「練習 - 撰寫 Azure Data Factory 對應資料流」
使用對應資料流來轉換資料
您可以使用「對應資料流」工作,透過 Azure Data Factory 程式碼以原生方式執行資料轉換,無須使用程式碼。 對應資料流可提供完整的視覺效果,而且不需要撰寫程式碼。 您的資料流程會在您自己的執行叢集上執行,以便進行擴充的資料處理作業。 資料流程活動可以透過現有的 Data Factory 排程、控制、流程和監視功能來運作。
建立資料流程時,您可以啟用偵錯模式,藉此開啟小型的互動式 Spark 叢集。 切換撰寫模組頂端的滑桿即可開啟偵錯模式。 偵錯叢集需要幾分鐘的時間來準備,但可用來以互動方式預覽轉換邏輯的輸出。

新增對應資料流並執行 Spark 叢集後,您就可以執行轉換,以及執行和預覽資料。 您不需要撰寫程式碼,因為 Azure Data Factory 會處理所有的程式碼轉譯、路徑最佳化,並且執行您的資料流程工作。
將來源資料新增至對應資料流
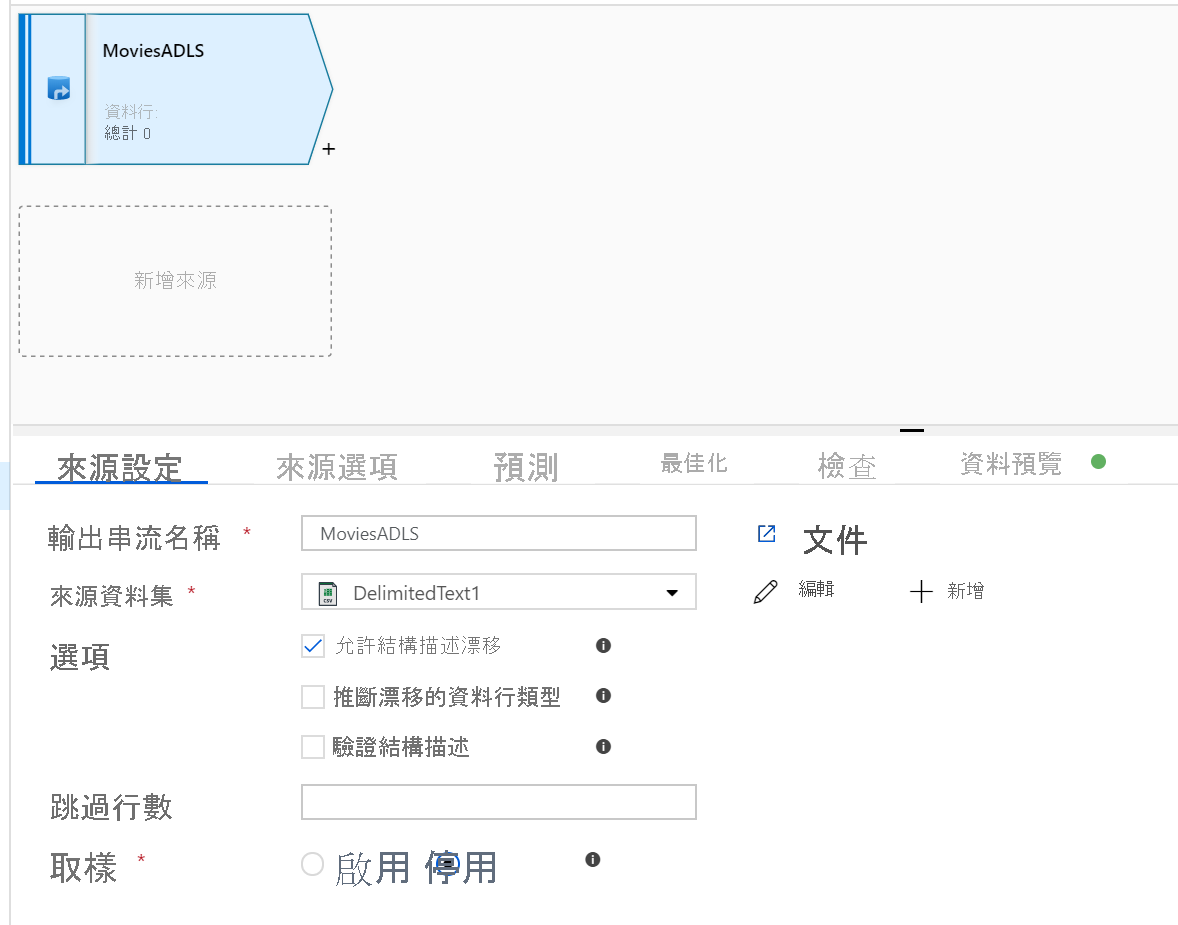
開啟 [對應資料流] 畫布。 在 [資料流程] 畫布中,按一下 [新增來源] 按鈕。 在 [來源資料集] 下拉式清單中選取您的資料來源;在此範例中是使用 ADLS Gen2 資料集
有幾點需要注意:
- 如果您的資料集指向的資料夾包含其他檔案,但您只想要使用一個檔案,您可能需要另外建立一個資料集,或利用參數化來確保只讀取特定檔案
- 如果您尚未在 ADLS 中匯入結構描述,但已內嵌您的資料,請前往資料集的 [結構描述] 索引標籤,然後按一下 [匯入結構描述],讓資料流程知道結構描述預測。
對應資料流會遵循擷取、載入、轉換 (ELT) 方法,而且適用於完全位於 Azure 中的暫存資料集。 目前有下列資料集可用於來源轉換:
- Azure Blob 儲存體 (JSON、Avro、Text、Parquet)
- Azure Data Lake Storage Gen1 (JSON、Avro、Text、Parquet)
- Azure Data Lake Storage Gen2 (JSON、Avro、Text、Parquet)
- Azure Synapse Analytics
- Azure SQL Database
- Azure Cosmos DB
Azure Data Factory 可以存取超過 80 種原生連接器。 若要納入資料流程中其他來源的資料,請使用 [複製活動] 將該資料載入其中一個受支援的暫存區域。
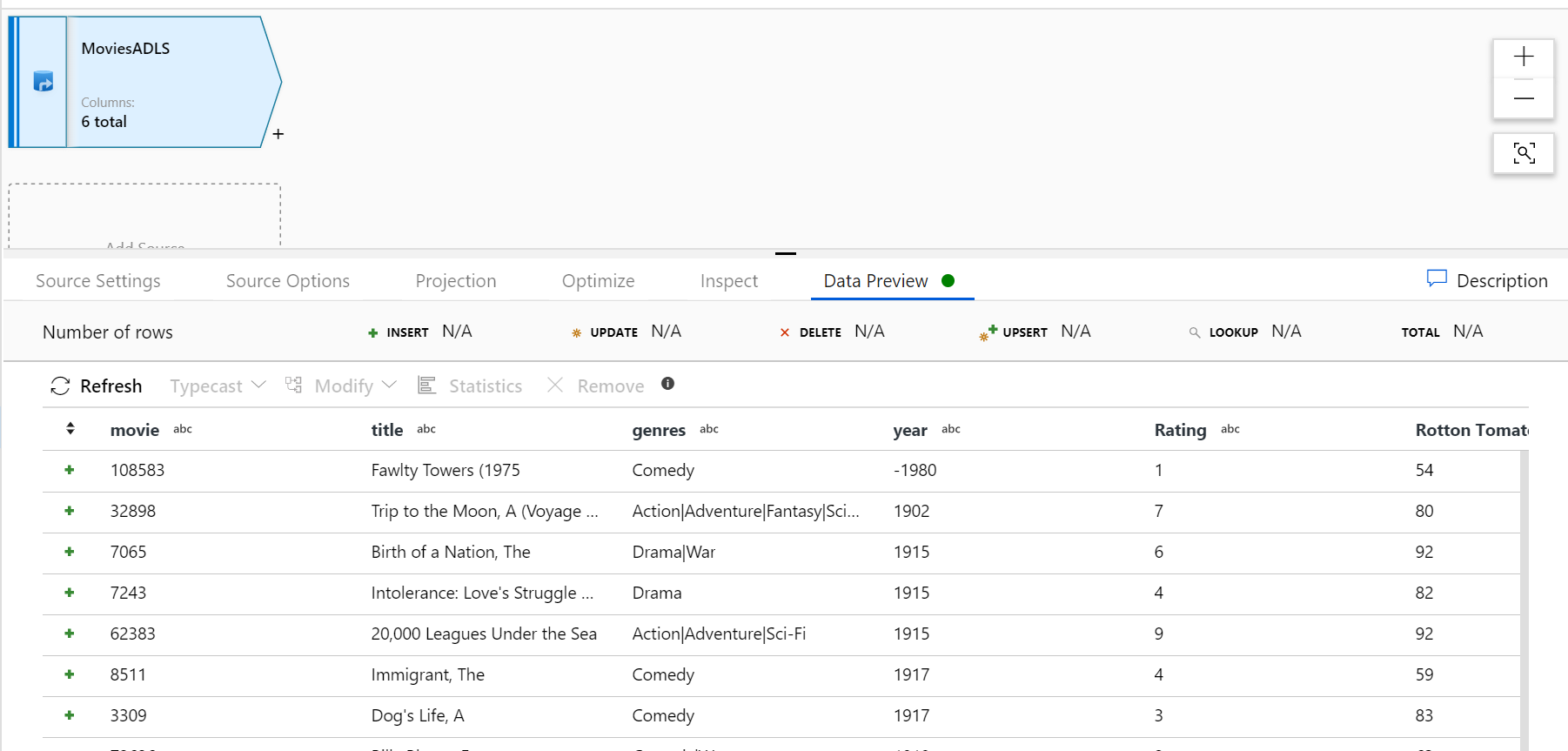
偵錯叢集準備就緒之後,請透過 [資料預覽] 索引標籤確認您的資料已正確載入。一旦按一下 [重新整理] 按鈕,對應資料流就會顯示您的資料在各個轉換時呈現之外觀的快照集。
在對應資料流中使用轉換
現在您已將資料移入 Azure Data Lake Store Gen2,就可以準備建立對應資料流,以透過 Spark 叢集大規模轉換資料,然後將資料載入資料倉儲。
這個動作包含以下主要工作:
準備環境
加入資料來源
使用對應資料流轉換
寫入資料接收器
工作 1:準備環境
開啟資料流程偵錯。開啟位於撰寫模組頂端的「資料流程偵錯」滑桿。
注意
資料流程叢集需要 5 至 7 分鐘的時間來準備。
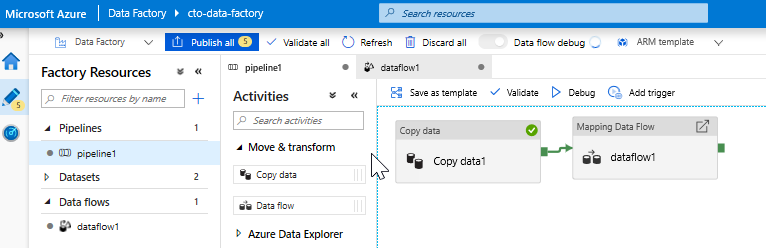
新增資料流程活動。 在 [活動] 窗格中,開啟 [移動和轉換] 摺疊式功能表,並將 [資料流程] 活動拖曳至管道畫布上。 在彈出的窗格中,按一下 [建立新的資料流程],並選取 [對應資料流],然後按一下 [確定]。 按一下 [pipeline1] 索引標籤,並從 [複製活動] 中將綠色方塊拖曳至 [資料流程活動],以建立「成功時」的條件。 您會在畫布中看到下列內容:
工作 2:新增資料來源
新增 ADLS 來源。 按兩下畫布中的 [對應資料流] 物件。 在 [資料流程] 畫布中,按一下 [新增來源] 按鈕。 在 [來源資料集] 下拉式功能表中,選取您在複製活動中使用的 [ADLSG2] 資料集
- 如果您的資料集指向包含其他檔案的資料夾,您可能需要建立另一個資料集,或利用參數化來確保僅讀取 moviesDB.csv 檔案
- 如果您尚未在 ADLS 中匯入結構描述,但已內嵌您的資料,請前往資料集的 [結構描述] 索引標籤,然後按一下 [匯入結構描述],讓資料流程知道結構描述預測。
