推出 SQL Server 巨量資料叢集
適用於:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
重要
Microsoft SQL Server 2019 巨量資料叢集附加元件將會淘汰。 SQL Server 2019 巨量資料叢集的支援將於 2025 年 2 月 28 日結束。 平台上將完全支援含軟體保證 SQL Server 2019 的所有現有使用者,而且軟體將會持續透過 SQL Server 累積更新來維護,直到該時間為止。 如需詳細資訊,請參閱公告部落格文章與 Microsoft SQL Server 平台上的巨量資料選項。
在 SQL Server 2019 (15.x) 中,SQL Server 巨量資料叢集可讓您部署在 Kubernetes 上執行的 SQL Server、Spark 和 HDFS 容器可調整叢集。 這些元件會並存執行,可供您讀取、寫入和處理來自 Transact-SQL 或 Spark 的巨量資料,讓您輕鬆地結合與分析具有大量巨量資料的高價值關聯式資料。
開始使用
- 首先,請參閱開始使用 SQL Server 巨量資料叢集
- 若要了解最新版本的新功能,請參閱版本資訊
- 如需常見問題集,請參閱巨量資料叢集常見問題集
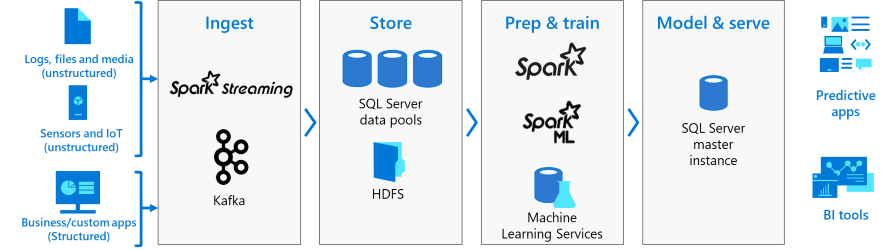
巨量資料叢集架構
下圖顯示 SQL Server 巨量資料叢集的元件:

控制器
控制器會提供叢集的管理和安全性。 其中包含控制項服務、設定存放區,以及其他叢集層級的服務 (例如 Kibana、Grafana 和彈性搜尋)。
計算集區
計算集區會將計算資源提供給叢集。 其中包含在 Linux Pod 上執行 SQL Server 的節點。 計算集區中的 Pod 會分割成 SQL 計算執行個體,以進行特定的處理工作。
資料集區
資料集區用於資料持續性。 資料集區由在 Linux 上執行 SQL Server 的一或多個 Pod 所組成。 用於從 SQL 查詢或 Spark 作業中內嵌資料。
儲存體集區
存放集區包含由 Linux 上的 SQL Server、Spark 和 HDFS 組成的存放集區 Pod。 SQL Server 巨量資料叢集中的所有存放裝置節點都是 HDFS 叢集成員。
提示
若要深入了解叢集架構和安裝,請參閱工作坊:Microsoft SQL Server 巨量資料叢集架構。
應用程式集區
應用程式部署提供了建立、管理和執行應用程式的介面,藉以在 SQL Server 巨量資料叢集上部署應用程式。
案例和功能
SQL Server 巨量資料叢集可讓您靈活地與您的巨量資料互動。 您可以查詢外部資料源、在 SQL Server 管理的 HDFS 中儲存巨量資料,或透過叢集查詢來自多個外部資料源的資料。 接著您可以使用 AI、機器學習服務和其他分析工作的資料。
使用 SQL Server 巨量資料叢集可執行下列動作:
- 為 Kubernetes 上執行的 SQL Server、Spark 和 HDFS 容器部署可擴充叢集。
- 讀取、寫入及處理來自 Transact-SQL 或 Spark 的巨量資料。
- 輕鬆結合及分析含有大量巨量資料的高價值關聯式資料。
- 查詢外部資料來源。
- 在 SQL Server 的受控 HDFS 中儲存巨量資料。
- 透過叢集查詢來自多個外部資料來源的資料。
- 使用 AI、機器學習和其他分析工作的資料。
- 在巨量資料叢集中部署及執行應用程式。
- 使用 PolyBase 將資料虛擬化。 使用外部資料表來查詢來自外部 SQL Server、Oracle、Teradata、MongoDB 和一般 ODBC 資料來源的資料。
- 使用 Always On 可用性群組技術,為 SQL Server 主要執行個體和所有資料庫提供高可用性。
下列各節提供這些案例的詳細資訊。
資料虛擬化
SQL Server 巨量資料叢集可利用 PolyBase 來查詢外部資料來源,而不需移動或複製資料。 SQL Server 2019 (15.x) 導入了新的資料來源連接器,如需詳細資訊,請參閱 PolyBase 2019 的新功能。
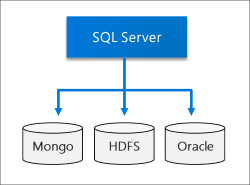
Data Lake
SQL Server 巨量資料叢集包含可調整的 HDFS「存放集區」 。 這可以用來儲存可能內嵌自多個外部來源的巨量資料。 當巨量資料儲存在巨量資料叢集中的 HDFS 之後,您就可以分析及查詢資料,並將其與關聯式資料結合。
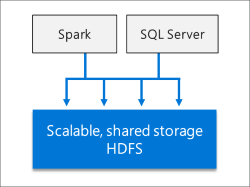
整合的 AI 與機器學習
SQL Server 巨量資料叢集會針對儲存在 HDFS 存放集區和資料集區中的資料啟用 AI 和機器學習工作。 您可以利用 R、Python、Scala 或 Java,在 SQL Server 中使用 Spark 和內建 AI 工具。
管理與監控
管理和監視是透過命令列工具、API、入口網站和動態管理檢視的組合來提供的。
您可以使用 Azure Data Studio 對巨量資料叢集執行各種工作:
- 常見管理工作的內建程式碼片段。
- 能夠瀏覽 HDFS、上傳檔案、預覽檔案及建立目錄。
- 能夠建立、開啟並執行與 Jupyter 相容的筆記本。
- 資料虛擬化精靈可簡化外部資料來源的建立流程 (由資料虛擬化延伸模組啟用)。
Kubernetes 概念
SQL Server 巨量資料叢集是由 Kubernetes 協調的 Linux 容器叢集。
Kubernetes 是開放原始碼容器協調器,可根據需求調整容器部署。 下表定義一些重要的 Kubernetes 術語:
| 詞彙 | 描述 |
|---|---|
| Cluster | Kubernetes 叢集是稱為節點的一組電腦。 其中一個節點會控制叢集,並受指定為主要節點,而其餘節點為背景工作節點。 Kubernetes 主要節點負責在背景工作節點間散發工作,並監視叢集的健康狀態。 |
| 節點 | 節點會執行容器化應用程式。 節點可以是實體電腦或虛擬機器。 Kubernetes 叢集可包含實體機器和虛擬機器節點的混合。 |
| Pod | Pod 是 Kubernetes 的不可部分完成部署單位。 Pod 是執行應用程式所需一或多個容器以及相關聯資源的邏輯群組。 每個 Pod 都會在一個節點上執行,每個節點可以執行一或多個 Pod。 Kubernetes 主機會自動將 Pod 指派給叢集中的節點。 |
在 SQL Server 巨量資料叢集中,Kubernetes 負責處理叢集的狀態。 Kubernetes 會建置及設定叢集節點、將 Pod 指派給節點,並監視叢集的健康情況。
後續步驟
如需部署 SQL Server 巨量資料叢集的詳細資訊,請參閱開始使用 SQL Server 巨量資料叢集。
然後,開始載入資料並執行 Spark 作業。
深入了解
了解相關技術的課程模組:
意見反應
即將推出:在 2024 年,我們將隨著內容的意見反應機制逐步淘汰 GitHub 問題,並以新的意見反應系統來取代。 如需詳細資訊,請參閱 https://aka.ms/ContentUserFeedback。
提交並檢視相關的意見反應