Tip
Power BI Dataflow Gen1 現在處於舊版狀態,不會再投資新功能。 對於具備 Fabric 存取權的高級用戶, Dataflow Gen2 是推薦的路徑,提供效能、規模、可靠性、功能性及內建 AI 的提升。 Pro/PPU 客戶可以繼續使用 Gen1,因為 Gen2 在這類情境下的指引正在演進中。 請參閱從 Dataflow Gen1 升級到 Dataflow Gen2 以獲得升級指引。
資料流程實作的最佳實務之一是將資料流的責任分為兩層:資料擷取與資料轉換。 這種模式特別適合處理同一資料流中多個較慢資料來源的查詢,或多個資料流查詢同一資料來源時。 與其每次查詢都從緩慢的資料來源重複取得資料,資料擷取過程只需完成一次,轉換則可在此過程之上進行。 本文將說明這個過程。
本地資料來源
在許多情況下,本地資料來源是緩慢的資料來源。 尤其考慮到閘道作為資料流與資料來源之間的中間層。
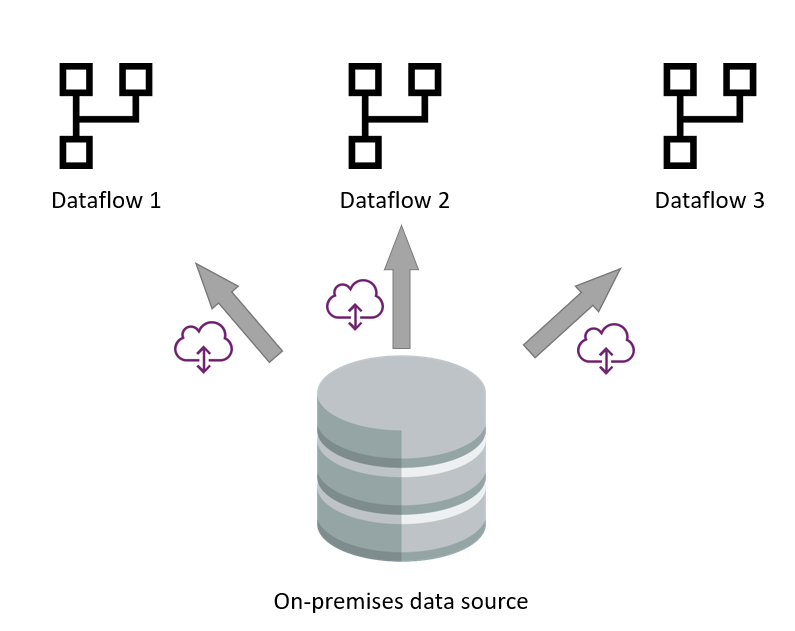
使用分析資料流進行資料擷取,能減少從來源取得資料的過程,並專注於將資料載入 Azure Data Lake Storage。 一旦進入儲存空間,就可以建立其他資料流,利用擷取資料流的輸出。 資料流引擎可以直接從資料湖讀取資料並進行轉換,無需聯絡原始資料來源或閘道器。
緩慢資料來源
當資料來源緩慢時,同樣的過程也適用。 部分軟體即服務(SaaS)資料來源因 API 呼叫限制而表現緩慢。
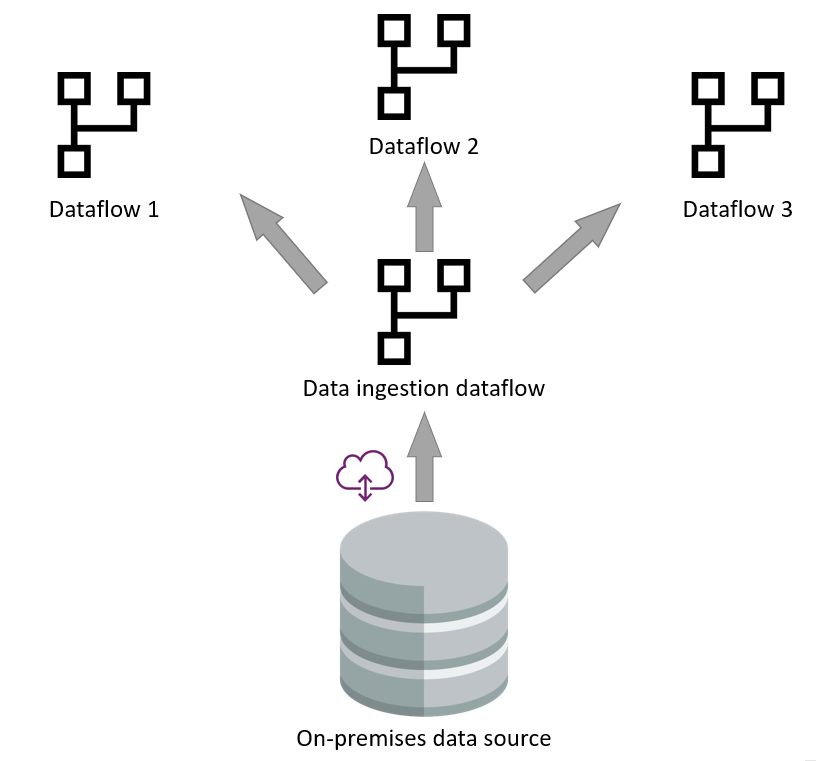
資料擷取與資料轉換資料流的分離
將資料擷取與轉換兩層分開,在資料來源緩慢的情境下非常有幫助。 這有助於減少與資料來源的互動。
這種分離不僅因為效能提升而有用,對於舊有資料來源系統遷移到新系統的情況也很有幫助。 在這些情況下,只需更改資料擷取資料流。 資料轉換資料流在此類變更時保持完整。
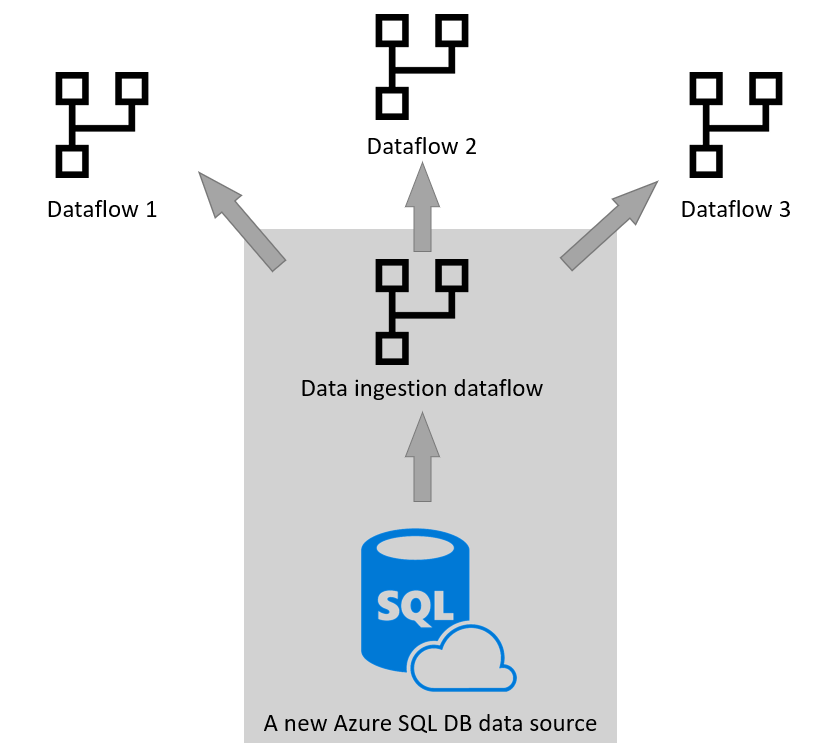
在其他工具與服務中的重複利用
將資料擷取資料流與資料轉換資料流分離,在許多情境下都很有幫助。 另一個使用情境是當你想在其他工具和服務中使用這些資料時。 為此,最好使用分析性資料流,並以自己的 Data Lake Storage 作為儲存引擎。 更多資訊: 分析資料流
優化資料引入流程
盡可能考慮優化資料擷取資料流。 舉例來說,如果不需要所有來源資料,且資料來源支援查詢摺疊,那麼過濾資料並只取得必要的子集是個不錯的方法。 想了解更多關於查詢摺疊的資訊,請參考 Power Query 中的查詢評估與查詢摺疊概覽。
建立資料匯入資料流作為分析資料流
考慮將資料擷取資料流建立為分析性資料流。 這特別有助於其他服務和應用程式利用這些資料。 這也讓資料轉換資料流更容易從分析性資料匯入資料流取得資料。 欲了解更多,請前往 分析資料流。