الحصول على موضع الوجه باستخدام viseme
إشعار
لاستكشاف لغة معتمدة لمعرف viseme ومزج الأشكال، راجع قائمة بجميع الحقول المحلية المدعومة. يتم دعم رسومات المتجهات القابلة للتطوير (SVG) للغات en-US المحلية فقط.
viseme هو الوصف المرئي لصوت لغوي بلغة منطوقة. وهو يحدد موضع الوجه والفم عند بدء الشخص بالتحدث. يصور كل فيزيم وضعيات الوجه الرئيسية لمجموعة محددة من الأصوات اللغوية.
يمكنك استخدام visemes للتحكم في حركة نماذج الأفاتار ثلاثية الأبعاد وثنائية الأبعاد، بحيث تتم محاذاة مواضع الوجه بشكل أفضل مع الكلام الاصطناعي. على سبيل المثال، يمكنك:
- إنشاء مساعد صوت ظاهري متحرك للأكشاك الذكية، وبناء خدمات متكاملة متعددة الوضع لعملائك.
- بناء بث الأخبار الشاملة وتحسين تجارب الجمهور مع حركات الوجه والفم الطبيعية.
- إنشاء صور رمزية أكثر تفاعلية للألعاب وشخصيات كرتونية يمكنها التحدث بمحتوى ديناميكي.
- اجعل مقاطع فيديو تعليم اللغة أكثر فعالية تساعد متعلمي اللغة على فهم حركة الفم لكل كلمة وصوت لغوي.
- يمكن للأشخاص الذين يعانون من ضعف في السمع أيضاً التقاط الأصوات بصرياً ومحتوى الكلام "قراءة الشفاه" الذي يظهر أشكالاً على وجه متحرك.
لمزيد من المعلومات حول فيزيم، اعرض هذا الفيديو التمهيدي.
سير العمل العام لإنتاج viseme مع الكلام
تحويل النص العصبي إلى كلام (TTS عصبي) إلى تحويل نص الإدخال أو SSML (لغة ترميز تركيب الكلام) إلى كلام مركب من ناحية الحياة. يمكن أن يكون إخراج الصوت عند الكلام مصحوبًا بمعرّف فيسيم أو رسومات متجهات قابلة للتطوير (SVG) أو مزيج الأشكال. باستخدام محرك عرض ثنائي الأبعاد أو ثلاثي الأبعاد، يمكنك استخدام أحداث فيزيم هذه لتحريك صورتك الرمزية.
يصور سير العمل العام لـ viseme في المخطط الانسيابي التالي:
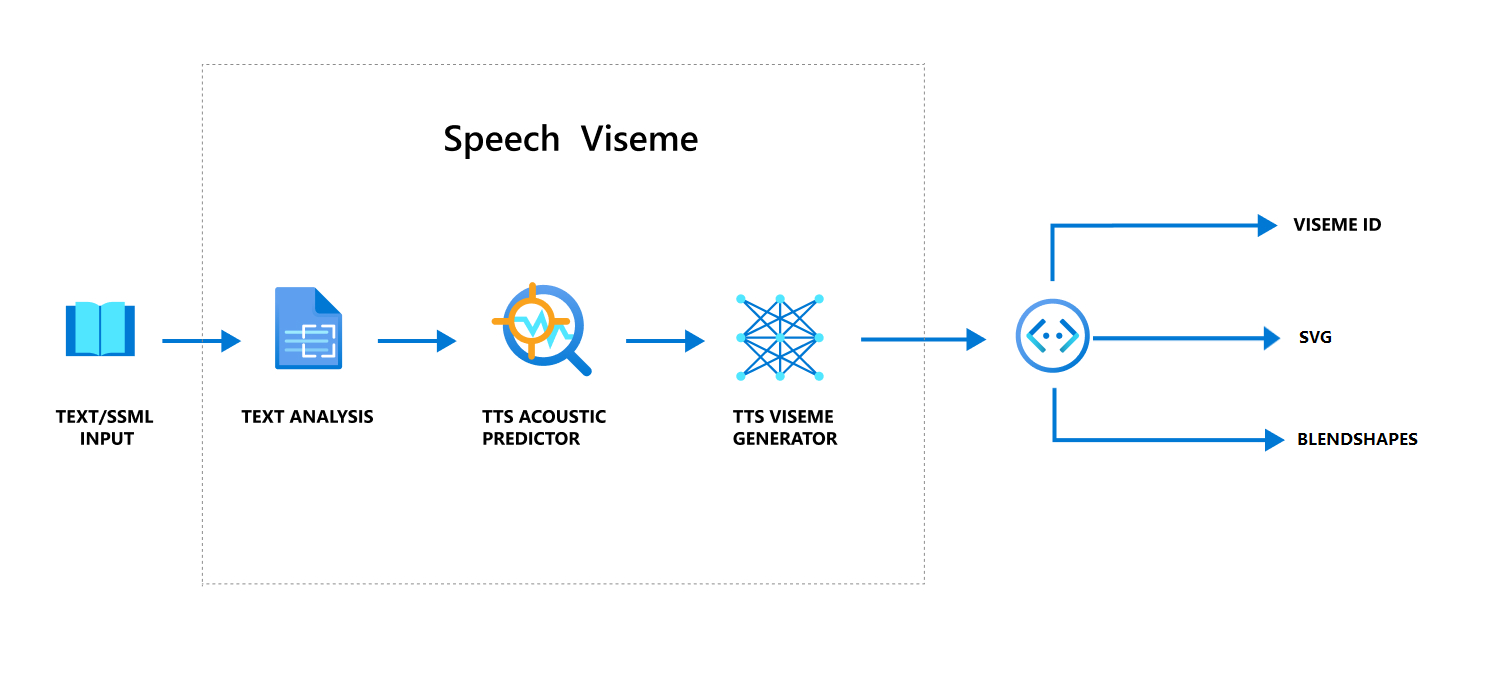
معرف Viseme
يشير معرف Viseme إلى رقم عدد صحيح يحدد viseme. نحن نقدم 22 visemes مختلفة، كل تصور موضع الفم لمجموعة محددة من الهواتف. لا توجد مراسلات بين visemes وphonemes. في كثير من الأحيان، تتوافق العديد من الرسائل الصوتية مع لسمة واحدة، لأنها بدت بنفس الشكل على وجه السماعة عند إنتاجها، مثل s و z. لمزيد من المعلومات المحددة، راجع جدول تعيين الأصوات اللغوية إلى معرفات فيزيم.
