ملاحظة
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
في هذا التشغيل السريع، يمكنك تجربة الكلام في الوقت الحقيقي إلى نص في Azure الذكاء الاصطناعي Foundry.
المتطلبات الأساسية
- اشتراك Azure - إنشاء حساب مجانًا
- بعض ميزات خدمات Azure الذكاء الاصطناعي مجانية لتجربتها في مدخل Azure الذكاء الاصطناعي Foundry. للوصول إلى جميع الإمكانات الموضحة في هذه المقالة، تحتاج إلى توصيل خدمات الذكاء الاصطناعي في Azure الذكاء الاصطناعي Foundry.
تجربة تحويل الكلام إلى نص في الوقت الحقيقي
انتقل إلى مشروع Azure الذكاء الاصطناعي Foundry. إذا كنت بحاجة إلى إنشاء مشروع، فشاهد إنشاء مشروع Azure الذكاء الاصطناعي Foundry.
حدد Playgrounds من الجزء الأيمن ثم حدد ملعبا لاستخدامه. في هذا المثال، حدد Try the Speech playground.
اختياريا، يمكنك تحديد اتصال مختلف لاستخدامه في الملعب. في ملعب الكلام، يمكنك الاتصال بموارد خدمات Azure الذكاء الاصطناعي متعددة الخدمات أو موارد خدمة الكلام.
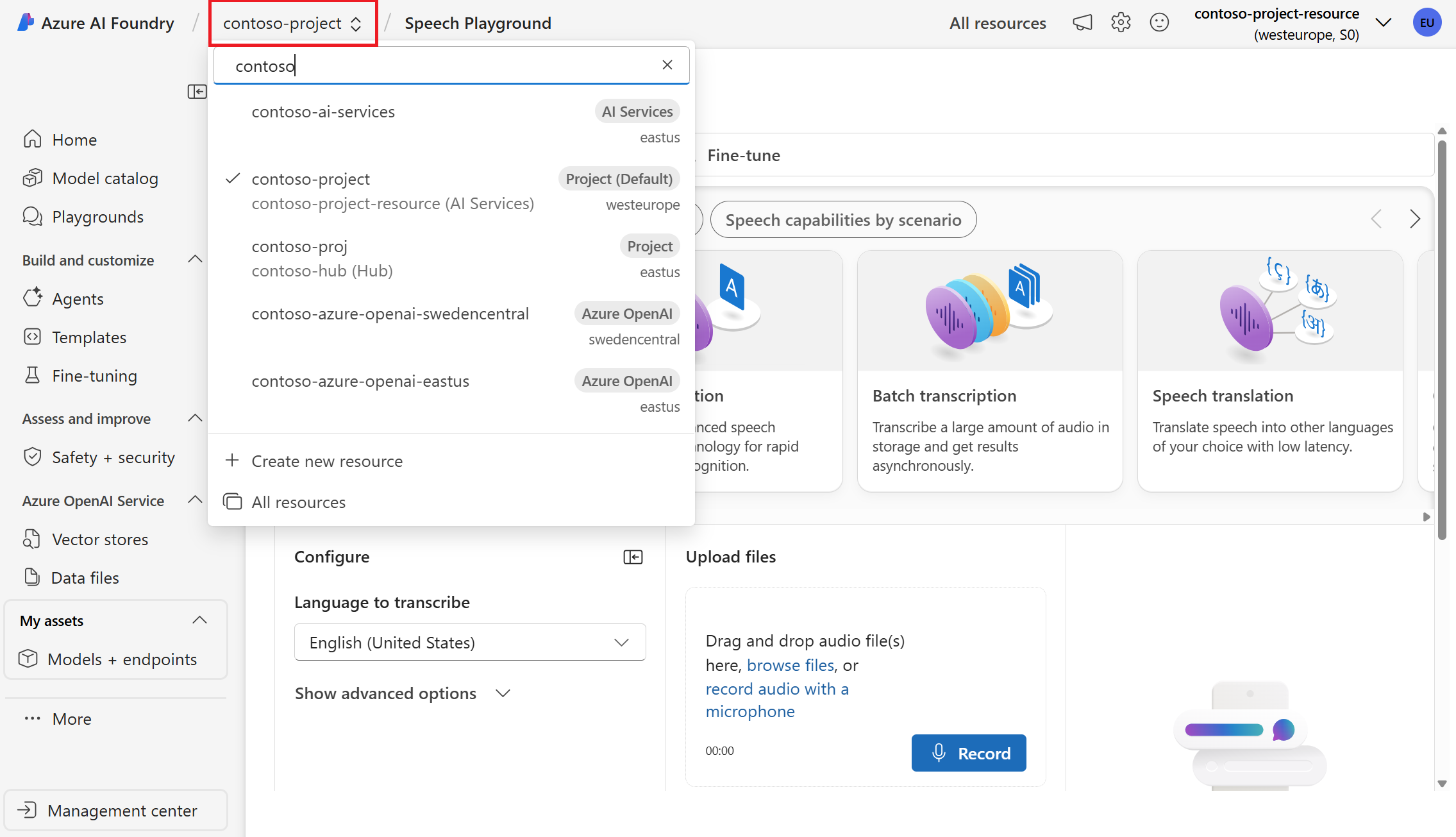
حدد النسخ في الوقت الحقيقي.
حدد إظهار الخيارات المتقدمة لتكوين الكلام إلى خيارات نصية مثل:
- تعريف اللغة: يستخدم لتحديد اللغات المنطوقة في الصوت عند مقارنتها بقائمة اللغات المدعومة. لمزيد من المعلومات حول خيارات تعريف اللغة مثل في البداية والتعرف المستمر، راجع تعريف اللغة.
- يوميات المحاضر: تستخدم لتحديد السماعات وفصلها في الصوت. تميز اليوميات بين المتحدثين المختلفين الذين يشاركون في المحادثة. توفر خدمة الكلام معلومات حول المتحدث الذي كان يتحدث جزءا معينا من الكلام المنسوخ. لمزيد من المعلومات حول يوميات المحاضر، راجع التشغيل السريع للخطاب في الوقت الحقيقي إلى النص باستخدام يوميات المحاضر .
- نقطة النهاية المخصصة: استخدم نموذجا منشورا من الكلام المخصص لتحسين دقة التعرف. لاستخدام النموذج الأساسي ل Microsoft، اترك هذه المجموعة على بلا. لمزيد من المعلومات حول الكلام المخصص، راجع الكلام المخصص.
- تنسيق الإخراج: اختر بين تنسيقات الإخراج البسيطة والمفصلة. يتضمن الإخراج البسيط تنسيق العرض والطوابع الزمنية. يتضمن الإخراج التفصيلي المزيد من التنسيقات (مثل العرض والمعجمي و ITN و ITN المقنع) والطوابع الزمنية وقوائم N-best.
- قائمة العبارات: تحسين دقة النسخ من خلال توفير قائمة بالعبارات المعروفة، مثل أسماء الأشخاص أو مواقع محددة. استخدم الفواصل أو الفواصل المنقطة لفصل كل قيمة في قائمة العبارات. لمزيد من المعلومات حول قوائم العبارات، راجع قوائم العبارات.
حدد ملفا صوتيا لتحميله أو تسجيل الصوت في الوقت الفعلي. في هذا المثال، نستخدم
Call1_separated_16k_health_insurance.wavالملف المتوفر في مستودع Speech SDK على GitHub. يمكنك تنزيل الملف أو استخدام ملف الصوت الخاص بك.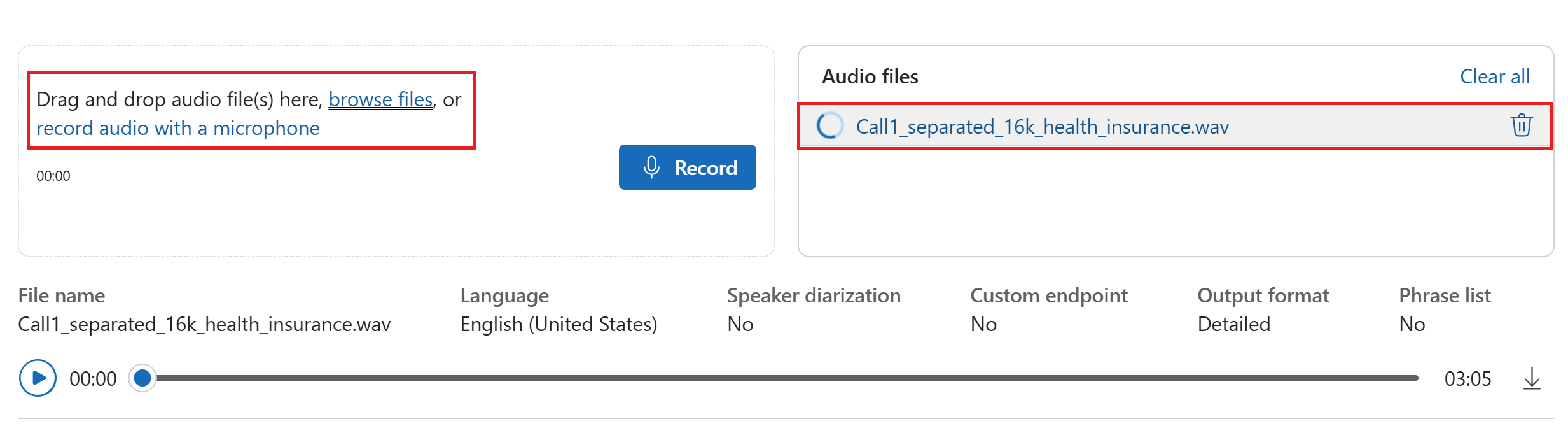
يمكنك عرض النسخ في الوقت الحقيقي في أسفل الصفحة.
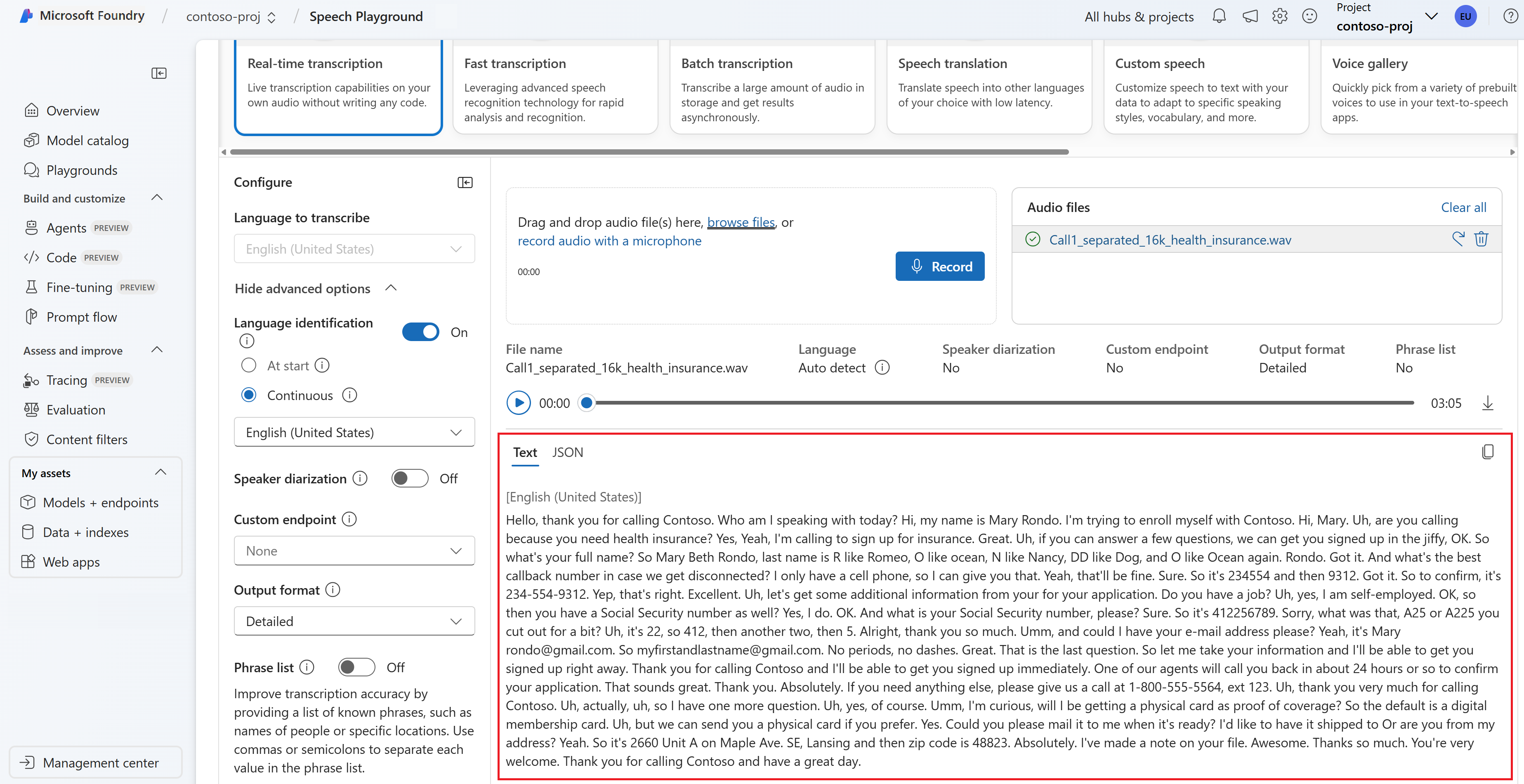
يمكنك تحديد علامة التبويب JSON لمشاهدة إخراج JSON للنسخ. تتضمن
Offsetالخصائص وDurationRecognitionStatusوDisplayLexicalITNوالمزيد.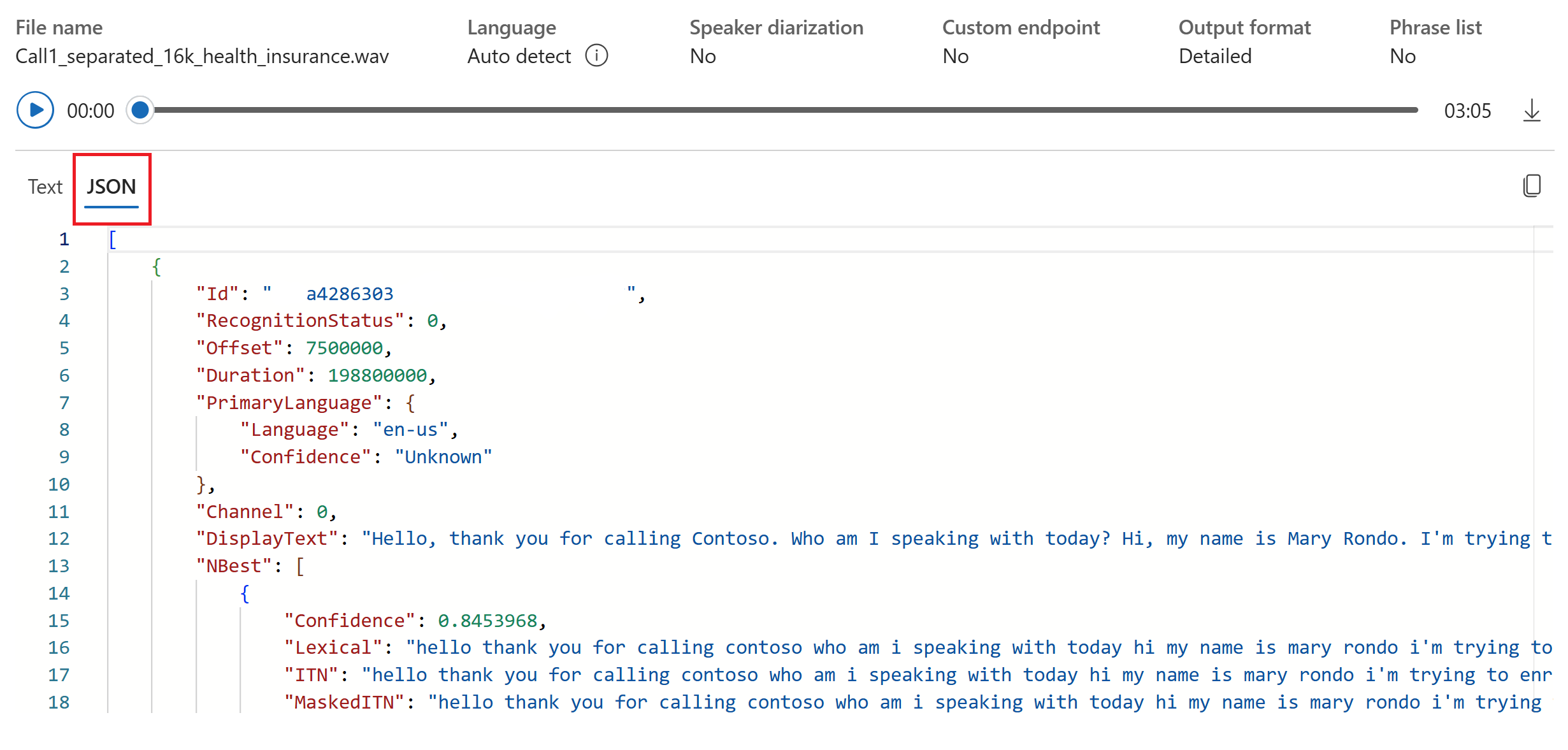





الوثائق | المرجعيةحزمة (NuGet) | عينات إضافية على GitHub
في هذا التشغيل السريع، يمكنك إنشاء وتشغيل تطبيق للتعرف على الكلام ونسخه إلى نص في الوقت الفعلي.
لنسخ الملفات الصوتية بدلا من ذلك بشكل غير متزامن، راجع ما هو النسخ الدفعي. إذا لم تكن متأكدا من حل الكلام إلى النص المناسب لك، فشاهد ما هو تحويل الكلام إلى نص؟
المتطلبات الأساسية
- اشتراك Azure. يمكنك إنشاء حساب مجانا.
- إنشاء مورد خدمات الذكاء الاصطناعي للكلام في مدخل Microsoft Azure.
- احصل على مفتاح مورد الكلام ونقطة النهاية. بعد نشر مورد Speech، حدد Go to resource لعرض المفاتيح وإدارتها.
إعداد البيئة
يتوفر Speech SDK كحزمة NuGet وينفذ .NET Standard 2.0. يمكنك تثبيت Speech SDK لاحقا في هذا الدليل. للحصول على أي متطلبات أخرى، راجع تثبيت Speech SDK.
تعيين متغيرات البيئة
تحتاج إلى مصادقة التطبيق الخاص بك للوصول إلى خدمات Azure الذكاء الاصطناعي. توضح لك هذه المقالة كيفية استخدام متغيرات البيئة لتخزين بيانات الاعتماد الخاصة بك. يمكنك بعد ذلك الوصول إلى متغيرات البيئة من التعليمات البرمجية الخاصة بك لمصادقة التطبيق الخاص بك. للإنتاج، استخدم طريقة أكثر أمانا لتخزين بيانات الاعتماد والوصول إليها.
هام
نوصي بمصادقة معرف Microsoft Entra مع الهويات المدارة لموارد Azure لتجنب تخزين بيانات الاعتماد مع التطبيقات التي تعمل في السحابة.
استخدم مفاتيح واجهة برمجة التطبيقات بحذر. لا تقم بتضمين مفتاح API مباشرة في التعليمات البرمجية الخاصة بك، ولا تنشره بشكل عام. إذا كنت تستخدم مفاتيح واجهة برمجة التطبيقات، فخزنها بأمان في Azure Key Vault، وقم بتدوير المفاتيح بانتظام، وتقييد الوصول إلى Azure Key Vault باستخدام التحكم في الوصول المستند إلى الدور وقيود الوصول إلى الشبكة. لمزيد من المعلومات حول استخدام مفاتيح واجهة برمجة التطبيقات بشكل آمن في تطبيقاتك، راجع مفاتيح واجهة برمجة التطبيقات باستخدام Azure Key Vault.
لمزيد من المعلومات حول أمان خدمات الذكاء الاصطناعي، راجع مصادقة الطلبات إلى خدمات Azure الذكاء الاصطناعي.
لتعيين متغيرات البيئة لمفتاح مورد Speech ونقطة النهاية، افتح نافذة وحدة التحكم، واتبع الإرشادات الخاصة بنظام التشغيل وبيئة التطوير.
- لتعيين
SPEECH_KEYمتغير البيئة، استبدل مفتاحك بأحد مفاتيح المورد الخاص بك. - لتعيين
ENDPOINTمتغير البيئة، استبدل نقطة النهاية بإحدى نقاط النهاية لموردك.
- بالنسبة لنظام التشغيل
- Linux
-
macOS
setx SPEECH_KEY your-key
setx ENDPOINT your-endpoint
ملاحظة
إذا كنت بحاجة فقط إلى الوصول إلى متغيرات البيئة في وحدة التحكم الحالية، يمكنك تعيين متغير البيئة باستخدام set بدلا من setx.
بعد إضافة متغيرات البيئة، قد تحتاج إلى إعادة تشغيل أي برامج تحتاج إلى قراءة متغيرات البيئة، بما في ذلك نافذة وحدة التحكم. على سبيل المثال، إذا كنت تستخدم Visual Studio كمحرر، فقم بإعادة تشغيل Visual Studio قبل تشغيل المثال.
التعرف على الكلام من ميكروفون
نَصِيحة
جرب Azure الذكاء الاصطناعي Speech Toolkit لإنشاء نماذج وتشغيلها بسهولة على Visual Studio Code.
اتبع هذه الخطوات لإنشاء تطبيق وحدة تحكم وتثبيت Speech SDK.
افتح نافذة موجه الأوامر في المجلد حيث تريد المشروع الجديد. قم بتشغيل هذا الأمر لإنشاء تطبيق وحدة تحكم باستخدام .NET CLI.
dotnet new consoleينشئ هذا الأمر ملف Program.cs في دليل المشروع.
قم بتثبيت Speech SDK في مشروعك الجديد باستخدام .NET CLI.
dotnet add package Microsoft.CognitiveServices.Speechاستبدال محتويات Program.cs بالتعليمة البرمجية التالية:
using System; using System.IO; using System.Threading.Tasks; using Microsoft.CognitiveServices.Speech; using Microsoft.CognitiveServices.Speech.Audio; class Program { // This example requires environment variables named "SPEECH_KEY" and "ENDPOINT" static string speechKey = Environment.GetEnvironmentVariable("SPEECH_KEY"); static string endpoint = Environment.GetEnvironmentVariable("ENDPOINT"); static void OutputSpeechRecognitionResult(SpeechRecognitionResult speechRecognitionResult) { switch (speechRecognitionResult.Reason) { case ResultReason.RecognizedSpeech: Console.WriteLine($"RECOGNIZED: Text={speechRecognitionResult.Text}"); break; case ResultReason.NoMatch: Console.WriteLine($"NOMATCH: Speech could not be recognized."); break; case ResultReason.Canceled: var cancellation = CancellationDetails.FromResult(speechRecognitionResult); Console.WriteLine($"CANCELED: Reason={cancellation.Reason}"); if (cancellation.Reason == CancellationReason.Error) { Console.WriteLine($"CANCELED: ErrorCode={cancellation.ErrorCode}"); Console.WriteLine($"CANCELED: ErrorDetails={cancellation.ErrorDetails}"); Console.WriteLine($"CANCELED: Did you set the speech resource key and endpoint values?"); } break; } } async static Task Main(string[] args) { var speechConfig = SpeechConfig.FromEndpoint(speechKey, endpoint); speechConfig.SpeechRecognitionLanguage = "en-US"; using var audioConfig = AudioConfig.FromDefaultMicrophoneInput(); using var speechRecognizer = new SpeechRecognizer(speechConfig, audioConfig); Console.WriteLine("Speak into your microphone."); var speechRecognitionResult = await speechRecognizer.RecognizeOnceAsync(); OutputSpeechRecognitionResult(speechRecognitionResult); } }لتغيير لغة التعرف على الكلام، استبدل
en-USبلغة أخرى مدعومة. على سبيل المثال، استخدمes-ESللإسبانية (إسبانيا). إذا لم تحدد لغة، فإن الإعداد الافتراضي هوen-US. للحصول على تفاصيل حول كيفية تحديد إحدى اللغات المتعددة التي قد يتم التحدث بها، راجع تعريف اللغة.تشغيل تطبيق وحدة التحكم الجديد لبدء التعرف على الكلام من ميكروفون:
dotnet runتحدث إلى الميكروفون عند مطالبتك. يجب أن يظهر ما تتحدثه كنص:
Speak into your microphone. RECOGNIZED: Text=I'm excited to try speech to text.
الملاحظات
فيما يلي بعض الاعتبارات الأخرى:
يستخدم
RecognizeOnceAsyncهذا المثال العملية لنسخ الألفاظ التي تصل إلى 30 ثانية، أو حتى يتم الكشف عن الصمت. للحصول على معلومات حول التعرف المستمر على الصوت الأطول، بما في ذلك المحادثات متعددة اللغات، راجع كيفية التعرف على الكلام.للتعرف على الكلام من ملف صوتي، استخدم
FromWavFileInputبدلا منFromDefaultMicrophoneInput:using var audioConfig = AudioConfig.FromWavFileInput("YourAudioFile.wav");بالنسبة للملفات الصوتية المضغوطة مثل MP4، قم بتثبيت GStreamer واستخدم
PullAudioInputStreamأوPushAudioInputStream. لمزيد من المعلومات، راجع كيفية استخدام صوت الإدخال المضغوط.
تنظيف الموارد
يمكنك استخدام مدخل Microsoft Azure أو واجهة سطر الأوامر Azure (CLI) لإزالة مورد الكلام الذي أنشأته.
الوثائق | المرجعيةحزمة (NuGet) | عينات إضافية على GitHub
في هذا التشغيل السريع، يمكنك إنشاء وتشغيل تطبيق للتعرف على الكلام ونسخه إلى نص في الوقت الفعلي.
لنسخ الملفات الصوتية بدلا من ذلك بشكل غير متزامن، راجع ما هو النسخ الدفعي. إذا لم تكن متأكدا من حل الكلام إلى النص المناسب لك، فشاهد ما هو تحويل الكلام إلى نص؟
المتطلبات الأساسية
- اشتراك Azure. يمكنك إنشاء حساب مجانا.
- إنشاء مورد خدمات الذكاء الاصطناعي للكلام في مدخل Microsoft Azure.
- احصل على مفتاح مورد الكلام ونقطة النهاية. بعد نشر مورد Speech، حدد Go to resource لعرض المفاتيح وإدارتها.
إعداد البيئة
يتوفر Speech SDK كحزمة NuGet وينفذ .NET Standard 2.0. يمكنك تثبيت Speech SDK لاحقا في هذا الدليل. للحصول على متطلبات أخرى، راجع تثبيت Speech SDK.
تعيين متغيرات البيئة
تحتاج إلى مصادقة التطبيق الخاص بك للوصول إلى خدمات Azure الذكاء الاصطناعي. توضح لك هذه المقالة كيفية استخدام متغيرات البيئة لتخزين بيانات الاعتماد الخاصة بك. يمكنك بعد ذلك الوصول إلى متغيرات البيئة من التعليمات البرمجية الخاصة بك لمصادقة التطبيق الخاص بك. للإنتاج، استخدم طريقة أكثر أمانا لتخزين بيانات الاعتماد والوصول إليها.
هام
نوصي بمصادقة معرف Microsoft Entra مع الهويات المدارة لموارد Azure لتجنب تخزين بيانات الاعتماد مع التطبيقات التي تعمل في السحابة.
استخدم مفاتيح واجهة برمجة التطبيقات بحذر. لا تقم بتضمين مفتاح API مباشرة في التعليمات البرمجية الخاصة بك، ولا تنشره بشكل عام. إذا كنت تستخدم مفاتيح واجهة برمجة التطبيقات، فخزنها بأمان في Azure Key Vault، وقم بتدوير المفاتيح بانتظام، وتقييد الوصول إلى Azure Key Vault باستخدام التحكم في الوصول المستند إلى الدور وقيود الوصول إلى الشبكة. لمزيد من المعلومات حول استخدام مفاتيح واجهة برمجة التطبيقات بشكل آمن في تطبيقاتك، راجع مفاتيح واجهة برمجة التطبيقات باستخدام Azure Key Vault.
لمزيد من المعلومات حول أمان خدمات الذكاء الاصطناعي، راجع مصادقة الطلبات إلى خدمات Azure الذكاء الاصطناعي.
لتعيين متغيرات البيئة لمفتاح مورد Speech ونقطة النهاية، افتح نافذة وحدة التحكم، واتبع الإرشادات الخاصة بنظام التشغيل وبيئة التطوير.
- لتعيين
SPEECH_KEYمتغير البيئة، استبدل مفتاحك بأحد مفاتيح المورد الخاص بك. - لتعيين
ENDPOINTمتغير البيئة، استبدل نقطة النهاية بإحدى نقاط النهاية لموردك.
- بالنسبة لنظام التشغيل
- Linux
-
macOS
setx SPEECH_KEY your-key
setx ENDPOINT your-endpoint
ملاحظة
إذا كنت بحاجة فقط إلى الوصول إلى متغيرات البيئة في وحدة التحكم الحالية، يمكنك تعيين متغير البيئة باستخدام set بدلا من setx.
بعد إضافة متغيرات البيئة، قد تحتاج إلى إعادة تشغيل أي برامج تحتاج إلى قراءة متغيرات البيئة، بما في ذلك نافذة وحدة التحكم. على سبيل المثال، إذا كنت تستخدم Visual Studio كمحرر، فقم بإعادة تشغيل Visual Studio قبل تشغيل المثال.
التعرف على الكلام من ميكروفون
نَصِيحة
جرب Azure الذكاء الاصطناعي Speech Toolkit لإنشاء نماذج وتشغيلها بسهولة على Visual Studio Code.
اتبع هذه الخطوات لإنشاء تطبيق وحدة تحكم وتثبيت Speech SDK.
إنشاء مشروع وحدة تحكم C++ جديد في Visual Studio Community المسمى
SpeechRecognition.حدد Tools>Nuget Package Manager>Package Manager Console. في وحدة تحكم مدير الحزم، قم بتشغيل هذا الأمر:
Install-Package Microsoft.CognitiveServices.Speechاستبدل محتويات
SpeechRecognition.cppبالتعليمة البرمجية التالية:#include <iostream> #include <stdlib.h> #include <speechapi_cxx.h> using namespace Microsoft::CognitiveServices::Speech; using namespace Microsoft::CognitiveServices::Speech::Audio; std::string GetEnvironmentVariable(const char* name); int main() { // This example requires environment variables named "SPEECH_KEY" and "ENDPOINT" auto speechKey = GetEnvironmentVariable("SPEECH_KEY"); auto endpoint = GetEnvironmentVariable("ENDPOINT"); if ((size(speechKey) == 0) || (size(endpoint) == 0)) { std::cout << "Please set both SPEECH_KEY and ENDPOINT environment variables." << std::endl; return -1; } auto speechConfig = SpeechConfig::FromEndpoint(speechKey, endpoint); speechConfig->SetSpeechRecognitionLanguage("en-US"); auto audioConfig = AudioConfig::FromDefaultMicrophoneInput(); auto speechRecognizer = SpeechRecognizer::FromConfig(speechConfig, audioConfig); std::cout << "Speak into your microphone.\n"; auto result = speechRecognizer->RecognizeOnceAsync().get(); if (result->Reason == ResultReason::RecognizedSpeech) { std::cout << "RECOGNIZED: Text=" << result->Text << std::endl; } else if (result->Reason == ResultReason::NoMatch) { std::cout << "NOMATCH: Speech could not be recognized." << std::endl; } else if (result->Reason == ResultReason::Canceled) { auto cancellation = CancellationDetails::FromResult(result); std::cout << "CANCELED: Reason=" << (int)cancellation->Reason << std::endl; if (cancellation->Reason == CancellationReason::Error) { std::cout << "CANCELED: ErrorCode=" << (int)cancellation->ErrorCode << std::endl; std::cout << "CANCELED: ErrorDetails=" << cancellation->ErrorDetails << std::endl; std::cout << "CANCELED: Did you set the speech resource key and endpoint values?" << std::endl; } } } std::string GetEnvironmentVariable(const char* name) { #if defined(_MSC_VER) size_t requiredSize = 0; (void)getenv_s(&requiredSize, nullptr, 0, name); if (requiredSize == 0) { return ""; } auto buffer = std::make_unique<char[]>(requiredSize); (void)getenv_s(&requiredSize, buffer.get(), requiredSize, name); return buffer.get(); #else auto value = getenv(name); return value ? value : ""; #endif }لتغيير لغة التعرف على الكلام، استبدل
en-USبلغة أخرى مدعومة. على سبيل المثال، استخدمes-ESللإسبانية (إسبانيا). إذا لم تحدد لغة، فإن الإعداد الافتراضي هوen-US. للحصول على تفاصيل حول كيفية تحديد إحدى اللغات المتعددة التي قد يتم التحدث بها، راجع تعريف اللغة.لبدء التعرف على الكلام من ميكروفون، قم بإنشاء وتشغيل تطبيق وحدة التحكم الجديد.
تحدث إلى الميكروفون عند مطالبتك. يجب أن يظهر ما تتحدثه كنص:
Speak into your microphone. RECOGNIZED: Text=I'm excited to try speech to text.
الملاحظات
فيما يلي بعض الاعتبارات الأخرى:
يستخدم
RecognizeOnceAsyncهذا المثال العملية لنسخ الألفاظ التي تصل إلى 30 ثانية، أو حتى يتم الكشف عن الصمت. للحصول على معلومات حول التعرف المستمر على الصوت الأطول، بما في ذلك المحادثات متعددة اللغات، راجع كيفية التعرف على الكلام.للتعرف على الكلام من ملف صوتي، استخدم
FromWavFileInputبدلا منFromDefaultMicrophoneInput:auto audioConfig = AudioConfig::FromWavFileInput("YourAudioFile.wav");بالنسبة للملفات الصوتية المضغوطة مثل MP4، قم بتثبيت GStreamer واستخدم
PullAudioInputStreamأوPushAudioInputStream. لمزيد من المعلومات، راجع كيفية استخدام صوت الإدخال المضغوط.
تنظيف الموارد
يمكنك استخدام مدخل Microsoft Azure أو واجهة سطر الأوامر Azure (CLI) لإزالة مورد الكلام الذي أنشأته.
الوثائق | المرجعيةالحزمة (Go) | عينات إضافية على GitHub
في هذا التشغيل السريع، يمكنك إنشاء وتشغيل تطبيق للتعرف على الكلام ونسخه إلى نص في الوقت الفعلي.
لنسخ الملفات الصوتية بدلا من ذلك بشكل غير متزامن، راجع ما هو النسخ الدفعي. إذا لم تكن متأكدا من حل الكلام إلى النص المناسب لك، فشاهد ما هو تحويل الكلام إلى نص؟
المتطلبات الأساسية
- اشتراك Azure. يمكنك إنشاء حساب مجانا.
- إنشاء مورد الذكاء الاصطناعي Foundry ل Speech في مدخل Microsoft Azure.
- احصل على مفتاح مورد الكلام والمنطقة. بعد نشر مورد Speech، حدد Go to resource لعرض المفاتيح وإدارتها.
إعداد البيئة
تثبيت Speech SDK ل Go. للحصول على المتطلبات والإرشادات، راجع تثبيت Speech SDK.
تعيين متغيرات البيئة
تحتاج إلى مصادقة التطبيق الخاص بك للوصول إلى خدمات Azure الذكاء الاصطناعي. توضح لك هذه المقالة كيفية استخدام متغيرات البيئة لتخزين بيانات الاعتماد الخاصة بك. يمكنك بعد ذلك الوصول إلى متغيرات البيئة من التعليمات البرمجية الخاصة بك لمصادقة التطبيق الخاص بك. للإنتاج، استخدم طريقة أكثر أمانا لتخزين بيانات الاعتماد والوصول إليها.
هام
نوصي بمصادقة معرف Microsoft Entra مع الهويات المدارة لموارد Azure لتجنب تخزين بيانات الاعتماد مع التطبيقات التي تعمل في السحابة.
استخدم مفاتيح واجهة برمجة التطبيقات بحذر. لا تقم بتضمين مفتاح API مباشرة في التعليمات البرمجية الخاصة بك، ولا تنشره بشكل عام. إذا كنت تستخدم مفاتيح واجهة برمجة التطبيقات، فخزنها بأمان في Azure Key Vault، وقم بتدوير المفاتيح بانتظام، وتقييد الوصول إلى Azure Key Vault باستخدام التحكم في الوصول المستند إلى الدور وقيود الوصول إلى الشبكة. لمزيد من المعلومات حول استخدام مفاتيح واجهة برمجة التطبيقات بشكل آمن في تطبيقاتك، راجع مفاتيح واجهة برمجة التطبيقات باستخدام Azure Key Vault.
لمزيد من المعلومات حول أمان خدمات الذكاء الاصطناعي، راجع مصادقة الطلبات إلى خدمات Azure الذكاء الاصطناعي.
لتعيين متغيرات البيئة لمفتاح مورد الكلام والمنطقة، افتح نافذة وحدة التحكم، واتبع الإرشادات الخاصة بنظام التشغيل وبيئة التطوير.
- لتعيين
SPEECH_KEYمتغير البيئة، استبدل مفتاحك بأحد مفاتيح المورد الخاص بك. - لتعيين
SPEECH_REGIONمتغير البيئة، استبدل منطقتك بإحدى المناطق لموردك.
- بالنسبة لنظام التشغيل
- Linux
-
macOS
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
ملاحظة
إذا كنت بحاجة فقط إلى الوصول إلى متغيرات البيئة في وحدة التحكم الحالية، يمكنك تعيين متغير البيئة باستخدام set بدلا من setx.
بعد إضافة متغيرات البيئة، قد تحتاج إلى إعادة تشغيل أي برامج تحتاج إلى قراءة متغيرات البيئة، بما في ذلك نافذة وحدة التحكم. على سبيل المثال، إذا كنت تستخدم Visual Studio كمحرر، فقم بإعادة تشغيل Visual Studio قبل تشغيل المثال.
التعرف على الكلام من ميكروفون
اتبع هذه الخطوات لإنشاء وحدة GO.
افتح نافذة موجه الأوامر في المجلد حيث تريد المشروع الجديد. إنشاء ملف جديد يسمى speech-recognition.go.
انسخ التعليمات البرمجية التالية إلى speech-recognition.go:
package main import ( "bufio" "fmt" "os" "github.com/Microsoft/cognitive-services-speech-sdk-go/audio" "github.com/Microsoft/cognitive-services-speech-sdk-go/speech" ) func sessionStartedHandler(event speech.SessionEventArgs) { defer event.Close() fmt.Println("Session Started (ID=", event.SessionID, ")") } func sessionStoppedHandler(event speech.SessionEventArgs) { defer event.Close() fmt.Println("Session Stopped (ID=", event.SessionID, ")") } func recognizingHandler(event speech.SpeechRecognitionEventArgs) { defer event.Close() fmt.Println("Recognizing:", event.Result.Text) } func recognizedHandler(event speech.SpeechRecognitionEventArgs) { defer event.Close() fmt.Println("Recognized:", event.Result.Text) } func cancelledHandler(event speech.SpeechRecognitionCanceledEventArgs) { defer event.Close() fmt.Println("Received a cancellation: ", event.ErrorDetails) fmt.Println("Did you set the speech resource key and region values?") } func main() { // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" speechKey := os.Getenv("SPEECH_KEY") speechRegion := os.Getenv("SPEECH_REGION") audioConfig, err := audio.NewAudioConfigFromDefaultMicrophoneInput() if err != nil { fmt.Println("Got an error: ", err) return } defer audioConfig.Close() speechConfig, err := speech.NewSpeechConfigFromSubscription(speechKey, speechRegion) if err != nil { fmt.Println("Got an error: ", err) return } defer speechConfig.Close() speechRecognizer, err := speech.NewSpeechRecognizerFromConfig(speechConfig, audioConfig) if err != nil { fmt.Println("Got an error: ", err) return } defer speechRecognizer.Close() speechRecognizer.SessionStarted(sessionStartedHandler) speechRecognizer.SessionStopped(sessionStoppedHandler) speechRecognizer.Recognizing(recognizingHandler) speechRecognizer.Recognized(recognizedHandler) speechRecognizer.Canceled(cancelledHandler) speechRecognizer.StartContinuousRecognitionAsync() defer speechRecognizer.StopContinuousRecognitionAsync() bufio.NewReader(os.Stdin).ReadBytes('\n') }قم بتشغيل الأوامر التالية لإنشاء ملف go.mod يرتبط بالمكونات المستضافة على GitHub:
go mod init speech-recognition go get github.com/Microsoft/cognitive-services-speech-sdk-goإنشاء التعليمات البرمجية وتشغيلها:
go build go run speech-recognition
تنظيف الموارد
يمكنك استخدام مدخل Microsoft Azure أو واجهة سطر الأوامر Azure (CLI) لإزالة مورد الكلام الذي أنشأته.
الوثائق | المرجعيةعينات إضافية على GitHub
في هذا التشغيل السريع، يمكنك إنشاء وتشغيل تطبيق للتعرف على الكلام ونسخه إلى نص في الوقت الفعلي.
لنسخ الملفات الصوتية بدلا من ذلك بشكل غير متزامن، راجع ما هو النسخ الدفعي. إذا لم تكن متأكدا من حل الكلام إلى النص المناسب لك، فشاهد ما هو تحويل الكلام إلى نص؟
المتطلبات الأساسية
- اشتراك Azure. يمكنك إنشاء حساب مجانا.
- إنشاء مورد خدمات الذكاء الاصطناعي للكلام في مدخل Microsoft Azure.
- احصل على مفتاح مورد الكلام ونقطة النهاية. بعد نشر مورد Speech، حدد Go to resource لعرض المفاتيح وإدارتها.
إعداد البيئة
لإعداد بيئتك، قم بتثبيت Speech SDK. تعمل العينة في هذا التشغيل السريع مع وقت تشغيل Java.
