Reliability in Azure AI Search
Across Azure, reliability means resiliency and availability if there's a service outage or degradation. In Azure AI Search, reliability can be achieved within a single service or through multiple search services in separate regions.
Deploy a single search service and scale up for high availability. You can add multiple replicas to handle higher indexing and query workloads. If your search service supports availability zones, replicas are automatically provisioned in different physical data centers for extra resiliency.
Deploy multiple search services across different geographic regions. All search workloads are fully contained within a single service that runs in a single geographic region, but in a multi-service scenario, you have options for synchronizing content so that it's the same across all services. You can also set up a load balancing solution to redistribute requests or fail over if there's a service outage.
For business continuity and recovery from disasters at a regional level, plan on a cross-regional topology, consisting of multiple search services having identical configuration and content. Your custom script or code provides the fail over mechanism to an alternate search service if one suddenly becomes unavailable.
High availability
In Azure AI Search, replicas are copies of your index. A search service is commissioned with at least one replica, and can have up to 12 replicas. Adding replicas allows Azure AI Search to do machine reboots and maintenance against one replica, while query execution continues on other replicas.
For each individual search service, Microsoft guarantees at least 99.9% availability for configurations that meet these criteria:
Two replicas for high availability of read-only workloads (queries)
Three or more replicas for high availability of read-write workloads (queries and indexing)
The system has internal mechanisms for monitoring replica health and partition integrity. If you provision a specific combination of replicas and partitions, the system ensures that level of capacity for your service.
No Service Level Agreement (SLA) is provided for the Free tier. For more information, see the SLA for Azure AI Search.
Availability zone support
Availability zones are an Azure platform capability that divides a region's data centers into distinct physical location groups to provide high availability, within the same region. In Azure AI Search, individual replicas are the units for zone assignment. A search service runs within one region; its replicas run in different physical data centers (or zones) within that region.
Availability zones are used when you add two or more replicas to your search service. Each replica is placed in a different availability zone within the region. If you have more replicas than available zones in the search service region, the replicas are distributed across zones as evenly as possible. There's no specific action on your part, except to create a search service in a region that provides availability zones, and then to configure the service to use multiple replicas.
Prerequisites
- Service tier must be Standard or higher
- Service region must be in a region that has available zones (listed in the following section)
- Configuration must include multiple replicas: two for read-only query workloads, three for read-write workloads that include indexing
Supported regions
Support for availability zones depends on infrastructure and storage. Currently, the following zone has insufficient storage and doesn't provide an availability zone for Azure AI Search:
- Japan West
Otherwise, availability zones for Azure AI Search are supported in the following regions:
| Region | Roll out date |
|---|---|
| Australia East | January 30, 2021 or later |
| Brazil South | May 2, 2021 or later |
| Canada Central | January 30, 2021 or later |
| Central India | January 20, 2022 or later |
| Central US | December 4, 2020 or later |
| China North 3 | September 7, 2022 or later |
| East Asia | January 13, 2022 or later |
| East US | January 27, 2021 or later |
| East US 2 | January 30, 2021 or later |
| France Central | October 23, 2020 or later |
| Germany West Central | May 3, 2021, or later |
| Israel Central | April 1, 2024, or later |
| Italy North | April 1, 2024, or later |
| Japan East | January 30, 2021 or later |
| Korea Central | January 20, 2022 or later |
| North Europe | January 28, 2021 or later |
| Norway East | January 20, 2022 or later |
| Qatar Central | August 25, 2022 or later |
| South Africa North | September 7, 2022 or later |
| South Central US | April 30, 2021 or later |
| South East Asia | January 31, 2021 or later |
| Sweden Central | January 21, 2022 or later |
| Switzerland North | September 7, 2022 or later |
| UAE North | September 9, 2022 or later |
| UK South | January 30, 2021 or later |
| US Gov Virginia | April 30, 2021 or later |
| West Europe | January 29, 2021 or later |
| West US 2 | January 30, 2021 or later |
| West US 3 | June 02, 2021 or later |
Note
Availability zones don't change the terms of the SLA. You still need three or more replicas for query high availability.
Multiple services in separate geographic regions
Service redundancy is necessary if your operational requirements include:
Business continuity and disaster recovery (BCDR) requirements. Azure AI Search doesn't provide instant failover if there's an outage.
Fast performance for a globally distributed application. If query and indexing requests come from all over the world, users who are closest to the host data center experience faster performance. Creating more services in regions with close proximity to these users can equalize performance for all users.
If you need two or more search services, creating them in different regions can meet application requirements for continuity and recovery, and faster response times for a global user base.
Azure AI Search doesn't provide an automated method of replicating search indexes across geographic regions, but there are some techniques that can make this process simple to implement and manage. These techniques are outlined in the next few sections.
The goal of a geo-distributed set of search services is to have two or more indexes available in two or more regions, where a user is routed to the Azure AI Search service that provides the lowest latency:
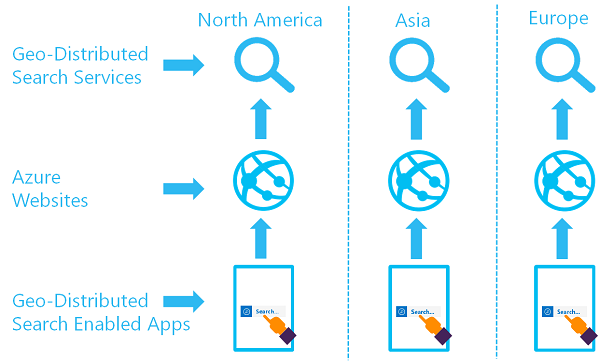
You can implement this architecture by creating multiple services and designing a strategy for data synchronization. Optionally, you can include a resource like Azure Traffic Manager for routing requests.
Tip
For help in deploying multiple search services across multiple regions, see this Bicep sample on GitHub that deploys a fully configured, multi-regional search solution. The sample gives you two options for index synchronization, and request redirection using Traffic Manager.
Synchronize data across multiple services
There are two options for keeping two or more distinct search services in sync:
- Pull content updates into a search index by using an indexer.
- Push content into an index using the Add or Update Documents (REST) API or an Azure SDK equivalent API.
To configure either option, we recommend using the sample Bicep script in the azure-search-multiple-region repository, modified to your regions and indexing strategies.
Option 1: Use indexers for updating content on multiple services
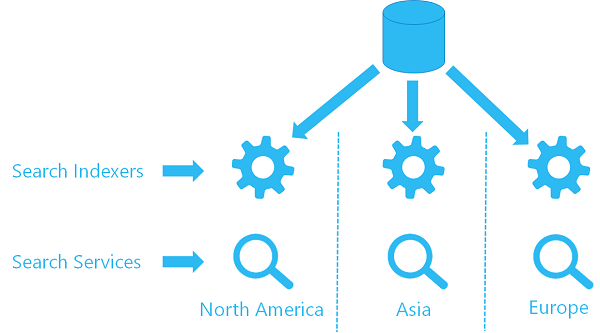
If you're already using indexer on one service, you can configure a second indexer on a second service to use the same data source object, pulling data from the same location. Each service in each region has its own indexer and a target index (your search index isn't shared, which means each index has its own copy of the data), but each indexer references the same data source.
Here's a high-level visual of what that architecture would look like.
Option 2: Use REST APIs for pushing content updates on multiple services
If you're using the Azure AI Search REST API to push content to your search index, you can keep your various search services in sync by pushing changes to all search services whenever an update is required. In your code, make sure to handle cases where an update to one search service fails but succeeds for other search services.
Fail over or redirect query requests
If you need redundancy at the request level, Azure provides several load balancing options:
- Azure Traffic Manager, used to route requests to multiple geo-located websites that are then backed by multiple search services.
- Application Gateway, used to load balance between servers in a region at the application layer.
- Azure Front Door, used to optimize global routing of web traffic and provide global failover.
Some points to keep in mind when evaluating load balancing options:
Search is a backend service that accepts query and indexing requests from a client.
Requests from the client to a search service must be authenticated. For access to search operations, the caller must have role-based permissions or provide an API key on the request.
Service endpoints are reached through a public internet connection by default. If you set up a private endpoint for client connections that originate from within a virtual network, use Application Gateway.
Azure AI Search accepts requests addressed to the
<your-search-service-name>.search.windows.netendpoint. If you reach the same endpoint using a different DNS name in the host header, such as a CNAME, the request is rejected.
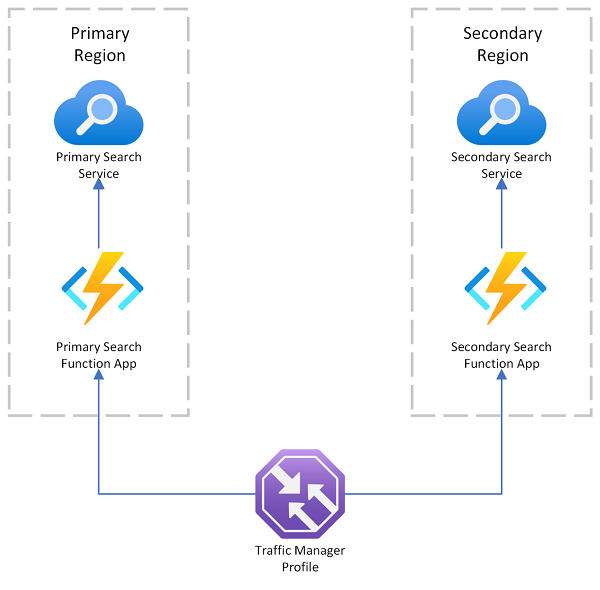
Azure AI Search provides a multi-region deployment sample that uses Azure Traffic Manager for request redirection if the primary endpoint fails. This solution is useful when you route to a search-enabled client that only calls a search service in the same region.
Azure Traffic Manager is primarily used for routing network traffic across different endpoints based on specific routing methods (such as priority, performance, or geographic location). It acts at the DNS level to direct incoming requests to the appropriate endpoint. If an endpoint that Traffic Manager is servicing begins refusing requests, traffic is routed to another endpoint.
Traffic Manager doesn't provide an endpoint for a direct connection to Azure AI Search, which means you can't put a search service directly behind Traffic Manager. Instead, the assumption is that requests flow to Traffic Manager, then to a search-enabled web client, and finally to a search service on the backend. The client and service are located in the same region. If one search service goes down, the search client starts failing, and Traffic Manager redirects to the remaining client.
Data residency in a multi-region deployment
When you deploy multiple search services in various geographic regions, your content is stored in the region you chose for each search service.
Azure AI Search doesn't store data outside of your specified region without your authorization. Authorization is implicit when you use features that write to an Azure Storage resource: enrichment cache, debug session, knowledge store. In all cases, the storage account is one that you provide, in the region of your choice.
Note
If both the storage account and the search service are in the same region, network traffic between search and storage uses a private IP address and occurs over the Microsoft backbone network. Because private IP addresses are used, you can't configure IP firewalls or a private endpoint for network security. Instead, use the trusted service exception as an alternative when both services are in the same region.
About service outages and catastrophic events
As stated in the SLA, Microsoft guarantees a high level of availability for index query requests when an Azure AI Search service instance is configured with two or more replicas, and index update requests when an Azure AI Search service instance is configured with three or more replicas. However, there's no built-in mechanism for disaster recovery. If continuous service is required in the event of a catastrophic failure outside of Microsoft’s control, we recommend provisioning a second service in a different region and implementing a geo-replication strategy to ensure indexes are fully redundant across all services.
Customers who use indexers to populate and refresh indexes can handle disaster recovery through geo-specific indexers that retrieve data from the same data source. Two services in different regions, each running an indexer, could index the same data source to achieve geo-redundancy. If you're indexing from data sources that are also geo-redundant, remember that Azure AI Search indexers can only perform incremental indexing (merging updates from new, modified, or deleted documents) from primary replicas. In a failover event, be sure to redirect the indexer to the new primary replica.
If you don't use indexers, you would use your application code to push objects and data to different search services in parallel. For more information, see Synchronize data across multiple services.
Back up and restore alternatives
A business continuity strategy for the data layer usually includes a restore-from-backup step. Because Azure AI Search isn't a primary data storage solution, Microsoft doesn't provide a formal mechanism for self-service backup and restore. However, you can use the index-backup-restore sample code in this Azure AI Search .NET sample repo to back up your index definition and snapshot to a series of JSON files, and then use these files to restore the index, if needed. This tool can also move indexes between service tiers.
Otherwise, your application code used for creating and populating an index is the de facto restore option if you delete an index by mistake. To rebuild an index, you would delete it (assuming it exists), recreate the index in the service, and reload by retrieving data from your primary data store.
Related content
- Review Service limits to learn more about the pricing tiers and service limits.
- Review Plan for capacity to learn more about partition and replica combinations.
- Review Case Study: Use Cognitive Search to Support Complex AI Scenarios for more configuration guidance.