إشعار
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
يستخدم هذا البرنامج التعليمي مصمم التعلم الآلي من Microsoft Azure لإنشاء نموذج تعلم آلي تنبؤي. يعتمد النموذج على البيانات المخزنة في Azure Synapse. يعد سيناريو البرنامج التعليمي التنبؤ بما إن كان من المحتمل أن يشتري العميل دراجة أم لا، لذا يمكن لـ Adventure Works، ومتجر الدراجات، إنشاء حملة تسويقية مستهدفة.
المتطلبات الأساسية
للخطو نحو هذا البرنامج التعليمي، تحتاج إلى ما يلي:
- تجمع SQL محمل مسبقًا ببيانات العينة الخاصة بـ AdventureWorksDW. لتوفير تجمع SQL هذا، راجع إنشاء تجمع SQL واختر تحميل بيانات العينة. في حالة امتلاكك لمستودع بيانات بالفعل ولكن ليس لديك بيانات العينة، يمكنك تحميل بيانات العينة يدويًا.
- مساحة العمل الخاصة بالتعلم الآلي من Microsoft Azure. اتبع هذا البرنامج التعليمي لإنشاء أخرى جديدة.
الحصول على البيانات
البيانات المستخدمة موجودة في العرض dbo.vTargetMail في AdventureWorksDW. لاستخدام مخزن البيانات في هذا البرنامج التعليمي، تصدر البيانات أولًا إلى حساب Azure Data Lake Storage نظرًا لعدم دعم Azure Synapse مجموعات البيانات حاليًا. يمكن استخدام Azure Data Factory لتصدير البيانات من مستودع البيانات إلى Azure Data Lake Storage من خلال استخدام نشاط النسخ. استخدم الاستعلام التالي للاستيراد:
SELECT [CustomerKey]
,[GeographyKey]
,[CustomerAlternateKey]
,[MaritalStatus]
,[Gender]
,cast ([YearlyIncome] as int) as SalaryYear
,[TotalChildren]
,[NumberChildrenAtHome]
,[EnglishEducation]
,[EnglishOccupation]
,[HouseOwnerFlag]
,[NumberCarsOwned]
,[CommuteDistance]
,[Region]
,[Age]
,[BikeBuyer]
FROM [dbo].[vTargetMail]
بمجرد توفر البيانات في Azure Data Lake Storage، تُستخدم مخازن البيانات في التعلم الآلي من Microsoft Azure للاتصال بخدمات تخزين Azure. اتبع الخطوات الموضحة أدناه لإنشاء مخزن بيانات ومجموعة بيانات مقابلة:
شغل استوديو التعلم الآلي من Microsoft Azure إما من مدخل Microsoft Azure أو تسجيل الدخول إلى استوديو التعلم الآلي من Microsoft Azure.
انقر فوق Datastores في الجزء الأيسر في قسم Manage بعد ذلك انقر فوق New Datastore.
أدخل اسمًا لمخزن البيانات، وحدد النوع كـ «Azure Blob Storage»، ووفر الموقع وبيانات الاعتماد. ثم انقر فوق Create.
بعد ذلك، انقر فوق Datasets في الجزء الأيسر في قسم Assets. حدد Create dataset مع الخيار الظاهر From datastore.
حدد اسم مجموعة البيانات وحدد النوع الذي يجب أن يكون Tabular. ثم انقر فوق Next للانتقال إلى الأمام.
في قسم تحديد مخزن بيانات أو إنشائه، حدد الخيار Previously created datastore. حدد مخزن البيانات الذي أنشأ في وقت سابق. انقر فوق Next وحدد إعدادات المسار والملف. تأكد من تحديد عنوان العمود في حالة كانت الملفات تحتوي على واحد.
أخيرًا، انقر فوق Create لإنشاء مجموعة البيانات.
تكوين التجربة الخاصة بالمصمم
بعد ذلك، اتبع الخطوات الموضحة أدناه لتكوين المصمم:
انقر فوق علامة التبويب Designer في الجزء الأيسر في قسم Author.
حدد Easy-to-use prebuilt components لإنشاء بنية أساسية جديدة.
في جزء الإعدادات الموجود على اليمين، حدد اسم البنية الأساسية.
حدد أيضًا نظام مجموعة حساب مستهدف للتجربة بأكملها في زر الإعدادات إلى نظام مجموعة وفرت مسبقًا. أغلق الجزء الخاص بالإعدادات.
استيراد البيانات
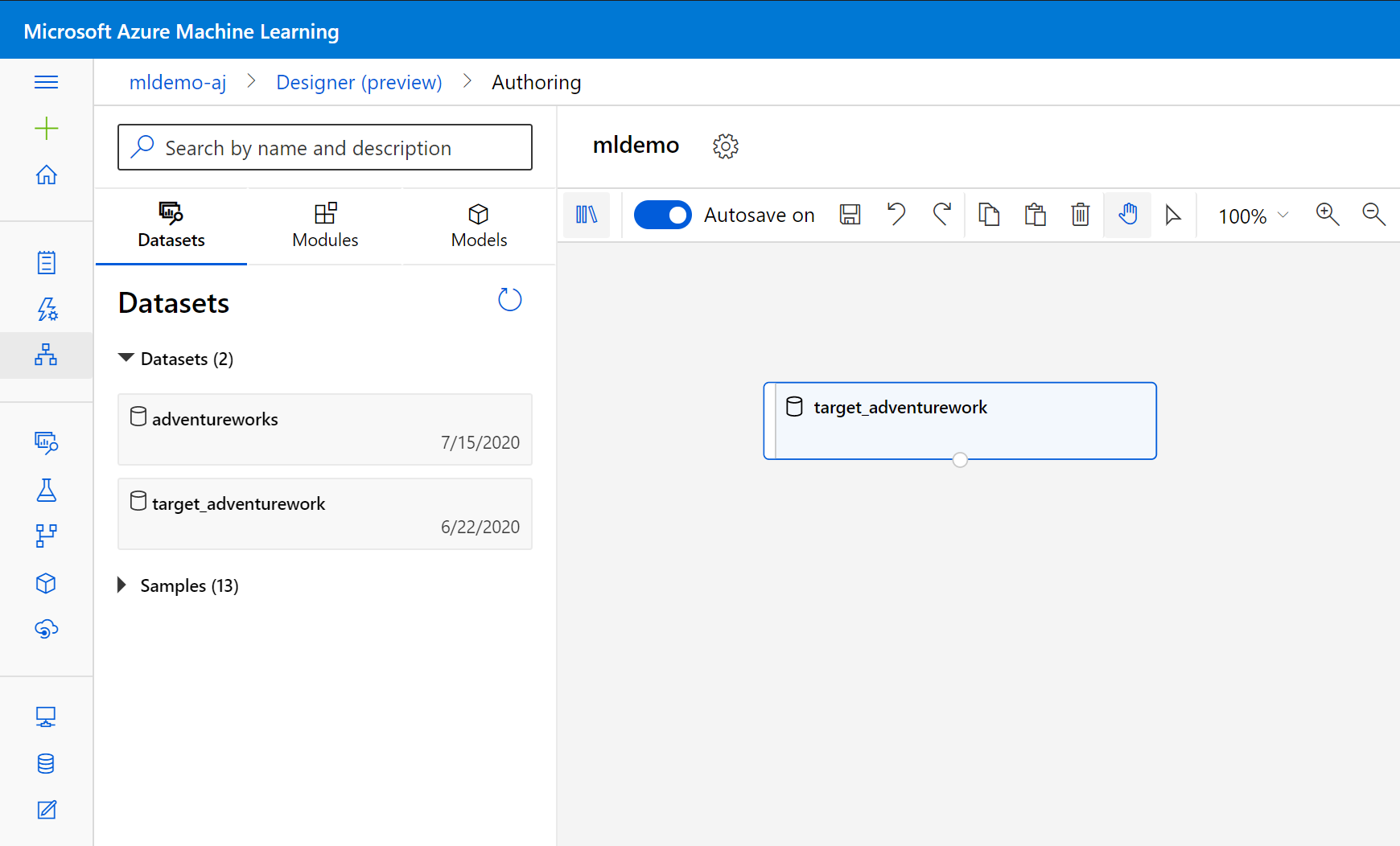
حدد علامة التبويب Datasetsالفرعية في الجزء الأيسر أسفل مربع البحث.
اسحب مجموعة البيانات التي أنشأتها من قبل إلى اللوحة.
حذف البيانات
لتنظيف البيانات، أسقط الأعمدة التي لا صلة لها بالنموذج. اتبع الخطوات التالية:
حدد علامة التبويب Componentsالفرعية في الجزء الأيسر.
اسحب مكون Select Columns in Dataset ضمن Data Transformation < Manipulation إلى اللوحة. صل هذا المكون بمكون Dataset.
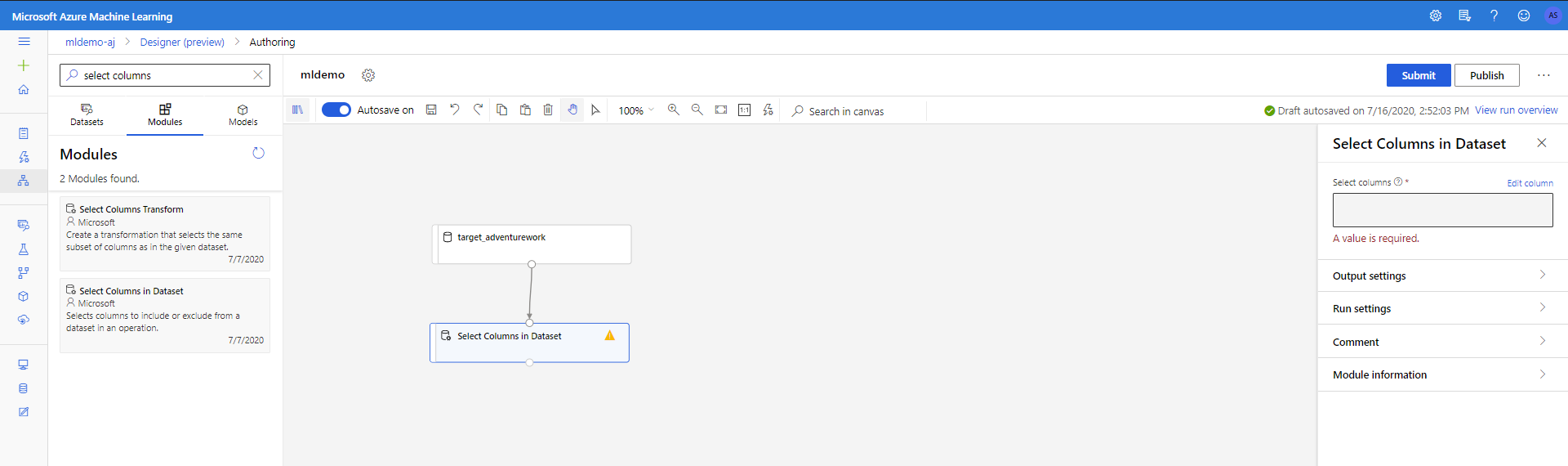
اضغط فوق component لفتح جزء الخصائص. اضغط فوق Edit column لتحديد الأعمدة التي ترغب في إسقاطها.
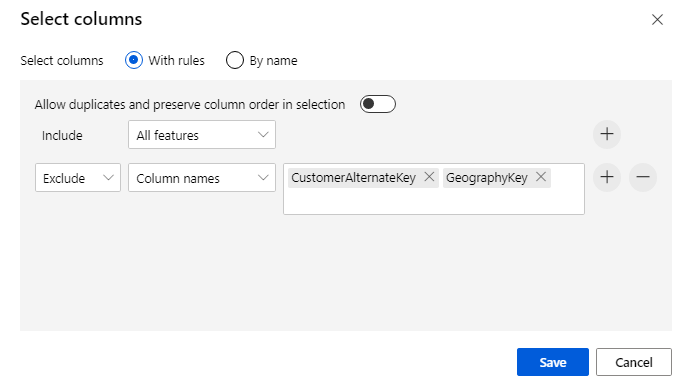
استبعاد عمودين: CustomerAlternateKey إضافة إلي GeographyKey. انقر فوق حفظ

بناء النموذج
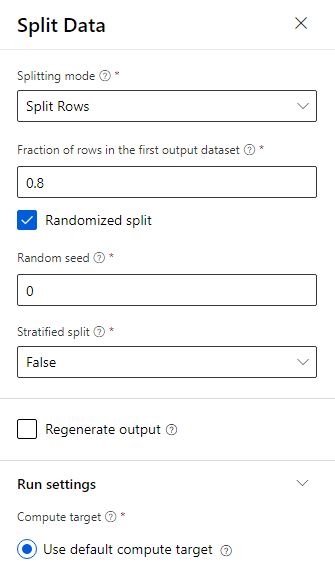
تقسم البيانات 80-20: بنسبة 80٪ لتدريب نموذج التعلم الآلي و20٪ لاختبار النموذج. تستخدم خوارزميات «من فئتين» في مشكلة التصنيف الثنائي هذه.