قم بتثبيت Apache Maven. ثم قم بتشغيل
mvn -vلتأكيد التثبيت الناجح.أنشئ ملفا جديدا
pom.xmlفي جذر مشروعك، وانسخ التعليمات البرمجية التالية فيه:<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.microsoft.cognitiveservices.speech.samples</groupId> <artifactId>quickstart-eclipse</artifactId> <version>1.0.0-SNAPSHOT</version> <build> <sourceDirectory>src</sourceDirectory> <plugins> <plugin> <artifactId>maven-compiler-plugin</artifactId> <version>3.7.0</version> <configuration> <source>1.8</source> <target>1.8</target> </configuration> </plugin> </plugins> </build> <dependencies> <dependency> <groupId>com.microsoft.cognitiveservices.speech</groupId> <artifactId>client-sdk</artifactId> <version>1.43.0</version> </dependency> </dependencies> </project>تثبيت Speech SDK والتبعيات.
mvn clean dependency:copy-dependencies
تعيين متغيرات البيئة
تحتاج إلى مصادقة التطبيق الخاص بك للوصول إلى خدمات Azure الذكاء الاصطناعي. توضح لك هذه المقالة كيفية استخدام متغيرات البيئة لتخزين بيانات الاعتماد الخاصة بك. يمكنك بعد ذلك الوصول إلى متغيرات البيئة من التعليمات البرمجية الخاصة بك لمصادقة التطبيق الخاص بك. للإنتاج، استخدم طريقة أكثر أمانا لتخزين بيانات الاعتماد والوصول إليها.
هام
نوصي بمصادقة معرف Microsoft Entra مع الهويات المدارة لموارد Azure لتجنب تخزين بيانات الاعتماد مع التطبيقات التي تعمل في السحابة.
استخدم مفاتيح واجهة برمجة التطبيقات بحذر. لا تقم بتضمين مفتاح API مباشرة في التعليمات البرمجية الخاصة بك، ولا تنشره بشكل عام. إذا كنت تستخدم مفاتيح واجهة برمجة التطبيقات، فخزنها بأمان في Azure Key Vault، وقم بتدوير المفاتيح بانتظام، وتقييد الوصول إلى Azure Key Vault باستخدام التحكم في الوصول المستند إلى الدور وقيود الوصول إلى الشبكة. لمزيد من المعلومات حول استخدام مفاتيح واجهة برمجة التطبيقات بشكل آمن في تطبيقاتك، راجع مفاتيح واجهة برمجة التطبيقات باستخدام Azure Key Vault.
لمزيد من المعلومات حول أمان خدمات الذكاء الاصطناعي، راجع مصادقة الطلبات إلى خدمات Azure الذكاء الاصطناعي.
لتعيين متغيرات البيئة لمفتاح مورد Speech ونقطة النهاية، افتح نافذة وحدة التحكم، واتبع الإرشادات الخاصة بنظام التشغيل وبيئة التطوير.
- لتعيين
SPEECH_KEYمتغير البيئة، استبدل مفتاحك بأحد مفاتيح المورد الخاص بك. - لتعيين
ENDPOINTمتغير البيئة، استبدل نقطة النهاية بإحدى نقاط النهاية لموردك.
- بالنسبة لنظام التشغيل
- Linux
-
macOS
setx SPEECH_KEY your-key
setx ENDPOINT your-endpoint
ملاحظة
إذا كنت بحاجة فقط إلى الوصول إلى متغيرات البيئة في وحدة التحكم الحالية، يمكنك تعيين متغير البيئة باستخدام set بدلا من setx.
بعد إضافة متغيرات البيئة، قد تحتاج إلى إعادة تشغيل أي برامج تحتاج إلى قراءة متغيرات البيئة، بما في ذلك نافذة وحدة التحكم. على سبيل المثال، إذا كنت تستخدم Visual Studio كمحرر، فقم بإعادة تشغيل Visual Studio قبل تشغيل المثال.
التعرف على الكلام من ميكروفون
اتبع هذه الخطوات لإنشاء تطبيق وحدة تحكم للتعرف على الكلام.
إنشاء ملف جديد باسم SpeechRecognition.java في نفس الدليل الجذر للمشروع.
انسخ التعليمات البرمجية التالية في SpeechRecognition.java:
import com.microsoft.cognitiveservices.speech.*; import com.microsoft.cognitiveservices.speech.audio.AudioConfig; import java.util.concurrent.ExecutionException; import java.util.concurrent.Future; public class SpeechRecognition { // This example requires environment variables named "SPEECH_KEY" and "ENDPOINT" private static String speechKey = System.getenv("SPEECH_KEY"); private static String endpoint = System.getenv("ENDPOINT"); public static void main(String[] args) throws InterruptedException, ExecutionException { SpeechConfig speechConfig = SpeechConfig.fromEndpoint(speechKey, endpoint); speechConfig.setSpeechRecognitionLanguage("en-US"); recognizeFromMicrophone(speechConfig); } public static void recognizeFromMicrophone(SpeechConfig speechConfig) throws InterruptedException, ExecutionException { AudioConfig audioConfig = AudioConfig.fromDefaultMicrophoneInput(); SpeechRecognizer speechRecognizer = new SpeechRecognizer(speechConfig, audioConfig); System.out.println("Speak into your microphone."); Future<SpeechRecognitionResult> task = speechRecognizer.recognizeOnceAsync(); SpeechRecognitionResult speechRecognitionResult = task.get(); if (speechRecognitionResult.getReason() == ResultReason.RecognizedSpeech) { System.out.println("RECOGNIZED: Text=" + speechRecognitionResult.getText()); } else if (speechRecognitionResult.getReason() == ResultReason.NoMatch) { System.out.println("NOMATCH: Speech could not be recognized."); } else if (speechRecognitionResult.getReason() == ResultReason.Canceled) { CancellationDetails cancellation = CancellationDetails.fromResult(speechRecognitionResult); System.out.println("CANCELED: Reason=" + cancellation.getReason()); if (cancellation.getReason() == CancellationReason.Error) { System.out.println("CANCELED: ErrorCode=" + cancellation.getErrorCode()); System.out.println("CANCELED: ErrorDetails=" + cancellation.getErrorDetails()); System.out.println("CANCELED: Did you set the speech resource key and endpoint values?"); } } System.exit(0); } }لتغيير لغة التعرف على الكلام، استبدل
en-USبلغة أخرى مدعومة. على سبيل المثال، استخدمes-ESللإسبانية (إسبانيا). إذا لم تحدد لغة، فإن الإعداد الافتراضي هوen-US. للحصول على تفاصيل حول كيفية تحديد إحدى اللغات المتعددة التي قد يتم التحدث بها، راجع تعريف اللغة.تشغيل تطبيق وحدة التحكم الجديد لبدء التعرف على الكلام من ميكروفون:
javac SpeechRecognition.java -cp ".;target\dependency\*" java -cp ".;target\dependency\*" SpeechRecognitionتحدث إلى الميكروفون عند مطالبتك. يجب أن يظهر ما تتحدثه كنص:
Speak into your microphone. RECOGNIZED: Text=I'm excited to try speech to text.
الملاحظات
فيما يلي بعض الاعتبارات الأخرى:
يستخدم
RecognizeOnceAsyncهذا المثال العملية لنسخ الألفاظ التي تصل إلى 30 ثانية، أو حتى يتم الكشف عن الصمت. للحصول على معلومات حول التعرف المستمر على الصوت الأطول، بما في ذلك المحادثات متعددة اللغات، راجع كيفية التعرف على الكلام.للتعرف على الكلام من ملف صوتي، استخدم
fromWavFileInputبدلا منfromDefaultMicrophoneInput:AudioConfig audioConfig = AudioConfig.fromWavFileInput("YourAudioFile.wav");بالنسبة للملفات الصوتية المضغوطة مثل MP4، قم بتثبيت GStreamer واستخدم
PullAudioInputStreamأوPushAudioInputStream. لمزيد من المعلومات، راجع كيفية استخدام صوت الإدخال المضغوط.
تنظيف الموارد
يمكنك استخدام مدخل Microsoft Azure أو واجهة سطر الأوامر Azure (CLI) لإزالة مورد الكلام الذي أنشأته.
الوثائق | المرجعيةالحزمة (npm) | عينات إضافية على GitHub | التعليمات البرمجية المصدر للمكتبة
في هذا التشغيل السريع، يمكنك إنشاء وتشغيل تطبيق للتعرف على الكلام ونسخه إلى نص في الوقت الفعلي.
لنسخ الملفات الصوتية بدلا من ذلك بشكل غير متزامن، راجع ما هو النسخ الدفعي. إذا لم تكن متأكدا من حل الكلام إلى النص المناسب لك، فشاهد ما هو تحويل الكلام إلى نص؟
المتطلبات الأساسية
- اشتراك Azure. يمكنك إنشاء حساب مجانا.
- إنشاء مورد الذكاء الاصطناعي Foundry ل Speech في مدخل Microsoft Azure.
- احصل على مفتاح مورد الكلام والمنطقة. بعد نشر مورد Speech، حدد Go to resource لعرض المفاتيح وإدارتها.
تحتاج أيضا إلى ملف صوتي .wav على جهازك المحلي. يمكنك استخدام ملف .wav الخاص بك (حتى 30 ثانية) أو تنزيل https://crbn.us/whatstheweatherlike.wav نموذج الملف.
إعداد البيئة
لإعداد بيئتك، قم بتثبيت Speech SDK ل JavaScript. قم بتشغيل هذا الأمر: npm install microsoft-cognitiveservices-speech-sdk. للحصول على إرشادات التثبيت الإرشادية، راجع تثبيت Speech SDK.
تعيين متغيرات البيئة
تحتاج إلى مصادقة التطبيق الخاص بك للوصول إلى خدمات Azure الذكاء الاصطناعي. توضح لك هذه المقالة كيفية استخدام متغيرات البيئة لتخزين بيانات الاعتماد الخاصة بك. يمكنك بعد ذلك الوصول إلى متغيرات البيئة من التعليمات البرمجية الخاصة بك لمصادقة التطبيق الخاص بك. للإنتاج، استخدم طريقة أكثر أمانا لتخزين بيانات الاعتماد والوصول إليها.
هام
نوصي بمصادقة معرف Microsoft Entra مع الهويات المدارة لموارد Azure لتجنب تخزين بيانات الاعتماد مع التطبيقات التي تعمل في السحابة.
استخدم مفاتيح واجهة برمجة التطبيقات بحذر. لا تقم بتضمين مفتاح API مباشرة في التعليمات البرمجية الخاصة بك، ولا تنشره بشكل عام. إذا كنت تستخدم مفاتيح واجهة برمجة التطبيقات، فخزنها بأمان في Azure Key Vault، وقم بتدوير المفاتيح بانتظام، وتقييد الوصول إلى Azure Key Vault باستخدام التحكم في الوصول المستند إلى الدور وقيود الوصول إلى الشبكة. لمزيد من المعلومات حول استخدام مفاتيح واجهة برمجة التطبيقات بشكل آمن في تطبيقاتك، راجع مفاتيح واجهة برمجة التطبيقات باستخدام Azure Key Vault.
لمزيد من المعلومات حول أمان خدمات الذكاء الاصطناعي، راجع مصادقة الطلبات إلى خدمات Azure الذكاء الاصطناعي.
