نموذج قراءة تحليل معلومات المستند
هام
- توفر إصدارات المعاينة العامة ل Document Intelligence وصولا مبكرا إلى الميزات قيد التطوير النشط.
- قد تتغير الميزات والنهج والعمليات، قبل التوفر العام (GA)، استنادا إلى ملاحظات المستخدم.
- إصدار المعاينة العامة لمكتبات عميل Document Intelligence افتراضيا إلى إصدار REST API 2024-02-29-preview.
- يتوفر إصدار المعاينة العامة 2024-02-29-preview حاليا فقط في مناطق Azure التالية:
- شرق الولايات المتحدة
- غرب الولايات المتحدة 2
- غرب أوروبا
ينطبق هذا المحتوى على:![]() v4.0 (معاينة) | الإصدارات السابقة:
v4.0 (معاينة) | الإصدارات السابقة:![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA)
v3.0 (GA)
ينطبق هذا المحتوى على:![]() v3.1 (GA) | أحدث إصدار:
v3.1 (GA) | أحدث إصدار:![]() v4.0 (معاينة) | الإصدارات السابقة:
v4.0 (معاينة) | الإصدارات السابقة:![]() v3.0
v3.0
ينطبق هذا المحتوى على:![]() v3.0 (GA) | أحدث الإصدارات:
v3.0 (GA) | أحدث الإصدارات:![]() v4.0 (معاينة)
v4.0 (معاينة)![]() v3.1
v3.1
إشعار
لاستخراج النص من الصور الخارجية مثل التسميات وعلامات الشوارع والملصقات، استخدم ميزة القراءة Azure الذكاء الاصطناعي Image Analysis v4.0 المحسنة للصور العامة غير المستندة باستخدام واجهة برمجة تطبيقات متزامنة محسنة الأداء تسهل تضمين التعرف البصري على الحروف (OCR) في سيناريوهات تجربة المستخدم.
يعمل نموذج Document Intelligence Read Optical Character Recognition (OCR) بدقة أعلى من Azure الذكاء الاصطناعي Vision Read ويستخرج النص المطبوع والمكتوب بخط اليد من مستندات PDF والصور الممسوحة ضوئيا. كما يتضمن الدعم لاستخراج النص من مستندات Microsoft Word وExcel وPowerPoint وHTML. يكتشف الفقرات وخطوط النص والكلمات والمواقع واللغات. نموذج القراءة هو محرك التعرف البصري على الحروف (OCR) الأساسي للنماذج الأخرى التي تم إنشاؤها مسبقا ل Document Intelligence مثل التخطيط والمستند العام والفاتورة والإيصال والهوية (ID) وبطاقة التأمين الصحي وW2 بالإضافة إلى النماذج المخصصة.
ما هو التعرف البصري على الحروف للمستندات؟
تم تحسين التعرف البصري على الأحرف (OCR) للمستندات للمستندات الكبيرة ذات النصوص الثقيلة بتنسيقات ملفات متعددة ولغات عمومية. وهو يتضمن ميزات مثل المسح الضوئي عالي الدقة لصور المستندات من أجل معالجة أفضل للنص الأصغر والكثيفة؛ الكشف عن الفقرات؛ وإدارة النماذج القابلة للتعبئة. تتضمن قدرات التعرف البصري على الحروف أيضا سيناريوهات متقدمة مثل مربعات الأحرف الفردية والاستخراج الدقيق لحقول المفاتيح الموجودة عادة في الفواتير والإيصالات والسيناريوهات الأخرى التي تم إنشاؤها مسبقا.
خيارات التطوير
يدعم Document Intelligence v4.0 (2024-02-29-preview، 2023-10-31-preview) الأدوات والتطبيقات والمكتبات التالية:
| ميزة | الموارد | معرف النموذج |
|---|---|---|
| قراءة نموذج التعرف البصري على الحروف (OCR) | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-read |
يدعم Document Intelligence v3.1 الأدوات والتطبيقات والمكتبات التالية:
| ميزة | الموارد | معرف النموذج |
|---|---|---|
| قراءة نموذج التعرف البصري على الحروف (OCR) | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-read |
يدعم Document Intelligence v3.0 الأدوات والتطبيقات والمكتبات التالية:
| ميزة | الموارد | معرف النموذج |
|---|---|---|
| قراءة نموذج التعرف البصري على الحروف (OCR) | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-read |
متطلبات الإدخال
للحصول على أفضل النتائج، قم بتوفير صورة واحدة واضحة أو مسح ضوئي عالي الجودة لكل مستند.
