型功能會透過將定型作業分散到計算叢集,針對這些案例進行調整。 它已成功應用於具有數百萬個時間序列的資料。 如需詳細資訊,請參閱許多模型一節。 您也可以在備受矚目的競賽資料集上閱讀許多模型的成功 (英文)。
如何讓 AutoML 更快?
請參閱為什麼 AutoML 在處理我的資料時速度很慢?解答,以了解您的案例中 AutoML 可能變慢的原因。
請考慮下列可能加速作業的設定變更:
- 封鎖時間序列模型,例如 ARIMA 和 Prophet。
- 關閉延遲和滾動視窗等回查功能。
- 減少:
- 試用/反覆項目的數目。
- 試用/反覆項目逾時。
- 實驗逾時。
- 交叉驗證折疊的數目。
- 請確定已啟用提早終止。
我應該使用什麼模型設定?
AutoML 預測支援四個基本設定:
| 組態 | 案例 | 優點 | 缺點 |
|---|---|---|---|
| 預設 AutoML | 如果資料集有少量時間序列,且具有大致類似的歷程記錄行為,則建議使用。 | - 可透過程式碼/SDK 或 Azure Machine Learning 工作室輕鬆設定。 - AutoML 可以跨不同時間序列進行學習,因為迴歸模型會在定型中將所有序列集結在一起。 如需詳細資訊,請參閱模型群組。 |
- 如果定型資料中的時間序列具有不同的行為,則迴歸模型可能不太準確。 - 如果定型資料有大量的序列,時間序列模型可能需要很長的時間才能定型。 如需詳細資訊,請參閱為什麼 AutoML 在處理我的資料時速度很慢?解答。 |
| 使用深度學習的 AutoML | 建議用於具有超過 1,000 個觀測值、且可能存在大量呈現複雜模式之時間序列的資料集。 啟用後,AutoML 將在定型期間掃描時間卷積神經網路 (TCN) 模型。 如需詳細資訊,請參閱啟用深度學習。 | - 可透過程式碼/SDK 或 Azure Machine Learning 工作室輕鬆設定。 - 交叉學習機會,因為 TCN 集結了所有系列的資料。 - 由於深度神經網路 (DNN) 模型的容量龐大,因此精確度可能更高。 如需詳細資訊,請參閱 AutoML 中的預測模型。 |
- 由於 DNN 模型的複雜性,定型可能需要更長的時間。 - 歷程記錄太少的系列不太可能受益於這些模型。 |
| 許多模型 | 如果您需要以可調整的方式定型和管理大量預測模型,則建議使用。 如需詳細資訊,請參閱許多模型一節。 | - 可調整。 - 當時間序列彼此之間存在不同行為時,準確度可能會更高。 |
- 無法跨時間序列進行學習。 - 無法從 Azure Machine Learning 工作室設定或執行許多模型作業。 目前僅提供程式碼/SDK 體驗。 |
| 階層式時間序列 (HTS) | 如果您資料中的序列具有巢狀、階層式結構,而且您需要在階層的彙總層級定型或進行預測,則建議使用。 如需詳細資訊,請參閱階層式時間序列預測一節。 | - 在彙總層級進行定型可以降低分葉節點時間序列中的雜訊,並可能產生較高精確度的模型。 - 您可以透過彙總或分解定型層級的預測,以擷取階層任何層級的預測。 |
- 您需要提供定型的匯總層級。 AutoML 目前沒有演算法可尋找最佳層級。 |
注意
當深度學習啟用時,建議您搭配 GPU 使用計算節點,以充分利用高 DNN 容量。 相較於只有 CPU 的節點,定型時間可能更快。 如需詳細資訊,請參閱 GPU 最佳化的虛擬機器大小一文。
注意
HTS 是針對階層中需要在彙總層級進行定型或預測的工作而設計。 對於只需要分葉節點定型和預測的階層式資料,請改用許多模型。
如何防止過度學習和資料外洩?
AutoML 會使用機器學習最佳做法,例如交叉驗證的模型選取,以減輕許多過度學習的問題。 不過,還有其他潛在的過度學習來源:
輸入資料包含從目標衍生的特徵資料行,其中包含簡單公式。 例如,精確倍數為目標的特徵可以產生近乎完美的定型分數。 不過,模型可能不會一般化為樣本外資料。 建議您在模型定型之前探索資料,並卸除「洩漏」目標資訊的資料行。
定型資料會使用未來未知的特徵,最多到預測範圍。 AutoML 的迴歸模型目前假設預測範圍已知所有特徵。 建議您在定型之前先探索您的資料,並刪除僅歷程已知的任何特徵資料行。
資料的定型、驗證或測試部分之間有顯著的結構差異 (機制變更)。 例如,假設 COVID-19 疫情對 2020 年和 2021 年期間幾乎所有商品需求的影響。 這是機制變更的經典範例。 由於機制變更而導致的過度學習是最具挑戰性的問題,因為它高度依賴案例,而且可能需要深入了解才能識別。
作為第一道防線,請嘗試保留總歷程記錄的 10% 到 20% 進行驗證資料或交叉驗證資料。 如果定型歷程記錄較短,則不一定可以保留這麼多的驗證資料,但這是最佳做法。 如需詳細資訊,請參閱定型和驗證資料。
如果我的定型作業達到完美的驗證分數,那是什麼意思?
當您檢視定型作業的驗證指標時,可能會看到完美的分數。 完美分數表示驗證集上的預測和實際值相同 (或幾乎相同)。 例如,您的根平均平方誤差等於 0.0,或 R2 分數為 1.0。
完美的驗證分數「通常」表示模型嚴重過度學習,可能是因為資料外洩。 最好的作法是檢查資料是否有洩漏,並刪除導致洩漏的資料行。
如果我的時間序列資料沒有定期間隔的觀察結果,該怎麼辦?
AutoML 的預測模型都需要定型資料具有參考行事曆的定期間隔觀察結果。 這項要求包括每月或每年觀察結果等情況,其中觀察結果之間的天數可能會有所不同。 在兩種情況下,時間相依資料可能不符合此要求:
資料具有明確定義的頻率,但遺漏的觀察結果在該序列中產生間距。 在此情況下,AutoML 會嘗試偵測頻率、針對間距填入新的觀察結果,以及插補遺漏的目標和特徵值。 或者,使用者可以透過 SDK 設定或 Web UI 來設定插補方法。 如需詳細資訊,請參閱自訂特徵化。
資料沒有明確定義的頻率。 也就是說,觀察結果之間的持續時間沒有明顯的模式。 交易資料 (例如來自銷售點系統的資料) 就是一個例子。 在此情況下,您可以將 AutoML 設定為依所選的頻率彙總資料。 您可以選擇最適合資料和模型目標的一般頻率。 如需詳細資訊,請參閱資料匯總。
如何選擇主要計量?
主要計量很重要,因為它在驗證資料上的值會決定掃掠和選取期間的最佳模型。 正規化根均方誤差 (NRMSE) 和正規化平均絕對誤差 (NMAE) 通常是預測作業中,主要計量的最佳選擇。
若要在它們之間進行選擇,請注意,NRMSE 對定型資料中的極端值的懲罰比 NMAE 更多,因為它會使用誤差的平方。 如果您希望模型對極端值較不敏感,NMAE 可能是更好的選擇。 如需詳細資訊,請參閱迴歸和預測計量。
注意
我們不建議使用 R2 分數 (或 R2) 作為預測的主要計量。
注意
AutoML 不支援主要計量的自訂或使用者提供函式。 您必須選擇 AutoML 支援的其中一個預先定義主要計量。
如何改善模型的精確度?
- 請確定您以最適合資料的方式設定 AutoML。 如需詳細資訊,請參閱我應該使用哪些模型設定?解答。
- 如需如何建置和改善預測模型的逐步指南,請參閱預測食譜筆記本 (英文)。
- 使用數個預測週期的反向測試來評估模型。 此程序提供更健全的預測誤差估計值,並為您提供測量改進的基準。 如需範例,請參閱回測筆記本 (英文)。
- 如果資料有雜訊,請考慮將其彙總到較粗的頻率以提高訊號雜訊比。 如需詳細資訊,請參閱頻率和目標資料彙總。
- 新增可協助預測目標的新特徵。 當您選取定型資料時,主題專業知識可提供很大幫助。
- 比較驗證和測試計量值,並判斷選取的模型是否正在學習或過度學習資料。 此知識可引導您進行更好的定型設定。 例如,您可能會判斷需要使用更多交叉驗證折疊來回應過度學習。
AutoML 一律會從相同的定型資料和設定中選取相同的最佳模型嗎?
AutoML 的模型搜尋程序不具決定性,因此它不一定會從相同的資料和設定中選取相同的模型。
如何修復記憶體不足錯誤?
有兩種類型的記憶體錯誤:
- RAM 記憶體不足
- 磁碟記憶體不足
首先,請確定您以最適合您資料的方式設定 AutoML。 如需詳細資訊,請參閱我應該使用哪些模型設定?解答。
針對預設的 AutoML 設定,您可以使用具有更多 RAM 的計算節點來修正 RAM 記憶體不足錯誤。 一般規則是,可用 RAM 的數量至少應大於原始資料大小 10 倍,才能使用預設設定來執行 AutoML。
您可以藉由刪除計算叢集並建立新的叢集,來解決磁碟記憶體不足錯誤。
AutoML 支援哪些進階預測案例?
AutoML 支援下列進階預測案例:
- 分位數預測
- 透過滾動預測進行健全的模型評估
- 超出預測範圍的預測
- 當定型和預測期間之間存在時間間隔時進行預測
如需範例和詳細資料,請參閱進階預測案例的筆記本 (英文)。
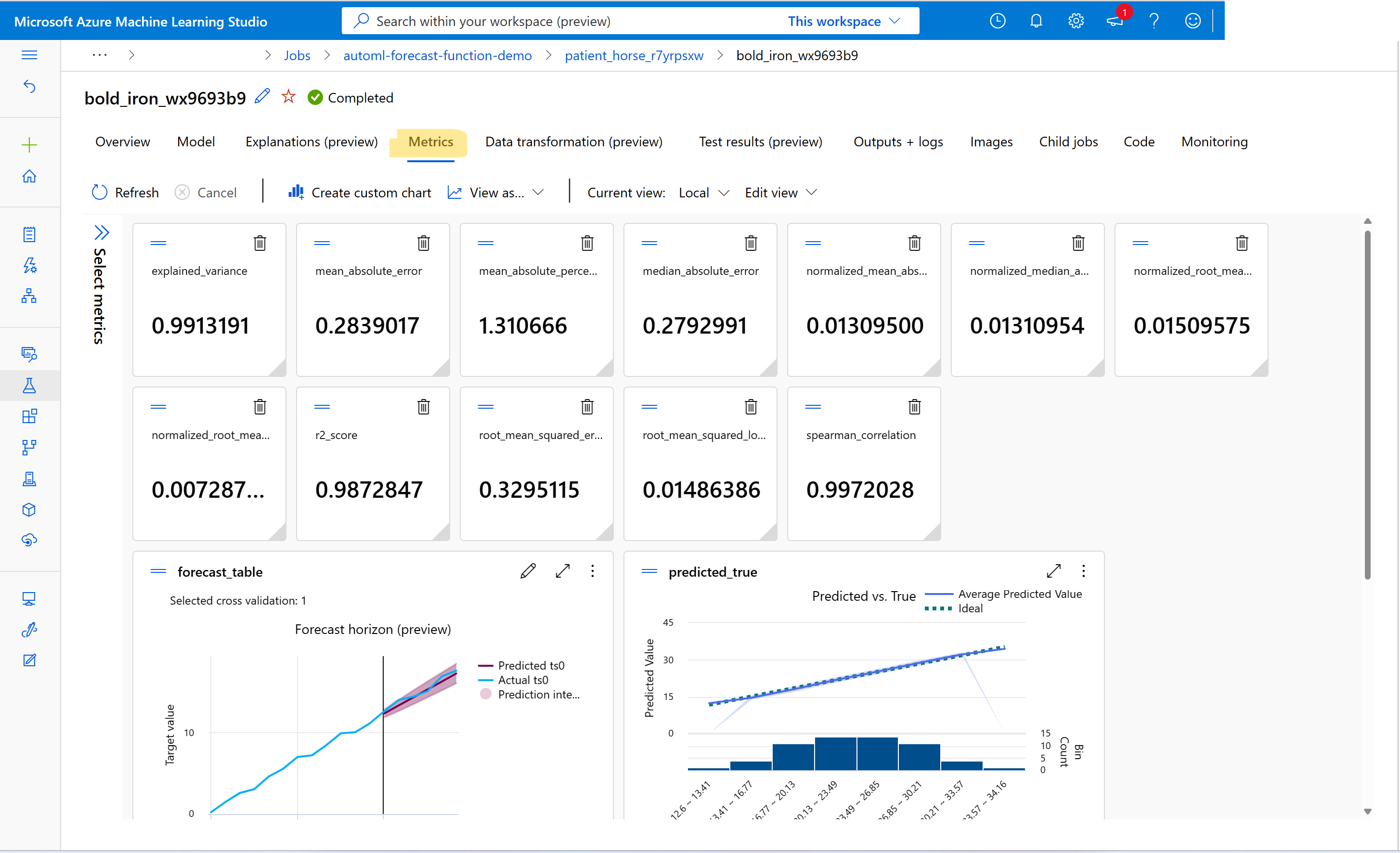
如何檢視預測定型作業的計量?
若要尋找定型和驗證計量值,請參閱在工作室中檢視作業/執行資訊。 您可以從工作室中的 AutoML 作業 UI 前往模型,並選擇 [計量] 索引標籤來查看 AutoML 中定型之任何預測模型的指標。
如何偵錯預測定型作業的失敗?
如果您的 AutoML 預測作業失敗,工作室 UI 上的錯誤訊息可協助您診斷並修正問題。 除了錯誤訊息之外,有關失敗的最佳資訊來源是作業的驅動程式記錄檔。 如需尋找驅動程式記錄檔的指示,請參閱使用 MLflow 檢視作業/執行資訊。
注意
對於許多模型或 HTS 作業,定型通常是在多節點計算叢集上進行。 每個節點 IP 位址都有這些作業的記錄檔。 在此情況下,您必須在每個節點中搜尋錯誤記錄檔。 錯誤記錄檔以及驅動程式記錄檔位於每個節點 IP 的 user_logs 資料夾中。
如何部署預測定型作業的模型?
您可以透過下列其中一種方式,從預測定型作業部署模型:
- 線上端點:檢查部署中使用的評分檔案,或選取工作室中端點頁面上的 [測試] 索引標籤,以了解部署預期的輸入結構。 如需範例,請參閱此筆記本 (英文)。 如需線上部署的詳細資訊,請參閱將 AutoML 模型部署到線上端點。
- 批次端點:此部署方法會要求您開發自訂評分指令碼。 如需範例,請參閱此筆記本 (英文)。 如需批次部署的詳細資訊,請參閱使用批次端點進行批次評分。
針對 UI 部署,建議您使用下列其中一個選項:
- 即時端點
- 批次端點
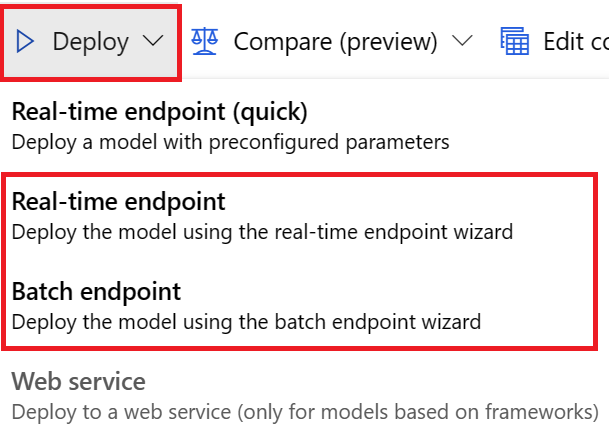
請勿使用第一個選項 Real-time-endpoint (quick)。
注意
到目前為止,我們不支援透過 SDK、CLI 或 UI 從預測定型作業來部署 MLflow 模型。 如果您嘗試的話,就會收到錯誤。
什麼是工作區、環境、實驗、計算執行個體或計算目標?
如果您不熟悉 Azure Machine Learning 概念,請從什麼是 Azure Machine Learning?和什麼是 Azure Machine Learning 工作區?文章開始。