Azure Databricks
An Apache Spark-based analytics platform optimized for Azure.
1,947 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ESR%3C/text%3E%3C/svg%3E)
Hi Expert,
how we can create unique key in table creatoin in databricks pysparrk
like 1,2,3, auto integration column in databricks
id,Name
1 test,
2 test2
3 test3
Regards
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ESM%3C/text%3E%3C/svg%3E)
Hi @Shambhu Rai ,
Just checking in to see if the above answer helped. If this answers your query, do click Accept Answer and Up-Vote for the same. And, if you have any further query do let us know.
Hi @Shambhu Rai ,
Just checking in to see if the above answer helped. If this answers your query, do click Accept Answer and Up-Vote for the same. And, if you have any further query do let us know.
Hi @Shambhu Rai ,
Thanks for posting question in Microsoft Q&A forum and for using Azure Services.
As I understand your question, you want to create an id column as key with incremental numbers during table creation in databricks.
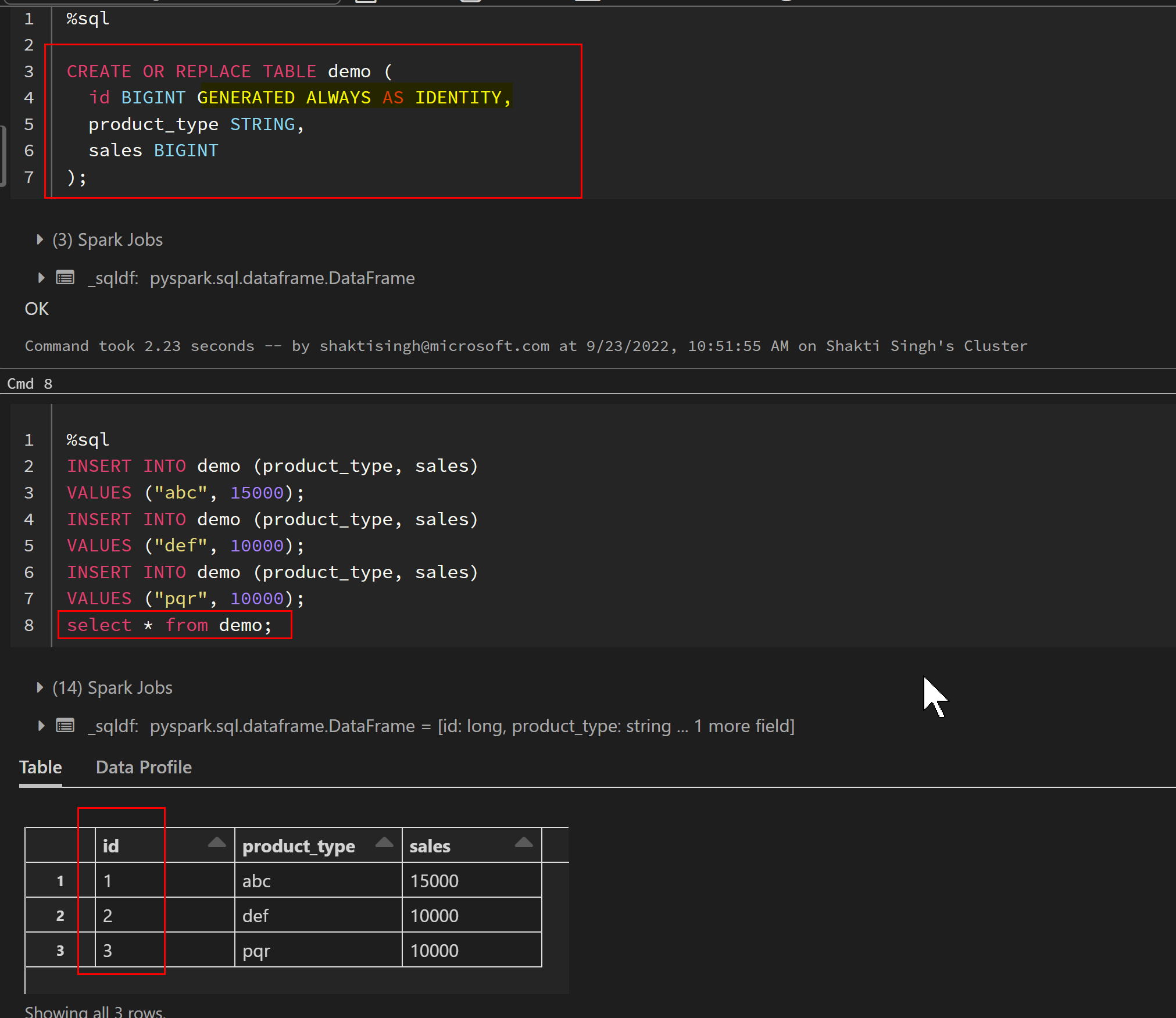
To accomplish this, we can use Generate Always As Identity while table creation:
CREATE OR REPLACE TABLE demo (
id BIGINT GENERATED ALWAYS AS IDENTITY,
product_type STRING,
sales BIGINT
);
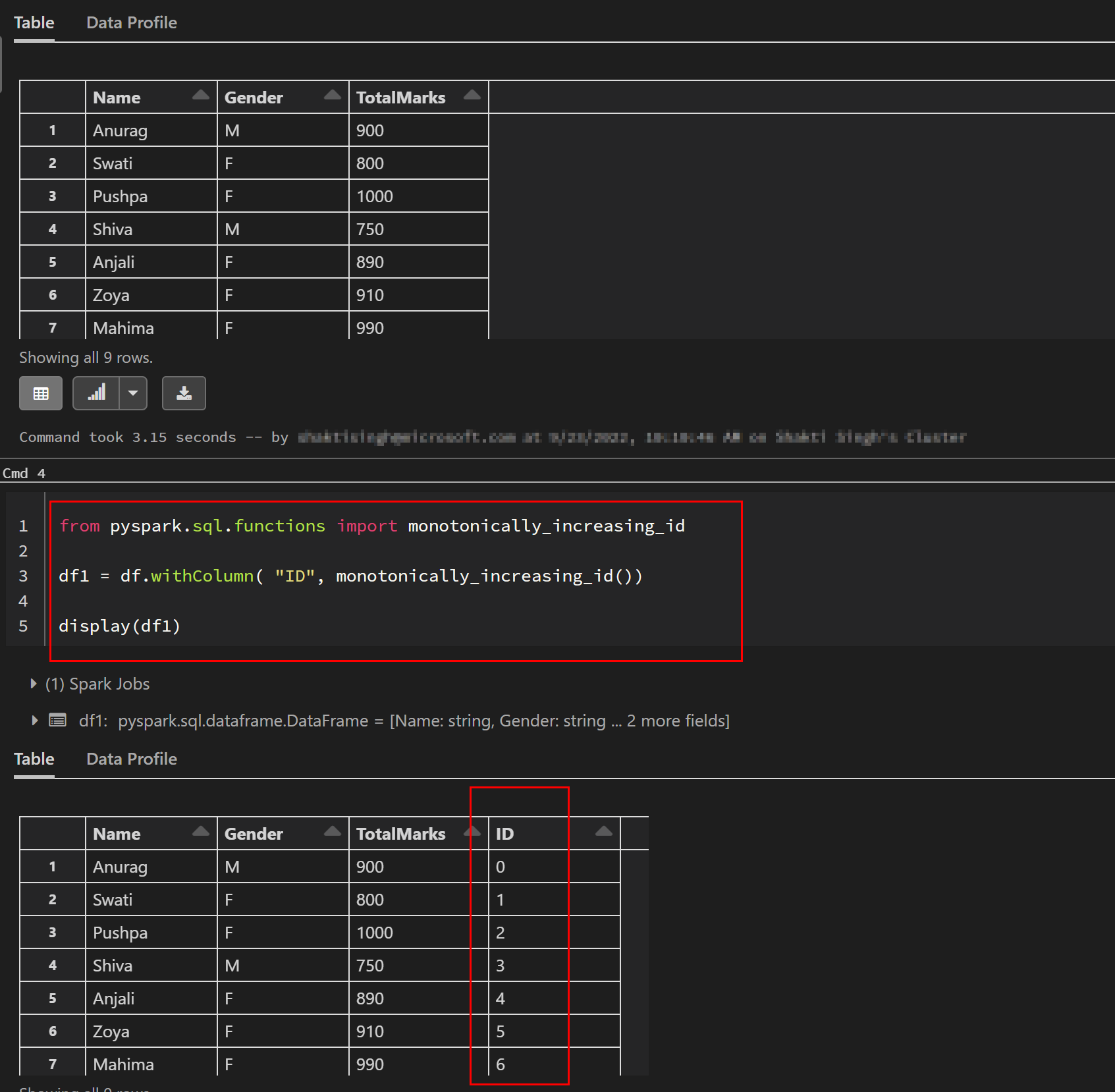
If the table already exists and we want to add surrogate key column, then we can make use of sql function monotonically_increasing_id or could use analytical function row_number as shown below:
from pyspark.sql.functions import monotonically_increasing_id
df1 = df.withColumn( "ID", monotonically_increasing_id())
display(df1)
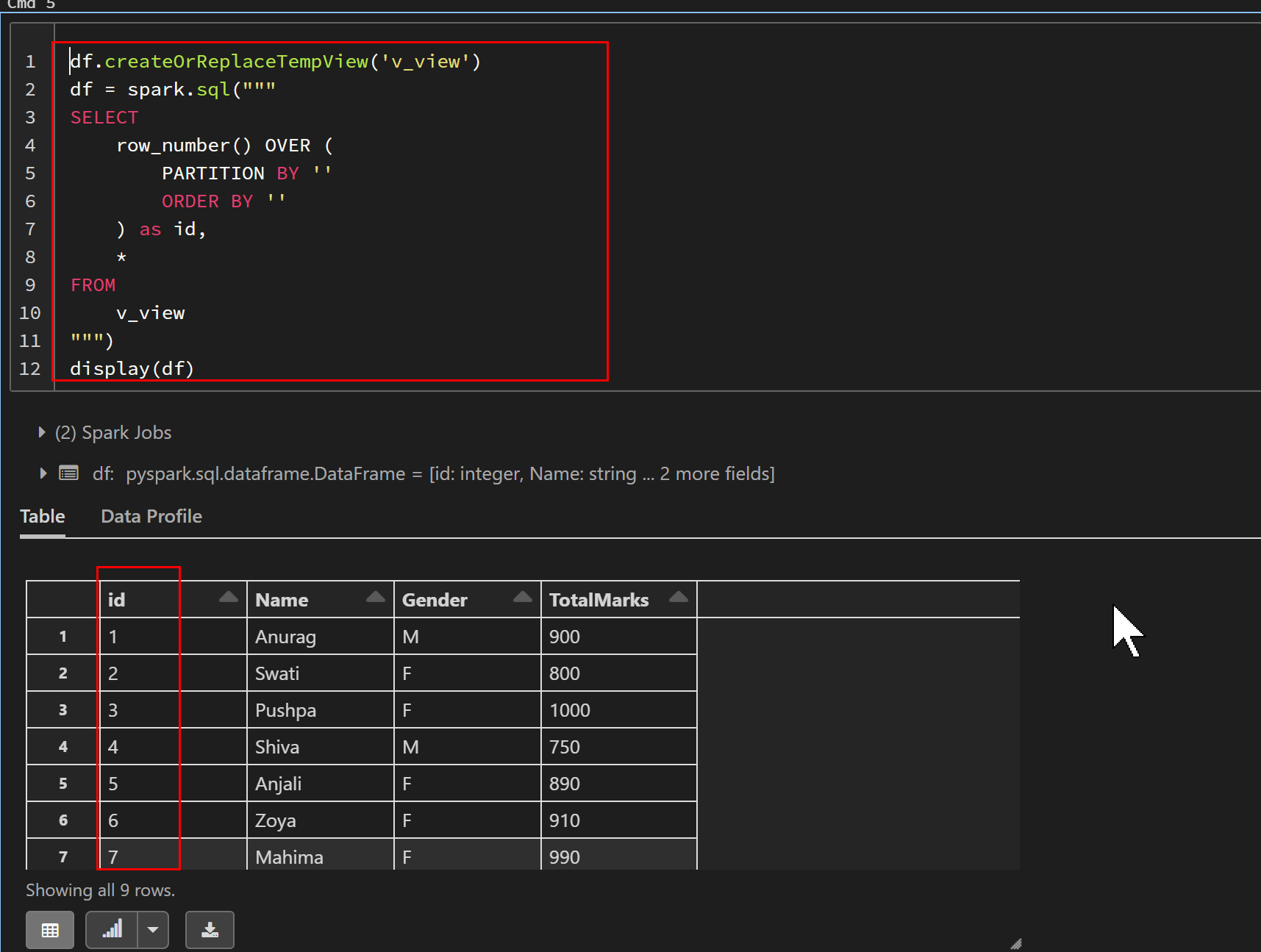
df.createOrReplaceTempView('v_view')
df = spark.sql("""
SELECT
row_number() OVER (
PARTITION BY ''
ORDER BY ''
) as id,
*
FROM
v_view
""")
display(df)
Hope this will help. Please let us know if any further queries.
------------------------------
 or upvote
or upvote  button whenever the information provided helps you.
button whenever the information provided helps you.