اسحب مكون Split Data نحو اللوحة.
في جزء الخصائص، أدخل 0.8 من أجل تجزئة الصفوف في مجموعة بيانات الإخراج الأولى.
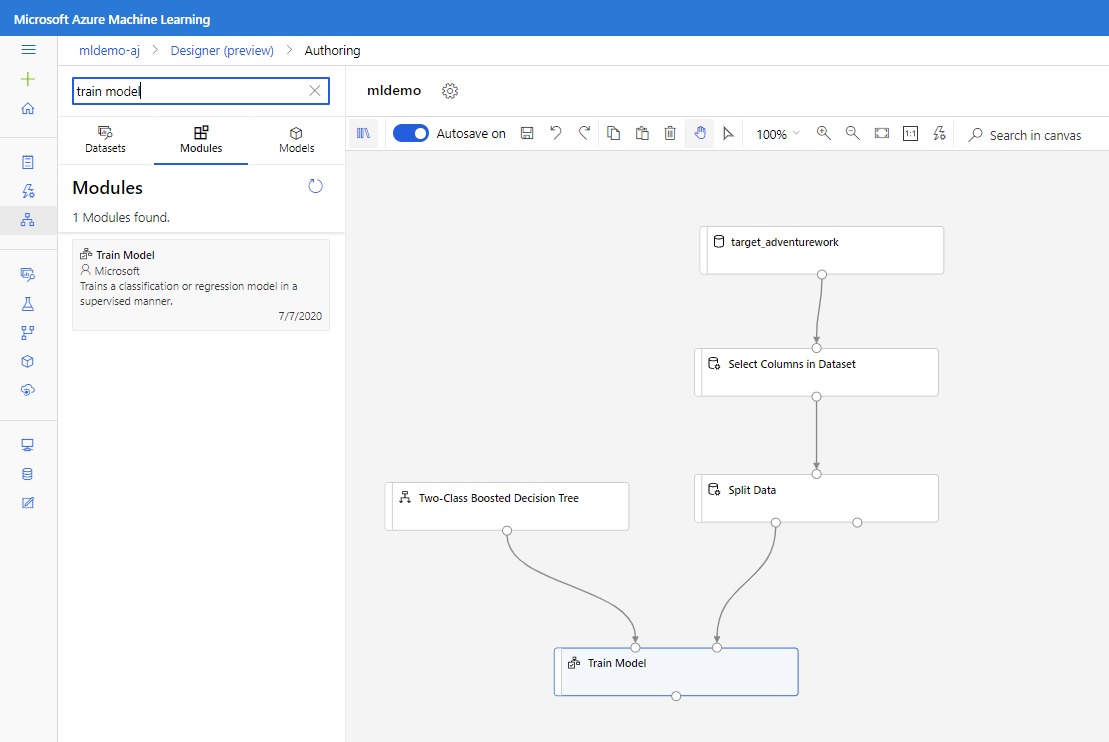
اسحب مكون Two-Class Boosted Decision Tree إلى اللوحة.
اسحب مكون Train Model نحو اللوحة. حدد المدخلات عن طريق توصيلها بمكونات Two-Class Boosted Decision Tree (خوارزمية التعلم الآلي من Microsoft Azure) وSplit Data (بيانات لتدريب الخوارزمية عليها).