تنسيقات الملفات المعتمدة:
النموذج PDF الصورة:
JPEG/JPG، PNG، BMP، TIFF، HEIFMicrosoft Office:
Word (DOCX) وExcel (XLSX) وPowerPoint (PPTX) وHTMLقراءة ✔ ✔ ✔ Layout ✔ ✔ ✔ (معاينة 2024-02-29، 2023-10-31-preview) مستند عام ✔ ✔ منشأ مسبقًا ✔ ✔ استخراج مخصص ✔ ✔ تصنيف مخصص ✔ ✔ ✔ (2024-02-29-preview) بالنسبة لملفات PDF وTIFF، يمكن معالجة ما يصل إلى 2000 صفحة (بالنسببة للاشتراك المجاني، تتم معالجة أول صفحتين فقط).
حجم الملف لتحليل المستندات هو 500 ميغابايت للطبقة المدفوعة (S0) و4 ميغابايت للمستوى المجاني (F0).
يجب أن تتراوح أبعاد الصورة بين 50 × 50 بكسل و 10000 بكسل × 10000 بكسل.
إذا كانت ملفات PDF الخاصة بك مؤمنة بكلمة مرور، فيجب عليك إزالة القفل قبل الإرسال.
الحد الأدنى لارتفاع النص المراد استخراجه هو 12 بكسل لصورة 1024 × 768 بكسل. يتوافق هذا البعد مع نص نقطة تقريبا
8عند 150 نقطة لكل بوصة (DPI).بالنسبة للتدريب على النموذج المخصص، الحد الأقصى لعدد صفحات بيانات التدريب هو 500 لنموذج القالب المخصص و50000 للنموذج العصبي المخصص.
لتدريب نموذج الاستخراج المخصص، يبلغ الحجم الإجمالي لبيانات التدريب 50 ميغابايت لنموذج القالب و1G-MB للنموذج العصبي.
بالنسبة لتدريب نموذج التصنيف المخصص، يكون الحجم الإجمالي لبيانات
1GBالتدريب بحد أقصى 10000 صفحة.
بدء استخدام نموذج القراءة
حاول استخراج النص من النماذج والمستندات باستخدام Document Intelligence Studio. تحتاج إلى الأصول التالية:
اشتراك Azure - يمكنك إنشاء اشتراك مجانا.
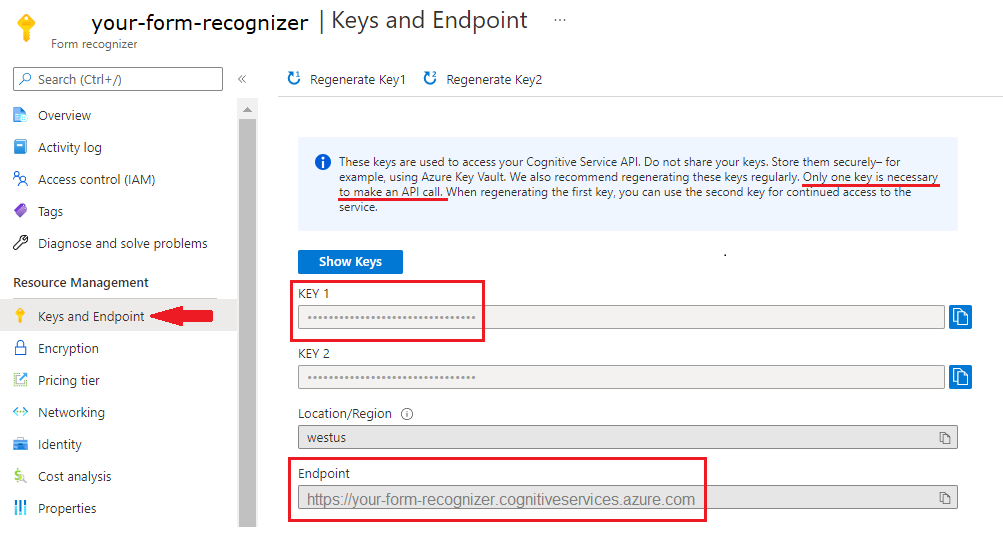
مثيل Document Intelligence في مدخل Microsoft Azure. يمكنك استخدام طبقة التسعير المجانية
F0() لتجربة الخدمة. بعد نشر المورد، حدد انتقال إلى المورد للحصول على المفتاح ونقطة النهاية.
إشعار
حاليا، لا يدعم Document Intelligence Studio تنسيقات ملفات Microsoft Word وExcel وPowerPoint وHTML.
نموذج مستند تمت معالجته باستخدام Document Intelligence Studio
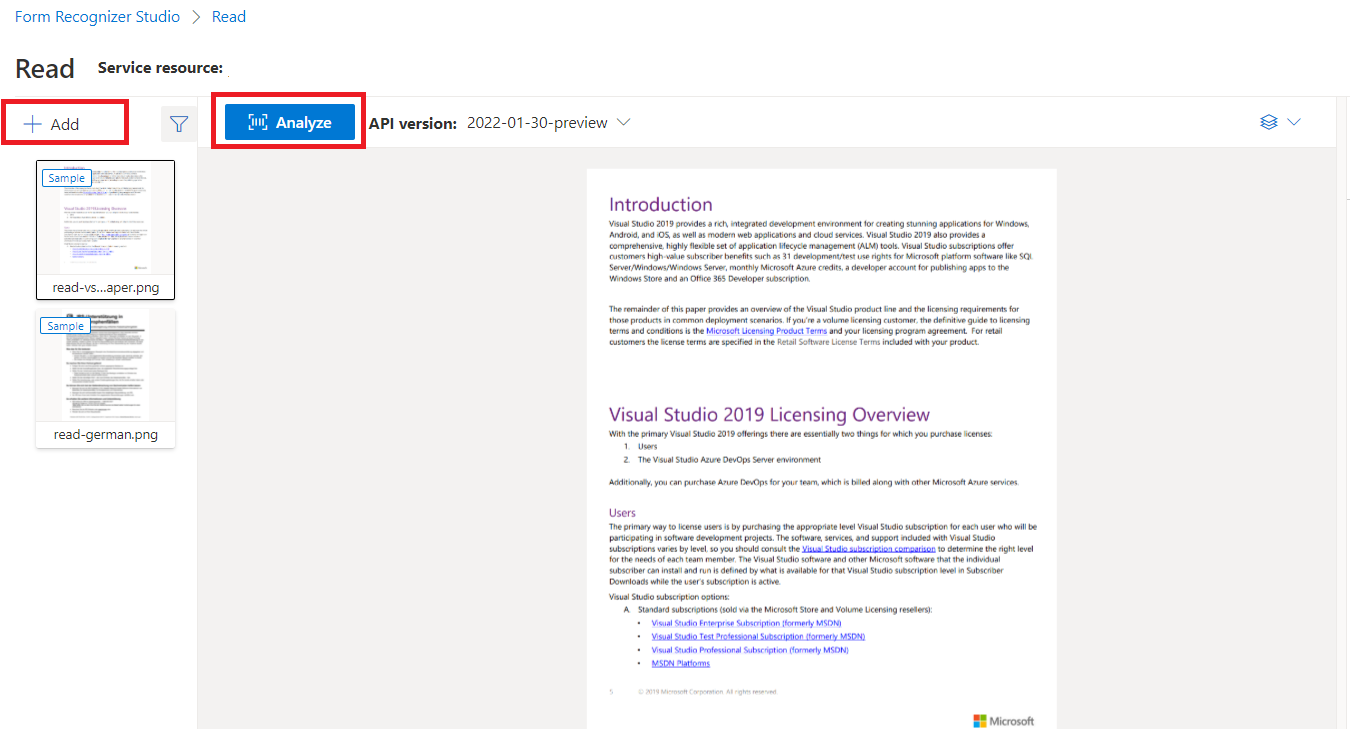
في الصفحة الرئيسية ل Document Intelligence Studio، حدد Read.
يمكنك تحليل نموذج المستند أو تحميل ملفاتك الخاصة.
حدد الزر Run analysis، وقم بتكوين خيارات Analyze، إذا لزم الأمر:

اللغات والإعدادات المحلية المدعومة
راجع صفحة نماذج تحليل اللغة للحصول على قائمة كاملة باللغات المدعومة.
استخراج البيانات
إشعار
يتم دعم ملف Microsoft Word وHTML في الإصدار 3.1 والإصدارات الأحدث. بالمقارنة مع PDF والصور، الميزات أدناه غير مدعومة:
- لا توجد زاوية وعرض/ارتفاع ووحدة مع كل كائن صفحة.
- لكل كائن تم اكتشافه، لا توجد مضلع إحاطة أو منطقة حدود.
- نطاق الصفحة (
pages) غير معتمد كمعلمة. - لا يوجد
linesكائن.
الصفحات
مجموعة الصفحات هي قائمة بالصفحات داخل المستند. يتم تمثيل كل صفحة بشكل تسلسلي داخل المستند وتتضمن زاوية الاتجاه التي تشير إلى ما إذا كان يتم تدوير الصفحة والعرض والارتفاع (الأبعاد بالبكسل). يتم حساب وحدات الصفحة في إخراج النموذج كما هو موضح:
| تنسيق الملف | وحدة الصفحة المحسوبة | إجمالي الصفحات |
|---|---|---|
| الصور (JPEG/JPG، PNG، BMP، HEIF) | كل صورة = وحدة صفحة واحدة | إجمالي الصور |
| كل صفحة في PDF = وحدة صفحة واحدة | إجمالي الصفحات في ملف PDF | |
| TIFF | كل صورة في وحدة صفحة TIFF = 1 | إجمالي الصور في TIFF |
| Word (DOCX) | ما يصل إلى 3000 حرف = وحدة صفحة واحدة أو صور مضمنة أو مرتبطة غير مدعومة | إجمالي الصفحات التي يصل عددها إلى 3000 حرف لكل منها |
| Excel (XLSX) | كل ورقة عمل = وحدة صفحة واحدة أو صور مضمنة أو مرتبطة غير معتمدة | إجمالي أوراق العمل |
| PowerPoint (PPTX) | كل شريحة = وحدة صفحة واحدة أو صور مضمنة أو مرتبطة غير معتمدة | إجمالي الشرائح |
| HTML | ما يصل إلى 3000 حرف = وحدة صفحة واحدة أو صور مضمنة أو مرتبطة غير مدعومة | إجمالي الصفحات التي يصل عددها إلى 3000 حرف لكل منها |
"pages": [
{
"pageNumber": 1,
"angle": 0,
"width": 915,
"height": 1190,
"unit": "pixel",
"words": [],
"lines": [],
"spans": []
}
]
تحديد صفحات لاستخراج النص
بالنسبة إلى المستندات الكبيرة متعددة الصفحات، استخدم معلمة الاستعلام pages من أجل الإشارة إلى أرقام صفحات أو نطاقات صفحات معينة لاستخراج النص.
الفقرات
يستخرج نموذج قراءة التعرف البصري على الحروف (OCR) في Document Intelligence كافة كتل النص المحددة في paragraphs المجموعة ككائن المستوى الأعلى ضمن analyzeResults. يمثل كل إدخال في هذه المجموعة كتلة نص ويتضمن النص المستخرج كإحداثياتcontent الإحاطة polygon . span تشير المعلومات إلى جزء النص ضمن خاصية المستوى content الأعلى التي تحتوي على النص الكامل من المستند.
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"content": "While healthcare is still in the early stages of its Al journey, we are seeing pharmaceutical and other life sciences organizations making major investments in Al and related technologies.\" TOM LAWRY | National Director for Al, Health and Life Sciences | Microsoft"
}
]
النص والخطوط والكلمات
يستخرج نموذج قراءة التعرف البصري على الحروف (OCR) نص النمط المطبوع والمكتوب بخط اليد ك lines و words. يقوم النموذج بإخراج إحداثيات الإحاطةpolygonوconfidenceللكلمات المستخرجة. تشمل المجموعة styles أي نمط مكتوب بخط اليد للخطوط، إذا تم اكتشافه، إلى جانب الامتدادات التي تشير إلى النص المقترن. تنطبق هذه الميزة علىلغات الكمبيوتر المعتمدة المكتوبة بخط اليد.
بالنسبة إلى Microsoft Word وExcel وPowerPoint وHTML، يقوم نموذج Document Intelligence Read الإصدار 3.1 والإصدارات الأحدث باستخراج كل النص المضمن كما هو. يتم إضافة النصوص ككلمات وفقرات. الصور المضمنة غير مدعومة.
"words": [
{
"content": "While",
"polygon": [],
"confidence": 0.997,
"span": {}
},
],
"lines": [
{
"content": "While healthcare is still in the early stages of its Al journey, we",
"polygon": [],
"spans": [],
}
]
نمط مكتوب بخط اليد لخطوط النص
تتضمن الاستجابة تصنيف ما إذا كان كل سطر نصي من نمط خط اليد أم لا، إلى جانب درجة الثقة. لمزيد من المعلومات، راجعدعم اللغة المكتوبة بخط اليد. يوضح المثال التالي مثالا لمقتطف JSON.
"styles": [
{
"confidence": 0.95,
"spans": [
{
"offset": 509,
"length": 24
}
"isHandwritten": true
]
}
إذا قمت بتمكين إمكانية إضافة الخط/النمط، فستحصل أيضا على نتيجة الخط/النمط كجزء من styles العنصر.
الخطوات التالية
إكمال التشغيل السريع ل Document Intelligence:
استكشف REST API: