Azure Synapse Analytics
An Azure analytics service that brings together data integration, enterprise data warehousing, and big data analytics. Previously known as Azure SQL Data Warehouse.
4,369 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ECC%3C/text%3E%3C/svg%3E)
I'm using spark.read.synapse to connect to my dedicated pool, but since yesterday, i'm getting the error "key not found: db_name".
I didn't find nothing about it, and dont know if the problema is related to my db_name which have a blank space in name "DB Name.dbo.Mytable".
When i exclude the blank space, i get another error, not finding the database. It was working in that way with this 'db_name' about a year without problems

Hello @Calleb Cecco ,
Thanks for the question and using MS Q&A platform.
Could you please share the code snippet which youa re trying to connect to dedicated SQL pool and also share the screenshot of the error message which you are experiencing?
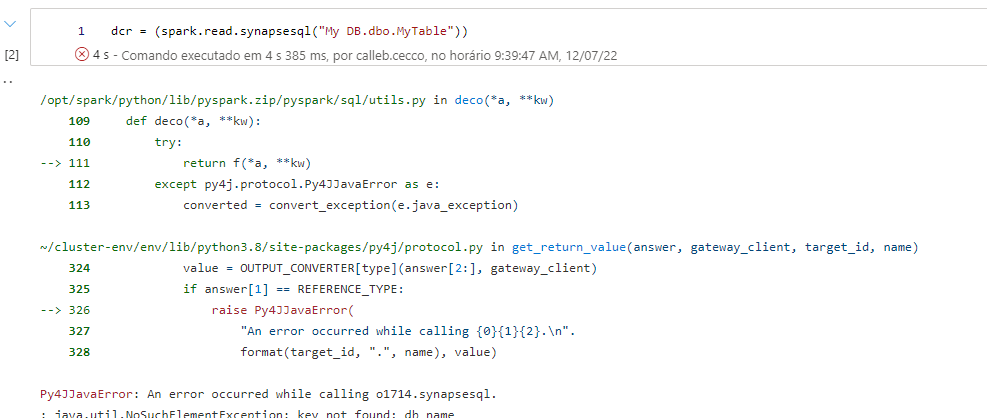
I'm using this method
Py4JJavaError Traceback (most recent call last)
<ipython-input-7-281c750a> in <module>
3 dbName = "My DB.dbo.MyTable"
4
----> 5 dcr = (spark.read.option(Constants.SERVER, "pesa-dw.database.windows.net"))
~/cluster-env/env/lib/python3.8/site-packages/com/microsoft/spark/sqlanalytics/SqlAnalyticsReader.py in synapsesql(self, table_name)
40 df = DataFrame(jdf, sqlcontext)
41 except Exception as e:
---> 42 raise e
43 return df
~/cluster-env/env/lib/python3.8/site-packages/com/microsoft/spark/sqlanalytics/SqlAnalyticsReader.py in synapsesql(self, table_name)
37 connector = sqlcontext._jvm.com.microsoft.spark.sqlanalytics.SqlAnalyticsConnectorClass() \
38 .SQLAnalyticsFormatReader(self._jreader)
---> 39 jdf = connector.synapsesql(table_name)
40 df = DataFrame(jdf, sqlcontext)
41 except Exception as e:
~/cluster-env/env/lib/python3.8/site-packages/py4j/java_gateway.py in call(self, *args)
1319
1320 answer = self.gateway_client.send_command(command)
-> 1321 return_value = get_return_value(
1322 answer, self.gateway_client, self.target_id, self.name)
1323
/opt/spark/python/lib/pyspark.zip/pyspark/sql/utils.py in deco(*a, **kw)
109 def deco(*a, **kw):
110 try:
--> 111 return f(*a, **kw)
112 except py4j.protocol.Py4JJavaError as e:
113 converted = convert_exception(e.java_exception)
~/cluster-env/env/lib/python3.8/site-packages/py4j/java_gateway.py in call(self, *args)
1319
1320 answer = self.gateway_client.send_command(command)
-> 1321 return_value = get_return_value(
1322 answer, self.gateway_client, self.target_id, self.name)
1323
/opt/spark/python/lib/pyspark.zip/pyspark/sql/utils.py in deco(*a, **kw)
109 def deco(*a, **kw):
110 try:
--> 111 return f(*a, **kw)
112 except py4j.protocol.Py4JJavaError as e:
113 converted = convert_exception(e.java_exception)
~/cluster-env/env/lib/python3.8/site-packages/py4j/protocol.py in get_return_value(answer, gateway_client, target_id, name)
324 value = OUTPUT_CONVERTERtype
325 if answer[1] == REFERENCE_TYPE:
--> 326 raise Py4JJavaError(
327 "An error occurred while calling {0}{1}{2}.\n".
328 format(target_id, ".", name), value)
Py4JJavaError: An error occurred while calling o1715.synapsesql.
: java.util.NoSuchElementException: key not found: db_name
at scala.collection.MapLike.default(MapLike.scala:236)
at scala.collection.MapLike.default$(MapLike.scala:235)
at scala.collection.AbstractMap.default(Map.scala:65)
at scala.collection.MapLike.apply(MapLike.scala:144)
at scala.collection.MapLike.apply$(MapLike.scala:143)
at scala.collection.AbstractMap.apply(Map.scala:65)
at com.microsoft.spark.sqlanalytics.utils.Utils$.putConnectionString(Utils.scala:355)
at com.microsoft.spark.sqlanalytics.utils.Utils$.initializeAndValidateOptions(Utils.scala:106)
at com.microsoft.spark.sqlanalytics.ItemsTable.readSchema(ItemsTable.scala:96)
at com.microsoft.spark.sqlanalytics.ItemsTable.$anonfun$schema$1(ItemsTable.scala:88)
at scala.Option.getOrElse(Option.scala:189)
at com.microsoft.spark.sqlanalytics.ItemsTable.schema(ItemsTable.scala:88)
at com.microsoft.spark.sqlanalytics.SynapseSqlDataSourceV2.inferSchema(SynapseSqlDataSourceV2.scala:46)
at org.apache.spark.sql.execution.datasources.v2.DataSourceV2Utils$.getTableFromProvider(DataSourceV2Utils.scala:81)
at org.apache.spark.sql.DataFrameReader.$anonfun$load$1(DataFrameReader.scala:241)
at scala.Option.map(Option.scala:230)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:218)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:176)
at com.microsoft.spark.sqlanalytics.SqlAnalyticsConnectorClass$SQLAnalyticsFormatReader.sqlanalytics(SqlAnalyticsConnectorClass.scala:105)
Hello @Calleb Cecco ,
We are internal checking on the issue and I will get back to you once I hear back from the team.
Nothing yet?