Azure Synapse Analytics
An Azure analytics service that brings together data integration, enterprise data warehousing, and big data analytics. Previously known as Azure SQL Data Warehouse.
4,368 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EST%3C/text%3E%3C/svg%3E)
I have a source string literal containing one or more placeholders. E.g.
"Hi [[personID: 10001]]"
"Hi [[personID: 10001]] and [[personID: 10012]],"
"Hi [[personID: 1200]]"
The above are stored as rows in a table. I have another table (t_person) where you can find the name of a person using the personID.
personID, name
10001, Mike
10012, Dan
1200, Ram
The dataflow results should be:
"Hi Mike"
"Hi Mike and Dan,"
"Hi Ram"
In my dataflow expression, I tried using mapIf, map etc and it is actually is getting complicated. I'm pretty sure there is a simpler way to interpolate this. Any help is greatly appreciated.
Note: Due to various non technical reasons, want to get it done within the context of the dataflow engine.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EMM%3C/text%3E%3C/svg%3E)
Hello @Saru Thiagarajan and welcome to Microsoft Q&A.
I believe I have a solution that should work, but found a product bug while implementing it.
The idea is to put the t_person table into a cached sink so we can use a cached lookup. A cached lookup lets us do the lookup in-line rather than a separate lookup activity.
Ideally, I would extract and then replace the personID from the greeting, but you have an example with multiple persons, so I must use a different approach.
First I split the greeting, and clean up the brackets. I do this with
regexSplit(GreetingWithID, `(\[\[personID: )|(\]\])`)
"Hi [[personID: 10001]]" => ["Hi ","10001", ""]
Next I want to replace the "10001" with "Mike". I do not want to replace "Hi". So I can do a test isInteger() . When using a map, #item represents the current thing.
map(regexSplit(GreetingWithID, `(\[\[personID: )|(\]\])`), iif(not(isInteger(#item)), #item, toString(cache#lookup(toShort(#item)).name)))
Lastly I want to join the pieces together. We can use the reduce() funtion.
toString(reduce(The_map_above, '', #acc + #item, #result))
The bug I'm working on right now is "name" not being found.
Thanks for working on this. The "reduce" is a good one, +1 for that.
I've been breaking my head around the same cache lookup. The dataflow would simply be in the queue state and pipeline would be in the running state when the expression has the cachedPerson inline lookup.
Would you double check for me in your logic that it is replacing all the placeholders in the string for the use case : "Hi [[personID: 10001]] and [[personID: 10012]],"
Kudos (+1) for the use of reducer. Let me also test on my end by renaming the column to something else. "name" could be a reserved word and it could hinder with the metadata namespaces.
Look forward to hearing back from you.
Hello @Saru Thiagarajan . Here is data preview
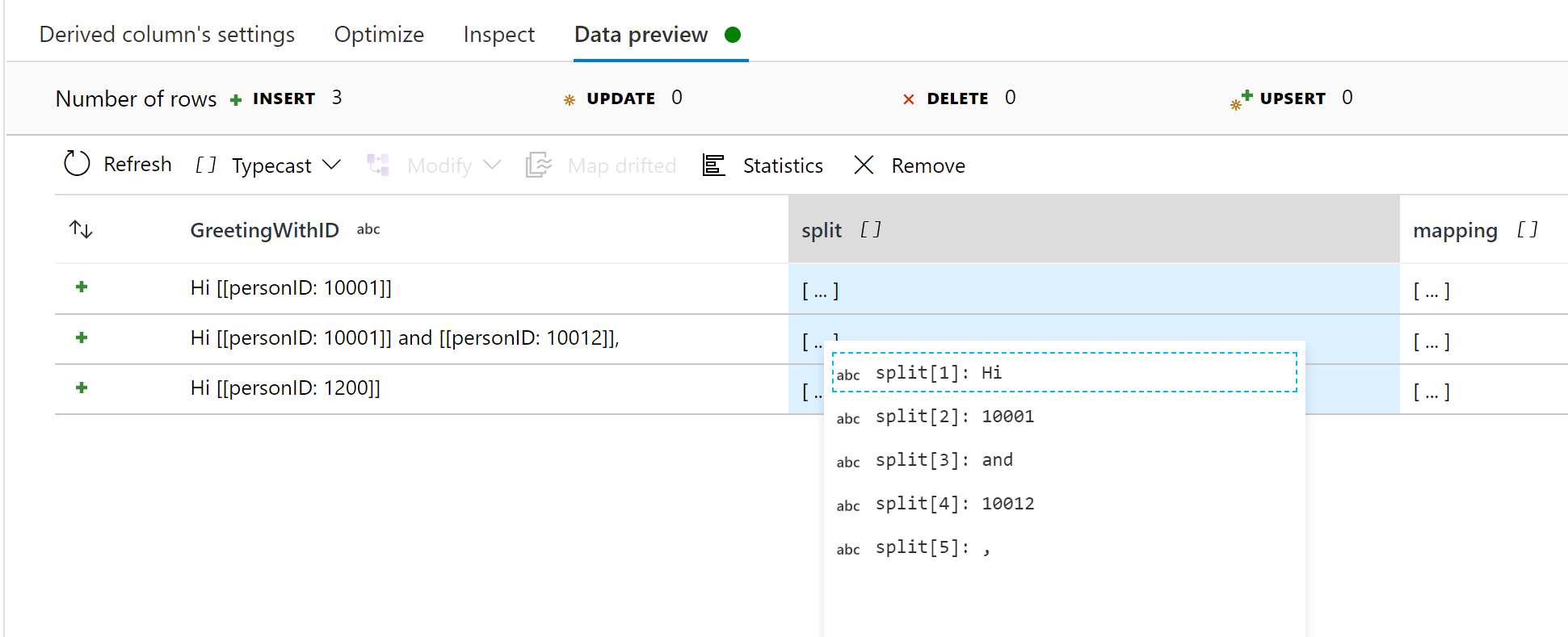
where split is defined by
regexSplit(GreetingWithID, (\[\[personID: )|(\]\]))
I'll accept your answer but do let us know after you've gone past that bug.
The below is using the join and not a lookup in the map.
Create a Crossjoin where left stream is the srcGreetingWithID and Right Stream is the srct_person
Condition instr(GreetingWithID, '[[personID: '+personID+']]') > 0
and in the aggregator
reduce(collect(personid+': :'+name), first(GreetingWithID),replace(#acc,'[personID:'+toString(split(#item, ': :')[1]+']]', toString(split(#item, ': :')[2])), #result)