نموذج تخطيط تحليل معلومات المستند
هام
- توفر إصدارات المعاينة العامة ل Document Intelligence وصولا مبكرا إلى الميزات قيد التطوير النشط.
- قد تتغير الميزات والنهج والعمليات، قبل التوفر العام (GA)، استنادا إلى ملاحظات المستخدم.
- إصدار المعاينة العامة لمكتبات عميل Document Intelligence افتراضيا إلى إصدار REST API 2024-02-29-preview.
- يتوفر إصدار المعاينة العامة 2024-02-29-preview حاليا فقط في مناطق Azure التالية:
- شرق الولايات المتحدة
- غرب الولايات المتحدة 2
- غرب أوروبا
ينطبق هذا المحتوى على:![]() v4.0 (معاينة) | الإصدارات السابقة:
v4.0 (معاينة) | الإصدارات السابقة:![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA)
v3.0 (GA)![]() v2.1 (GA)
v2.1 (GA)
ينطبق هذا المحتوى على:![]() v3.1 (GA) | أحدث إصدار:
v3.1 (GA) | أحدث إصدار:![]() v4.0 (معاينة) | الإصدارات السابقة:
v4.0 (معاينة) | الإصدارات السابقة:![]() v3.0
v3.0![]() v2.1
v2.1
ينطبق هذا المحتوى على:![]() v3.0 (GA) | أحدث الإصدارات:
v3.0 (GA) | أحدث الإصدارات:![]() v4.0 (معاينة)
v4.0 (معاينة)![]() v3.1 | الإصدار السابق:
v3.1 | الإصدار السابق:![]() v2.1
v2.1
ينطبق هذا المحتوى على:![]() v2.1 | أحدث إصدار:
v2.1 | أحدث إصدار:![]() v4.0 (معاينة)
v4.0 (معاينة)
نموذج تخطيط ذكاء المستند هو واجهة برمجة تطبيقات متقدمة لتحليل المستندات المستندة إلى التعلم الآلي متوفرة في سحابة Document Intelligence. يمكنك من أخذ المستندات بتنسيقات مختلفة وإرجاع تمثيلات البيانات المنظمة للمستندات. فهو يجمع بين إصدار محسن من قدرات التعرف البصري على الحروف (OCR) القوية مع نماذج التعلم العميق لاستخراج النص والجداول وعلامات التحديد وبنية المستند.
تحليل تخطيط المستند
تحليل تخطيط بنية المستند هو عملية تحليل مستند لاستخراج المناطق ذات الاهتمام والعلاقات بينهما. الهدف هو استخراج النص والعناصر الهيكلية من الصفحة لبناء نماذج فهم دلالي أفضل. يوجد نوعان من الأدوار في تخطيط المستند:
- الأدوار الهندسية: النص والجداول والأشكال وعلامات التحديد هي أمثلة على الأدوار الهندسية.
- الأدوار المنطقية: العناوين والعناوين والتذييلات هي أمثلة للأدوار المنطقية للنصوص.
يوضح الرسم التوضيحي التالي المكونات النموذجية في صورة لصفحة عينة.

خيارات التطوير
يدعم Document Intelligence v4.0 (2024-02-29-preview، 2023-10-31-preview) الأدوات والتطبيقات والمكتبات التالية:
| ميزة | الموارد | معرف النموذج |
|---|---|---|
| نموذج تخطيط | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-layout |
يدعم Document Intelligence v3.1 الأدوات والتطبيقات والمكتبات التالية:
| ميزة | الموارد | معرف النموذج |
|---|---|---|
| نموذج تخطيط | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-layout |
يدعم Document Intelligence v3.0 الأدوات والتطبيقات والمكتبات التالية:
| ميزة | الموارد | معرف النموذج |
|---|---|---|
| نموذج تخطيط | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-layout |
يدعم Document Intelligence v2.1 الأدوات والتطبيقات والمكتبات التالية:
| ميزة | الموارد |
|---|---|
| نموذج تخطيط | • أداة تسمية ذكاء المستند• REST API • مكتبة العميل SDK • حاوية Docker لذكاء المستند |
متطلبات الإدخال
للحصول على أفضل النتائج، قم بتوفير صورة واحدة واضحة أو مسح ضوئي عالي الجودة لكل مستند.
تنسيقات الملفات المعتمدة:
النموذج PDF الصورة:
JPEG/JPG، PNG، BMP، TIFF، HEIFMicrosoft Office:
Word (DOCX) وExcel (XLSX) وPowerPoint (PPTX) وHTMLقراءة ✔ ✔ ✔ Layout ✔ ✔ ✔ (معاينة 2024-02-29، 2023-10-31-preview) مستند عام ✔ ✔ منشأ مسبقًا ✔ ✔ استخراج مخصص ✔ ✔ تصنيف مخصص ✔ ✔ ✔ (2024-02-29-preview) بالنسبة لملفات PDF وTIFF، يمكن معالجة ما يصل إلى 2000 صفحة (بالنسببة للاشتراك المجاني، تتم معالجة أول صفحتين فقط).
حجم الملف لتحليل المستندات هو 500 ميغابايت للطبقة المدفوعة (S0) و4 ميغابايت للمستوى المجاني (F0).
يجب أن تتراوح أبعاد الصورة بين 50 × 50 بكسل و 10000 بكسل × 10000 بكسل.
إذا كانت ملفات PDF الخاصة بك مؤمنة بكلمة مرور، فيجب عليك إزالة القفل قبل الإرسال.
الحد الأدنى لارتفاع النص المراد استخراجه هو 12 بكسل لصورة 1024 × 768 بكسل. يتوافق هذا البعد مع نص نقطة تقريبا
8عند 150 نقطة لكل بوصة (DPI).بالنسبة للتدريب على النموذج المخصص، الحد الأقصى لعدد صفحات بيانات التدريب هو 500 لنموذج القالب المخصص و50000 للنموذج العصبي المخصص.
لتدريب نموذج الاستخراج المخصص، يبلغ الحجم الإجمالي لبيانات التدريب 50 ميغابايت لنموذج القالب و1G-MB للنموذج العصبي.
بالنسبة لتدريب نموذج التصنيف المخصص، يكون الحجم الإجمالي لبيانات
1GBالتدريب بحد أقصى 10000 صفحة.
- تنسيقات الملفات المدعومة: JPEG وPNG وPDF وTIFF.
- عدد الصفحات المدعومة: بالنسبة إلى PDF وTIFF، تتم معالجة ما يصل إلى 2000 صفحة. لمشتركي المستوى المجاني، تتم معالجة أول صفحتين فقط.
- حجم الملف المدعوم: يجب أن يكون حجم الملف أقل من 50 ميغابايت وأبعاد 50 × 50 بكسل على الأقل و10000 × 10000 بكسل على الأكثر.
بدء استخدام نموذج التخطيط
تعرف على كيفية استخراج البيانات، بما في ذلك النص والجداول ورؤوس الجداول وعلامات التحديد ومعلومات البنية من المستندات باستخدام Document Intelligence. تحتاج إلى الموارد التالية:
اشتراك Azure - يمكنك إنشاء اشتراك مجانا.
مثيل Document Intelligence في مدخل Microsoft Azure. يمكنك استخدام طبقة التسعير المجانية
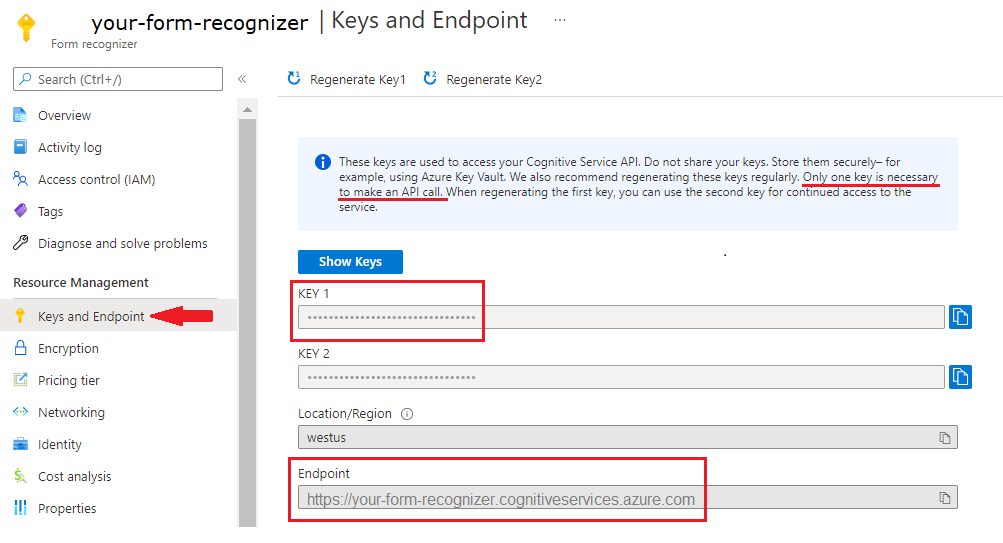
F0() لتجربة الخدمة. بعد نشر المورد، حدد انتقال إلى المورد للحصول على المفتاح ونقطة النهاية.
إشعار
يتوفر Document Intelligence Studio مع واجهات برمجة التطبيقات v3.0 والإصدارات الأحدث.
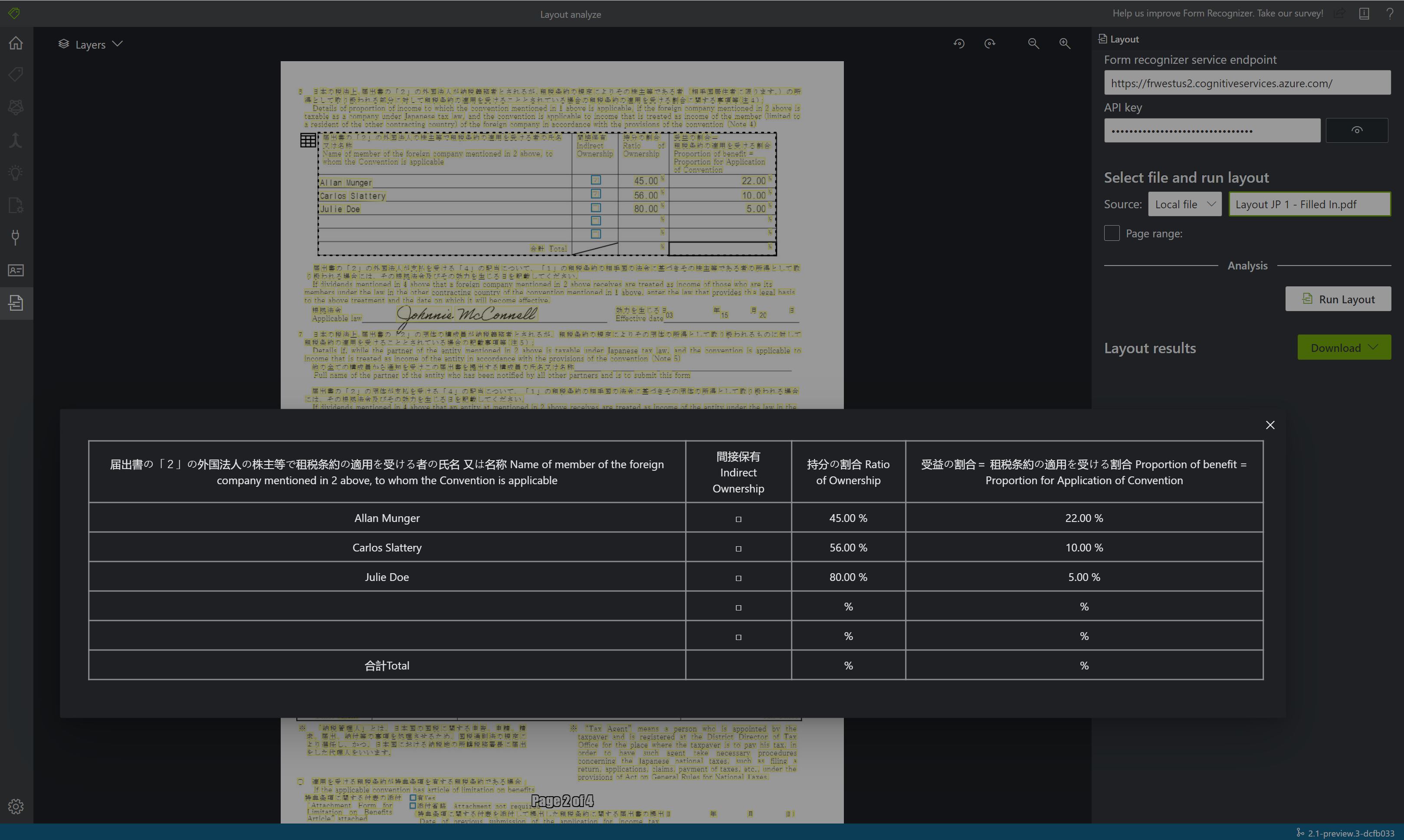
نموذج مستند تمت معالجته باستخدام Document Intelligence Studio
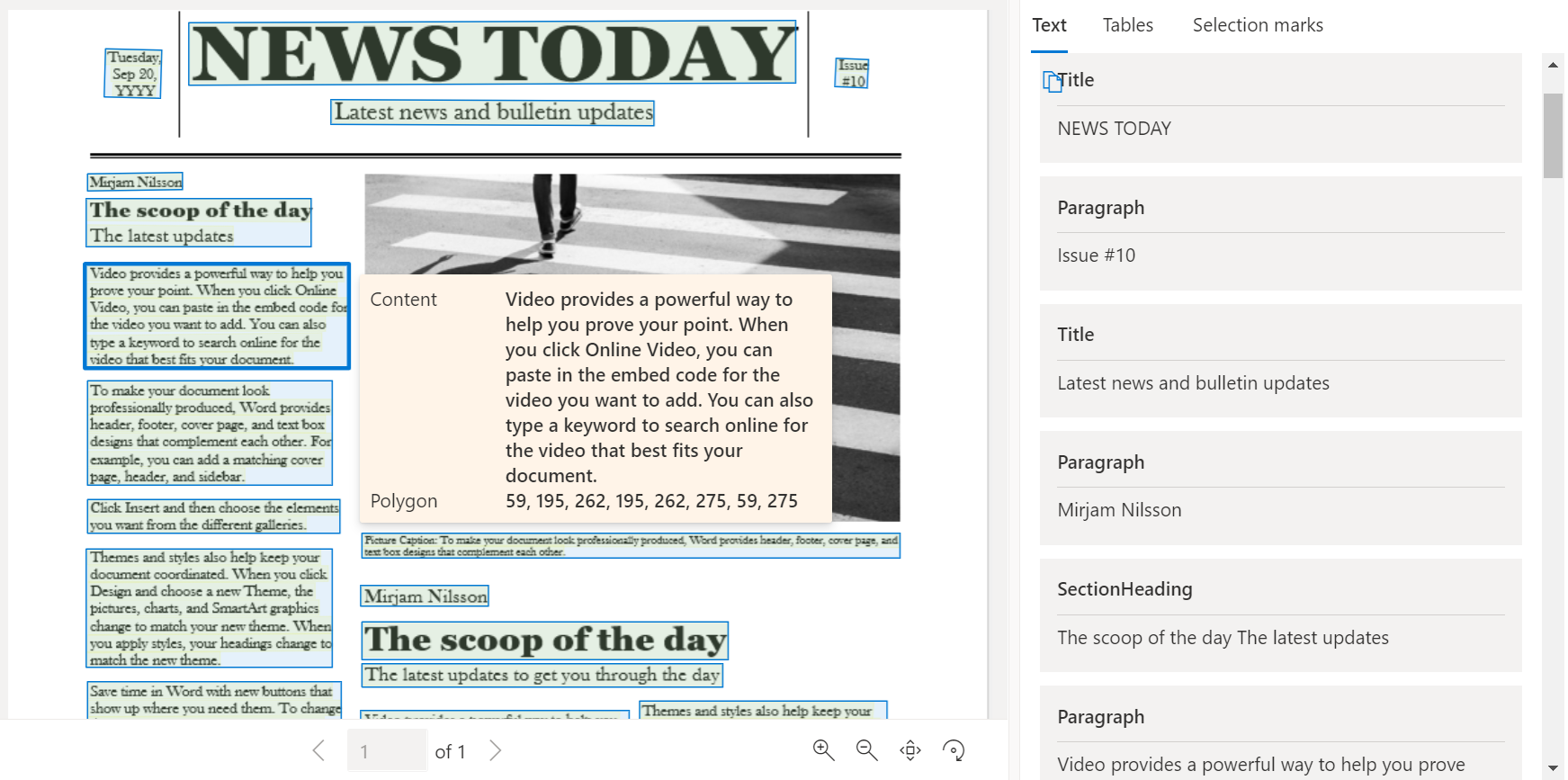
في الصفحة الرئيسية ل Document Intelligence Studio، حدد Layout.
يمكنك تحليل نموذج المستند أو تحميل ملفاتك الخاصة.
حدد الزر Run analysis، وقم بتكوين خيارات Analyze، إذا لزم الأمر:

أداة تسمية نموذج تحليل معلومات المستند
انتقل إلى أداة نموذج Document Intelligence.
في الصفحة الرئيسية لأداة العينة حدد Use Layout to get text, tables and selection marks.
في حقل نقطة نهاية خدمة Document Intelligence، الصق نقطة النهاية التي حصلت عليها باستخدام اشتراك Document Intelligence.
في حقل المفتاح ، الصق المفتاح الذي حصلت عليه من مورد Document Intelligence.
في حقل المصدر ، حدد URL من القائمة المنسدلة يمكنك استخدام نموذج المستند:
حدد الزر إحضار.
حدد تشغيل التخطيط. تستدعي
Analyze Layoutأداة تسمية نموذج تحليل معلومات المستند واجهة برمجة التطبيقات لتحليل المستند.
عرض النتائج - راجع النص المميز المستخرج وعلامات التحديد المكتشفة والجداول المكتشفة.
{kind=link}
اللغات والإعدادات المحلية المدعومة
راجع صفحة نماذج تحليل اللغة للحصول على قائمة كاملة باللغات المدعومة.
يدعم Document Intelligence v2.1 الأدوات والتطبيقات والمكتبات التالية:
| ميزة | الموارد |
|---|---|
| واجهة برمجة تطبيقات التخطيط |
استخراج البيانات
يستخرج نموذج التخطيط النص وعلامات التحديد والجداول والفقرات وأنواع الفقرات (roles) من المستند.
إشعار
تدعم الإصدارات 2024-02-29-preview2023-10-31-previewو و ملفات Microsoft office (DOCX و XLSX و PPTX) و HTML. الميزات التالية غير مدعمة:
- لا توجد زاوية وعرض/ارتفاع ووحدة مع كل كائن صفحة.
- لكل كائن تم اكتشافه، لا توجد مضلع إحاطة أو منطقة حدود.
- نطاق الصفحة (
pages) غير معتمد كمعلمة. - لا يوجد
linesكائن.
الصفحات
مجموعة الصفحات هي قائمة بالصفحات داخل المستند. يتم تمثيل كل صفحة بشكل تسلسلي داخل المستند وتتضمن زاوية الاتجاه التي تشير إلى ما إذا كان يتم تدوير الصفحة والعرض والارتفاع (الأبعاد بالبكسل). يتم حساب وحدات الصفحة في إخراج النموذج كما هو موضح:
| تنسيق الملف | وحدة الصفحة المحسوبة | إجمالي الصفحات |
|---|---|---|
| الصور (JPEG/JPG، PNG، BMP، HEIF) | كل صورة = وحدة صفحة واحدة | إجمالي الصور |
| كل صفحة في PDF = وحدة صفحة واحدة | إجمالي الصفحات في ملف PDF | |
| TIFF | كل صورة في وحدة صفحة TIFF = 1 | إجمالي الصور في TIFF |
| Word (DOCX) | ما يصل إلى 3000 حرف = وحدة صفحة واحدة أو صور مضمنة أو مرتبطة غير مدعومة | إجمالي الصفحات التي يصل عددها إلى 3000 حرف لكل منها |
| Excel (XLSX) | كل ورقة عمل = وحدة صفحة واحدة أو صور مضمنة أو مرتبطة غير معتمدة | إجمالي أوراق العمل |
| PowerPoint (PPTX) | كل شريحة = وحدة صفحة واحدة أو صور مضمنة أو مرتبطة غير معتمدة | إجمالي الشرائح |
| HTML | ما يصل إلى 3000 حرف = وحدة صفحة واحدة أو صور مضمنة أو مرتبطة غير مدعومة | إجمالي الصفحات التي يصل عددها إلى 3000 حرف لكل منها |
"pages": [
{
"pageNumber": 1,
"angle": 0,
"width": 915,
"height": 1190,
"unit": "pixel",
"words": [],
"lines": [],
"spans": []
}
]
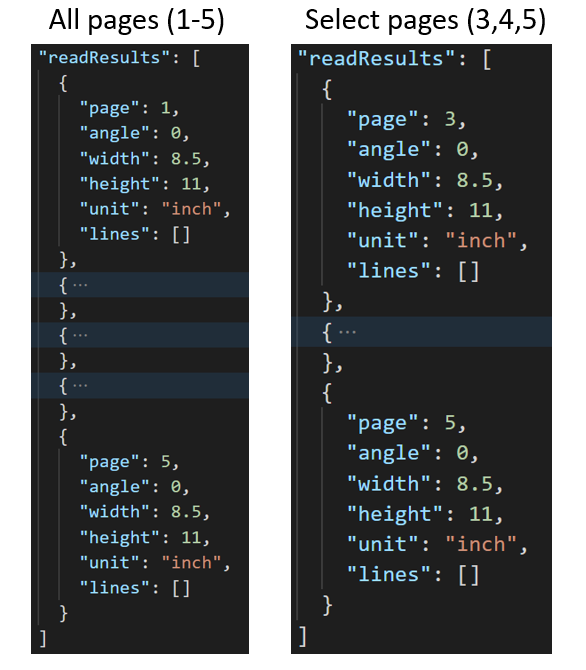
استخراج الصفحات المحددة من المستندات
بالنسبة للمستندات الكبيرة متعددة الصفحات، استخدم معلمةpages الاستعلام من أجل الإشارة إلى أرقام صفحات أو نطاقات صفحات معينة لاستخراج النص.
الفقرات
يستخرج نموذج التخطيط جميع كتل النص المحددة فيparagraphsالمجموعة كعنصر المستوى الأعلى ضمنanalyzeResults. يمثل كل إدخال في هذه المجموعة كتلة نصية ويشمل النص المستخرج كإحداثياتcontentالإحاطةpolygon. spanنقاط المعلومات لجزء النص داخل خاصية المستوىcontentالأعلى التي تحتوي على النص الكامل من المستند.
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"content": "While healthcare is still in the early stages of its Al journey, we are seeing pharmaceutical and other life sciences organizations making major investments in Al and related technologies.\" TOM LAWRY | National Director for Al, Health and Life Sciences | Microsoft"
}
]
أدوار الفقرات
يستخرج الكشف الجديد عن كائن الصفحة المستند إلى التعلم الآلي الأدوار المنطقية مثل العناوين وعناوين المقاطع ورؤوس الصفحات وتذييلات الصفحات والمزيد. يعين نموذج تخطيط المعلومات المستندية كتل نصية معينة في paragraphs المجموعة مع دورها المتخصص أو النوع الذي يتوقعه النموذج. من الأفضل استخدامها مع المستندات غير المهيكلة للمساعدة في فهم تخطيط المحتوى المستخرج لتحليل دلالي أكثر ثراءً. يتم دعم أدوار الفقرة التالية:
| دور متوقع | الوصف | أنواع الملفات المدعومة |
|---|---|---|
title |
العناوين الرئيسية في الصفحة | pdf، صورة، docx، pptx، xlsx، html |
sectionHeading |
عنوان فرعي واحد أو أكثر على الصفحة | pdf، صورة، docx، xlsx، html |
footnote |
رسالة نصية بالقرب من أسفل الصفحة | pdf، صورة |
pageHeader |
رسالة نصية بالقرب من الحافة العلوية للصفحة | pdf، صورة، مستند |
pageFooter |
رسالة نصية بالقرب من الحافة السفلية للصفحة | pdf، صورة، docx، pptx، html |
pageNumber |
رقم الصفحة | pdf، صورة |
{
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"role": "title",
"content": "NEWS TODAY"
},
{
"spans": [],
"boundingRegions": [],
"role": "sectionHeading",
"content": "Mirjam Nilsson"
}
]
}
النص والخطوط والكلمات
يستخرج نموذج تخطيط المستند في Document Intelligence نص النمط المطبوع والمكتوب بخط اليد ك lines و words. تشمل المجموعة styles أي نمط مكتوب بخط اليد للخطوط، إذا تم اكتشافه، إلى جانب الامتدادات التي تشير إلى النص المقترن. تنطبق هذه الميزة علىلغات الكمبيوتر المعتمدة المكتوبة بخط اليد.
بالنسبة إلى Microsoft Word وExcel وPowerPoint وHTML، يقوم نموذج تخطيط المستند 2024-02-29-preview و2023-10-31-preview باستخراج كل النص المضمن كما هو. يتم استخراج النصوص ككلمات وفقرات. الصور المضمنة غير مدعومة.
"words": [
{
"content": "While",
"polygon": [],
"confidence": 0.997,
"span": {}
},
],
"lines": [
{
"content": "While healthcare is still in the early stages of its Al journey, we",
"polygon": [],
"spans": [],
}
]
نمط مكتوب بخط اليد لخطوط النص
تتضمن الاستجابة تصنيف ما إذا كان كل سطر نصي من نمط خط اليد أم لا، إلى جانب درجة الثقة. لمزيد من المعلومات. راجع دعم اللغة المكتوبة بخط اليد. يوضح المثال التالي مثالا لمقتطف JSON.
"styles": [
{
"confidence": 0.95,
"spans": [
{
"offset": 509,
"length": 24
}
"isHandwritten": true
]
}
إذا قمت بتمكين إمكانية إضافة الخط/النمط، فستحصل أيضا على نتيجة الخط/النمط كجزء من styles العنصر.
علامات التحديد
يستخرج نموذج التخطيط أيضا علامات التحديد من المستندات. تظهر علامات التحديد المستخرجة خلالpagesالمجموعة لكل صفحة. وهي تشمل الإحاطةpolygonوconfidence والتحديدstate (selected/unselected). يتم أيضا تضمين تمثيل النص (أي و:unselected:selected:) كفهرس البداية (offset) ويشير length إلى خاصية المستوى content الأعلى التي تحتوي على النص الكامل من المستند.
{
"selectionMarks": [
{
"state": "unselected",
"polygon": [],
"confidence": 0.995,
"span": {
"offset": 1421,
"length": 12
}
}
]
}
الجداول
استخراج الجداول هو مطلب رئيسي لمعالجة المستندات التي تحتوي على كميات كبيرة من البيانات المنسقة عادة كجداول. يستخرج نموذج التخطيط الجداول في pageResults قسم من إخراج JSON. تشمل معلومات الجدول المستخرجة عدد الأعمدة والصفوف وامتداد الصفوف وامتداد الأعمدة. يتم إخراج كل خلية ذات المضلع المحيط بها مع معلومات حول ما إذا كان يتم التعرف على المنطقة على columnHeader أنها أم لا. يدعم النموذج استخراج الجداول التي يتم تدويرها. تحتوي كل خلية جدول على فهرس الصف والعمود والإحداثيات المتعلقة بالمضلع المحيط. بالنسبة لنص الخلية، فيقوم النموذج إخراج المعلومات التيspanتحتوي على فهرس البدء (offset). يقوم النموذج أيضا إخراج length داخل محتوى المستوى الأعلى الذي يحتوي على النص الكامل من المستند.
إشعار
الجدول غير معتمد إذا كان ملف الإدخال XLSX.
{
"tables": [
{
"rowCount": 9,
"columnCount": 4,
"cells": [
{
"kind": "columnHeader",
"rowIndex": 0,
"columnIndex": 0,
"columnSpan": 4,
"content": "(In millions, except earnings per share)",
"boundingRegions": [],
"spans": []
},
]
}
]
}
التعليقات التوضيحية (متوفرة فقط في 2023-02-28-preview واجهة برمجة التطبيقات.)
يستخرج نموذج التخطيط التعليقات التوضيحية في المستندات، مثل عمليات التحقق والعبور. تتضمن الاستجابة نوع التعليق التوضيحي، جنبا إلى جنب مع درجة الثقة والمضلع المحيط.
{
"pages": [
{
"annotations": [
{
"kind": "cross",
"polygon": [...],
"confidence": 1
}
]
}
]
}
الإخراج إلى تنسيق markdown
يمكن لواجهة برمجة تطبيقات التخطيط إخراج النص المستخرج بتنسيق markdown. outputContentFormat=markdown استخدم لتحديد تنسيق الإخراج في markdown. يتم إخراج محتوى markdown كجزء من content القسم.
"analyzeResult": {
"apiVersion": "2024-02-29-preview",
"modelId": "prebuilt-layout",
"contentFormat": "markdown",
"content": "# CONTOSO LTD...",
}
الارقام
تلعب الأرقام (المخططات والصور) في الوثائق دورا حاسما في استكمال وتعزيز المحتوى النصي، وتوفير تمثيلات مرئية تساعد في فهم المعلومات المعقدة. يحتوي كائن الرسوم التوضيحية الذي تم اكتشافه بواسطة نموذج التخطيط على خصائص رئيسية مثل boundingRegions (المواقع المكانية للرسم التوضيحي على صفحات المستند، بما في ذلك رقم الصفحة وإحداثيات المضلع التي تحدد حدود الرسم التوضيحي)، spans (تفاصيل تمتد النص المتعلقة بالرسم التوضيحي، وتحديد إزاحاتها وأطوالها داخل نص المستند. يساعد هذا الاتصال في إقران الشكل بالسياق النصي ذي الصلة)، elements (معرفات العناصر النصية أو الفقرات داخل المستند التي ترتبط بالشكل التوضيحي أو تصفه) وإذا caption كان هناك أي منها.
{
"figures": [
{
"boundingRegions": [],
"spans": [],
"elements": [
"/paragraphs/15",
...
],
"caption": {
"content": "Here is a figure with some text",
"boundingRegions": [],
"spans": [],
"elements": [
"/paragraphs/15"
]
}
}
]
}
الأقسام
يعد تحليل بنية المستندات الهرمية محوريا في تنظيم المستندات الشاملة وإدراكها ومعالجتها. يعد هذا النهج حيويا لتقسيم الوثائق الطويلة دلاليا لتعزيز الفهم وتسهيل التنقل وتحسين استرداد المعلومات. إن ظهور Retrieval Augmented Generation (RAG) في الذكاء الاصطناعي إنشاء المستندات يؤكد أهمية تحليل بنية المستند الهرمي. يدعم نموذج التخطيط المقاطع والأقسام الفرعية في الإخراج، والذي يحدد علاقة المقاطع والعنصر داخل كل مقطع. يتم الاحتفاظ بالبنية الهرمية في elements كل قسم. يمكنك استخدام الإخراج لتنسيق markdown للحصول على المقاطع والأقسام الفرعية بسهولة في markdown.
{
"sections": [
{
"spans": [],
"elements": [
"/paragraphs/0",
"/sections/1",
"/sections/2",
"/sections/5"
]
},
...
}
إخراج ترتيب القراءة الطبيعية (اللاتينية فقط)
يمكنك تحديد الترتيب الذي يتم به إخراج أسطر النص باستخدام معلمة readingOrder الاستعلام. استخدم natural لإخراج ترتيب قراءة أكثر ملاءمة للإنسان كما هو موضح في المثال التالي. هذه الميزة مدعومة فقط للغات اللاتينية.

حدد أرقام الصفحات أو النطاقات لاستخراج النص
بالنسبة للمستندات الكبيرة متعددة الصفحات، استخدم معلمةpages الاستعلام من أجل الإشارة إلى أرقام صفحات أو نطاقات صفحات معينة لاستخراج النص. يوضح المثال التالي مستنداً من 10 صفحات، مع نص مستخرج لكلتا الحالتين - جميع الصفحات (1-10) والصفحات المحددة (3-6).
عملية الحصول على تحليل نتيجة التخطيط
الخطوة الثانية هي استدعاء عملية الحصول على تحليل نتيجة التخطيط. تأخذ هذه العملية كمدخل معرف النتيجة الذي أنشأته Analyze Layout العملية. تقوم بإرجاع استجابة JSON التي تحتوي على حقل status بالقيم المحتملة التالية.
| الحقل | نوع | القيم المحتملة |
|---|---|---|
| الحالة | سلسلة | notStarted: لم يتم بدء عملية التحليل.running: عملية التحليل قيد التقدم. failed: فشلت عملية التحليل. succeeded: نجحت عملية التحليل. |
قم باستدعاء هذه العملية بشكل متكرر حتى تقوم بإرجاع succeeded القيمة. لتجنب تجاوز الطلبات في الثانية (RPS)، استخدم فاصلا زمنيا من 3 إلى 5 ثوان.
عندما يحتوي حقل الحالة على succeeded القيمة، تتضمن استجابة JSON التخطيط المستخرج والنص والجداول وعلامات التحديد. تتضمن البيانات المستخرجة أسطر نصية وكلمات مستخرجة ومربعات إحاطة ومظهر نص مع إشارة مكتوبة بخط اليد وجداول وعلامات تحديد مع الإشارة إليها محددة/غير محددة.
التصنيف المكتوب بخط اليد للخطوط النصية (اللاتينية فقط)
تتضمن الاستجابة تصنيف ما إذا كان كل سطر نصي من نمط خط اليد أم لا، إلى جانب درجة الثقة. هذه الميزة مدعومة فقط للغات اللاتينية. يوضح المثال التالي التصنيف المكتوب بخط اليد للنص في الصورة.

عينة إخراج JSON
الاستجابة لعملية الحصول على تحليل نتيجة التخطيط هي تمثيل منظم للمستند مع استخراج جميع المعلومات. انظر هنا للحصول على نموذج ملف مستند وإخراج تخطيط نموذج الإخراج المنظم الخاص به.
يحتوي إخراج JSON على جزأين:
readResultsتحتوي العقدة على كل النص الذي تم التعرف عليه وعلامة التحديد. التسلسل الهرمي للعرض التقديمي للنص هو صفحة، ثم سطر، ثم كلمات فردية.pageResultsتحتوي العقدة على الجداول والخلايا المستخرجة بمربعات الإحاطة والثقة والمرجع إلى الأسطر والكلمات في حقل "readResults".
مثال على الإخراج
النص
تستخرج واجهة برمجة تطبيقات التخطيط النص من المستندات والصور بزوايا وألوان نصية متعددة. وهو يقبل صور المستندات والفاكسات والنصوص المطبوعة و/أو المكتوبة بخط اليد (باللغة الإنجليزية فقط) والأوضاع المختلطة. يتم استخراج النص بالمعلومات المتوفرة على الأسطر والكلمات ومربعات الإحاطة ودرجات الثقة والنمط (مكتوب بخط اليد أو غير ذلك). يتم تضمين جميع المعلومات النصية في readResults قسم من إخراج JSON.
الجداول ذات الرؤوس
تستخرج واجهة برمجة تطبيقات تخطيط الجداول فيpageResultsقسم إخراج JSON. يمكن مسح المستندات ضوئياً أو تصويرها أو ترقيمها. يمكن أن تكون الجداول معقدة مع الخلايا أو الأعمدة المدمجة، مع حدود أو بدونها، وبزوايا فردية. تشمل معلومات الجدول المستخرجة عدد الأعمدة والصفوف وامتداد الصفوف وامتداد الأعمدة. يتم إخراج كل خلية بمربع الإحاطة الخاص بها مع ما إذا كان يتم التعرف على المنطقة كجزء من رأس أم لا. يمكن أن تمتد خلايا الرأس المتوقعة للنموذج على صفوف متعددة، وهي ليست بالضرورة الصفوف الأولى في جدول. كما أنها تعمل مع الجداول التي تم تدويرها. تتضمن كل خلية جدول أيضا النص الكامل مع مراجع للكلمات الفردية في readResults المقطع.
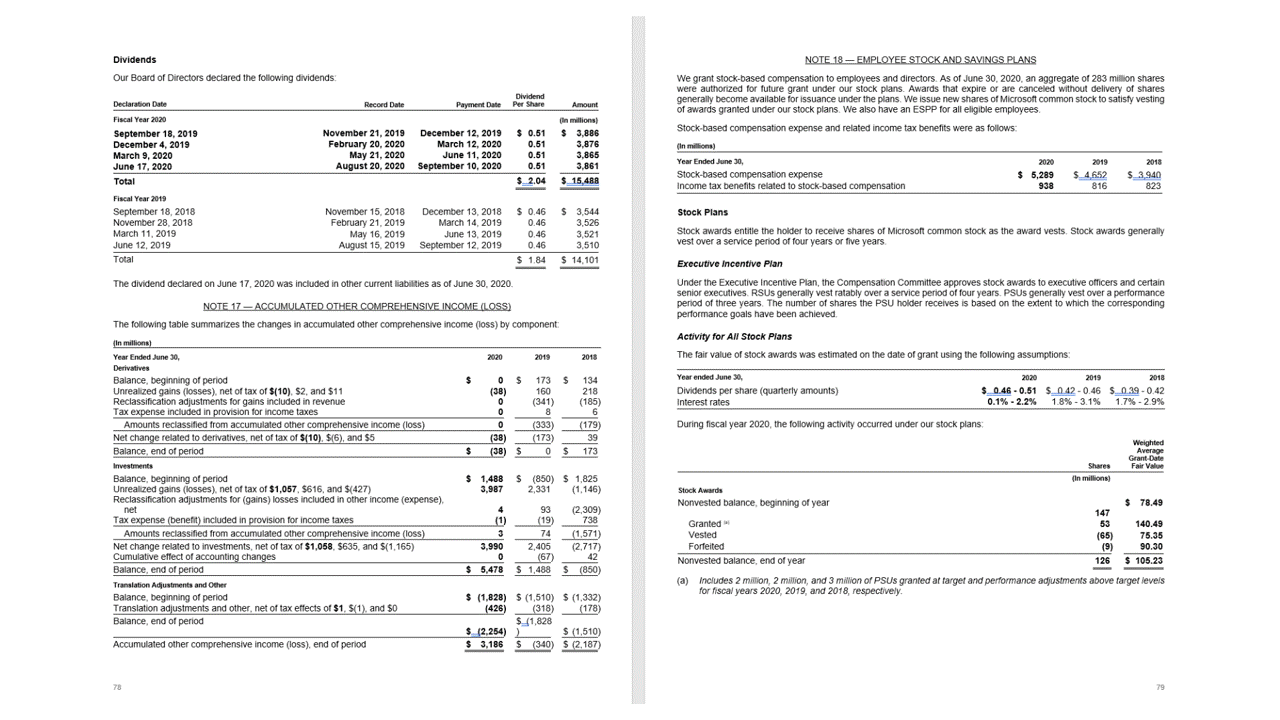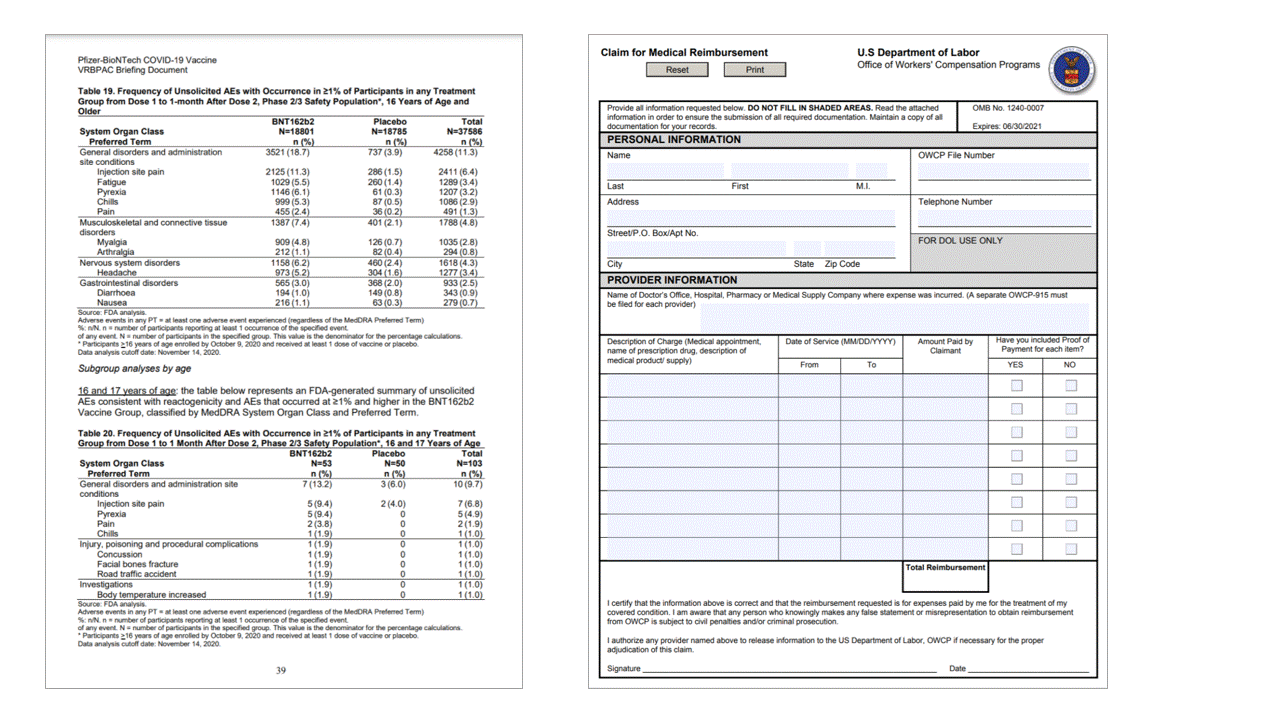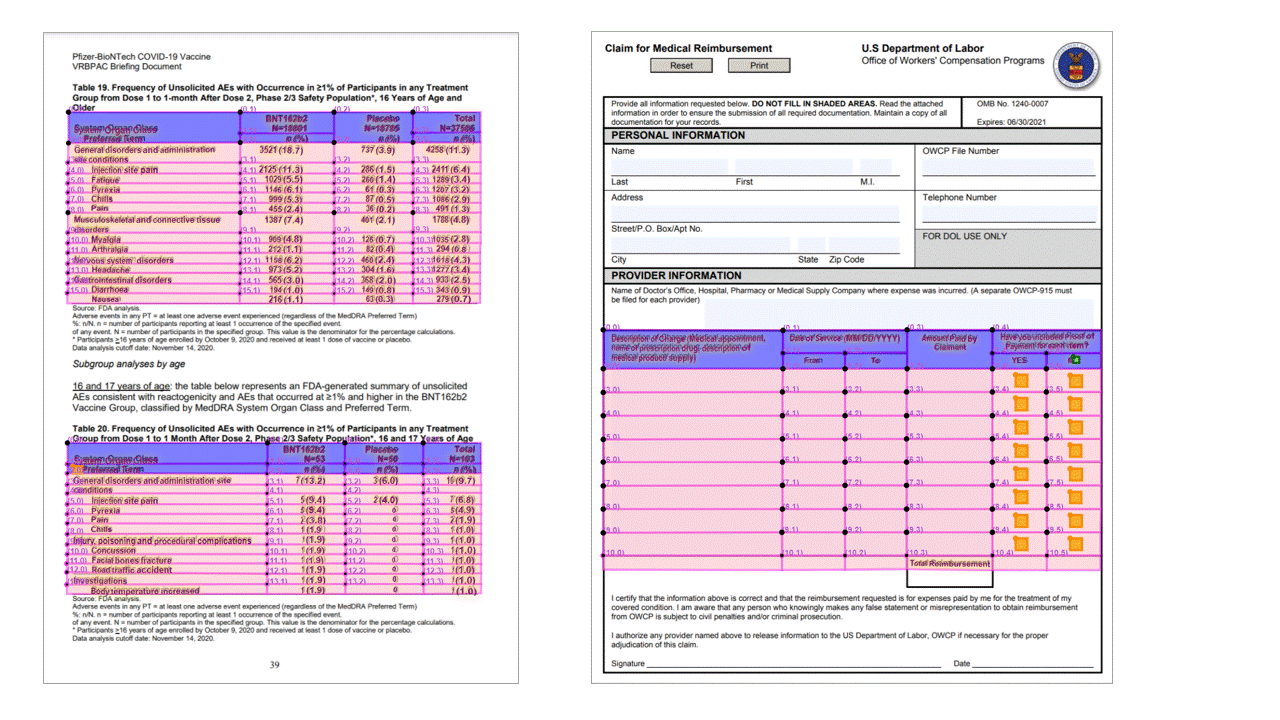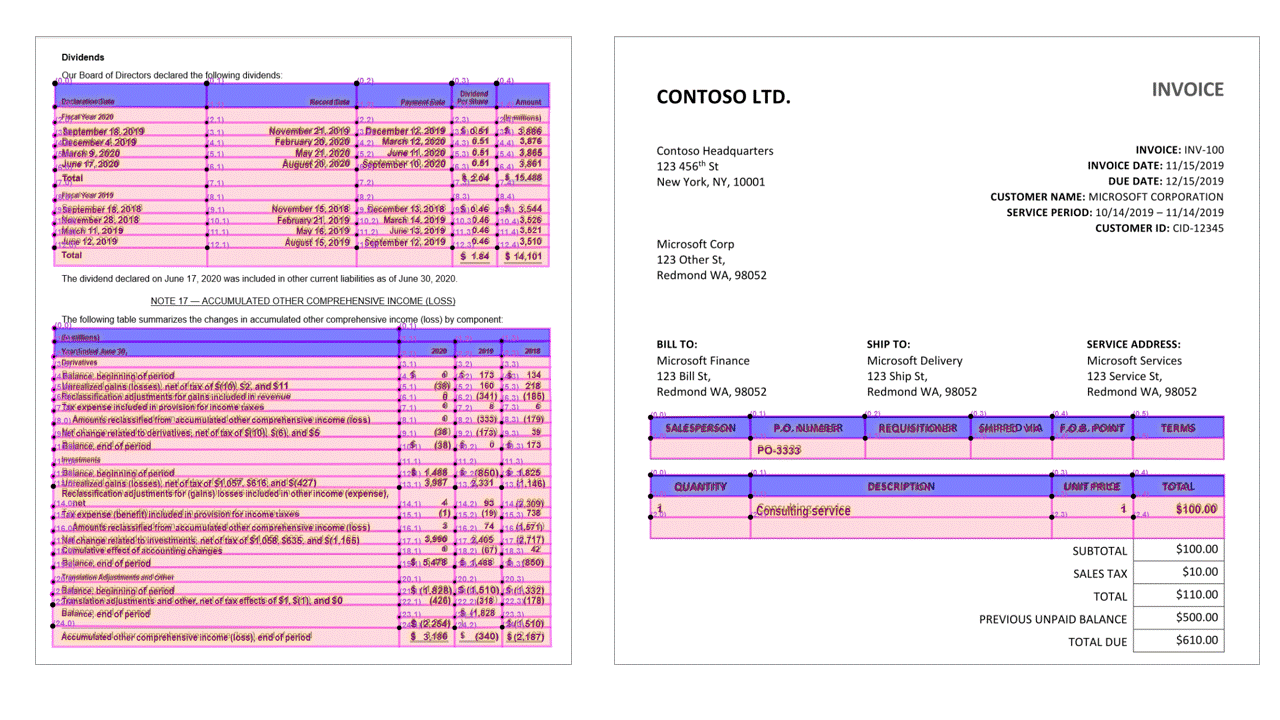
علامات التحديد
تقوم Layout API أيضًا باستخراج علامات التحديد من المستندات. تتضمن علامات التحديد المستخرجة المربع المحيط والثقة والحالة (محدد/غير محدد). يتم استخراج معلومات علامة التحديد في readResults قسم من إخراج JSON.
دليل الترحيل
- اتبع دليل ترحيل Document Intelligence v3.1 لمعرفة كيفية استخدام إصدار v3.1 في التطبيقات وسير العمل.
الخطوات التالية
تعرف على كيفية معالجة النماذج والمستندات الخاصة بك باستخدام Document Intelligence Studio.
أكمل التشغيل السريع ل Document Intelligence وابدأ في إنشاء تطبيق لمعالجة المستندات بلغة التطوير التي تختارها.
تعرف على كيفية معالجة النماذج والمستندات الخاصة بك باستخدام أداة تسمية نموذج ذكاء المستند.
أكمل التشغيل السريع ل Document Intelligence وابدأ في إنشاء تطبيق لمعالجة المستندات بلغة التطوير التي تختارها.