Azure Data Factory
An Azure service for ingesting, preparing, and transforming data at scale.
10,740 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EDH%3C/text%3E%3C/svg%3E)
Hi everyhwere,
I am using the YouTube Analytics and Reporting API to get performance data from a Youtube channel and to store it in Azure's Data Factory (ADF) programmitcally. From the YouTube API, I get the following JSON output format:
{
"kind": "youtubeAnalytics#resultTable",
"columnHeaders": [
{
"name": string,
"dataType": string,
"columnType": string
},
],
"rows": [
[
{value}, {value}, ...
]
]
}
See link here: https://developers.google.com/youtube/analytics/reference/reports/query#response
In a first step, I used the copy activity to copy the JSON into the blob storage. Everythine fine so far. Now, I wanted to create a data flow, flatten the json and write the values into derived columns before saving it in a data sink.
Issue #1
In the first step of my data flow - defining the source - I select the JSON from the blob storage and when I click on data preview, I will get this error message: SparkException: Malformed records are detected in schema inference. Parse Mode: FAILFAST, see screenshot:
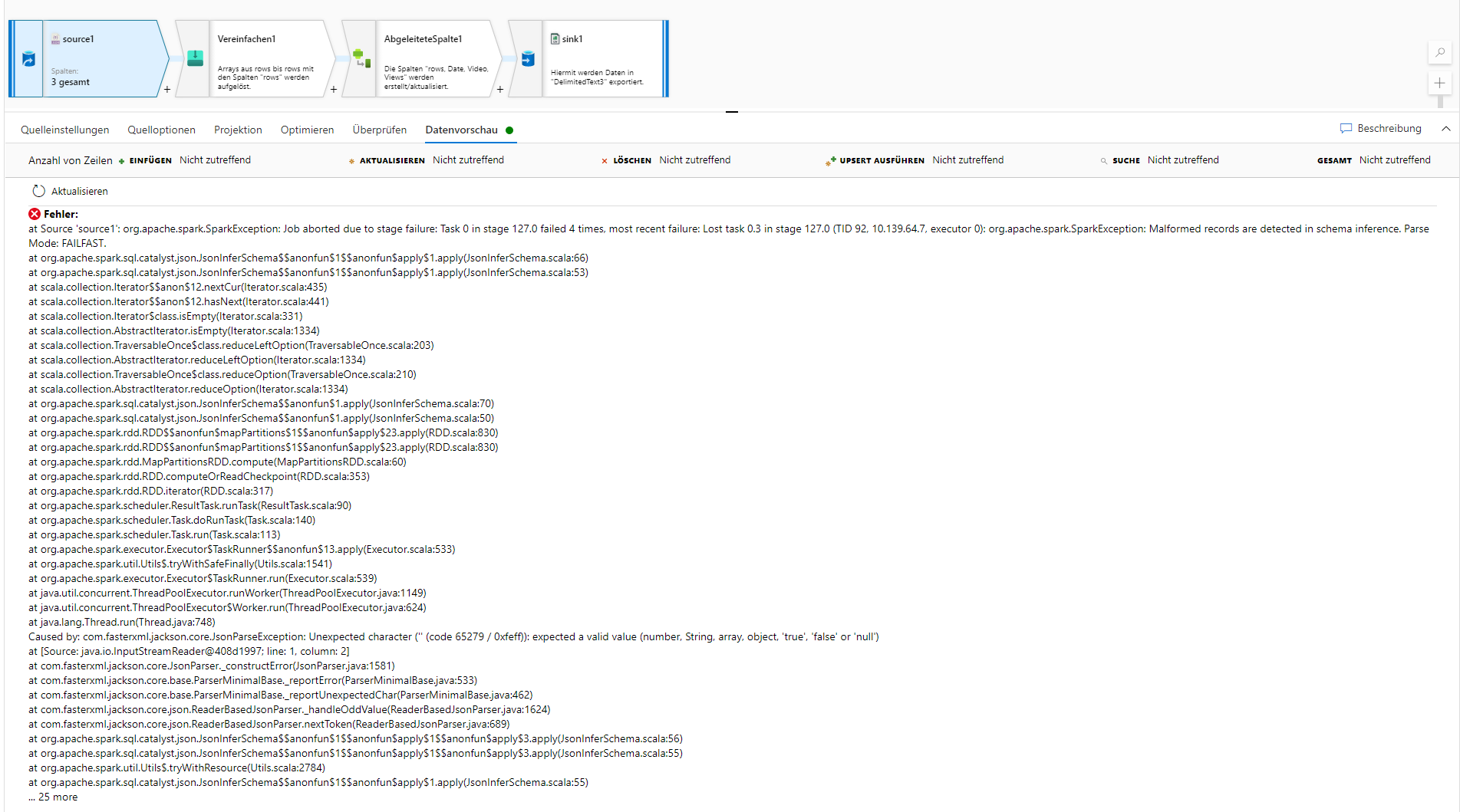
I checked the JSON's schema on https://jsonformatter.curiousconcept.com/ at generally, it seems to be fine so I don't understand why ADF cannot read it properly.
I realized that ADF is putting my whole JSON into [ ] brackets which possibly causing the Spark exception error. When I delete the [ ] brackets manually by editing the JSON in the blob storage (go get the native JSON structure of the API back again), the data preview is working as excpected. In a nutshell: ADF is adding something which it later on does not like any longer, hmm hmmm. Any ideas what can be done here?
Issue #2
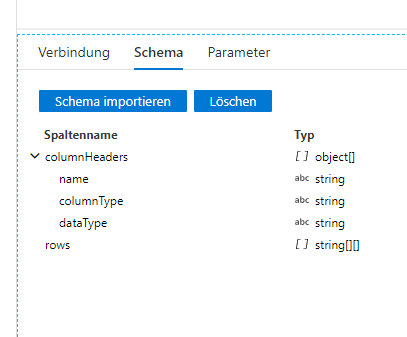
As soon as the parsing of the JSON is successful, I noticed that rows are not defined as object but as an array (in the data source linked service it's even defined as string), see both screenshots. Somehow, it should be defined as objects so that I am able to call the values within the rows, as it is for the "columnHeaders". I hope you get my pain point. Can anyone please tell me what I need to do here?

Looking forward to your replies. thanks in advance!
Okay, I am one step closer to the overall solution:
Thanks,
Daniel

' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EKM%3C/text%3E%3C/svg%3E)
You can use a derived tx or flatten tx in dataflow to reshape the JSON structure
Hi Kiran,
Thanks for your feedback. Yes, I want to use the flatten and derive to columns steps in the data flow and actually, I am able to do it for JSON's with a clear schema BUT obviously my JSON example above is not recognized as a clear schema.
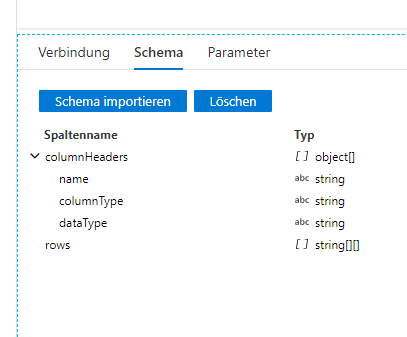
The value of the columnHeader key is an array of string, see screenshot attached.
I would expect that the rows key is also an array of strings, showing me the value in the same way as for columnHeaders but this is not the case and I don't understand why. Any ideas? As long as the rows key is not defined as array of strings, I can not flatten and derive it into columns.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ESS%3C/text%3E%3C/svg%3E)
@Kiran-MSFT Any suggestions ?
If you look closer, the schema indeed mirrors the json. rows is an array of arrays not array of strings. columnHeader is an array of structures.
Dataflow is showing the right schema. I am not sure what you are seeing in the dataset or copy activity.
Thank you @Kiran-MSFT ,
@Daniel Heilig Please let us know if you still have any issues.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EAA%3C/text%3E%3C/svg%3E)
For anyone still searching for a solution on this issue, I find that ADF dataflow is notoriously bad when dealing with JSON files. If for some reason you REALLY need to use JSON as your source data and your architecture and knowhow permits switching to databricks, then you should do the switch. Otherwise, try to use the standard copy activity to change the file type from json to csv or parquet, then use that as your dataflow source. In most cases, the Copy Activty parser will better understand JSONs, but if for some reason you still have any problems, then your best bet is to parse the json files through an Azure Function. Trust me, by always using Parquet or CSV as a source on DataFlow you'll avoid a lot of headaches.