Azure Databricks
An Apache Spark-based analytics platform optimized for Azure.
1,917 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ER%3C/text%3E%3C/svg%3E)
I have the current repo on azure databricks:
|-run_pipeline.py
|-__init__.py
|-data_science
|--__init.py__
|--text_cleaning
|---text_cleaning.py
|---__init.py__
On the run_pipeline notebook I have this
from data_science.text_cleaning import text_cleaning
path = os.path.join(os.path.dirname(__file__), os.pardir)
sys.path.append(path)
spark = SparkSession.builder.master(
"local[*]").appName('workflow').getOrCreate()
df = text_cleaning.basic_clean(spark_df)
On the text_cleaning.py I have a function called basic_clean that will run something like this:
def basic_clean(df):
print('Removing links')
udf_remove_links = udf(_remove_links, StringType())
df = df.withColumn("cleaned_message", udf_remove_links("cleaned_message"))
return df
When I do df.show() on the run_pipeline notebook, I get this error message:
Exception has occurred: PythonException (note: full exception trace is shown but execution is paused at: <module>)
An exception was thrown from a UDF: 'pyspark.serializers.SerializationError: Caused by Traceback (most recent call last):
File "/databricks/spark/python/pyspark/serializers.py", line 165, in _read_with_length
return self.loads(obj)
File "/databricks/spark/python/pyspark/serializers.py", line 466, in loads
return pickle.loads(obj, encoding=encoding)
ModuleNotFoundError: No module named 'data_science''. Full traceback below:
Traceback (most recent call last):
File "/databricks/spark/python/pyspark/serializers.py", line 165, in _read_with_length
return self.loads(obj)
File "/databricks/spark/python/pyspark/serializers.py", line 466, in loads
return pickle.loads(obj, encoding=encoding)
ModuleNotFoundError: No module named 'data_science'
Shouldnt the imports work? Why is this an issue?

Hi @roo ,
Thank you for posting query in Microsoft Q&A Platform.
from the error message it seems data_science module is not found, which is getting referred in your code. You double confirm by running command pip list to see installed libraries on cluster.
Kindly consider installing the modules when are needed to code work. Click here know how to install libraries or modules to cluster.
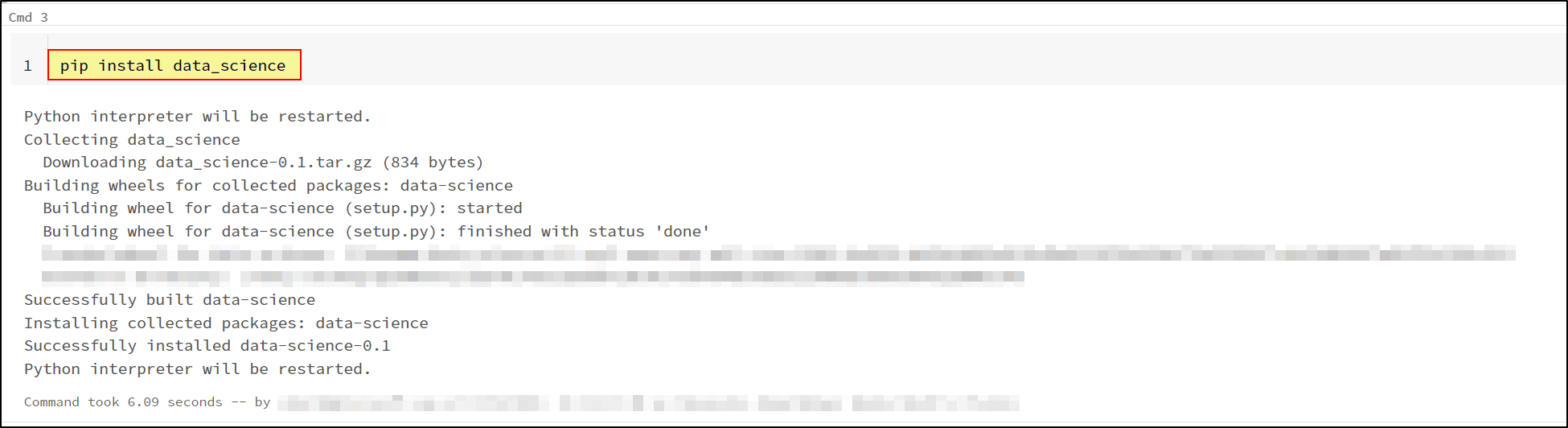
You consider running pip install data_science command in notebook cell as well.
Hope this helps. Please let me know if any further queries.
----------------------
Please consider hitting Accept Answer button. Accepted answers help community as well.
Hi thank you for your reply! The thing is that the package "data_science" is a custom package. I don't have a PyPI repo or a WHL. I created a setup.py that I install locally using python setup.py --user develop and then I can use it. However, I can't install the package like this. Besides, I'm constantly doing changes to that package, meaning, I'd have to re-install it again on the cluster for it to work. With this being said, is there a way to install a repo on a cluster for example? So that whenever a change is made and pushed to the repo, the package is also updated on the cluster? Currently, the only solution I found was adding all the functions on the same notebook, but this becomes unbearable if we have several functions and classes doing several things. Thanks!
Hi @roo ,
Since your package is custom package you should consider installing it on server. You can consider installing library by uploading to workspace or using init scripts.
Agree the fact that adding manually all functions to notebook always is not great solution. Consider installing custom library. Below link explains how to do that.
https://learn.microsoft.com/en-us/azure/databricks/libraries/cluster-libraries
Below link has various ways to installing libraries explained. We can install it using CLI or API calls too. Its discussed in below link. So you can consider manually loading the package to dbfs and then having a mechanism to in your repo to trigger API call to install same.
https://stackoverflow.com/questions/60543850/how-to-install-a-library-on-a-databricks-cluster-using-some-command-in-the-noteb
Please note, without getting package file on to workspace directly doing it from repo is not possible.
Hope this helps.
------------
Please consider hitting Accept Answer button. Accepted answers help community as well.
Hi @roo ,
Just checking in to see if the above answer helped. If this answers your query, do click  and upvote
and upvote  for the same. And, if you have any further query do let us know.
for the same. And, if you have any further query do let us know.