Azure Data Lake Storage
An Azure service that provides an enterprise-wide hyper-scale repository for big data analytic workloads and is integrated with Azure Blob Storage.
1,341 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ESR%3C/text%3E%3C/svg%3E)
Hi Expert,
I wanted to convert columns into the rows in azure db note book. The conversation table shows speed ration between 100 to 200 and 200 to 400 and out combines conversation table values
here is my source:
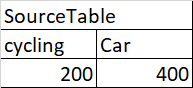 ]1
]1
Conversation table
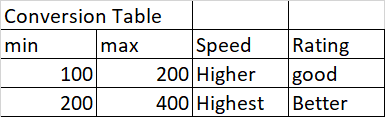
Expected output
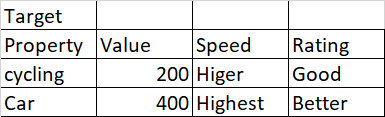
needs to convert this using case statement or any other method and column in rows in azure

Can you please start by pasting your code right now for what you have? Please redact anything that may be confidential.
insert into source1
values(50,99))
I just need a case condition which will work in Hive i.e. case when min and max value is not match then it should return original values in target table
suggesiton pls

Hi @Shambhu Rai ,
Thank you for posting query in Microsoft Q&A Platform.
You need to add a dummyColumn to
SourceTableand then perform Unpivot of it and then perform Join withConversion Table
Kindly check below detailed implementation code & screenshots.
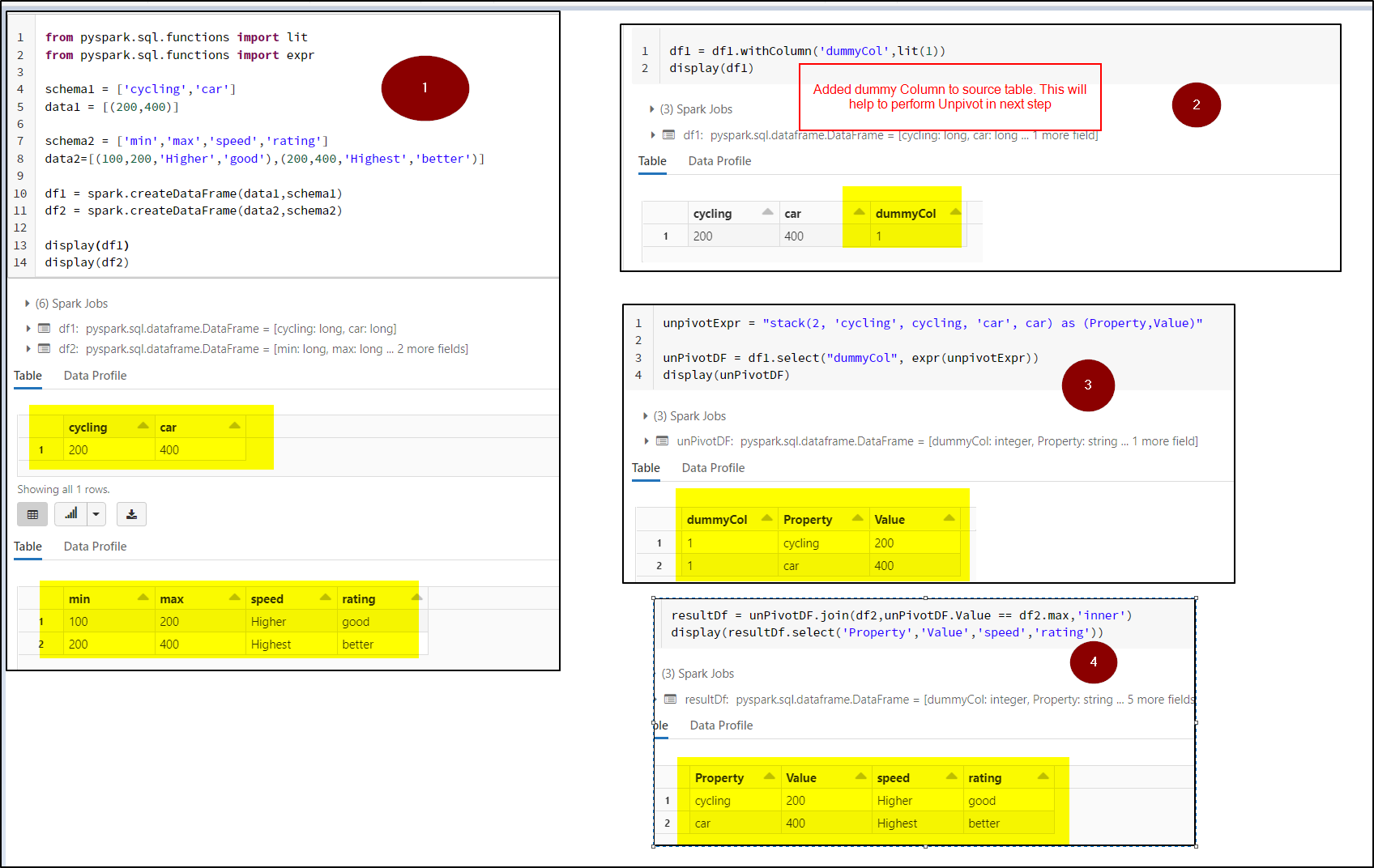
from pyspark.sql.functions import lit
from pyspark.sql.functions import expr
schema1 = ['cycling','car']
data1 = [(200,400)]
schema2 = ['min','max','speed','rating']
data2=[(100,200,'Higher','good'),(200,400,'Highest','better')]
df1 = spark.createDataFrame(data1,schema1)
df2 = spark.createDataFrame(data2,schema2)
display(df1)
display(df2)
df1 = df1.withColumn('dummyCol',lit(1))
display(df1)
unpivotExpr = "stack(2, 'cycling', cycling, 'car', car) as (Property,Value)"
unPivotDF = df1.select("dummyCol", expr(unpivotExpr))
display(unPivotDF)
resultDf = unPivotDF.join(df2,unPivotDF.Value == df2.max,'inner')
display(resultDf.select('Property','Value','speed','rating'))
Hope this helps. Please let us know if any further queries.
-------------
Please consider hitting Accept Answer button. Accepted answers help community as well.
Hi @Shambhu Rai ,
Just checking in to see if the below answer helped. If this answers your query, do click  and upvote
and upvote  for the same. And, if you have any further query do let us know.
for the same. And, if you have any further query do let us know.