يمكن أن يكون إخراج صوت الكلام مصحوبا بمعرفات viseme و Audio offset. Audio offset يشير إلى الطابع الزمني للإزاحة الذي يمثل وقت بدء كل viseme، في علامات التجزئة (100 نانو ثانية).
تعيين أصوات لغوية إلى فيزيم
تختلف الفيزيم حسب اللغة واللغة المحلية. تحتوي كل إعدادات محلية على مجموعة من الفيزيم التي تتوافق مع أصواتها اللغوية المحددة. تعين وثائق الحروف الأبجدية الصوتية SSML معرفات فيزيم إلى الرسائل الصوتية المطابقة للهجاء الصوتي الدولي (IPA). يعرض الجدول في هذا القسم علاقة تعيين بين معرفات viseme ومواضع الفم، مع سرد هواتف IPA النموذجية لكل معرف viseme.
| معرف Viseme | مخطط الأبجدية الصوتية الدولية | موضع الفم |
|---|---|---|
| 0 | الصَمت |  |
| 1 | æ، ، əʌ |
 |
| 2 | ɑ |
 |
| 3 | ɔ |
 |
| 4 | ɛ, ʊ |
 |
| 5 | ɝ |
 |
| 6 | j، ، iɪ |
 |
| 7 | w, u |
 |
| 8 | o |
 |
| 9 | aʊ |
 |
| 10 | ɔɪ |
 |
| 11 | aɪ |
 |
| 12 | h |
 |
| 13 | ɹ |
 |
| 14 | l |
 |
| 15 | s, z |
 |
| 16 | ʃ، ، tʃ، dʒʒ |
 |
| 17 | ð |
 |
| 18 | f, v |
 |
| 19 | d، ، t، nθ |
 |
| 20 | k، ، gŋ |
 |
| 21 | p، ، bm |
 |
حركة SVG ثنائية الأبعاد
بالنسبة للأحرف ثنائية الأبعاد، يمكنك تصميم حرف يناسب السيناريو الخاص بك واستخدام رسومات متجهات قابلة للتطوير (SVG) لكل معرف فيزيم للحصول على موضع وجه يستند إلى الوقت.
مع العلامات الزمنية التي يتم توفيرها في حدث viseme، تتم معالجة مجموعات SVG المصممة جيدا هذه مع تعديلات سلسة، وتوفر حركة قوية للمستخدمين. على سبيل المثال، يظهر الرسم التوضيحي التالي حرفا أحمر اللون مصمما لتعلم اللغة.

رسم متحرك للأشكال المدمجة ثلاثية الأبعاد
يمكنك استخدام مزج الأشكال لدفع حركات الوجه لشخصية ثلاثية الأبعاد قمت بتصميمها.
يتم تمثيل سلسلة JSON للأشكال المختلطة كمصفوفة ثنائية الأبعاد. يمثل كل صف عميل. يحتوي كل إطار (في 60 إطارا في الثانية) على صفيف من 55 موضع وجه.
الحصول على أحداث فيزيم باستخدام Speech SDK
للحصول على فيزيم مع الكلام الذي تم تركيبه، اشترك في VisemeReceived الحدث في Speech SDK.
إشعار
لطلب إخراج SVG أو مزج الأشكال، يجب استخدام mstts:viseme العنصر في SSML. للحصول على التفاصيل، راجع كيفية استخدام عنصر viseme في SSML.
توضح القصاصة البرمجية التالية كيفية الاشتراك في حدث فيزيم:
using (var synthesizer = new SpeechSynthesizer(speechConfig, audioConfig))
{
// Subscribes to viseme received event
synthesizer.VisemeReceived += (s, e) =>
{
Console.WriteLine($"Viseme event received. Audio offset: " +
$"{e.AudioOffset / 10000}ms, viseme id: {e.VisemeId}.");
// `Animation` is an xml string for SVG or a json string for blend shapes
var animation = e.Animation;
};
// If VisemeID is the only thing you want, you can also use `SpeakTextAsync()`
var result = await synthesizer.SpeakSsmlAsync(ssml);
}
auto synthesizer = SpeechSynthesizer::FromConfig(speechConfig, audioConfig);
// Subscribes to viseme received event
synthesizer->VisemeReceived += [](const SpeechSynthesisVisemeEventArgs& e)
{
cout << "viseme event received. "
// The unit of e.AudioOffset is tick (1 tick = 100 nanoseconds), divide by 10,000 to convert to milliseconds.
<< "Audio offset: " << e.AudioOffset / 10000 << "ms, "
<< "viseme id: " << e.VisemeId << "." << endl;
// `Animation` is an xml string for SVG or a json string for blend shapes
auto animation = e.Animation;
};
// If VisemeID is the only thing you want, you can also use `SpeakTextAsync()`
auto result = synthesizer->SpeakSsmlAsync(ssml).get();
SpeechSynthesizer synthesizer = new SpeechSynthesizer(speechConfig, audioConfig);
// Subscribes to viseme received event
synthesizer.VisemeReceived.addEventListener((o, e) -> {
// The unit of e.AudioOffset is tick (1 tick = 100 nanoseconds), divide by 10,000 to convert to milliseconds.
System.out.print("Viseme event received. Audio offset: " + e.getAudioOffset() / 10000 + "ms, ");
System.out.println("viseme id: " + e.getVisemeId() + ".");
// `Animation` is an xml string for SVG or a json string for blend shapes
String animation = e.getAnimation();
});
// If VisemeID is the only thing you want, you can also use `SpeakTextAsync()`
SpeechSynthesisResult result = synthesizer.SpeakSsmlAsync(ssml).get();
speech_synthesizer = speechsdk.SpeechSynthesizer(speech_config=speech_config, audio_config=audio_config)
def viseme_cb(evt):
print("Viseme event received: audio offset: {}ms, viseme id: {}.".format(
evt.audio_offset / 10000, evt.viseme_id))
# `Animation` is an xml string for SVG or a json string for blend shapes
animation = evt.animation
# Subscribes to viseme received event
speech_synthesizer.viseme_received.connect(viseme_cb)
# If VisemeID is the only thing you want, you can also use `speak_text_async()`
result = speech_synthesizer.speak_ssml_async(ssml).get()
var synthesizer = new SpeechSDK.SpeechSynthesizer(speechConfig, audioConfig);
// Subscribes to viseme received event
synthesizer.visemeReceived = function (s, e) {
window.console.log("(Viseme), Audio offset: " + e.audioOffset / 10000 + "ms. Viseme ID: " + e.visemeId);
// `Animation` is an xml string for SVG or a json string for blend shapes
var animation = e.animation;
}
// If VisemeID is the only thing you want, you can also use `speakTextAsync()`
synthesizer.speakSsmlAsync(ssml);
SPXSpeechSynthesizer *synthesizer =
[[SPXSpeechSynthesizer alloc] initWithSpeechConfiguration:speechConfig
audioConfiguration:audioConfig];
// Subscribes to viseme received event
[synthesizer addVisemeReceivedEventHandler: ^ (SPXSpeechSynthesizer *synthesizer, SPXSpeechSynthesisVisemeEventArgs *eventArgs) {
NSLog(@"Viseme event received. Audio offset: %fms, viseme id: %lu.", eventArgs.audioOffset/10000., eventArgs.visemeId);
// `Animation` is an xml string for SVG or a json string for blend shapes
NSString *animation = eventArgs.Animation;
}];
// If VisemeID is the only thing you want, you can also use `SpeakText`
[synthesizer speakSsml:ssml];
فيما يلي مثال على إخراج viseme.
(Viseme), Viseme ID: 1, Audio offset: 200ms.
(Viseme), Viseme ID: 5, Audio offset: 850ms.
……
(Viseme), Viseme ID: 13, Audio offset: 2350ms.
بعد الحصول على إخراج فيزيم، يمكنك استخدام هذه الأحداث لدفع حركة الأحرف. يمكنك إنشاء الأحرف الخاصة بك وتحريكها تلقائياً.
الخطوات التالية
الملاحظات
قريبًا: خلال عام 2024، سنتخلص تدريجيًا من GitHub Issues بوصفها آلية إرسال ملاحظات للمحتوى ونستبدلها بنظام ملاحظات جديد. لمزيد من المعلومات، راجع https://aka.ms/ContentUserFeedback.
إرسال الملاحظات وعرضها المتعلقة بـ