لتعيين متغيرات البيئة لمفتاح مورد الكلام والمنطقة، افتح نافذة وحدة التحكم، واتبع الإرشادات الخاصة بنظام التشغيل وبيئة التطوير.
- لتعيين
SPEECH_KEYمتغير البيئة، استبدل مفتاحك بأحد مفاتيح المورد الخاص بك. - لتعيين
SPEECH_REGIONمتغير البيئة، استبدل منطقتك بإحدى المناطق لموردك.
- بالنسبة لنظام التشغيل
- Linux
-
macOS
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
ملاحظة
إذا كنت بحاجة فقط إلى الوصول إلى متغيرات البيئة في وحدة التحكم الحالية، يمكنك تعيين متغير البيئة باستخدام set بدلا من setx.
بعد إضافة متغيرات البيئة، قد تحتاج إلى إعادة تشغيل أي برامج تحتاج إلى قراءة متغيرات البيئة، بما في ذلك نافذة وحدة التحكم. على سبيل المثال، إذا كنت تستخدم Visual Studio كمحرر، فقم بإعادة تشغيل Visual Studio قبل تشغيل المثال.
التعرف على الكلام من ملف
نَصِيحة
جرب Azure الذكاء الاصطناعي Speech Toolkit لإنشاء نماذج وتشغيلها بسهولة على Visual Studio Code.
اتبع هذه الخطوات لإنشاء تطبيق وحدة تحكم Node.js للتعرف على الكلام.
افتح نافذة موجه الأوامر حيث تريد المشروع الجديد، وأنشئ ملفا جديدا باسم SpeechRecognition.js.
تثبيت Speech SDK ل JavaScript:
npm install microsoft-cognitiveservices-speech-sdkانسخ التعليمات البرمجية التالية إلى SpeechRecognition.js:
const fs = require("fs"); const sdk = require("microsoft-cognitiveservices-speech-sdk"); // This example requires environment variables named "SPEECH_KEY" and "SPEECH_REGION" const speechConfig = sdk.SpeechConfig.fromSubscription(process.env.SPEECH_KEY, process.env.SPEECH_REGION); speechConfig.speechRecognitionLanguage = "en-US"; function fromFile() { let audioConfig = sdk.AudioConfig.fromWavFileInput(fs.readFileSync("YourAudioFile.wav")); let speechRecognizer = new sdk.SpeechRecognizer(speechConfig, audioConfig); speechRecognizer.recognizeOnceAsync(result => { switch (result.reason) { case sdk.ResultReason.RecognizedSpeech: console.log(`RECOGNIZED: Text=${result.text}`); break; case sdk.ResultReason.NoMatch: console.log("NOMATCH: Speech could not be recognized."); break; case sdk.ResultReason.Canceled: const cancellation = sdk.CancellationDetails.fromResult(result); console.log(`CANCELED: Reason=${cancellation.reason}`); if (cancellation.reason == sdk.CancellationReason.Error) { console.log(`CANCELED: ErrorCode=${cancellation.ErrorCode}`); console.log(`CANCELED: ErrorDetails=${cancellation.errorDetails}`); console.log("CANCELED: Did you set the speech resource key and region values?"); } break; } speechRecognizer.close(); }); } fromFile();في SpeechRecognition.js، استبدل YourAudioFile.wav بملف .wav الخاص بك. يتعرف هذا المثال فقط على الكلام من ملف .wav . للحصول على معلومات حول تنسيقات الصوت الأخرى، راجع كيفية استخدام صوت الإدخال المضغوط. يدعم هذا المثال ما يصل إلى 30 ثانية من الصوت.
لتغيير لغة التعرف على الكلام، استبدل
en-USبلغة أخرى مدعومة. على سبيل المثال، استخدمes-ESللإسبانية (إسبانيا). إذا لم تحدد لغة، فإن الإعداد الافتراضي هوen-US. للحصول على تفاصيل حول كيفية تحديد إحدى اللغات المتعددة التي قد يتم التحدث بها، راجع تعريف اللغة.قم بتشغيل تطبيق وحدة التحكم الجديد لبدء التعرف على الكلام من ملف:
node.exe SpeechRecognition.jsهام
تأكد من تعيين
SPEECH_KEYSPEECH_REGIONو. إذا لم تقم بتعيين هذه المتغيرات، تفشل العينة مع ظهور رسالة خطأ.يجب إخراج الكلام من الملف الصوتي كنص:
RECOGNIZED: Text=I'm excited to try speech to text.
الملاحظات
يستخدم recognizeOnceAsync هذا المثال العملية لنسخ الألفاظ التي تصل إلى 30 ثانية، أو حتى يتم الكشف عن الصمت. للحصول على معلومات حول التعرف المستمر على الصوت الأطول، بما في ذلك المحادثات متعددة اللغات، راجع كيفية التعرف على الكلام.
ملاحظة
التعرف على الكلام من ميكروفون غير مدعوم في Node.js. وهو مدعوم فقط في بيئة JavaScript المستندة إلى المستعرض. لمزيد من المعلومات، راجع نموذج Reactوتنفيذ الكلام إلى نص من ميكروفون على GitHub.
يظهر نموذج React أنماط تصميم لتبادل وإدارة رموز المصادقة المميزة. كما يعرض التقاط الصوت من ميكروفون أو ملف لتحويل الكلام إلى نص.
تنظيف الموارد
يمكنك استخدام مدخل Microsoft Azure أو واجهة سطر الأوامر Azure (CLI) لإزالة مورد الكلام الذي أنشأته.
الوثائق | المرجعيةالحزمة (PyPi) | عينات إضافية على GitHub
في هذا التشغيل السريع، يمكنك إنشاء وتشغيل تطبيق للتعرف على الكلام ونسخه إلى نص في الوقت الفعلي.
لنسخ الملفات الصوتية بدلا من ذلك بشكل غير متزامن، راجع ما هو النسخ الدفعي. إذا لم تكن متأكدا من حل الكلام إلى النص المناسب لك، فشاهد ما هو تحويل الكلام إلى نص؟
المتطلبات الأساسية
- اشتراك Azure. يمكنك إنشاء حساب مجانا.
- إنشاء مورد خدمات الذكاء الاصطناعي للكلام في مدخل Microsoft Azure.
- احصل على مفتاح مورد الكلام ونقطة النهاية. بعد نشر مورد Speech، حدد Go to resource لعرض المفاتيح وإدارتها.
إعداد البيئة
يتوفر Speech SDK ل Python كوحدة نمطية ل Python Package Index (PyPI). Speech SDK ل Python متوافق مع Windows وLinux وmacOS.
- بالنسبة إلى Windows، قم بتثبيت Microsoft Visual C++ Redistributable ل Visual Studio 2015 و2017 و2019 و2022 للنظام الأساسي الخاص بك. قد يتطلب تثبيت هذه الحزمة للمرة الأولى إعادة تشغيل.
- على Linux، يجب عليك استخدام البنية الهدف x64.
تثبيت إصدار من Python من 3.7 أو أحدث. للحصول على متطلبات أخرى، راجع تثبيت Speech SDK.
تعيين متغيرات البيئة
تحتاج إلى مصادقة التطبيق الخاص بك للوصول إلى خدمات Azure الذكاء الاصطناعي. توضح لك هذه المقالة كيفية استخدام متغيرات البيئة لتخزين بيانات الاعتماد الخاصة بك. يمكنك بعد ذلك الوصول إلى متغيرات البيئة من التعليمات البرمجية الخاصة بك لمصادقة التطبيق الخاص بك. للإنتاج، استخدم طريقة أكثر أمانا لتخزين بيانات الاعتماد والوصول إليها.
هام
نوصي بمصادقة معرف Microsoft Entra مع الهويات المدارة لموارد Azure لتجنب تخزين بيانات الاعتماد مع التطبيقات التي تعمل في السحابة.
استخدم مفاتيح واجهة برمجة التطبيقات بحذر. لا تقم بتضمين مفتاح API مباشرة في التعليمات البرمجية الخاصة بك، ولا تنشره بشكل عام. إذا كنت تستخدم مفاتيح واجهة برمجة التطبيقات، فخزنها بأمان في Azure Key Vault، وقم بتدوير المفاتيح بانتظام، وتقييد الوصول إلى Azure Key Vault باستخدام التحكم في الوصول المستند إلى الدور وقيود الوصول إلى الشبكة. لمزيد من المعلومات حول استخدام مفاتيح واجهة برمجة التطبيقات بشكل آمن في تطبيقاتك، راجع مفاتيح واجهة برمجة التطبيقات باستخدام Azure Key Vault.
لمزيد من المعلومات حول أمان خدمات الذكاء الاصطناعي، راجع مصادقة الطلبات إلى خدمات Azure الذكاء الاصطناعي.
لتعيين متغيرات البيئة لمفتاح مورد Speech ونقطة النهاية، افتح نافذة وحدة التحكم، واتبع الإرشادات الخاصة بنظام التشغيل وبيئة التطوير.
- لتعيين
SPEECH_KEYمتغير البيئة، استبدل مفتاحك بأحد مفاتيح المورد الخاص بك. - لتعيين
ENDPOINTمتغير البيئة، استبدل نقطة النهاية بإحدى نقاط النهاية لموردك.
- بالنسبة لنظام التشغيل
- Linux
-
macOS
setx SPEECH_KEY your-key
setx ENDPOINT your-endpoint
ملاحظة
إذا كنت بحاجة فقط إلى الوصول إلى متغيرات البيئة في وحدة التحكم الحالية، يمكنك تعيين متغير البيئة باستخدام set بدلا من setx.
بعد إضافة متغيرات البيئة، قد تحتاج إلى إعادة تشغيل أي برامج تحتاج إلى قراءة متغيرات البيئة، بما في ذلك نافذة وحدة التحكم. على سبيل المثال، إذا كنت تستخدم Visual Studio كمحرر، فقم بإعادة تشغيل Visual Studio قبل تشغيل المثال.
التعرف على الكلام من ميكروفون
نَصِيحة
جرب Azure الذكاء الاصطناعي Speech Toolkit لإنشاء نماذج وتشغيلها بسهولة على Visual Studio Code.
اتبع هذه الخطوات لإنشاء تطبيق وحدة تحكم.
افتح نافذة موجه الأوامر في المجلد حيث تريد المشروع الجديد. إنشاء ملف جديد باسم speech_recognition.py.
قم بتشغيل هذا الأمر لتثبيت Speech SDK:
pip install azure-cognitiveservices-speechانسخ التعليمات البرمجية التالية إلى speech_recognition.py:
import os import azure.cognitiveservices.speech as speechsdk def recognize_from_microphone(): # This example requires environment variables named "SPEECH_KEY" and "ENDPOINT" # Replace with your own subscription key and endpoint, the endpoint is like : "https://YourServiceRegion.api.cognitive.microsoft.com" speech_config = speechsdk.SpeechConfig(subscription=os.environ.get('SPEECH_KEY'), endpoint=os.environ.get('ENDPOINT')) speech_config.speech_recognition_language="en-US" audio_config = speechsdk.audio.AudioConfig(use_default_microphone=True) speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config, audio_config=audio_config) print("Speak into your microphone.") speech_recognition_result = speech_recognizer.recognize_once_async().get() if speech_recognition_result.reason == speechsdk.ResultReason.RecognizedSpeech: print("Recognized: {}".format(speech_recognition_result.text)) elif speech_recognition_result.reason == speechsdk.ResultReason.NoMatch: print("No speech could be recognized: {}".format(speech_recognition_result.no_match_details)) elif speech_recognition_result.reason == speechsdk.ResultReason.Canceled: cancellation_details = speech_recognition_result.cancellation_details print("Speech Recognition canceled: {}".format(cancellation_details.reason)) if cancellation_details.reason == speechsdk.CancellationReason.Error: print("Error details: {}".format(cancellation_details.error_details)) print("Did you set the speech resource key and endpoint values?") recognize_from_microphone()لتغيير لغة التعرف على الكلام، استبدل
en-USبلغة أخرى مدعومة. على سبيل المثال، استخدمes-ESللإسبانية (إسبانيا). إذا لم تحدد لغة، فإن الإعداد الافتراضي هوen-US. للحصول على تفاصيل حول كيفية تحديد إحدى اللغات المتعددة التي قد يتم التحدث بها، راجع تعريف اللغة.تشغيل تطبيق وحدة التحكم الجديد لبدء التعرف على الكلام من ميكروفون:
python speech_recognition.pyتحدث إلى الميكروفون عند مطالبتك. يجب أن يظهر ما تتحدثه كنص:
Speak into your microphone. RECOGNIZED: Text=I'm excited to try speech to text.
الملاحظات
فيما يلي بعض الاعتبارات الأخرى:
يستخدم
recognize_once_asyncهذا المثال العملية لنسخ الألفاظ التي تصل إلى 30 ثانية، أو حتى يتم الكشف عن الصمت. للحصول على معلومات حول التعرف المستمر على الصوت الأطول، بما في ذلك المحادثات متعددة اللغات، راجع كيفية التعرف على الكلام.للتعرف على الكلام من ملف صوتي، استخدم
filenameبدلا منuse_default_microphone:audio_config = speechsdk.audio.AudioConfig(filename="YourAudioFile.wav")بالنسبة للملفات الصوتية المضغوطة مثل MP4، قم بتثبيت GStreamer واستخدم
PullAudioInputStreamأوPushAudioInputStream. لمزيد من المعلومات، راجع كيفية استخدام صوت الإدخال المضغوط.
تنظيف الموارد
يمكنك استخدام مدخل Microsoft Azure أو واجهة سطر الأوامر Azure (CLI) لإزالة مورد الكلام الذي أنشأته.
الوثائق | المرجعيةحزمة (تنزيل) | عينات إضافية على GitHub
في هذا التشغيل السريع، يمكنك إنشاء وتشغيل تطبيق للتعرف على الكلام ونسخه إلى نص في الوقت الفعلي.
لنسخ الملفات الصوتية بدلا من ذلك بشكل غير متزامن، راجع ما هو النسخ الدفعي. إذا لم تكن متأكدا من حل الكلام إلى النص المناسب لك، فشاهد ما هو تحويل الكلام إلى نص؟
المتطلبات الأساسية
- اشتراك Azure. يمكنك إنشاء حساب مجانا.
- إنشاء مورد الذكاء الاصطناعي Foundry ل Speech في مدخل Microsoft Azure.
- احصل على مفتاح مورد الكلام والمنطقة. بعد نشر مورد Speech، حدد Go to resource لعرض المفاتيح وإدارتها.
إعداد البيئة
يتم توزيع Speech SDK ل Swift كحزمة إطار عمل. يدعم إطار العمل كلا من Objective-C وSwift على كل من iOS وmacOS.
يمكن استخدام Speech SDK في مشاريع Xcode ك CocoaPod، أو تنزيلها مباشرة وربطها يدويا. يستخدم هذا الدليل CocoaPod. قم بتثبيت مدير تبعية CocoaPod كما هو موضح في إرشادات التثبيت الخاصة به.
تعيين متغيرات البيئة
تحتاج إلى مصادقة التطبيق الخاص بك للوصول إلى خدمات Azure الذكاء الاصطناعي. توضح لك هذه المقالة كيفية استخدام متغيرات البيئة لتخزين بيانات الاعتماد الخاصة بك. يمكنك بعد ذلك الوصول إلى متغيرات البيئة من التعليمات البرمجية الخاصة بك لمصادقة التطبيق الخاص بك. للإنتاج، استخدم طريقة أكثر أمانا لتخزين بيانات الاعتماد والوصول إليها.
هام
نوصي بمصادقة معرف Microsoft Entra مع الهويات المدارة لموارد Azure لتجنب تخزين بيانات الاعتماد مع التطبيقات التي تعمل في السحابة.
استخدم مفاتيح واجهة برمجة التطبيقات بحذر. لا تقم بتضمين مفتاح API مباشرة في التعليمات البرمجية الخاصة بك، ولا تنشره بشكل عام. إذا كنت تستخدم مفاتيح واجهة برمجة التطبيقات، فخزنها بأمان في Azure Key Vault، وقم بتدوير المفاتيح بانتظام، وتقييد الوصول إلى Azure Key Vault باستخدام التحكم في الوصول المستند إلى الدور وقيود الوصول إلى الشبكة. لمزيد من المعلومات حول استخدام مفاتيح واجهة برمجة التطبيقات بشكل آمن في تطبيقاتك، راجع مفاتيح واجهة برمجة التطبيقات باستخدام Azure Key Vault.
لمزيد من المعلومات حول أمان خدمات الذكاء الاصطناعي، راجع مصادقة الطلبات إلى خدمات Azure الذكاء الاصطناعي.
لتعيين متغيرات البيئة لمفتاح مورد الكلام والمنطقة، افتح نافذة وحدة التحكم، واتبع الإرشادات الخاصة بنظام التشغيل وبيئة التطوير.
- لتعيين
SPEECH_KEYمتغير البيئة، استبدل مفتاحك بأحد مفاتيح المورد الخاص بك. - لتعيين
SPEECH_REGIONمتغير البيئة، استبدل منطقتك بإحدى المناطق لموردك.
- بالنسبة لنظام التشغيل
- Linux
-
macOS
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
ملاحظة
إذا كنت بحاجة فقط إلى الوصول إلى متغيرات البيئة في وحدة التحكم الحالية، يمكنك تعيين متغير البيئة باستخدام set بدلا من setx.
بعد إضافة متغيرات البيئة، قد تحتاج إلى إعادة تشغيل أي برامج تحتاج إلى قراءة متغيرات البيئة، بما في ذلك نافذة وحدة التحكم. على سبيل المثال، إذا كنت تستخدم Visual Studio كمحرر، فقم بإعادة تشغيل Visual Studio قبل تشغيل المثال.
التعرف على الكلام من ميكروفون
اتبع هذه الخطوات للتعرف على الكلام في تطبيق macOS.
استنسخ مستودع Azure-Samples/cognitive-services-speech-sdk للحصول على مشروع نموذج التعرف على الكلام من ميكروفون في Swift على macOS . يحتوي المستودع أيضا على عينات iOS.
انتقل إلى دليل نموذج التطبيق (
helloworld) الذي تم تنزيله في محطة طرفية.تشغيل الأمر
pod install. ينشئhelloworld.xcworkspaceهذا الأمر مساحة عمل Xcode تحتوي على كل من نموذج التطبيق وSDK الكلام كتبعية.helloworld.xcworkspaceافتح مساحة العمل في Xcode.افتح الملف المسمى AppDelegate.swift وحدد موقع الأسلوبين
applicationDidFinishLaunchingوrecognizeFromMicكما هو موضح هنا.import Cocoa @NSApplicationMain class AppDelegate: NSObject, NSApplicationDelegate { var label: NSTextField! var fromMicButton: NSButton! var sub: String! var region: String! @IBOutlet weak var window: NSWindow! func applicationDidFinishLaunching(_ aNotification: Notification) { print("loading") // load subscription information sub = ProcessInfo.processInfo.environment["SPEECH_KEY"] region = ProcessInfo.processInfo.environment["SPEECH_REGION"] label = NSTextField(frame: NSRect(x: 100, y: 50, width: 200, height: 200)) label.textColor = NSColor.black label.lineBreakMode = .byWordWrapping label.stringValue = "Recognition Result" label.isEditable = false self.window.contentView?.addSubview(label) fromMicButton = NSButton(frame: NSRect(x: 100, y: 300, width: 200, height: 30)) fromMicButton.title = "Recognize" fromMicButton.target = self fromMicButton.action = #selector(fromMicButtonClicked) self.window.contentView?.addSubview(fromMicButton) } @objc func fromMicButtonClicked() { DispatchQueue.global(qos: .userInitiated).async { self.recognizeFromMic() } } func recognizeFromMic() { var speechConfig: SPXSpeechConfiguration? do { try speechConfig = SPXSpeechConfiguration(subscription: sub, region: region) } catch { print("error \(error) happened") speechConfig = nil } speechConfig?.speechRecognitionLanguage = "en-US" let audioConfig = SPXAudioConfiguration() let reco = try! SPXSpeechRecognizer(speechConfiguration: speechConfig!, audioConfiguration: audioConfig) reco.addRecognizingEventHandler() {reco, evt in print("intermediate recognition result: \(evt.result.text ?? "(no result)")") self.updateLabel(text: evt.result.text, color: .gray) } updateLabel(text: "Listening ...", color: .gray) print("Listening...") let result = try! reco.recognizeOnce() print("recognition result: \(result.text ?? "(no result)"), reason: \(result.reason.rawValue)") updateLabel(text: result.text, color: .black) if result.reason != SPXResultReason.recognizedSpeech { let cancellationDetails = try! SPXCancellationDetails(fromCanceledRecognitionResult: result) print("cancelled: \(result.reason), \(cancellationDetails.errorDetails)") print("Did you set the speech resource key and region values?") updateLabel(text: "Error: \(cancellationDetails.errorDetails)", color: .red) } } func updateLabel(text: String?, color: NSColor) { DispatchQueue.main.async { self.label.stringValue = text! self.label.textColor = color } } }في AppDelegate.m، استخدم متغيرات البيئة التي قمت بتعيينها مسبقا لمفتاح مورد الكلام والمنطقة.
sub = ProcessInfo.processInfo.environment["SPEECH_KEY"] region = ProcessInfo.processInfo.environment["SPEECH_REGION"]لتغيير لغة التعرف على الكلام، استبدل
en-USبلغة أخرى مدعومة. على سبيل المثال، استخدمes-ESللإسبانية (إسبانيا). إذا لم تحدد لغة، فإن الإعداد الافتراضي هوen-US. للحصول على تفاصيل حول كيفية تحديد إحدى اللغات المتعددة التي قد يتم التحدث بها، راجع تعريف اللغة.لجعل إخراج التصحيح مرئيا، حدد View>Debug Area>Activate Console.
إنشاء التعليمات البرمجية المثال وتشغيلها عن طريق تحديد تشغيل المنتج> من القائمة أو تحديد الزر تشغيل.
بعد تحديد الزر في التطبيق ونطق بضع كلمات، يجب أن تشاهد النص الذي تحدثت به في الجزء السفلي من الشاشة. عند تشغيل التطبيق للمرة الأولى، فإنه يطالبك بمنح التطبيق حق الوصول إلى ميكروفون الكمبيوتر الخاص بك.
الملاحظات
يستخدم recognizeOnce هذا المثال العملية لنسخ الألفاظ التي تصل إلى 30 ثانية، أو حتى يتم الكشف عن الصمت. للحصول على معلومات حول التعرف المستمر على الصوت الأطول، بما في ذلك المحادثات متعددة اللغات، راجع كيفية التعرف على الكلام.
Objective-C
يشارك Speech SDK ل Objective-C مكتبات العميل والوثائق المرجعية مع Speech SDK ل Swift. للحصول على أمثلة التعليمات البرمجية Objective-C، راجع التعرف على الكلام من ميكروفون في Objective-C على نموذج مشروع macOS في GitHub.
تنظيف الموارد
يمكنك استخدام مدخل Microsoft Azure أو واجهة سطر الأوامر Azure (CLI) لإزالة مورد الكلام الذي أنشأته.
مرجع | Speech to text REST API for short audio reference | عينات إضافية على GitHub
في هذا التشغيل السريع، يمكنك إنشاء وتشغيل تطبيق للتعرف على الكلام ونسخه إلى نص في الوقت الفعلي.
لنسخ الملفات الصوتية بدلا من ذلك بشكل غير متزامن، راجع ما هو النسخ الدفعي. إذا لم تكن متأكدا من حل الكلام إلى النص المناسب لك، فشاهد ما هو تحويل الكلام إلى نص؟
المتطلبات الأساسية
- اشتراك Azure. يمكنك إنشاء حساب مجانا.
- إنشاء مورد الذكاء الاصطناعي Foundry ل Speech في مدخل Microsoft Azure.
- احصل على مفتاح مورد الكلام والمنطقة. بعد نشر مورد Speech، حدد Go to resource لعرض المفاتيح وإدارتها.
تحتاج أيضا إلى ملف صوتي .wav على جهازك المحلي. يمكنك استخدام ملف .wav الخاص بك حتى 60 ثانية أو تنزيل https://crbn.us/whatstheweatherlike.wav نموذج الملف.
تعيين متغيرات البيئة
تحتاج إلى مصادقة التطبيق الخاص بك للوصول إلى خدمات Azure الذكاء الاصطناعي. توضح لك هذه المقالة كيفية استخدام متغيرات البيئة لتخزين بيانات الاعتماد الخاصة بك. يمكنك بعد ذلك الوصول إلى متغيرات البيئة من التعليمات البرمجية الخاصة بك لمصادقة التطبيق الخاص بك. للإنتاج، استخدم طريقة أكثر أمانا لتخزين بيانات الاعتماد والوصول إليها.
هام
نوصي بمصادقة معرف Microsoft Entra مع الهويات المدارة لموارد Azure لتجنب تخزين بيانات الاعتماد مع التطبيقات التي تعمل في السحابة.
استخدم مفاتيح واجهة برمجة التطبيقات بحذر. لا تقم بتضمين مفتاح API مباشرة في التعليمات البرمجية الخاصة بك، ولا تنشره بشكل عام. إذا كنت تستخدم مفاتيح واجهة برمجة التطبيقات، فخزنها بأمان في Azure Key Vault، وقم بتدوير المفاتيح بانتظام، وتقييد الوصول إلى Azure Key Vault باستخدام التحكم في الوصول المستند إلى الدور وقيود الوصول إلى الشبكة. لمزيد من المعلومات حول استخدام مفاتيح واجهة برمجة التطبيقات بشكل آمن في تطبيقاتك، راجع مفاتيح واجهة برمجة التطبيقات باستخدام Azure Key Vault.
لمزيد من المعلومات حول أمان خدمات الذكاء الاصطناعي، راجع مصادقة الطلبات إلى خدمات Azure الذكاء الاصطناعي.
لتعيين متغيرات البيئة لمفتاح مورد الكلام والمنطقة، افتح نافذة وحدة التحكم، واتبع الإرشادات الخاصة بنظام التشغيل وبيئة التطوير.
- لتعيين
SPEECH_KEYمتغير البيئة، استبدل مفتاحك بأحد مفاتيح المورد الخاص بك. - لتعيين
SPEECH_REGIONمتغير البيئة، استبدل منطقتك بإحدى المناطق لموردك.
- بالنسبة لنظام التشغيل
- Linux
-
macOS
setx SPEECH_KEY your-key
setx SPEECH_REGION your-region
ملاحظة
إذا كنت بحاجة فقط إلى الوصول إلى متغيرات البيئة في وحدة التحكم الحالية، يمكنك تعيين متغير البيئة باستخدام set بدلا من setx.
بعد إضافة متغيرات البيئة، قد تحتاج إلى إعادة تشغيل أي برامج تحتاج إلى قراءة متغيرات البيئة، بما في ذلك نافذة وحدة التحكم. على سبيل المثال، إذا كنت تستخدم Visual Studio كمحرر، فقم بإعادة تشغيل Visual Studio قبل تشغيل المثال.
التعرف على الكلام من ملف
افتح نافذة وحدة تحكم وقم بتشغيل الأمر cURL التالي. استبدل YourAudioFile.wav بمسار الملف الصوتي واسمه.
- بالنسبة لنظام التشغيل
- Linux
-
macOS
curl --location --request POST "https://%SPEECH_REGION%.stt.speech.microsoft.com/speech/recognition/conversation/cognitiveservices/v1?language=en-US&format=detailed" ^
--header "Ocp-Apim-Subscription-Key: %SPEECH_KEY%" ^
--header "Content-Type: audio/wav" ^
--data-binary "@YourAudioFile.wav"
هام
تأكد من تعيين SPEECH_KEYSPEECH_REGION و. إذا لم تقم بتعيين هذه المتغيرات، تفشل العينة مع ظهور رسالة خطأ.
يجب أن تتلقى استجابة مشابهة لما هو موضح هنا.
DisplayText يجب أن يكون النص الذي تم التعرف عليه من الملف الصوتي. يتعرف الأمر على ما يصل إلى 60 ثانية من الصوت ويحوله إلى نص.
{
"RecognitionStatus": "Success",
"DisplayText": "My voice is my passport, verify me.",
"Offset": 6600000,
"Duration": 32100000
}
لمزيد من المعلومات، راجع تحويل الكلام إلى نص REST API للحصول على صوت قصير.
تنظيف الموارد
يمكنك استخدام مدخل Microsoft Azure أو واجهة سطر الأوامر Azure (CLI) لإزالة مورد الكلام الذي أنشأته.
في هذا التشغيل السريع، يمكنك إنشاء وتشغيل تطبيق للتعرف على الكلام ونسخه إلى نص في الوقت الفعلي.
لنسخ الملفات الصوتية بدلا من ذلك بشكل غير متزامن، راجع ما هو النسخ الدفعي. إذا لم تكن متأكدا من حل الكلام إلى النص المناسب لك، فشاهد ما هو تحويل الكلام إلى نص؟
المتطلبات الأساسية
- اشتراك Azure. يمكنك إنشاء حساب مجانا.
- إنشاء مورد الذكاء الاصطناعي Foundry ل Speech في مدخل Microsoft Azure.
- احصل على مفتاح مورد الكلام والمنطقة. بعد نشر مورد Speech، حدد Go to resource لعرض المفاتيح وإدارتها.
إعداد البيئة
اتبع هذه الخطوات وشاهد التشغيل السريع ل Speech CLI لمعرفة المتطلبات الأخرى للنظام الأساسي الخاص بك.
قم بتشغيل الأمر .NET CLI التالي لتثبيت Speech CLI:
dotnet tool install --global Microsoft.CognitiveServices.Speech.CLIقم بتشغيل الأوامر التالية لتكوين مفتاح مورد الكلام والمنطقة. استبدل
SUBSCRIPTION-KEYبمفتاح مورد Speech واستبدلREGIONبمنطقة مورد Speech.spx config @key --set SUBSCRIPTION-KEY spx config @region --set REGION
التعرف على الكلام من ميكروفون
قم بتشغيل الأمر التالي لبدء التعرف على الكلام من ميكروفون:
spx recognize --microphone --source en-USتحدث في الميكروفون، وترى كتابة كلماتك في نص في الوقت الفعلي. يتوقف Speech CLI بعد فترة من الصمت أو 30 ثانية أو عند تحديد Ctrl+C.
Connection CONNECTED... RECOGNIZED: I'm excited to try speech to text.
الملاحظات
فيما يلي بعض الاعتبارات الأخرى:
للتعرف على الكلام من ملف صوتي، استخدم
--fileبدلا من--microphone. بالنسبة للملفات الصوتية المضغوطة مثل MP4، قم بتثبيت GStreamer واستخدم--format. لمزيد من المعلومات، راجع كيفية استخدام صوت الإدخال المضغوط.spx recognize --file YourAudioFile.wav spx recognize --file YourAudioFile.mp4 --format anyلتحسين دقة التعرف على كلمات أو كلمات معينة، استخدم قائمة عبارات. يمكنك تضمين قائمة عبارات في سطر أو مع ملف نصي مع
recognizeالأمر :spx recognize --microphone --phrases "Contoso;Jessie;Rehaan;" spx recognize --microphone --phrases @phrases.txtلتغيير لغة التعرف على الكلام، استبدل
en-USبلغة أخرى مدعومة. على سبيل المثال، استخدمes-ESللإسبانية (إسبانيا). إذا لم تحدد لغة، فإن الإعداد الافتراضي هوen-US.spx recognize --microphone --source es-ESللتعرف المستمر على الصوت الذي يزيد عن 30 ثانية، قم بإلحاق
--continuous:spx recognize --microphone --source es-ES --continuousقم بتشغيل هذا الأمر للحصول على معلومات حول المزيد من خيارات التعرف على الكلام مثل إدخال الملف وإخراجه:
spx help recognize
تنظيف الموارد
يمكنك استخدام مدخل Microsoft Azure أو واجهة سطر الأوامر Azure (CLI) لإزالة مورد الكلام الذي أنشأته.