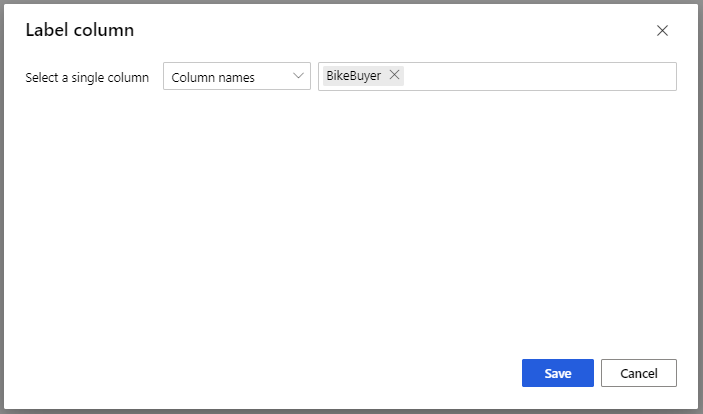
بالنسبة إلى نموذج Train Model، في خيار Label column في جزء الخصائص، حدد Edit column. حدد العمود BikeBuyer باعتباره العمود للتنبؤ ومن ثم حدد Save.
تسجيل نتيجة النموذج
الآن، اختبر كيف يعمل النموذج على بيانات الاختبار. ستحدث عملية مقارنة لخوارزميتين مختلفتين لمعرفة أيهما أفضل أداء. اتبع الخطوات التالية:
اسحب مكون Score Model إلى اللوحة ومن ثم صله بمكونات Train Model وSplit Data.
اسحب Two-Class Bayes Averaged Perceptron إلى لوحة التجربة. ستقارن طريقة أداء هذه الخوارزمية مقارنة بـ Two-Class Boosted Decision Tree.
انسخ مكونات Train Model وScore Model والصقها في اللوحة.
اسحب مكون Evaluate Model إلى اللوحة من أجل مقارنة الخوارزميتين.
انقر فوق submit لإعداد تشغيل البنية الأساسية.
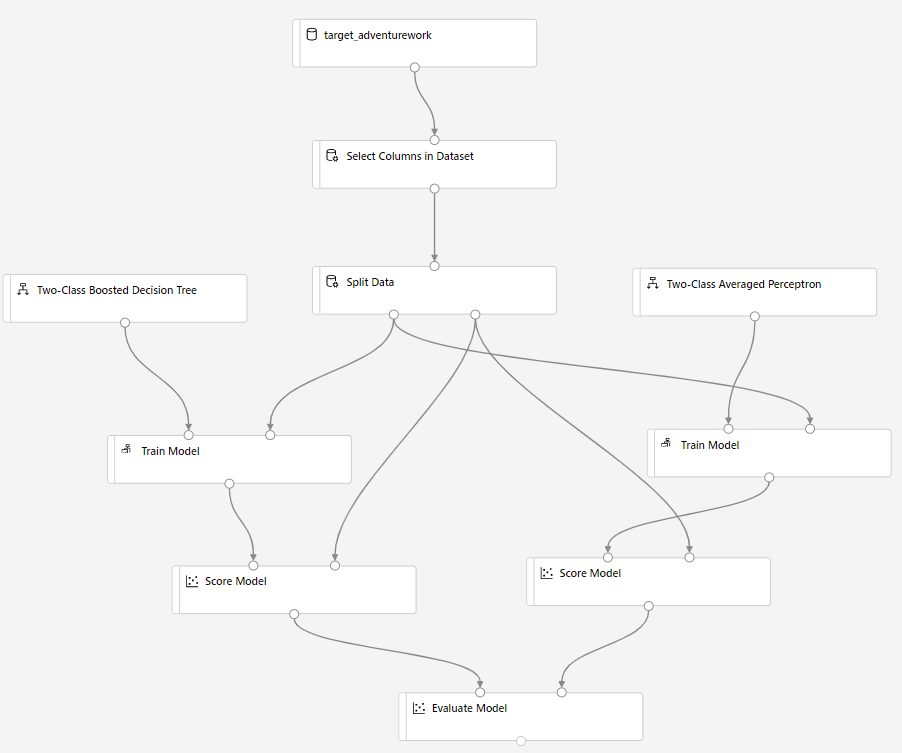
بمجرد انتهاء التشغيل، انقر بزر الماوس الأيمن فوق مكون Evaluate Model ومن ثم انقر فوق Visualize Evaluation results.
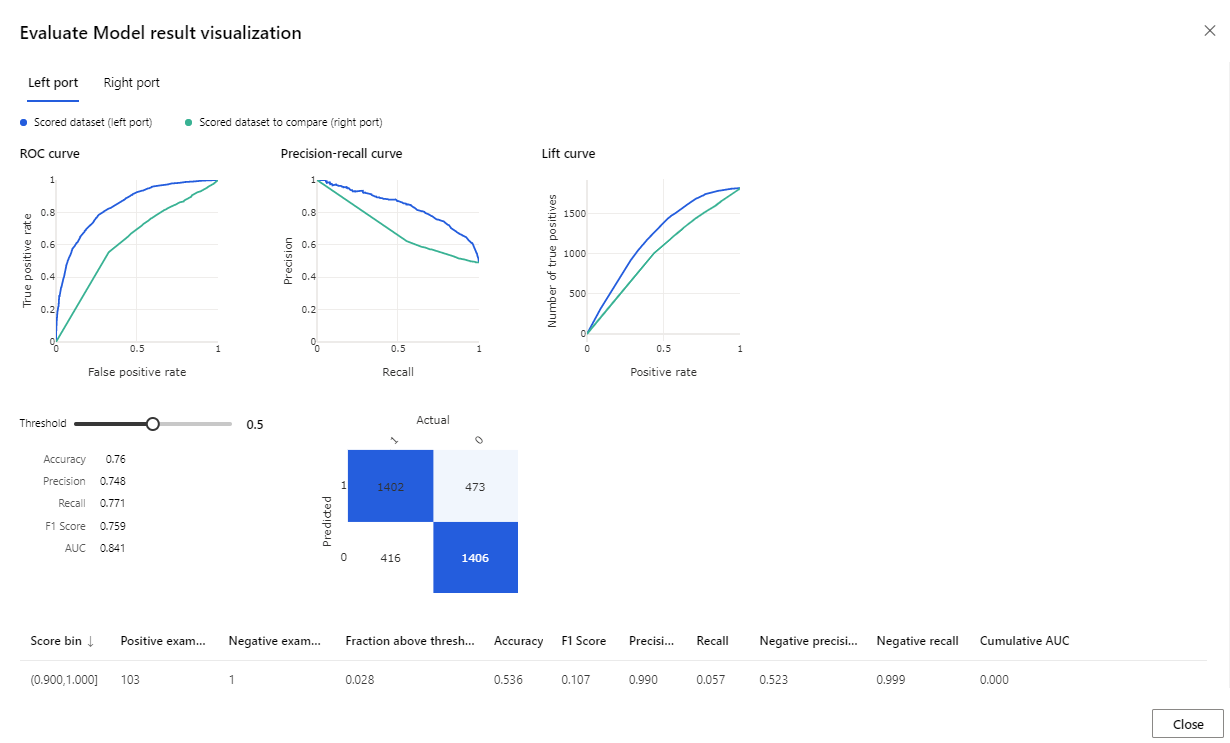

تعد المقاييس المتوفرة منحنى ROC، ومخطط الاسترجاع الدقة، ومنحنى الرفع. انظر إلى هذه المقاييس لترى أن أداء النموذج الأول أفضل من النموذج الثاني. لإلقاء نظرة على ما تنبأ به النموذج الأول، انقر بزر الماوس الأيمن فوق مكون Score Model ومن ثم انقر فوق Visualize Scored dataset لعرض النتائج المتوقعة.
سترى عمودين إضافيين مضافين إلى مجموعة بيانات الاختبار الخاصة بك.
- الاحتمالات المسجلة: احتمالية أن العميل مشتري الدراجة.
- التسميات المسجلة: التصنيف الذي أجراه النموذج - مشتري الدراجة (1) أو لا (0). يعين حد الاحتمال هذا للتسمية إلى 50٪ وبالإمكان تعديله.
قارن العمود BikeBuyer (الفعلي) مع التسميات المسجلة (التنبؤ)، لتري مدى أداء النموذج. بعد ذلك، يمكنك استخدام هذا النموذج من أجل إجراء تنبؤات للعملاء الجدد. يمكنك نشر هذا النموذج كخدمة ويب أو كتابة النتائج مرة أخرى إلى خدمة Azure Synapse.
الخطوات التالية
لمعرفة المزيد من المعلومات عن التعلم الآلي من Microsoft Azure، راجع مقدمة إلى التعلم الآلي على Azure.
تعرف على التسجيل المدمج في مستودع البيانات، هنا.