偵錯叢集準備就緒之後,請透過 [資料預覽] 索引標籤確認您的資料已正確載入。一旦按一下 [重新整理] 按鈕,對應資料流就會顯示您的資料在各個轉換時呈現之外觀的快照集。
工作 3:使用對應資料流轉換
新增「選取轉換」來重新命名與卸除資料行。 在資料的預覽中,您可能已經注意到「Rotton Tomatoes」資料行的拼寫錯誤。 若要為其正確命名並卸除未使用的 [評等] 資料行,您可以按一下 ADLS 來源節點旁邊的「+」圖示,並在 [結構描述] 修飾元下方選擇 [選取],以新增 [選取轉換]。
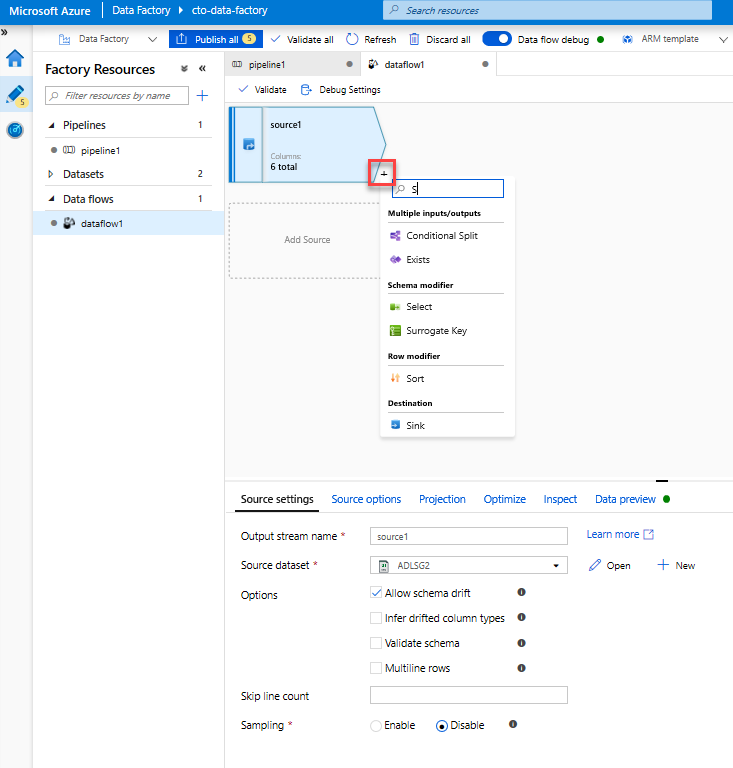
將 [名稱] 欄位中的「Rotton」變更為「Rotten」。 若要卸除 [評等] 資料行,請將滑鼠游標暫留在其上方,然後按一下垃圾桶圖示。
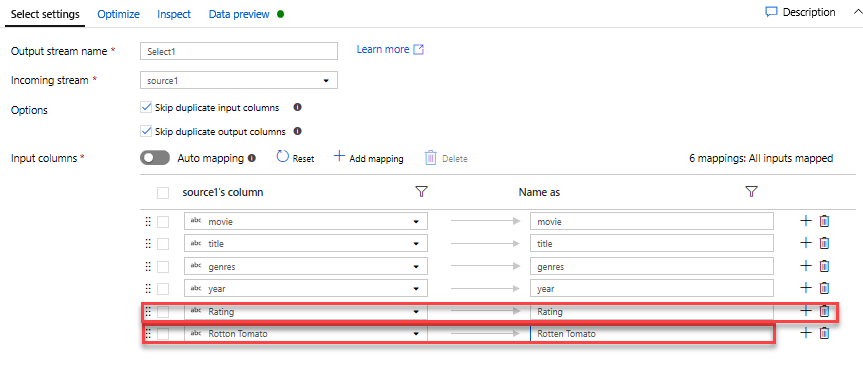
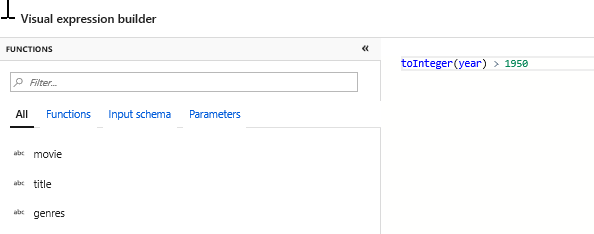
新增篩選轉換以篩選掉不需要的年份。 假設您只對 1951 年之後製作的電影感興趣。 您可以按一下選取轉換旁的 [+] 圖示,然後選擇「資料列」修飾元下方的 [篩選],以新增篩選轉換來指定篩選條件。 按一下 [運算式] 方塊以開啟運算式產生器,然後輸入篩選條件。 使用對應資料流運算式語言的語法,toInteger(year) > 1950 會將字串年份值轉換為整數,並且篩選值高於 1950 的資料列。
您可以使用運算式產生器的內嵌 [資料預覽] 窗格,以確認您的條件是否正常運作
新增「衍生轉換」以計算主要內容類型。 您可能有發現,內容類型資料行是以「|」字元分隔的字串。 如果您只在意每個資料行中的「第一個」內容類型,您可以按一下篩選轉換旁的 [+] 圖示,並選擇「結構描述」修飾元下方的 [衍生],以透過衍生的資料行轉換來衍生名為 [PrimaryGenre] 的新資料行。 衍生的資料行與篩選轉換一樣,都會使用對應資料流運算式產生器來指定新資料行的值。

在此案例中,您會嘗試擷取內容類型資料行的第一個內容類型,其格式為「genre1|genre2|...|genreN」。 使用 locate 函式取得內容類型字串中第一個以 1 起始的「|」索引。 使用 iif 函式時,如果此索引大於 1,就可以透過 left 函式來計算主要內容類型,這會傳回字串中位於索引左側的所有字元。 否則,PrimaryGenre 值會等於內容類型欄位。 您可以透過運算式產生器的資料預覽窗格來確認輸出。
透過「時段轉換」為電影排名。 假設您想要了解某部電影在特定年份內,在特定內容類型中的排名情形。 您可以按一下衍生資料行轉換旁的 [+] 圖示,並按一下「結構描述」修飾元下方的 [時段],以新增時段轉換來定義以時段為基礎的彙總。 若要完成此動作,請指定您要納入時段的項目、排序的依據、範圍為何,以及如何計算新的時段資料行。 在此範例中,我們將以無界限範圍對 PrimaryGenre 和年份進行視窗 Over、依 Rotten Tomato 遞減排序,並計算名為 RatingsRank (也就是每部電影在其特定內容類型年份中的排名) 的新資料行。
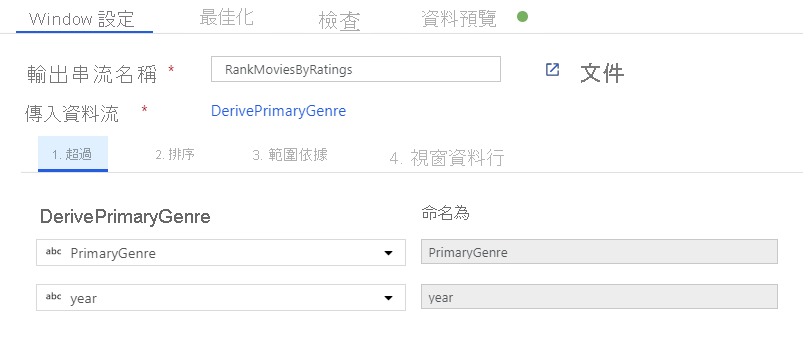
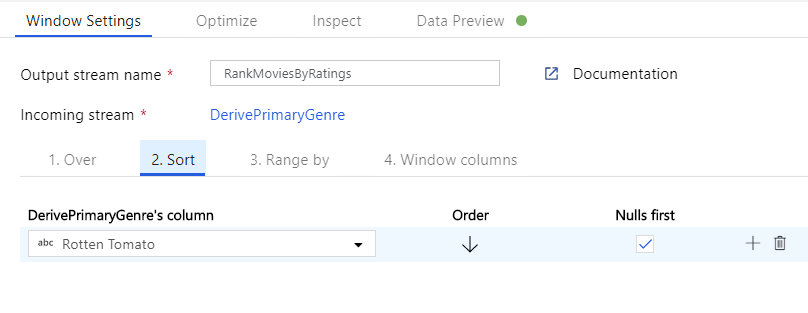
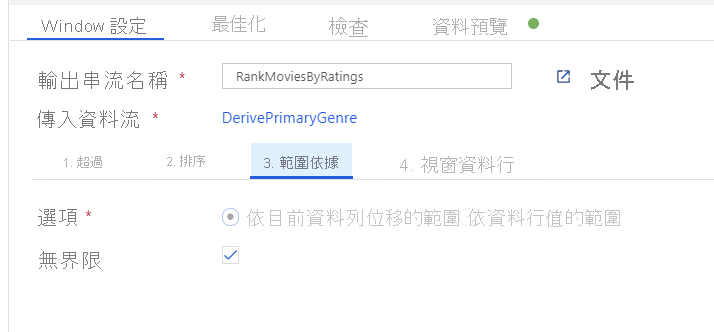
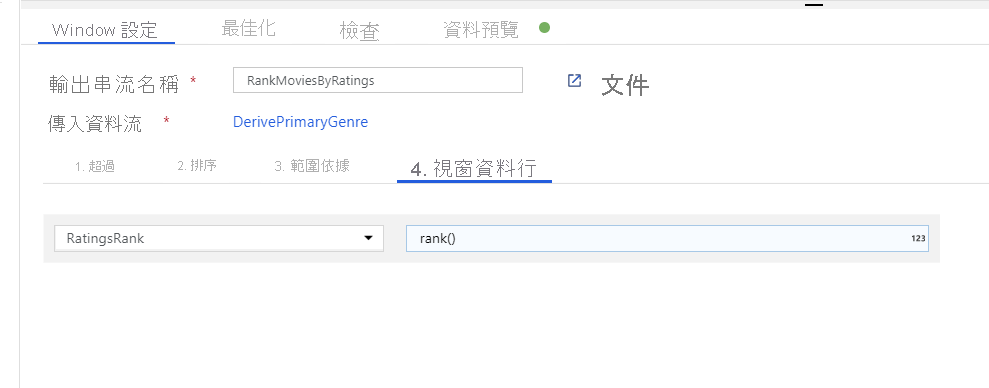
使用彙總轉換來彙總評等。 在您已收集並衍生所有所需資料後,我們便可以新增彙總轉換來計算以所需群組為基礎的計量,方法是按一下時段轉換旁的 [+] 圖示,然後按一下「結構描述」修飾元下方的 [彙總]。 如同您在視窗轉換中所做的一樣,讓影片依 PrimaryGenre 和年份分組
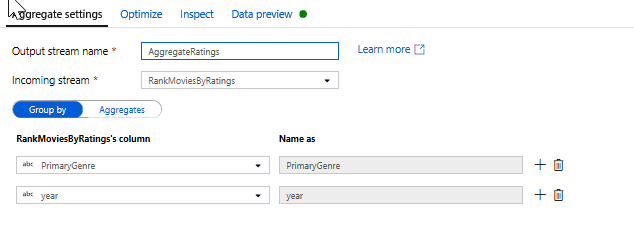
在 [彙總] 索引標籤中,您可以建立依據資料行對指定分組所計算的彙總。 您可以針對每個內容類型和年份,取得 Rotten Tomato 平均分數、評分最高和最低的電影 (利用時段函式),以及每個群組中的電影數量。 彙總會大幅減少轉換資料流中的資料列數量,而且只會依據轉換傳播群組,以及彙總轉換中指定的資料行。
- 若要查看彙總轉換如何變更您的資料,請使用 [資料預覽] 索引標籤
透過更改資料列轉換來指定更新插入條件。 如果您要寫入表格式接收器,可以按一下彙總轉換旁的 + 圖示,然後按一下 [資料列] 修飾元下方的 [更改資料列],以使用更改資料列轉換在資料列上指定插入、刪除、更新和更新插入原則。 由於您一直在插入和更新,因此可以指定一律更新插入所有資料列。

工作 4:寫入資料接收器
- 寫入 Azure Synapse Analytics 接收器。 現在您已完成所有轉換邏輯,可以準備寫入接收器了。
按一下 Upsert 轉換旁的 [+] 圖示,然後按一下「目的地」下方的 [接收器],藉此新增接收器。
在 [接收器] 索引標籤中,透過 [+ 新增] 按鈕建立新的資料倉儲資料集。
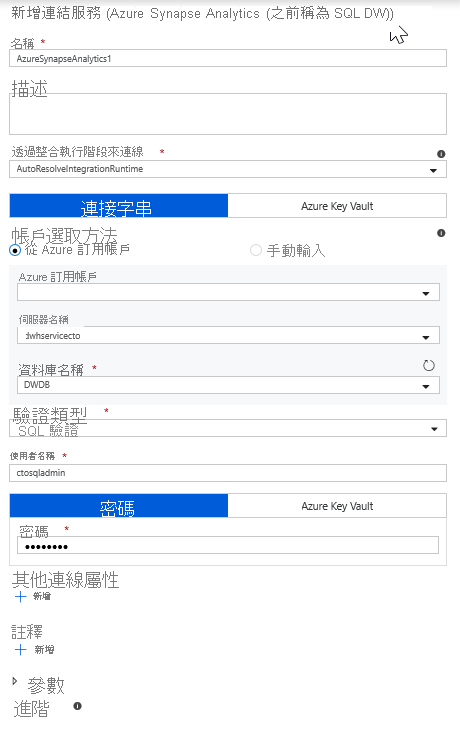
從並排顯示清單中選取 [Azure Synapse Analytics]。
選取新的連結服務,並設定您的 Azure Synapse Analytics 連線,以連線至 DWDB 資料庫。 在完成作業後,按一下 [建立]。
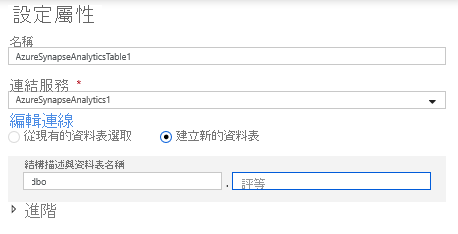
在資料集設定中,選取 [建立新的資料表],並輸入 Dbo 作為結構描述和 Ratings 作為資料表名稱。 完成時,請按一下 [確定]。
由於已指定 upsert 條件,因此您必須移至 [設定] 索引標籤,然後根據索引鍵資料行 PrimaryGenre 和年份選取 [允許 upsert]。
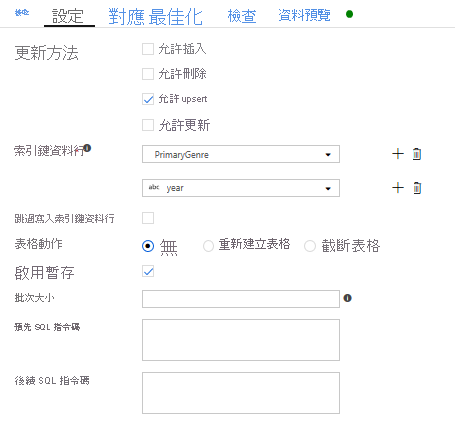
至此,您已完成 8 個轉換對應資料流的建置作業。 您現在可以執行管線並查看結果了!

工作 5:執行管線
移至畫布中的 [pipeline1] 索引標籤。 由於資料流程中的 Azure Synapse Analytics 是使用 PolyBase,您必須指定 blob 或 ADLS 複寫用快取資料夾。 在執行資料流程活動的 [設定] 索引標籤中,開啟 [PolyBase] 可折疊功能,然後選取您的 ADLS 連結服務,並指定複寫用快取資料夾路徑。
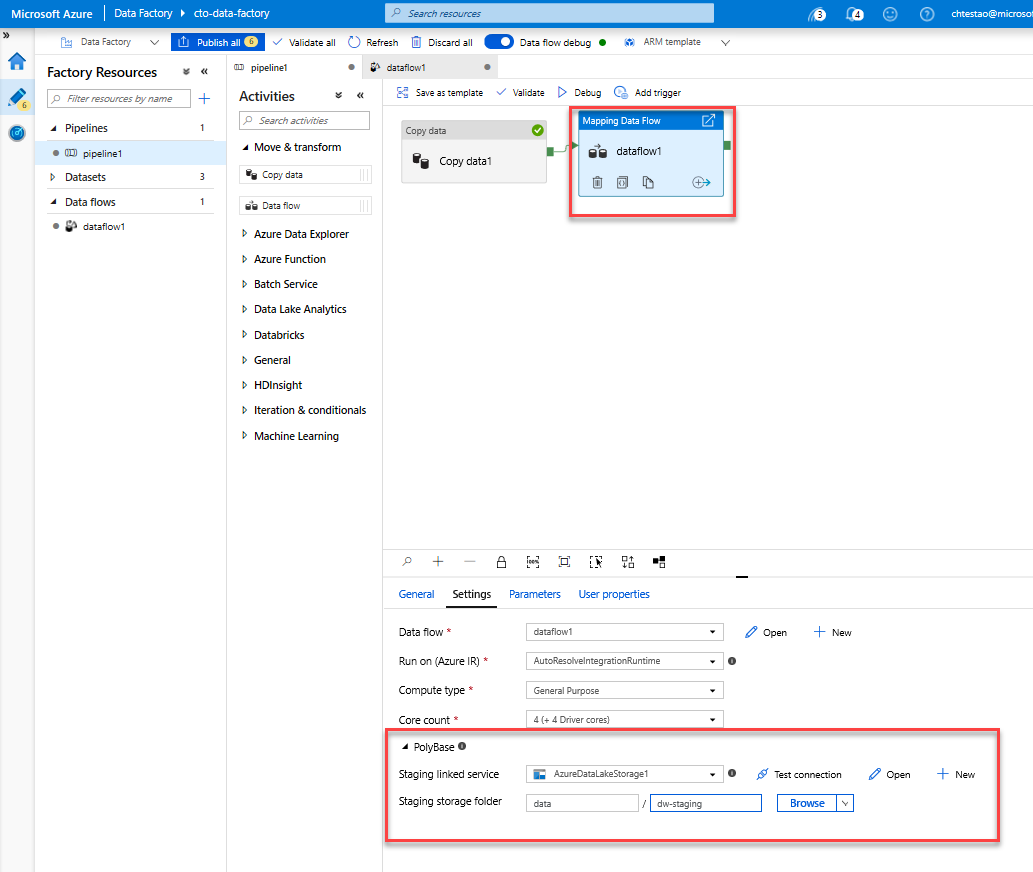
在您發佈管線之前,請執行另一個偵錯流程來確認其是否正常運作。 在 [輸出] 索引標籤中,您可以監控這兩個活動執行時的狀態。
在兩個活動都執行成功後,您可以按一下「資料流程」活動旁的眼鏡圖示,深入瞭解資料流程執行狀況。
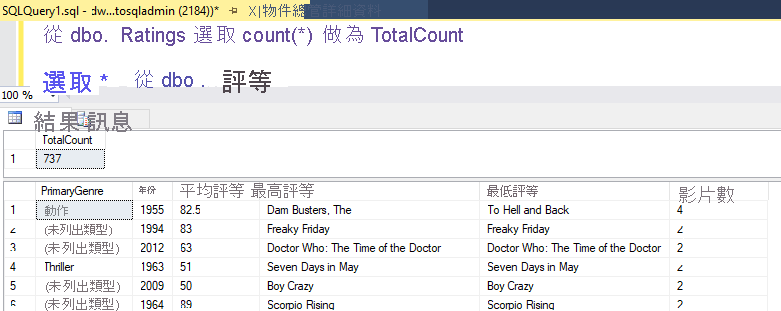
若您使用的邏輯和此實驗中所述相同,則您的資料流程會在 SQL DW 中寫入 737 個資料列。 您可以進入 SQL Server Management Studio 來確認管線是否正常運作,並查看所寫入的內容。