使用 Spark 執行範例筆記本
適用於:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
重要
Microsoft SQL Server 2019 巨量資料叢集附加元件將會淘汰。 SQL Server 2019 巨量資料叢集的支援將於 2025 年 2 月 28 日結束。 平台上將完全支援含軟體保證 SQL Server 2019 的所有現有使用者,而且軟體將會持續透過 SQL Server 累積更新來維護,直到該時間為止。 如需詳細資訊,請參閱公告部落格文章與 Microsoft SQL Server 平台上的巨量資料選項。
本教學課程示範如何在 SQL Server 2019 巨量資料叢集上,將筆記本載入 Azure Data Studio 中並執行。 這可讓資料科學家和資料工程師對叢集執行 Python、R 或 Scala 程式碼。
提示
如果您想要的話,也可以下載並執行用於本教學課程中命令的指令碼。 如需指示,請參閱 GitHub 上的 Spark 範例。
必要條件
- 巨量資料工具
- kubectl
- Azure Data Studio
- SQL Server 2019 延伸模組
- 將範例資料載入巨量資料叢集
下載範例筆記本檔案
使用下列指示,將範例筆記本檔案 spark-sql.ipynb 載入 Azure Data Studio。
開啟 Bash 命令提示字元 (Linux) 或 Windows PowerShell。
巡覽至您要下載範例筆記本檔案的目錄。
執行下列 curl 命令,從 GitHub 下載筆記本檔案:
curl https://raw.githubusercontent.com/Microsoft/sql-server-samples/master/samples/features/sql-big-data-cluster/spark/data-loading/transform-csv-files.ipynb -o transform-csv-files.ipynb
開啟 Notebook
下列步驟說明如何在 Azure Data Studio 中開啟筆記本檔案:
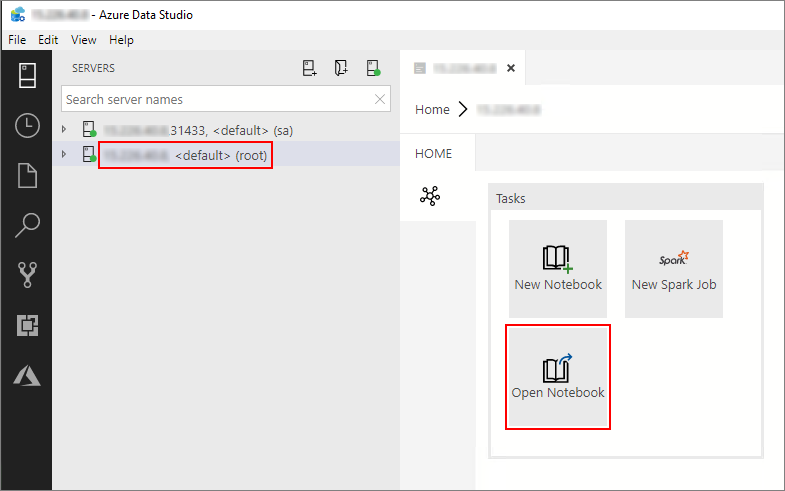
在 Azure Data Studio 中,連線到巨量資料叢集的主要執行個體。 如需詳細資訊,請參閱連線到巨量資料叢集。
按兩下 [伺服器] 視窗中的 HDFS/Spark 閘道連線。 然後選取 [開啟筆記本]。
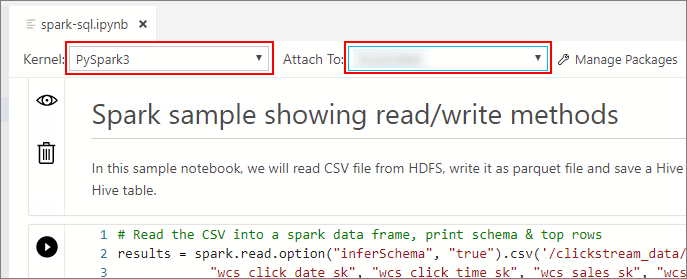
等候 [核心] 和目標內容 ([附加至] ) 填入。 將 [核心] 設定為 [PySpark3],並將 [附加至] 設定為巨量資料叢集端點的 IP 位址。
重要
在 Azure Data Studio 中,所有 Spark 筆記本類型 (Scala Spark、PySpark 和 SparkR) 通常都會在第一次儲存格執行時定義一些重要的 Spark 工作階段相關變數。 這些變數包括:spark、sc 和 sqlContext。 從筆記本複製邏輯以進行批次提交時 (例如,複製到要使用 azdata bdc spark batch create 執行的 Python 檔案中),請確實據以定義變數。
執行筆記本資料格
您可以按下資料格左側的播放按鈕,執行每個筆記本資料格。 資料格完成執行之後,會在筆記本中顯示結果。

連續執行範例筆記本中的每個資料格。 如需搭配使用筆記本與 SQL Server 巨量資料叢集的詳細資訊,請參閱下列資源:
後續步驟
深入了解筆記本:
意見反應
即將登場:在 2024 年,我們將逐步淘汰 GitHub 問題作為內容的意見反應機制,並將它取代為新的意見反應系統。 如需詳細資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交並檢視相關的意見反應