ملاحظة
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
لتقييم أداء نماذج وتطبيقات الذكاء الاصطناعي التوليدية بدقة عند تطبيقها على مجموعة بيانات كبيرة، يمكنك بدء عملية تقييم. أثناء هذا التقييم، يتم اختبار النموذج أو التطبيق الخاص بك مع مجموعة البيانات المحددة، وسيتم قياس أدائه كميا مع كل من المقاييس الرياضية والمقاييس بمساعدة الذكاء الاصطناعي. يوفر لك تشغيل التقييم هذا رؤى شاملة حول قدرات التطبيق وقيوده.
لإجراء هذا التقييم، يمكنك الاستفادة من وظيفة التقييم في مدخل Azure الذكاء الاصطناعي Foundry، وهو نظام أساسي شامل يوفر أدوات وميزات لتقييم أداء نموذج الذكاء الاصطناعي التوليدي وأمانه. في مدخل Microsoft Azure الذكاء الاصطناعي Foundry، يمكنك تسجيل مقاييس التقييم التفصيلية وعرضها وتحليلها.
في هذه المقالة، ستتعلم إنشاء تقييم يتم تشغيله مقابل نموذج أو مجموعة بيانات اختبار مع مقاييس تقييم مضمنة من واجهة مستخدم Azure الذكاء الاصطناعي Foundry. لمزيد من المرونة، يمكنك إنشاء تدفق تقييم مخصص واستخدام ميزة التقييم المخصص . بدلا من ذلك، إذا كان هدفك هو إجراء تشغيل دفعي فقط دون أي تقييم، يمكنك أيضا استخدام ميزة التقييم المخصص.
المتطلبات الأساسية
لتشغيل تقييم باستخدام مقاييس بمساعدة الذكاء الاصطناعي، يجب أن يكون لديك ما يلي جاهزا:
- مجموعة بيانات اختبار بأحد هذه التنسيقات:
csvأوjsonl. - اتصال Azure OpenAI. نشر أحد هذه النماذج: نماذج GPT 3.5 أو نماذج GPT 4 أو نماذج Davinci. مطلوب فقط عند تشغيل تقييم الجودة بمساعدة الذكاء الاصطناعي.
إنشاء تقييم باستخدام مقاييس التقييم المضمنة
يسمح لك تشغيل التقييم بإنشاء مخرجات قياسية لكل صف بيانات في مجموعة بيانات الاختبار. يمكنك اختيار مقياس تقييم واحد أو أكثر لتقييم الإخراج من جوانب مختلفة. يمكنك إنشاء عملية تقييم من صفحات كتالوج التقييم أو النموذج في مدخل Microsoft Azure الذكاء الاصطناعي Foundry. ثم يبدو أن معالج إنشاء التقييم يرشدك خلال عملية إعداد تشغيل تقييم.
من صفحة التقييم
من القائمة اليمنى القابلة للطي، حدد Evaluation>+ Create a new evaluation.

من صفحة كتالوج النموذج
من القائمة اليمنى القابلة للطي، حدد Model catalog> go to specific model > انتقل إلى علامة التبويب > benchmark Try with your own data. يؤدي هذا إلى فتح لوحة تقييم النموذج لك لإنشاء تشغيل تقييم مقابل النموذج المحدد.

هدف التقييم
عند بدء تقييم من صفحة التقييم، تحتاج إلى تحديد هدف التقييم أولا. من خلال تحديد هدف التقييم المناسب، يمكننا تخصيص التقييم وفقا للطبيعة المحددة للتطبيق الخاص بك، ما يضمن مقاييس دقيقة وملائمة. ندعم نوعين من أهداف التقييم:
- نموذج دقيق: تريد تقييم الإخراج الذي تم إنشاؤه بواسطة النموذج المحدد والمطالبة المعرفة من قبل المستخدم.
- مجموعة البيانات: لديك بالفعل مخرجات أنشأها النموذج الخاص بك في مجموعة بيانات اختبار.

تكوين بيانات الاختبار
عند إدخال معالج إنشاء التقييم، يمكنك التحديد من مجموعات البيانات الموجودة مسبقا أو تحميل مجموعة بيانات جديدة خصيصا للتقييم. تحتاج مجموعة بيانات الاختبار إلى أن يتم استخدام مخرجات النموذج التي تم إنشاؤها للتقييم. سيتم عرض معاينة لبيانات الاختبار في الجزء الأيمن.
اختر مجموعة البيانات الموجودة: يمكنك اختيار مجموعة بيانات الاختبار من مجموعة مجموعة البيانات التي تم إنشاؤها.
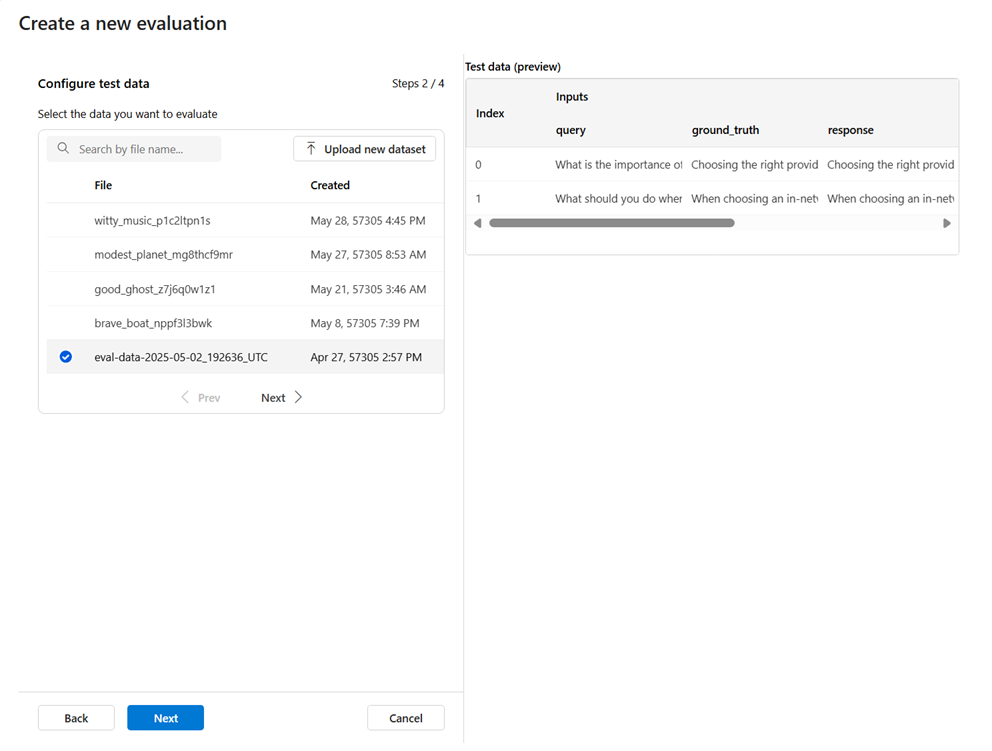
إضافة مجموعة بيانات جديدة: يمكنك تحميل الملفات من التخزين المحلي. نحن ندعم
.csvتنسيقات الملفات فقط.jsonl. سيتم عرض معاينة لبيانات الاختبار في الجزء الأيمن.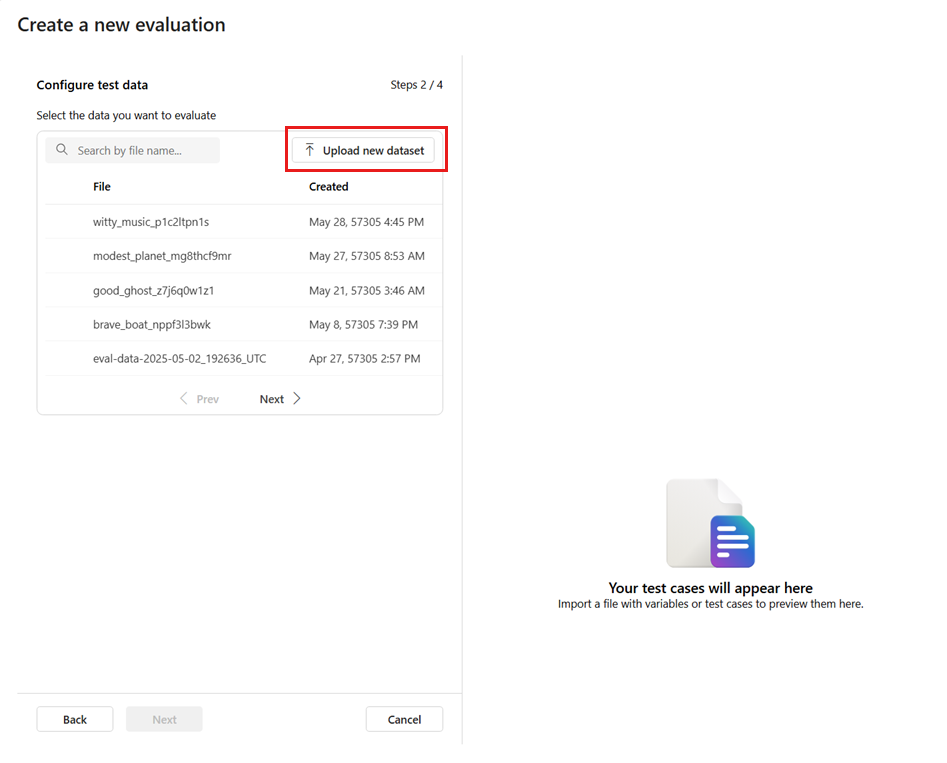


تكوين معايير الاختبار
نحن ندعم ثلاثة أنواع من المقاييس التي تديرها Microsoft لتسهيل تقييم شامل لتطبيقك:
- الذكاء الاصطناعي الجودة (الذكاء الاصطناعي بمساعدة): تقيم هذه المقاييس الجودة العامة والاتساق للمحتوى الذي تم إنشاؤه. لتشغيل هذه المقاييس، يتطلب نشر نموذج كقاض.
- الذكاء الاصطناعي الجودة (NLP): تستند مقاييس NLP هذه إلى الرياضيات، كما أنها تقيم الجودة الإجمالية للمحتوى الذي تم إنشاؤه. غالبا ما تتطلب بيانات الحقيقة الأساسية، ولكنها لا تتطلب نشر النموذج كحكم.
- مقاييس المخاطر والسلامة: تركز هذه المقاييس على تحديد مخاطر المحتوى المحتملة وضمان سلامة المحتوى الذي تم إنشاؤه.

أثناء إضافة معايير الاختبار الخاصة بك، سيتم استخدام مقاييس مختلفة كجزء من التقييم. يمكنك الرجوع إلى الجدول للحصول على القائمة الكاملة من المقاييس التي نقدم الدعم لها في كل سيناريو. لمزيد من المعلومات المتعمقة حول كل تعريف قياس وكيفية حسابه، راجع ما المقصود بالمقيمين؟.
| جودة الذكاء الاصطناعي (بمساعدة الذكاء الاصطناعي) | جودة الذكاء الاصطناعي (معالجة اللغة الطبيعية (NLP)) | مقاييس المخاطر والسلامة |
|---|---|---|
| الأساس، الصلة، الاتساق، الطلاقة، تشابه GPT | درجة F1، ROUGE، درجة، درجة BLEU، درجة GLEU، درجة METEOR | المحتوى المتعلق بالضرر الذاتي، المحتوى البغيض وغير العادل، المحتوى العنيف، المحتوى الجنسي، المواد المحمية، الهجوم غير المباشر |
عند تشغيل الذكاء الاصطناعي تقييم الجودة المساعد، يجب تحديد نموذج GPT لعملية الحساب/التقدير.

الذكاء الاصطناعي مقاييس الجودة (NLP) هي قياسات تستند إلى رياضيا تقيم أداء التطبيق الخاص بك. غالبا ما تتطلب بيانات الحقيقة الأساسية للحساب. ROUGE هي مجموعة من المقاييس. يمكنك تحديد نوع ROUGE لحساب الدرجات. توفر أنواع مختلفة من مقاييس ROUGE طرقا لتقييم جودة إنشاء النص. ROUGE-N يقيس تداخل n-غرام بين النصوص المرشحة والمرجعية.

بالنسبة لمقاييس المخاطر والسلامة، لا تحتاج إلى توفير توزيع. توفر تقييمات أمان مدخل Microsoft Azure الذكاء الاصطناعي Foundry الخدمة الخلفية نموذج GPT-4 الذي يمكن أن يولد درجات خطورة مخاطر المحتوى والمنطق لتمكينك من تقييم التطبيق الخاص بك لمعرفة أضرار المحتوى.

ملاحظة
تتم استضافة مقاييس المخاطر والسلامة بمساعدة الذكاء الاصطناعي بواسطة خدمة Azure الذكاء الاصطناعي Foundry safety service back-end وهي متوفرة فقط في المناطق التالية: شرق الولايات المتحدة 2، وفرنسا الوسطى، وجنوب المملكة المتحدة، ووسط السويد
تنبيه
التوافق مع الإصدارات السابقة لمستخدمي Azure OpenAI الذين تم إلحاقهم ب Foundry Developer Platform:
سيكون لدى المستخدمين الذين سبق لهم استخدام oai.azure.com لإدارة عمليات نشر النماذج الخاصة بهم وتشغيل التقييمات والذين تم إلحاقهم ب Foundry Developer Platform (FDP) بعض القيود عند استخدام ai.azure.com:
أولا، لن يتمكن المستخدمون من عرض تقييماتهم التي تم إنشاؤها باستخدام واجهة برمجة تطبيقات Azure OpenAI. بدلا من ذلك، لعرض هذه، يجب على المستخدمين الانتقال مرة أخرى إلى oai.azure.com.
ثانيا، لن يتمكن المستخدمون من استخدام واجهة برمجة تطبيقات Azure OpenAI لتشغيل التقييمات داخل الذكاء الاصطناعي Foundry. بدلا من ذلك، يجب أن يستمر هؤلاء المستخدمون في استخدام oai.azure.com لهذا. ومع ذلك، يمكن للمستخدمين استخدام مقيمي Azure OpenAI المتوفرين مباشرة في الذكاء الاصطناعي Foundry (ai.azure.com) في خيار إنشاء تقييم مجموعة البيانات. لا يتم دعم خيار تقييم النموذج الدقيق إذا كان النشر ترحيلا من Azure OpenAI إلى Azure Foundry.
لتحميل مجموعة البيانات + إحضار سيناريو التخزين الخاص بك، يجب أن تحدث بعض متطلبات التكوينات:
- يجب أن تكون مصادقة الحساب معرف إنترا.
- يجب إضافة التخزين إلى الحساب (إذا تمت إضافته إلى المشروع، فستحصل على أخطاء في الخدمة).
- يحتاج المستخدم إلى إضافة مشروعه إلى حساب التخزين الخاص به من خلال التحكم في الوصول في مدخل Microsoft Azure.
لمعرفة المزيد حول إنشاء التقييمات على وجه التحديد باستخدام درجات تقييم OpenAI في Azure OpenAI Hub، راجع كيفية استخدام Azure OpenAI في تقييم نماذج Azure الذكاء الاصطناعي Foundry
تعيين البَيَانَات
تعيين البيانات للتقييم: لكل مقياس تمت إضافته، يجب تحديد أعمدة البيانات في مجموعة البيانات التي تتوافق مع المدخلات المطلوبة في التقييم. تتطلب مقاييس التقييم المختلفة أنواعا مميزة من مدخلات البيانات لإجراء حسابات دقيقة.
أثناء التقييم، يتم تقييم استجابة النموذج مقابل المدخلات الرئيسية مثل:
- الاستعلام: مطلوب لجميع المقاييس
- السياق: اختياري
- الحقيقة الأرضية: اختياري، مطلوب لمقاييس جودة الذكاء الاصطناعي (NLP)
تضمن هذه التعيينات محاذاة دقيقة بين بياناتك ومعايير التقييم.

للحصول على إرشادات حول متطلبات تعيين البيانات المحددة لكل مقياس، راجع المعلومات المقدمة في الجدول:
متطلبات قياس الاستعلام والاستجابة
| متري | الاستعلام | استجابه | السياق | الحقيقة الأرضية |
|---|---|---|---|---|
| الارتباط بالواقع | مطلوب: Str | مطلوب: Str | مطلوب: Str | غير متوفر |
| الاتساق | مطلوب: Str | مطلوب: Str | غير متوفر | غير متوفر |
| الطلاقة | مطلوب: Str | مطلوب: Str | غير متوفر | غير متوفر |
| الصلة | مطلوب: Str | مطلوب: Str | مطلوب: Str | غير متوفر |
| تشابه GPT | مطلوب: Str | مطلوب: Str | غير متوفر | مطلوب: Str |
| درجة F1 | غير متوفر | مطلوب: Str | غير متوفر | مطلوب: Str |
| درجة BLEU | غير متوفر | مطلوب: Str | غير متوفر | مطلوب: Str |
| درجة GLEU | غير متوفر | مطلوب: Str | غير متوفر | مطلوب: Str |
| درجة METEOR | غير متوفر | مطلوب: Str | غير متوفر | مطلوب: Str |
| درجة ROUGE | غير متوفر | مطلوب: Str | غير متوفر | مطلوب: Str |
| المحتوى المتعلق بالضرر الذاتي | مطلوب: Str | مطلوب: Str | غير متوفر | غير متوفر |
| محتوى كريه وغير عادل | مطلوب: Str | مطلوب: Str | غير متوفر | غير متوفر |
| محتوى عنيف | مطلوب: Str | مطلوب: Str | غير متوفر | غير متوفر |
| المحتوى الجنسي | مطلوب: Str | مطلوب: Str | غير متوفر | غير متوفر |
| مواد محمية | مطلوب: Str | مطلوب: Str | غير متوفر | غير متوفر |
| هجوم غير مباشر | مطلوب: Str | مطلوب: Str | غير متوفر | غير متوفر |
- الاستعلام: استعلام يبحث عن معلومات محددة.
- الاستجابة: الاستجابة للاستعلام الذي تم إنشاؤه بواسطة النموذج.
- السياق: المصدر الذي تنشأ عنه الاستجابة فيما يتعلق (أي المستندات الأساسية)...
- الحقيقة الأساسية: الاستجابة للاستعلام الذي أنشأه المستخدم/الإنسان كإجابة حقيقية.
المراجعة والانتهاء
بعد إكمال جميع التكوينات الضرورية، يمكنك توفير اسم اختياري لتقييمك. ثم يمكنك المراجعة والمتابعة لتحديد Submit لإرسال تشغيل التقييم.

تقييم النموذج المضبط بدقة
لإنشاء تقييم جديد لنشر النموذج المحدد، يمكنك استخدام نموذج GPT لإنشاء أسئلة نموذجية أو يمكنك الاختيار من مجموعة مجموعة البيانات المنشأة.

تكوين بيانات الاختبار للنموذج المضبط بدقة
إعداد مجموعة بيانات الاختبار المستخدمة للتقييم. يتم إرسال مجموعة البيانات هذه إلى النموذج لإنشاء استجابات للتقييم. لديك خياران لتكوين بيانات الاختبار:
- إنشاء عينة من الأسئلة
- استخدام مجموعة البيانات الموجودة (أو تحميل مجموعة بيانات جديدة)
إنشاء عينة من الأسئلة
إذا لم يكن لديك مجموعة بيانات متاحة بسهولة وترغب في تشغيل تقييم باستخدام عينة صغيرة، فحدد نشر النموذج الذي تريد تقييمه استنادا إلى موضوع تم اختياره. نحن ندعم كلا من نماذج Azure OpenAI والنماذج المفتوحة الأخرى المتوافقة مع نشر واجهة برمجة التطبيقات بلا خادم، مثل نماذج عائلة Meta LIama وPhi-3. يساعد الموضوع على تخصيص المحتوى الذي تم إنشاؤه ليتناسب مع مجال اهتمامك. يتم إنشاء الاستعلامات والاستجابات في الوقت الحقيقي، ولديك خيار إعادة إنشائها حسب الحاجة.

استخدام مجموعة البيانات الخاصة بك
يمكنك أيضا الاختيار من بين مجموعة البيانات المنشأة أو تحميل مجموعة بيانات جديدة.

اختيار مقاييس التقييم
بعد ذلك يمكنك الوصول إلى التالي لتكوين معايير الاختبار الخاصة بك. عند تحديد المعايير الخاصة بك، تتم إضافة المقاييس، وتحتاج إلى تعيين أعمدة مجموعة البيانات إلى الحقول المطلوبة للتقييم. تضمن هذه التعيينات محاذاة دقيقة بين بياناتك ومعايير التقييم. بمجرد تحديد معايير الاختبار التي تريدها، يمكنك مراجعة التقييم وتغيير اسم التقييم اختياريا ثم تحديد إرسال لإرسال تشغيل التقييم والانتقال إلى صفحة التقييم للاطلاع على النتائج.

ملاحظة
يتم حفظ مجموعة البيانات التي تم إنشاؤها في تخزين الكائن الثنائي كبير الحجم للمشروع بمجرد إنشاء تشغيل التقييم.
عرض المقيمين وإدارتهم في مكتبة المقيم
مكتبة المقيم هي مكان مركزي يسمح لك برؤية تفاصيل وحالة المقيمين. يمكنك عرض المقيمين المنسقين من Microsoft وإدارتهم.
تتيح مكتبة المقيم أيضا إدارة الإصدار. يمكنك مقارنة إصدارات مختلفة من عملك، واستعادة الإصدارات السابقة إذا لزم الأمر، والتعاون مع الآخرين بسهولة أكبر.
لاستخدام مكتبة المقيم في مدخل Microsoft Azure الذكاء الاصطناعي Foundry، انتقل إلى صفحة تقييم مشروعك وحدد علامة التبويب مكتبة المقيم .

يمكنك تحديد اسم المقيم للاطلاع على مزيد من التفاصيل. يمكنك رؤية الاسم والوصف والمعلمات، والتحقق من أي ملفات مقترنة بالمقيم. فيما يلي بعض الأمثلة على المقيمين المنسقين من Microsoft:
- بالنسبة لمقيمي الأداء والجودة المنسقين بواسطة Microsoft، يمكنك عرض مطالبة التعليق التوضيحي في صفحة التفاصيل. يمكنك تكييف هذه المطالبات مع حالة الاستخدام الخاصة بك عن طريق تغيير المعلمات أو المعايير وفقا لبياناتك وأهدافك في Azure الذكاء الاصطناعي Evaluation SDK. على سبيل المثال، يمكنك تحديد Groundedness-المقيم والتحقق من ملف Prompty الذي يوضح كيفية حساب المقياس.
- بالنسبة لمقيمي المخاطر والسلامة الذين ترعاهم Microsoft، يمكنك مشاهدة تعريف المقاييس. على سبيل المثال، يمكنك تحديد مقيم المحتوى ذاتي الضرر ومعرفة ما يعنيه وكيف تحدد Microsoft مستويات الخطورة المختلفة لمقياس الأمان هذا.
المحتوى ذو الصلة
تعرف على المزيد حول كيفية تقييم تطبيقات الذكاء الاصطناعي التوليدية: