إشعار
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
Azure Synapse Analytics
Azure Data Factory
المشكلة الشائعة التي تواجهها المؤسسات هي كيفية جمع البيانات من مصادر متعددة، بتنسيقات متنوعة. ثم ستحتاج إلى نقله إلى مخزن بيانات واحد أو أكثر. قد لا تكون الوجهة هي نفس نوع مخزن البيانات مثل المصدر. غالباً ما يكون التنسيق مختلفاً، أو يجب تشكيل البيانات أو تنظيفها قبل تحميلها في وجهتها النهائية.
وقد تم تطوير العديد من الأدوات والخدمات والعمليات على مر السنين للمساعدة في مواجهة هذه التحديات. بغض النظر عن العملية المستخدمة، هناك حاجة شائعة لتنسيق العمل وتطبيق مستوى ما من تحويل البيانات داخل مسار البيانات. تسلط الأقسام التالية الضوء على الأساليب الشائعة المستخدمة لتنفيذ هذه المهام.
عملية الاستخراج والتحويل والتحميل (ETL)
الاستخراج والتحويل والتحميل (ETL) هو مسار بيانات يستخدم لجمع البيانات من مصادر مختلفة. ثم يقوم بتحويل البيانات وفقاً لقواعد العمل، ويحمل البيانات إلى مخزن بيانات الوجهة. يتم عمل التحويل في ETL في محرك متخصص، وغالباً ما يتضمن استخدام جداول التقسيم المرحلي للاحتفاظ بالبيانات مؤقتاً أثناء تحويلها وتحميلها في نهاية المطاف إلى وجهتها.
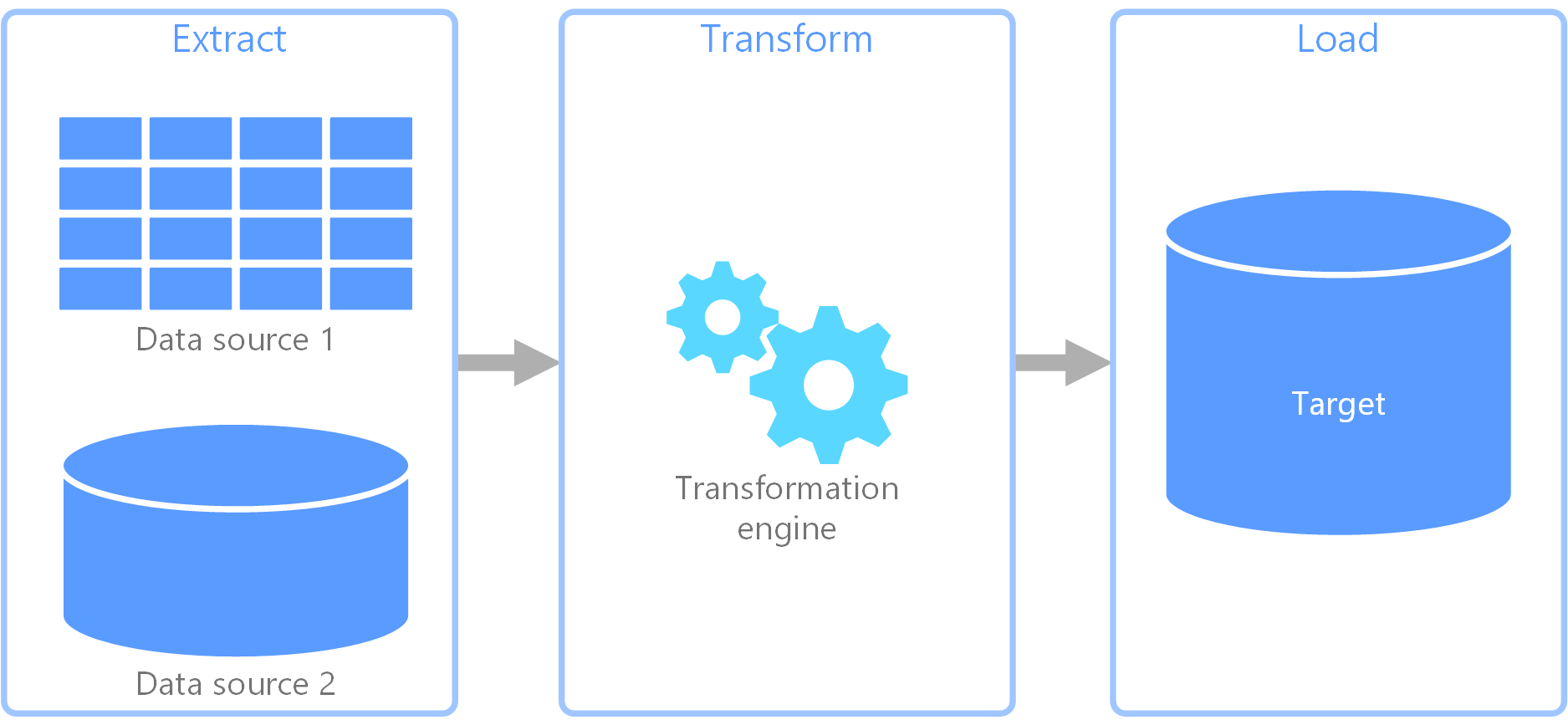
يتضمن تحويل البيانات الذي يحدث عادة عمليات مختلفة، مثل التصفية والفرز والتجميع والانضمام إلى البيانات وتنظيف البيانات وإلغاء تكرار البيانات والتحقق من صحتها.
غالباً ما يتم تشغيل مراحل ETL الثلاث بالتوازي لتوفير الوقت. على سبيل المثال، أثناء استخراج البيانات، يمكن أن تعمل عملية التحويل على البيانات التي تم تلقيها بالفعل وإعدادها للتحميل، ويمكن أن تبدأ عملية التحميل في العمل على البيانات المعدة، بدلاً من انتظار اكتمال عملية الاستخراج بأكملها.
خدمة Azure ذات الصلة:
أدوات أخرى:
استخراج وتحميل وتحويل (ELT)
يختلف الاستخراج والتحميل والتحويل (ELT) عن ETL فقط في مكان حدوث التحويل. في مسار ELT، يحدث التحويل في مخزن البيانات الهدف. بدلاً من استخدام محرك تحويل منفصل، تُستخدم إمكانيات المعالجة لمخزن البيانات الهدف لتحويل البيانات. هذا يبسط البنية عن طريق إزالة محرك التحويل من المسار. فائدة أخرى لهذا النهج هي أن تحجيم مخزن البيانات الهدف يوسع أيضاً من أداء خط أنابيب ELT. ومع ذلك، يعمل ELT بشكل جيد فقط عندما يكون النظام الهدف قوياً بما يكفي لتحويل البيانات بكفاءة.
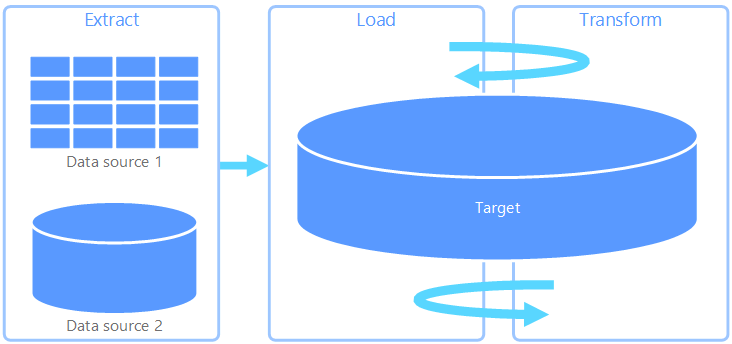
تقع حالات الاستخدام النموذجية ل ELT ضمن نطاق البيانات الضخمة. على سبيل المثال، قد تبدأ باستخراج كافة البيانات المصدر إلى ملفات مسطحة في تخزين قابل للتطوير، مثل نظام الملفات الموزعة Hadoop أو مخزن Azure blob أو Azure Data Lake gen 2 (أو مجموعة). يمكن بعد ذلك استخدام التقنيات، مثل Spark أو Hive أو PolyBase، للاستعلام عن البيانات المصدر. النقطة الرئيسية مع ELT هي أن مخزن البيانات المستخدم لإجراء التحويل هو نفس مخزن البيانات حيث يتم استهلاك البيانات في نهاية المطاف. يقرأ مخزن البيانات هذا مباشرة من التخزين القابل للتطوير، بدلاً من تحميل البيانات في التخزين الخاص به. يتخطى هذا الأسلوب خطوة نسخ البيانات الموجودة في ETL، والتي غالباً ما تكون عملية تستغرق وقتاً طويلاً لمجموعات البيانات الكبيرة.
في الممارسة العملية، مخزن البيانات الهدف هو مستودع بيانات باستخدام إما مجموعة Hadoop (باستخدام Apache Hive أو Spark) أو تجمعات مخصصة SQL على Azure Synapse Analytics. بشكل عام، يتم تراكب المخطط على بيانات الملف الثابت في وقت الاستعلام ويتم تخزينه كجدول، مما يتيح الاستعلام عن البيانات مثل أي جدول آخر في مخزن البيانات. يشار إليها بالجداول الخارجية لأن البيانات لا توجد في التخزين الذي يديره مخزن البيانات نفسه، ولكن على بعض التخزين الخارجي القابل للتطوير مثل مخزن Azure Data Lake أو تخزين Azure blob.
يدير مخزن البيانات مخطط البيانات فقط ويطبق المخطط عند القراءة. على سبيل المثال، قد تصف مجموعة Hadoop التي تستخدم Apache Hive جدول Hive حيث يكون مصدر البيانات هو مسار فعال لمجموعة من الملفات في HDFS. في Azure Synapse، يمكن ل PolyBase تحقيق نفس النتيجة - إنشاء جدول مقابل البيانات المخزنة خارجياً في قاعدة البيانات نفسها. بمجرد تحميل البيانات المصدر، يمكن معالجة البيانات الموجودة في الجداول الخارجية باستخدام قدرات مخزن البيانات. في سيناريوهات البيانات الضخمة، يعني هذا أن مخزن البيانات يجب أن يكون قادراً على المعالجة المتوازية على نطاق واسع (MPP)، والتي تقسم البيانات إلى أجزاء أصغر وتوزع معالجة الأجزاء عبر عقد متعددة على التوازي.
عادةً ما تكون المرحلة الأخيرة من مسار ELT هي تحويل بيانات المصدر إلى تنسيق نهائي أكثر كفاءة لأنواع الاستعلامات التي تحتاج إلى دعم. على سبيل المثال، قد يتم تقسيم البيانات. أيضاً، قد تستخدم ELT تنسيقات التخزين المحسنة مثل Parquet، والتي تخزن البيانات الموجهة للصفوف بطريقة عمودية وتوفر فهرسة محسنة.
خدمة Azure ذات الصلة:
- تجمعات SQL المخصصة في Azure Synapse Analytics
- تجمعات SQL بلا خادم في Azure Synapse Analytics
- HDInsight مع Apache Hive
- Azure Data Factory
- Datamarts في Power BI
أدوات أخرى:
تدفق البيانات وتدفق التحكم
في سياق مسارات البيانات، يضمن تدفق التحكم المعالجة النظامية لمجموعة من المهام. لفرض ترتيب المعالجة الصحيح لهذه المهام، يتم استخدام قيود الأسبقية. يمكنك التفكير في هذه القيود كموصلات في رسم تخطيطي لسير العمل، كما هو موضح في الصورة أدناه. كل مهمة لها نتيجة، مثل النجاح أو الفشل أو الإكمال. ولا تبدأ أي مهمة لاحقة في المعالجة حتى تكتمل المهمة السابقة لها بإحدى هذه النتائج.
تنفذ تدفقات التحكم تدفقات البيانات كمهمة. في مهمة تدفق البيانات، يتم استخراج البيانات من مصدر أو تحويلها أو تحميلها في مخزن بيانات. يمكن أن يكون إخراج مهمة تدفق بيانات واحدة هو الإدخال إلى مهمة تدفق البيانات التالية، ويمكن تشغيل تدفقات البيانات بالتوازي. على عكس تدفقات التحكم، لا يمكنك إضافة قيود بين المهام في تدفق البيانات. ومع ذلك، يمكنك إضافة عارض بيانات لمراقبة البيانات أثناء معالجتها بواسطة كل مهمة.
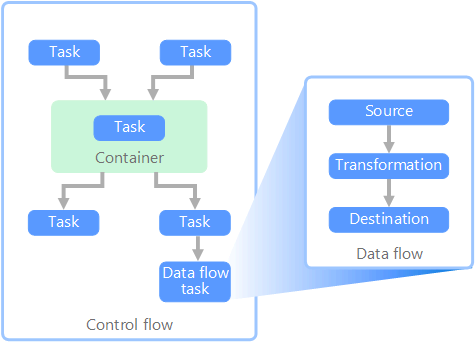
في الرسم التخطيطي أعلاه، هناك العديد من المهام داخل تدفق عنصر التحكم، واحدة منها مهمة تدفق البيانات. إحدى المهام متداخلة داخل حاوية. يمكن استخدام الحاويات لتوفير بنية للمهام، ما يوفر وحدة عمل. أحد الأمثلة على ذلك هو تكرار العناصر داخل مجموعة، مثل الملفات الموجودة في مجلد أو عبارات قاعدة بيانات.
خدمة Azure ذات الصلة:
أدوات أخرى:
خيارات التكنولوجيا
- مخازن بيانات معالجة المعاملات عبر الإنترنت (OLTP)
- مخازن بيانات المعالجة التحليلية عبر الإنترنت (OLAP)
- مستودعات البيانات
- تنسيق المسار
الخطوات التالية
- دمج البيانات مع Azure Data Factory أو Azure Synapse Pipeline
- مقدمة إلى Azure Synapse Analytics
- تنسيق حركة البيانات وتحويلها في Azure Data Factory أو Azure Synapse Pipeline
الموارد ذات الصلة
تظهر البنيات المرجعية التالية مسارات ELT الشاملة على Azure: