البرنامج التعليمي: استخدام Personalizer فيAzure Notebook
هام
اعتبارا من 20 سبتمبر 2023، لن تتمكن من إنشاء موارد Personalizer جديدة. يتم إيقاف خدمة Personalizer في 1 أكتوبر 2026.
يستخدم هذا البرنامج التعليمي Personalizer loop في an Azure Notebook، مما يدل على دورة حياة شاملة لـ Personalizer loop.
تقترح الحلقة نوع القهوة الذي يجب على العميل طلبه. يتم تخزين المستخدمين وتفضيلاتهم في مجموعة بيانات المستخدم. يتم تخزين معلومات حول القهوة في مجموعة بيانات القهوة.
المستخدمون والقهوة
يقوم دفتر الملاحظات، الذي يحاكي تفاعل المستخدم مع موقع ويب، بتحديد مستخدم عشوائي ووقت اليوم ونوع الطقس من مجموعة البيانات. ملخص معلومات المستخدم هو:
| العملاء - ميزات السياق | أوقات اليوم | أنواع الطقس |
|---|---|---|
| Alice كائن البيانات الثنائي كبير الحجم كاثي ديف |
الصباح بعد الظهيرة المساء |
مشمس ممطر ثلجي |
لمساعدة Personalizer على التعلم، بمرور الوقت، يعرف النظام أيضًا تفاصيل حول اختيار القهوة لكل شخص.
| القهوة - ميزات الحركة | أنواع درجات الحرارة | أماكن المنشأ | أنواع الشواء | عضوي |
|---|---|---|---|---|
| كابتشينو | ساخن | كينيا | داكن | عضوي |
| المشروب البارد | بارد | البرازيل | خفيف | عضوي |
| موكا مثلج | بارد | إثيوبيا | خفيف | غير عضوي |
| لاتيه | ساخن | البرازيل | داكن | غير عضوي |
الغرض من Personalizer loop هو العثور على أفضل تطابق بين المستخدمين والقهوة بأكبر قدر ممكن من الوقت.
يُعد كود البرنامج التعليمي مُتاحًا للتحميل في مستودع Personalizer Samples GitHub repository.
كيف تعمل المحاكاة
في بداية نظام التشغيل، تعتبر اقتراحات Personalizer ناجحة فقط بنسبة تتراوح بين 20٪ إلى 30٪. يشار إلى هذا النجاح من خلال المكافأة المرسلة مرة أخرى إلى واجهة برمجة التطبيقات Personalizer's Reward API، مع درجة 1. بعد بعض مكالمات Rank and Reward، يتحسن النظام.
بعد الطلبات الأولية، قم بتشغيل التقييم دون اتصال. وهذا يسمح لـ Personalizer بمراجعة البيانات واقتراح سياسة تعلم أفضل. تطبيق نهج التعلم الجديد وتشغيل دفتر الملاحظات مرة أخرى باستخدام 20٪ من عدد الطلبات السابقة. سيكون أداء الحلقة أفضل مع سياسة التعلم الجديدة.
مكالمات Rank and Reward
لكل من بضعة آلاف من الاستدعاءات إلى خدمة Personalizer، ترسل Azure Notebook طلب ترتيب إلى REST API:
- رقم المعرف الفريد لحالة Rank/Request.
- ميزات السياق - اختيار عشوائي للمستخدم والطقس ووقت اليوم - محاكاة مستخدم على موقع ويب أو جهاز محمول
- الإجراءات مع الميزات - جميع بيانات القهوة - التي يقدم منها برنامج Personalizer اقتراحًا لها
يتلقى النظام الطلب، ثم يقارن هذا التنبؤ اختيار المستخدم المعروف لنفس الوقت من اليوم والطقس. إذا كان الاختيار المعروف هو نفس الخيار المتوقع، يتم إرسال Reward 1 مرة أخرى إلى Personalizer. وإلا فإن المكافأة المرسلة هي 0.
إشعار
هذه محاكاة لذلك خوارزمية المكافأة بسيطة. في سيناريو العالم الحقيقي، يجب أن تستخدم الخوارزمية منطق العمل، ربما مع أوزان لجوانب مختلفة من تجربة العميل، من أجل تحديد درجة المكافأة.
المتطلبات الأساسية
- حساب Azure Notebook.
- مورد Azure الذكاء الاصطناعي Personalizer.
- إذا كنت قد استخدمت مورد Personalizer بالفعل، فتأكد من «clear the data» في مدخل Azure للمورد.
- «Upload all the files for this sample into an Azure Notebook project.»
أوصاف الملف:
- Personalizer.ipynb هو دفتر Jupyter لهذا البرنامج التعليمي.
- يتم تخزين مجموعة بيانات المستخدم في كائن JSON.
- يتم تخزين مجموعة بيانات القهوة في كائن JSON.
- مثال طلب JSON هو التنسيق المتوقع لطلب POST إلى Rank API.
تكوين مورد Personalizer
في مدخل Microsoft Azure، قم بتكوينمورد Personalizerمع تعيينتحديث تردد النموذجإلى 15 ثانية ووقت انتظار المكافأةلمدة 10 ثانية. تم العثور على هذه القيم في صفحة «Configuration».
| الإعداد | القيمة |
|---|---|
| تحديث تردد الطراز | 15 ثانية |
| وقت انتظار المكافأة | 10 دقيقة |
تتمتع هذه القيم لها بمدة قصيرة جدًّا من أجل إظهار التغييرات في هذا البرنامج التعليمي. لا ينبغي استخدام هذه القيم في سيناريو الإنتاج دون التحقق من أنها تحقق هدفك من خلال Personalizer loop.
إعداد Azure Notebook
- تغيير Kernel إلى
Python 3.6. - افتح الملف
Personalizer.ipynb.
تشغيل خلايا Notebook
تشغيل كل خلية قابلة للتنفيذ وانتظر حتى تعود. أنت تعلم أنه يتم ذلك عندما تعرض الأقواس الموجودة بجانب الخلية رقمًا بدلًا من *. تشرح المقاطع التالية ما تقوم به كل خلية برمجيًّا وما يمكن توقعه للإنتاجية.
شمل الوحدات النمطية لـ python
شمل الوحدات النمطية المطلوبة لـ python. الخلية لا يوجد بها مخرجات.
import json
import matplotlib.pyplot as plt
import random
import requests
import time
import uuid
تعيين اسم ومفتاح مورد Personalizer
من مدخل Azure، ابحث عن المفتاح ونقطة النهاية في صفحة Quickstart لمورد Personalizer. تغيير قيمة <your-resource-name>لاسم مورد Personalizer. تغيير قيمة <your-resource-key>لمفتاح Personalizer.
# Replace 'personalization_base_url' and 'resource_key' with your valid endpoint values.
personalization_base_url = "https://<your-resource-name>.cognitiveservices.azure.com/"
resource_key = "<your-resource-key>"
طباعة التاريخ والوقت الحاليين
استخدم هذه الدالة لملاحظة أوقات البدء والنهاية للدالة التكرارية والتكرارات.
هذه الخلايا ليس لها مخرجات. تتمتع الدالة بنتائج التاريخ والوقت الحالي عند استدعائها.
# Print out current datetime
def currentDateTime():
currentDT = datetime.datetime.now()
print (str(currentDT))
الحصول على آخر وقت لتحديث الطراز
عند استدعاء الدالة، get_last_updated، تقوم الدالة بطباعة تاريخ ووقت آخر تعديل تم فيه تحديث الطراز.
هذه الخلايا ليس لها مخرجات. تقوم الدالة بإخراج أحدث تاريخ لتدريب النموذج عند الاستدعاء.
تستخدم الدالة GET REST API من أجل الحصول على خصائص الطراز.
# ititialize variable for model's last modified date
modelLastModified = ""
def get_last_updated(currentModifiedDate):
print('-----checking model')
# get model properties
response = requests.get(personalization_model_properties_url, headers = headers, params = None)
print(response)
print(response.json())
# get lastModifiedTime
lastModifiedTime = json.dumps(response.json()["lastModifiedTime"])
if (currentModifiedDate != lastModifiedTime):
currentModifiedDate = lastModifiedTime
print(f'-----model updated: {lastModifiedTime}')
الحصول على تكوين السياسة والخدمة
التحقق من صحة حالة الخدمة مع كلا استدعاءين REST.
هذه الخلايا ليس لها مخرجات. تقوم الدالة بإخراج قيم الخدمة عند استدعائها.
def get_service_settings():
print('-----checking service settings')
# get learning policy
response = requests.get(personalization_model_policy_url, headers = headers, params = None)
print(response)
print(response.json())
# get service settings
response = requests.get(personalization_service_configuration_url, headers = headers, params = None)
print(response)
print(response.json())
إنشاء عناوين URL وقراءة ملفات بيانات JSON
هذه الخلية
- تقوم بإنشاء عناوين URL المستخدمة في مكالمات REST
- تعيين رأس الأمان باستخدام مفتاح مورد Personalizer
- تعيين البذور العشوائية لـ ID حدث Rank
- يقرأ في ملفات البيانات JSON
- استدعاء
get_last_updatedالأسلوب - تمت إزالة نهج التعلم في نتاج المثال - طريقة
get_service_settingsالاستدعاء
تتمتع الخلية بنتاج الاستدعاء إلى الدوالget_last_updatedوget_service_settings.
# build URLs
personalization_rank_url = personalization_base_url + "personalizer/v1.0/rank"
personalization_reward_url = personalization_base_url + "personalizer/v1.0/events/" #add "{eventId}/reward"
personalization_model_properties_url = personalization_base_url + "personalizer/v1.0/model/properties"
personalization_model_policy_url = personalization_base_url + "personalizer/v1.0/configurations/policy"
personalization_service_configuration_url = personalization_base_url + "personalizer/v1.0/configurations/service"
headers = {'Ocp-Apim-Subscription-Key' : resource_key, 'Content-Type': 'application/json'}
# context
users = "users.json"
# action features
coffee = "coffee.json"
# empty JSON for Rank request
requestpath = "example-rankrequest.json"
# initialize random
random.seed(time.time())
userpref = None
rankactionsjsonobj = None
actionfeaturesobj = None
with open(users) as handle:
userpref = json.loads(handle.read())
with open(coffee) as handle:
actionfeaturesobj = json.loads(handle.read())
with open(requestpath) as handle:
rankactionsjsonobj = json.loads(handle.read())
get_last_updated(modelLastModified)
get_service_settings()
print(f'User count {len(userpref)}')
print(f'Coffee count {len(actionfeaturesobj)}')
التحقق من تعيين المخرجاتrewardWaitTimeإلى 10 دقائق وتعيينهاmodelExportFrequencyإلى 15 ثانية.
-----checking model
<Response [200]>
{'creationTime': '0001-01-01T00:00:00+00:00', 'lastModifiedTime': '0001-01-01T00:00:00+00:00'}
-----model updated: "0001-01-01T00:00:00+00:00"
-----checking service settings
<Response [200]>
{...learning policy...}
<Response [200]>
{'rewardWaitTime': '00:10:00', 'defaultReward': 0.0, 'rewardAggregation': 'earliest', 'explorationPercentage': 0.2, 'modelExportFrequency': '00:00:15', 'logRetentionDays': -1}
User count 4
Coffee count 4
استكشاف الأخطاء وإصلاحها في استدعاء REST الأول
هذه الخلية السابقة هي الخلية الأولى التي تستدعي Personalizer. تأكد أن التعليمة البرمجية لحالة REST في المخرجات <Response [200]>. إذا حدث خطأ، مثل 404، ولكنك متأكد من صحة مفتاح المورد والاسم، أعد تحميل دفتر الملاحظات.
تأكد من أن عدد القهوة والمستخدمين على حد سواء 4. إذا حدث خطأ، فتحقق من تحميلك لملفات JSON الثلاثة.
إعداد مخطط متري في مدخل Azure
في وقت لاحق في هذا البرنامج التعليمي، تعتبر العملية طويلة الأمد المكونة من 10,000 طلب مرئية من المتصفح مع مربع نص للتحديث. قد يكون من الأسهل رؤيته في الرسم البياني أو كمجموع إجمالي، عندما تنتهي عملية التشغيل الطويلة. لعرض هذه المعلومات، استخدم المقاييس المتوفرة مع المورد. يمكنك إنشاء المخطط الآن بعد إكمال طلب الخدمة، ثم تحديث المخطط بشكل دوري أثناء سير العملية الطويلة.
في مدخل Azure، حدد مورد Personalizer.
في التنقل بين الموارد، حدد «Metrics» ضمن «Monitoring».
في المخطط، حدد «Add metric».
تم تعيين مساحة اسم المورد والمقياس بالفعل. تحتاج فقط إلى تحديد «metric of successful calls» و» the aggregation of sum».
تغيير عامل تصفية الوقت إلى آخر 4 ساعات.
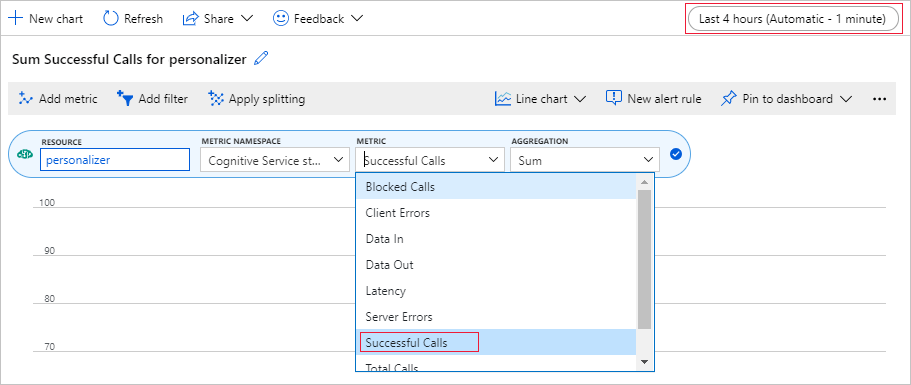
يجب أن تشاهد ثلاث مكالمات ناجحة في التخطيط.
إنشاء ID حدث فريد
تقوم هذه الدالة بإنشاء ID فريد لاستدعاء كل rank. يُستخدم ID لتحديد معلومات استدعاء rank and reward. قد تأتي هذه القيمة من عملية تجارية مثل ID عرض ويب أو ID المعاملة.
الخلية لا يوجد بها مخرجات. تقوم الدالة بإخراج ID الفريد عند استدعائه.
def add_event_id(rankjsonobj):
eventid = uuid.uuid4().hex
rankjsonobj["eventId"] = eventid
return eventid
الحصول على مستخدم عشوائي والطقس ووقت اليوم
تقوم هذه الدالة بتحديد مستخدم فريد والطقس ووقت اليوم، ثم تُضيف هذه العناصر إلى كائن JSON لإرسالها إلى طلب Rank.
الخلية لا يوجد بها مخرجات. عند استدعاء الدالة، تُعيد اسم المستخدم العشوائي والطقس العشوائي والوقت العشوائي من اليوم.
قائمة المستخدمين الأربعة وتفضيلاتهم - يتم عرض بعض التفضيلات فقط للإيجاز:
{
"Alice": {
"Sunny": {
"Morning": "Cold brew",
"Afternoon": "Iced mocha",
"Evening": "Cold brew"
}...
},
"Bob": {
"Sunny": {
"Morning": "Cappucino",
"Afternoon": "Iced mocha",
"Evening": "Cold brew"
}...
},
"Cathy": {
"Sunny": {
"Morning": "Latte",
"Afternoon": "Cold brew",
"Evening": "Cappucino"
}...
},
"Dave": {
"Sunny": {
"Morning": "Iced mocha",
"Afternoon": "Iced mocha",
"Evening": "Iced mocha"
}...
}
}
def add_random_user_and_contextfeatures(namesoption, weatheropt, timeofdayopt, rankjsonobj):
name = namesoption[random.randint(0,3)]
weather = weatheropt[random.randint(0,2)]
timeofday = timeofdayopt[random.randint(0,2)]
rankjsonobj['contextFeatures'] = [{'timeofday': timeofday, 'weather': weather, 'name': name}]
return [name, weather, timeofday]
إضافة جميع بيانات القهوة
تضيف هذه الدالة قائمة القهوة بأكملها إلى كائن JSON لإرسالها إلى طلب Rank.
الخلية لا يوجد بها مخرجات. تُغير الدالة rankjsonobjعند استدعائها.
مثال على ميزات القهوة الواحدة هو:
{
"id": "Cappucino",
"features": [
{
"type": "hot",
"origin": "kenya",
"organic": "yes",
"roast": "dark"
}
}
def add_action_features(rankjsonobj):
rankjsonobj["actions"] = actionfeaturesobj
مقارنة التنبؤ بتفضيل المستخدم المعروف
يتم استدعاء هذه الدالة بعد استدعاء Rank API لكل تكرار.
تقارن هذه الوظيفة تفضيل المستخدم للقهوة؛ استنادًا إلى الطقس ووقت اليوم، مع اقتراح Personalizer للمستخدم لتلك الفلاتر. إذا تطابق الاقتراح، يتم إرجاع درجة 1، وإلا فإن النتيجة تكون 0. الخلية لا يوجد بها مخرجات. تقوم الدالة بإخراج الدرجة عند الاستدعاء.
def get_reward_from_simulated_data(name, weather, timeofday, prediction):
if(userpref[name][weather][timeofday] == str(prediction)):
return 1
return 0
قم بإضافة حلقة من خلال الاستدعاءات إلى Rank and Reward
الخلية التالية هي العمل الرئيسي لـ Notebook، والحصول على مستخدم عشوائي، والحصول على قائمة القهوة، وإرسال كليهما إلى Rank API. مقارنة التنبؤ بتفضيلات المستخدم المعروفة، ثم إرسال المكافأة مرة أخرى إلى خدمة Personalizer.
يتم تشغيل الحلقة لـnum_requestsمرات. يحتاج الطابع الشخصي إلى بضعة آلاف الاستدعاءات إلى Rank and Reward لإنشاء نموذج.
يتبع مثال JSON المُرسل إلى Rank API. قائمة القهوة غير كاملة، للإيجاز. يمكنك ان ترى JSON كاملًا لتناول القهوة في coffee.json.
JSON المرسلة إلى Rank API:
{
'contextFeatures':[
{
'timeofday':'Evening',
'weather':'Snowy',
'name':'Alice'
}
],
'actions':[
{
'id':'Cappucino',
'features':[
{
'type':'hot',
'origin':'kenya',
'organic':'yes',
'roast':'dark'
}
]
}
...rest of coffee list
],
'excludedActions':[
],
'eventId':'b5c4ef3e8c434f358382b04be8963f62',
'deferActivation':False
}
استجابة JSON من Rank API:
{
'ranking': [
{'id': 'Latte', 'probability': 0.85 },
{'id': 'Iced mocha', 'probability': 0.05 },
{'id': 'Cappucino', 'probability': 0.05 },
{'id': 'Cold brew', 'probability': 0.05 }
],
'eventId': '5001bcfe3bb542a1a238e6d18d57f2d2',
'rewardActionId': 'Latte'
}
وأخيرًا، تظهر كل حلقة الاختيار العشوائي للمستخدم والطقس ووقت اليوم والمكافأة المحددة. تشير المكافأة 1 إلى مورد Personalizer الذي حدد نوع القهوة الصحيح للمستخدم والطقس والوقت المحدد من اليوم.
1 Alice Rainy Morning Latte 1
تستخدم الدالة:
- Rank: الـ POST REST API من أجلللحصول على rank.
- Reward: الـ API POST REST للإبلاغ عن reward.
def iterations(n, modelCheck, jsonFormat):
i = 1
# default reward value - assumes failed prediction
reward = 0
# Print out dateTime
currentDateTime()
# collect results to aggregate in graph
total = 0
rewards = []
count = []
# default list of user, weather, time of day
namesopt = ['Alice', 'Bob', 'Cathy', 'Dave']
weatheropt = ['Sunny', 'Rainy', 'Snowy']
timeofdayopt = ['Morning', 'Afternoon', 'Evening']
while(i <= n):
# create unique id to associate with an event
eventid = add_event_id(jsonFormat)
# generate a random sample
[name, weather, timeofday] = add_random_user_and_contextfeatures(namesopt, weatheropt, timeofdayopt, jsonFormat)
# add action features to rank
add_action_features(jsonFormat)
# show JSON to send to Rank
print('To: ', jsonFormat)
# choose an action - get prediction from Personalizer
response = requests.post(personalization_rank_url, headers = headers, params = None, json = jsonFormat)
# show Rank prediction
print ('From: ',response.json())
# compare personalization service recommendation with the simulated data to generate a reward value
prediction = json.dumps(response.json()["rewardActionId"]).replace('"','')
reward = get_reward_from_simulated_data(name, weather, timeofday, prediction)
# show result for iteration
print(f' {i} {currentDateTime()} {name} {weather} {timeofday} {prediction} {reward}')
# send the reward to the service
response = requests.post(personalization_reward_url + eventid + "/reward", headers = headers, params= None, json = { "value" : reward })
# for every N rank requests, compute total correct total
total = total + reward
# every N iteration, get last updated model date and time
if(i % modelCheck == 0):
print("**** 10% of loop found")
get_last_updated(modelLastModified)
# aggregate so chart is easier to read
if(i % 10 == 0):
rewards.append( total)
count.append(i)
total = 0
i = i + 1
# Print out dateTime
currentDateTime()
return [count, rewards]
تشغيل حتى 10,000 تكرار
تشغيل حلقة Personalizer حتى 10,000 تكرار. هذا حدث طويل الأمد. لا تغلق المستعرض الذي يشغل دفتر الملاحظات. قم بتحديث مخطط المقاييس في مدخل Azure بشكل دوري لرؤية إجمالي الاستدعاءات إلى الخدمة. عندما يكون لديك حوالي 20،000 استدعاء، استدعاء rank and reward call لكل تكرارات الحلقة، يتم القيام بكل التكرارات.
# max iterations
num_requests = 200
# check last mod date N% of time - currently 10%
lastModCheck = int(num_requests * .10)
jsonTemplate = rankactionsjsonobj
# main iterations
[count, rewards] = iterations(num_requests, lastModCheck, jsonTemplate)
نتائج المخطط لرؤية التحسن
إنشاء مخطط من count و rewards .
def createChart(x, y):
plt.plot(x, y)
plt.xlabel("Batch of rank events")
plt.ylabel("Correct recommendations per batch")
plt.show()
تشغيل مخطط لعدد 10,000 طلب للرتبة
قم بتشغيل createChartالدالة.
createChart(count,rewards)
قراءة المخطط
يوضح هذا المخطط نجاح النموذج لسياسة التعلم الافتراضية الحالية.

الهدف المثالي أنه بحلول نهاية الاختبار، تمثل الحلقة متوسط معدل النجاح الذي يقترب من 100 في المئة ناقص الاستكشاف. القيمة الافتراضية للاستكشاف هي 20٪.
100-20=80
تم العثور على قيمة الاستكشاف هذه في مدخل Azure، لمورد Personalizer، في صفحة «Configuration».
من أجل العثور على سياسة تعلم أفضل، استنادًا إلى البيانات الخاصة بك إلى Rank API، قم بتشغيل تقييم دون اتصال في المدخل الخاص بحلقة Personalizer.
تشغيل التقييم دون اتصال
في مدخل Azure، افتح صفحة «Evaluations» الخاصة بمورد Personalizer.
حدد «Create Evaluation».
أدخل البيانات المطلوبة من اسم التقييم ونطاق التاريخ لتقييم الحلقة. يجب أن يتضمن نطاق التاريخ الأيام التي تركز عليها للتقييم الخاص بك.
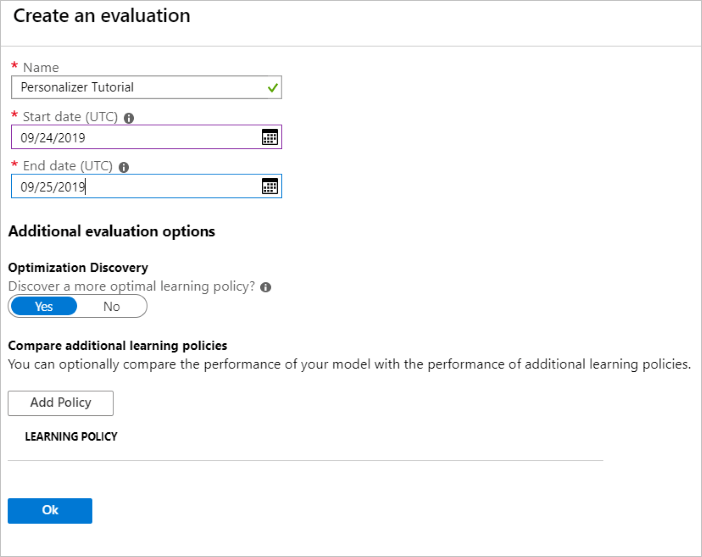
الغرض من تشغيل هذا التقييم دون اتصال هو تحديد ما إذا كان هناك نهج تعلم أفضل للميزات والإجراءات المستخدمة في هذه الحلقة. للعثور على سياسة التعلم الأفضل، تأكد من تشغيل «Optimization Discovery».
حدد «OK»لبدء التقييم.
تدرج صفحة «Evaluations» هذه التقييم الجديد وحالته الحالية. اعتمادًا على كمية البيانات التي لديك، قد يستغرق هذا التقييم بعض الوقت. يمكنك العودة إلى هذه الصفحة بعد بضع دقائق للاطلاع على النتائج.
عند اكتمال التقييم، حدد «evaluation»، ثم حدد «Comparison of different learning policies». وهذا يوضح سياسات التعلم المتاحة وكيف ستتصرف مع البيانات.
حدد «the top-most learning policy in the table» وحدد «Apply». وهذا ينطبق على أفضل سياسة تعلم النموذج الخاص بك وإعادة التدريب.
تغيير تردد طراز التحديث إلى 5 دقائق
- في مدخل Azure، الذي لا يزال على مورد Personalizer، حدد صفحة «Configuration».
- تغيير تكرار تحديث الطراز ووقتانتظار المكافأةحتى 5 دقائق وحدد «Save».
تعرف على المزيد حول وقت انتظار المكافأة وتكرارتحديث النموذج.
#Verify new learning policy and times
get_service_settings()
تحقق من ضبط كل من النتائجrewardWaitTime وmodelExportFrequencyعلى 5 دقائق لكا منهما.
-----checking model
<Response [200]>
{'creationTime': '0001-01-01T00:00:00+00:00', 'lastModifiedTime': '0001-01-01T00:00:00+00:00'}
-----model updated: "0001-01-01T00:00:00+00:00"
-----checking service settings
<Response [200]>
{...learning policy...}
<Response [200]>
{'rewardWaitTime': '00:05:00', 'defaultReward': 0.0, 'rewardAggregation': 'earliest', 'explorationPercentage': 0.2, 'modelExportFrequency': '00:05:00', 'logRetentionDays': -1}
User count 4
Coffee count 4
التحقق من صحة سياسة التعلم الجديدة
العودة إلى ملف Azure Notebooks ثم المتابعة من خلال تشغيل نفس الحلقة ولكن فقط لمدة 2000 تكرار. قم بتحديث مخطط المقاييس في مدخل Azure بشكل دوري لرؤية إجمالي الاستدعاءات إلى الخدمة. عندما يكون لديك حوالي 4000 استدعاء، استدعاء rank and reward لكل تكرار للحلقة ، يتم القيام بالتكرار.
# max iterations
num_requests = 2000
# check last mod date N% of time - currently 10%
lastModCheck2 = int(num_requests * .10)
jsonTemplate2 = rankactionsjsonobj
# main iterations
[count2, rewards2] = iterations(num_requests, lastModCheck2, jsonTemplate)
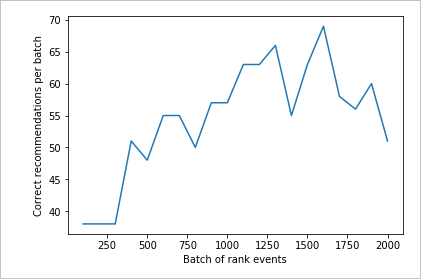
تشغيل مخطط لعدد 2000 طلب rank
قم بتشغيل createChartالدالة.
createChart(count2,rewards2)
راجع المخطط الثاني
يجب أن يظهر المخطط الثاني زيادة واضحة في تنبؤات Rank التي تتوافق مع تفضيلات المستخدم.
تنظيف الموارد
إذا لم تكن تنوي متابعة سلسلة البرنامج التعليمي، قم بتنظيف الموارد التالية:
- حذف مشروع Azure Notebook الخاص بك.
- حذف مورد Personalizer.
الخطوات التالية
دفتر Jupyter وملفات البيانات المستخدمة في هذه العينة متوفرة على GitHub repo لـ Personalizer.