SQL Server
A family of Microsoft relational database management and analysis systems for e-commerce, line-of-business, and data warehousing solutions.
12,710 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EWM%3C/text%3E%3C/svg%3E)
DISCLAIMER : THIS CODE AND INFORMATION IS PROVIDED "AS IS" WITHOUT WARRANTY OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE.
Issue symptom ============== User enabled CDC on SQL 2019 prior to CU5. After upgrading SQL to CU5 and disable cdc on database, he might meet errors when he tries to re-enable cdc table on the same database:
(1) When running “EXEC sys.sp_cdc_enable_table”, following error will show up:
Msg 22832, Level 16, State 1, Procedure sys.sp_cdc_enable_table_internal, Line 673 [Batch Start Line 1]
Could not update the metadata that indicates table [dbo].[table_name] is enabled for Change Data Capture. The failure occurred when executing the command '[sys].[sp_cdc_add_job] @job_type = N'capture''. The error returned was 208: 'Invalid object name 'cdc_jobs'.'. Use the action and error to determine the cause of the failure and resubmit the request.
(2) When running “[sys].[sp_cdc_add_job] @job_type = N'capture'” following error will show up:
Msg 208, Level 16, State 1, Procedure cdc_jobs_view, Line 12 [Batch Start Line 17]
Invalid object name 'cdc_jobs'.
Msg 4413, Level 16, State 1, Procedure sys.sp_cdc_add_job_internal, Line 92 [Batch Start Line 17]
Could not use view or function 'msdb.dbo.cdc_jobs_view' because of binding errors.
Reproduce steps ===============
(1)
use cdctest
EXEC sys.sp_cdc_enable_table
@source_schema = N'dbo', @source_name = N'Table1',
@role_name = N'cdc_admin', @capture_instance = N'dbo_Table1', @supports_net_changes =1
GO
Msg 22832, Level 16, State 1, Procedure sys.sp_cdc_enable_table_internal, Line 673 [Batch Start Line 1] Could not update the metadata that indicates table [dbo].[Table1] is enabled for Change Data Capture. The failure occurred when executing the command '[sys].[sp_cdc_add_job] @Job _type = N'capture''. The error returned was 208: 'Invalid object name 'cdc_jobs'.'. Use the action and error to determine the cause of the failure and resubmit the request.
(2)
use cdctest
[sys].[sp_cdc_add_job] @job_type = N'capture'
Msg 208, Level 16, State 1, Procedure cdc_jobs_view, Line 12 [Batch Start Line 17] Invalid object name 'cdc_jobs'. Msg 4413, Level 16, State 1, Procedure sys.sp_cdc_add_job_internal, Line 92 [Batch Start Line 17] Could not use view or function 'msdb.dbo.cdc_jobs_view' because of binding errors.
Solution =========
Possible Cause ============== The view msdb.dbo.cdc_jobs_view is introduced since SQL 2019 CU5. It should be deleted in stored procedure “sp_cdc_cleanup_job_entries” and “sp_cdc_drop_job_internal”. The stored procedure will be used when you try to disable cdc on database. However, in CU5, the view is not dropped when disabling cdc on database. So the view still exists but the table msdb.cdc_jobs which it depends on is dropped when cdc is disabled on database. This causes binding errors.
DISCLAIMER : THIS CODE AND INFORMATION IS PROVIDED "AS IS" WITHOUT WARRANTY OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE.
DISCLAIMER : THIS CODE AND INFORMATION IS PROVIDED "AS IS" WITHOUT WARRANTY OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE.
Issue:
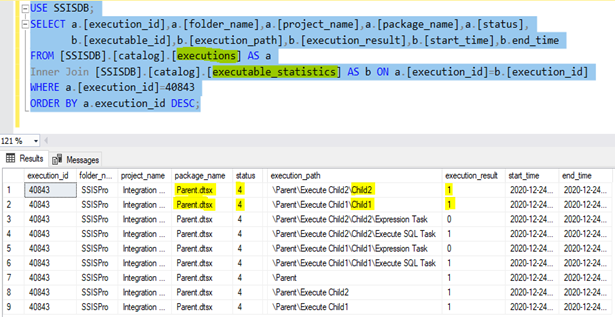
How to find the execution results of Child packages after executing Parent package in SSISDB Catalog?
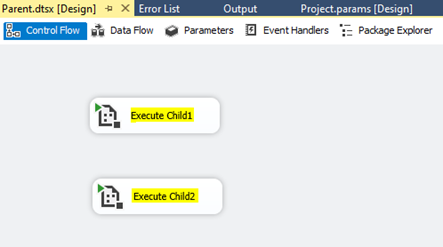
Solution:
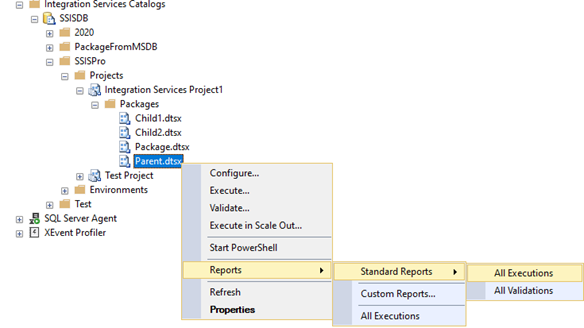
First, we can right click the Parent package in SSISDB Catalog ,
then choose Reports-->Standard Reports-->All Executions .
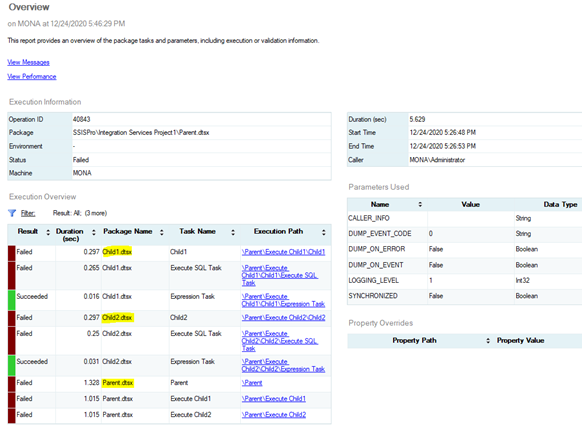
Second, we can also get the execution results of Child packages using the following query:
USE SSISDB;
SELECT a.[execution_id],a.[folder_name],a.[project_name],a.[package_name],a.[status], b.[executable_id],b.[execution_path],b.[execution_result],b.[start_time],b.end_time
FROM [SSISDB].[catalog].[executions] AS a
Inner Join [SSISDB].[catalog].[executable_statistics] AS b ON a.[execution_id]=b.[execution_id]
WHERE a.[execution_id]=40843
ORDER BY a.execution_id DESC;
Notes:
DISCLAIMER : THIS CODE AND INFORMATION IS PROVIDED "AS IS" WITHOUT WARRANTY OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE.
DISCLAIMER : THIS CODE AND INFORMATION IS PROVIDED "AS IS" WITHOUT WARRANTY OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE.
Issue:
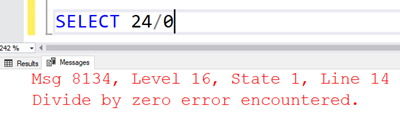
How to avoid the SQL divide by zero error
The divisor cannot be 0 in SQL Server. If the divisor is 0, an error will be returned.
Solution:
There are many ways to avoid this error in SQL Server. Below we introduce three ways to deal with this error.
--Create test data
create table #DollarCapExecutive
(Prgld int,AverageSpend float,AnnualCap int,
AverageDaystomeetcap int,NumberofPatientsMetCap int);
insert into #DollarCapExecutive
values(10112,108.35,2000,6,5),(10112,2071.90,35000,136,1),
(10112,805.62,35000,0,0),(10112,1059.44,15000,0,0),
(10112,48.74,300,12,18);
SELECT * FROM #DollarCapExecutive
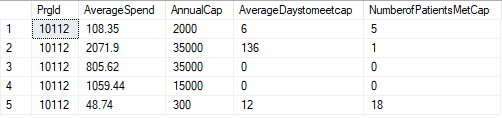
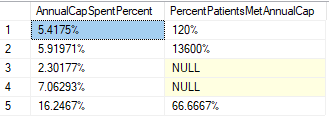
You can see that the NumberofPatientsMetCap column has data with a value of 0. When the column is directly used as a divisor, SQL Server will return divide by zero error.
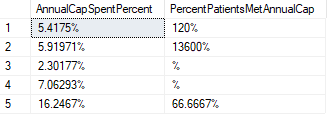
Method 1: SQL NULLIF Function
Select
concat((AverageSpend/cast(AnnualCap as float))* 100,'%' ) as AnnualCapSpentPercent,
concat((AverageDaystomeetcap/cast(nullif(NumberofPatientsMetCap,0) as float)) *100,'%' ) as PercentPatientsMetAnnualCap
from #DollarCapExecutive
Method 2: Using CASE statement to avoid divide by zero error
Select
concat((AverageSpend/cast(AnnualCap as float))*100,'%' ) as AnnualCapSpentPercent,
case when NumberofPatientsMetCap=0 then null else
concat((AverageDaystomeetcap/cast(NumberofPatientsMetCap as float))*100,'%') end as PercentPatientsMetAnnualCap
from #DollarCapExecutive
Method 3: SET ARITHABORT OFF
For details, please refer to the following article.SET ARITHABORT (Transact-SQL)]5
This method may cause performance problems, if not necessary, it is best to choose the first two methods.
DISCLAIMER : THIS CODE AND INFORMATION IS PROVIDED "AS IS" WITHOUT WARRANTY OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE.
DISCLAIMER : THIS CODE AND INFORMATION IS PROVIDED "AS IS" WITHOUT WARRANTY OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE.
Issue:
Resize the width of a report table by using a parameter
There is a report that uses a table to display the list of orders, This report includes a Boolean parameter used to hide/show two columns in that table. When true, the two columns are displayed. When columns are displayed, the table occupies the entire width of the page, but when they are not displayed, a lower-width table is obviously displayed that leaves a blank space to its right. .For the Width property of the columns in the table, insert expressions are not supported.
Requirements: When the above two columns are hidden, the table occupies all available space on the page with its width.
Solution:
As mentioned above: For the Width property of the columns in the table, insert expressions are not supported. When you hide/show the report through parameters, the column width is usually fixed, and the column width cannot be set by expression. We could set the dynamic column width by inserting a chart in the row.
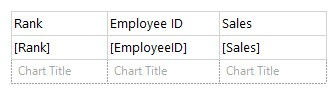
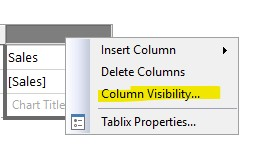
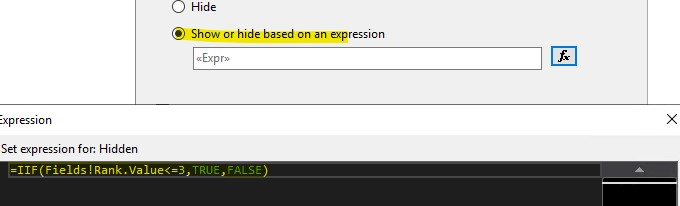
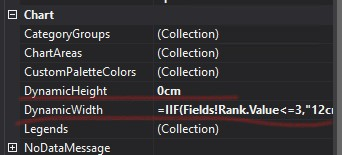
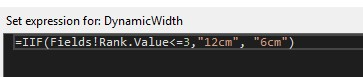


DISCLAIMER : THIS CODE AND INFORMATION IS PROVIDED "AS IS" WITHOUT WARRANTY OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE.
DISCLAIMER : THIS CODE AND INFORMATION IS PROVIDED "AS IS" WITHOUT WARRANTY OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE.
Issue:
Understanding GUID VS IDENTITY in SQL Server
In our normal environment, auto-increment is very common and necessary when we create a table.
Auto-increment allows a unique number to be generated automatically when a new record is inserted into a table.
Often this is the primary key field that we would like to be created automatically every time a new record is inserted.
We used the following SQL statement to create a table named "Person" and defined the "Personid" column to be an auto-increment primary key field.
CREATE TABLE Person (
Personid int IDENTITY(1,1) PRIMARY KEY,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Age int
);
In the example above, the starting value for IDENTITY is 1, and it will increment by 1 for each new record.
Tip: To specify that the "Personid" column should start at value 10 and increment by 5, change it to IDENTITY(10,5).
To insert new records into the "Person" table, we will NOT have to specify a value for the "Personid" column (a unique value will be added automatically).
INSERT INTO Person(FirstName,LastName,Age) VALUES
('Lars','Monsen',18),
('Mary','Green',19);
The SQL statement above would insert two new records into the "Person" table. The "Personid" column would be assigned unique values(1 and 2).
Now let’s create a new table “Student” that contains the union of all the records from the “Person” table and “Person2” table.
CREATE TABLE Students
(
Personid int PRIMARY KEY,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Age int
)
GO
INSERT INTO Students
SELECT * FROM Person
UNION ALL
SELECT * FROM Person2
But we got one error after executing above.

This error is due to both “Person” and “Person2” tables having the same values for the Id column which is also the primary key column for the newly created Students table. Therefore, when we try to insert the union of the records from “Person” and “Person2” tables, the “Violation of PRIMARY KEY constraint” error occurs. This is when we need to use the GUID data type.GUID is a 16 byte binary SQL Server data type that is globally unique across tables, databases, and servers. The term GUID stands for Globally Unique Identifier and it is used interchangeably with UNIQUEIDENTIFIER. To create a GUID in SQL Server, the NEWID() function is used as shown below
SELECT NEWID()
Above returns a GUID like ‘FB4F6574-D29D-43C6-A797-6096EC74169F’ and execute above SQL multiple times and you will see a different value every time. This is because the NEWID() function generates a unique value whenever you execute it.
To declare a variable of type GUID, the keyword used is UNIQUEIDENTIFIER as mentioned in the script below:
DECLARE @GUID UNIQUEIDENTIFIER
SET @GUID = NEWID()
SELECT @GUID
Above returns as ‘0332C398-193E-4295-8323-15BF3DDD6702’.So GUID values are unique across tables, databases, and servers. GUIDs can be considered as global primary keys. Local primary keys are used to uniquely identify records within a table.
Let’s create new tables Person3 and Person4 but this time we change the data type of the Id column from INT to UNIQUEIDENTIFIER.
To set a default value for the column we will use the default keyword and set the default value as the value returned by the ‘NEWID()’ function.
CREATE TABLE Person3 (
Personid UNIQUEIDENTIFIER PRIMARY KEY default NEWID(),
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Age int);
INSERT INTO Person3(FirstName,LastName,Age) VALUES
('Lars','Monsen',18),
('Mary','Green',19);
CREATE TABLE Person4 (
Personid UNIQUEIDENTIFIER PRIMARY KEY default NEWID(),
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Age int);
INSERT INTO Person4(FirstName,LastName,Age) VALUES
('Tom','White',20),
('Jerry','Red',17);
select * from Person3
select * from Person4
Now if you select all the records from Person3 and Person4 tables, you will a result that looks like this:
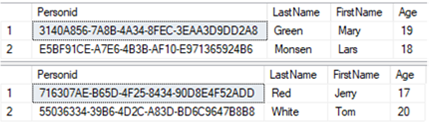
Now we have globally unique values in the Id columns of both Person3 and Person4 tables.
Let’s create a new Table named Students2 and just as we did before, try to insert the union of the records from Person3 and Person4 tables.
CREATE TABLE Students2
(
Personid UNIQUEIDENTIFIER PRIMARY KEY,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Age int);
GO
INSERT INTO Students2
SELECT * FROM Person3
UNION ALL
SELECT * FROM Person4
This time we will see that there will be no “Violation of PRIMARY KEY constraint” error, since the values in the Id column of both Person3 and Person4 tables are unique.
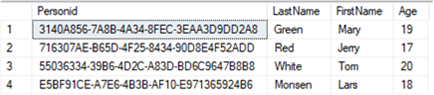
Besides, you could also explicitly use NEWID() when inserting the data as below:
CREATE TABLE Customer
(
CustomerId uniqueidentifier NOT NULL,
CustomerName varchar(70) NOT NULL,
);
INSERT Customer (CustomerId, CustomerName)
VALUES
(NEWID(), 'Ann'),
(NEWID(), 'Tom');
SELECT * FROM Customer;
Result:

DISCLAIMER : THIS CODE AND INFORMATION IS PROVIDED "AS IS" WITHOUT WARRANTY OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE.
DISCLAIMER : THIS CODE AND INFORMATION IS PROVIDED "AS IS" WITHOUT WARRANTY OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE.
Question:
It is not possible to connect to the Always on availability group established on the virtual machines environment through the listener on the local machine and implement the read-only routing function.
The read-only routing configuration of this availability group is correct, and this function can be implemented normally in the virtual machine environment. In addition, the network between the local machine and the virtual machines is connected, the listener and all replicas of this AG can be connected to the local machine through SSMS or SQLCMD.
Only when connecting the AG listener from the local machine and the ApplicationIntent=ReadOnly keyword is added to implement read-only routing, a connection error will be reported and failed.
The network where the local computer is located is different from the network where the Always on availability groups is located.
Description:
The reason for the failure of read-only routing outside the virtual machine network is that the ROR URL endpoint is set to a value that cannot be connected from the local environment.
When configuring the Always On availability group to support read-only routing, the read-only routing URL of the replicas is usually specified in the form of a fully qualified domain name(FQDN): port. The URL is an Active Directory-specific FQDN and usually cannot be accessed outside the domain.
The read-only routing URL is actually in the form of an endpoint. Usually this endpoint points to the replica itself. Therefore, it is necessary to ensure that the client can access this replica through the FQDN(or IP Address) and port number in the URL. This string will be sent back to the client by the primary replica via "redirect TDS".
Solution:
Modify the read-only routing URL configured for the replicas in the availability groups and use the format of "TCP: // IP Address: port" instead of the format of "TCP: //server.domain.com: port" (FQDN).
DISCLAIMER : THIS CODE AND INFORMATION IS PROVIDED "AS IS" WITHOUT WARRANTY OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE.