إشعار
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
Azure
تمكين أحد التطبيقات من معالجة حالات التعطل العابرة عندما يحاول الاتصال بخدمة أو مورد شبكة، عن طريق إعادة محاولة عملية فاشلة بشفافية. يمكن أن يحسن هذا من عملية استقرار التطبيق.
السياق والمشكلة
يلزم أن يكون التطبيق الذي يتصل بالعناصر التي تعمل في السحابة حساسا للأخطاء العابرة التي يمكن أن تحدث في هذه البيئة. تتضمن الأخطاء الفقدان اللحظي لاتصالية الشبكة بالمكونات والخدمات، أو عدم توفر الخدمة مؤقتا، أو المهلات التي تحدث عندما تكون الخدمة مشغولة.
عادة ما تكون هذه الأخطاء ذاتية التصحيح، وفي حالة تم تكرار الإجراء الذي تسبب في حدوث خطأ بعد تأخير مناسب، فمن المحتمل أن يكون ناجحا. على سبيل المثال، يمكن لخدمة قاعدة البيانات التي تعالج عددا كبيرا من الطلبات المتزامنة تنفيذ استراتيجية تقييد ترفض مؤقتا أي طلبات أخرى حتى يتم تخفيف حمل العمل الخاص بها. ربما يتعطل التطبيق الذي يحاول الوصول إلى قاعدة البيانات في الاتصال، ولكن في حالة حاول مرة أخرى بعد تأخير، فقد ينجح.
حل
في السحابة، يجب توقع أخطاء عابرة ويجب تصميم تطبيق للتعامل معها بشكل أنيق وشفاف. يؤدي القيام بذلك إلى تقليل التأثيرات التي يمكن أن يكون لها أخطاء على مهام العمل التي يقوم بها التطبيق. نمط التصميم الأكثر شيوعا لمعالجته هو تقديم آلية إعادة المحاولة.
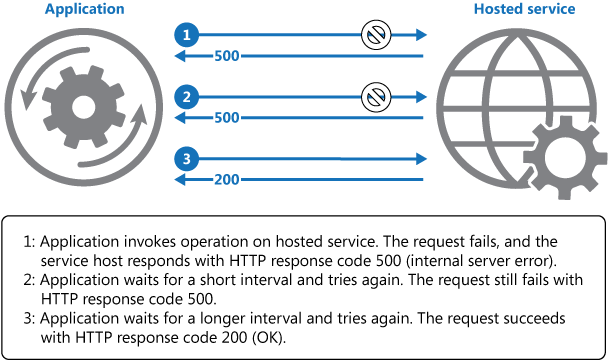
يوضح الرسم التخطيطي أعلاه استدعاء عملية في خدمة مستضافة باستخدام آلية إعادة المحاولة. في حالة لم ينجح الطلب بعد عدد محدد مسبقا من المحاولات، يجب على التطبيق التعامل مع الخطأ كاستثناء والتعامل معه وفقا لذلك.
إشعار
نظرا للطبيعة الشائعة للأخطاء العابرة، تتوفر الآن آليات إعادة المحاولة المضمنة في العديد من مكتبات العملاء والخدمات السحابية، مع درجة ما من قابلية التكوين لعدد مرات إعادة المحاولة القصوى والتأخير بين عمليات إعادة المحاولة والمعلمات الأخرى. يمكن العثور على دعم إعادة المحاولة المضمن للعديد من خدمات Azure هنا ويوفر Microsof Entity Framework تسهيلات لإعادة محاولة عمليات قاعدة البيانات الفاشلة.
إستراتيجيات إعادة المحاولة
في حالة اكتشف أحد التطبيقات عطلًا عندما يحاول إرسال طلب إلى خدمة بعيدة، فيمكنه معالجة العطل باستخدام الاستراتيجيات التالية:
إلغاء الأمر. في حالة كان الخطأ يشير إلى أن العطل ليس عابرا أو من غير المحتمل أن يكون ناجحا في حالة تم تكراره، فيجب على التطبيق إلغاء العملية والإبلاغ عن استثناء.
أعد المحاولة على الفور. إذا كان الخطأ المحدد الذي تم الإبلاغ عنه غير عادي أو نادر، مثل تلف حزمة الشبكة أثناء إرسالها، فقد يكون أفضل مسار للعمل هو إعادة محاولة الطلب على الفور.
إعادة المحاولة بعد التأخير. إذا كان الخطأ ناتجا عن أحد حالات فشل الاتصال أو الشغل الأكثر شيوعا، فقد تحتاج الشبكة أو الخدمة إلى فترة قصيرة أثناء تصحيح مشكلات الاتصال أو مسح تراكم العمل، لذلك يعد تأخير إعادة المحاولة برمجيا استراتيجية جيدة. في كثير من الحالات، يجب اختيار الفترة بين عمليات إعادة المحاولة لنشر الطلبات من مثيلات متعددة من التطبيق بالتساوي قدر الإمكان لتقليل فرصة استمرار التحميل الزائد لخدمة مشغولة.
في حالة استمرار تعطل الطلب، يمكن للتطبيق الانتظار وإجراء محاولة أخرى. في حالة لزم الأمر، يمكن تكرار هذه العملية مع زيادة التأخير بين محاولات إعادة المحاولة، حتى يجرب الحد الأقصى من الطلبات. يمكن زيادة التأخير بصفة تزايدية أو أسية، اعتمادا على نوع العطل واحتمال تصحيحه خلال هذا الوقت.
يجب أن يلتف التطبيق على جميع المحاولات للوصول إلى خدمة بعيدة في التعليمات البرمجية التي تنفذ سياسة إعادة المحاولة الذي يطابق إحدى الاستراتيجيات المذكورة أعلاه. يمكن أن تخضع الطلبات المرسلة إلى الخدمات المختلفة للسياسات المختلفة.
يجب أن يسجل التطبيق التفاصيل الخاصة بالأخطاء والعمليات المعطلة. تعد هذه المعلومات مفيدة للمشغلين. ولكن من أجل تجنب مشغلي الفيضانات مع تنبيهات بشأن العمليات التي نجحت فيها المحاولات التي تمت إعادة المحاولة فيما بعد، من الأفضل تسجيل حالات العطل المبكرة بصفتهاإدخالات إعلامية وعط آخر محاولات إعادة المحاولة باعتباره خطأ فعلي فقط. يرد هنامثال على الطريقة التي يبدو عليها نموذج التسجيل هذا.
في حالة كانت الخدمة غير متوفرة أو مشغولة بطريقة متكررة، فغالبا ما يكون ذلك بسبب استنفاد الخدمة لمواردها. يمكنك تقليل تكرار هذه الأخطاء عن طريق توسيع النطاق الخاص بالخدمة. على سبيل المثال، في حالة كانت خدمة قاعدة البيانات محملة بشكل زائد باستمرار، فقد يكون من المفيد تقسيم قاعدة البيانات ونشر الحمل عبر الخوادم المتعددة.
المسائل والاعتبارات
يجب مراعاة النقاط التالية عند تحديد طريقة تنفيذ هذا النمط.
التأثير على الأداء
يجب ضبط سياسة إعادة المحاولة لمطابقة متطلبات العمل للتطبيق وطبيعة العطل. بالنسبة لبعض العمليات غير الأساسية، من الأفضل أن تعطل بسرعة بدلا من إعادة المحاولة عدة مرات والتأثير على معدل النقل الخاص بالتطبيق. على سبيل المثال، في تطبيق الويب التفاعلي يصل إلى خدمة بعيدة، من الأفضل أن تعطل بعد عدد أقل من عمليات إعادة المحاولة مع تأخير قصير فقط بين محاولات إعادة المحاولة، وعرض رسالة مناسبة للمستخدم (على سبيل المثال، «يرجى المحاولة مرة أخرى لاحقا»). بالنسبة لتطبيق الدفعة، قد يكون من الأنسب زيادة عدد محاولات إعادة المحاولة مع التأخير المتزايد بشكل كبير بين المحاولات.
قد تؤدي سياسة إعادة المحاولة الصارمة مع الحد الأدنى من التأخير بين المحاولات وعدد كبير من عمليات إعادة المحاولة إلى تدهور الخدمة المشغولة التي تعمل بالقرب من السعة أو بكامل طاقتها. يمكن أن تؤثر سياسة إعادة المحاولة هذه أيضا على استجابة التطبيق في حالة كان يحاول باستمرار تنفيذ عملية معطلة.
في حالة كان الطلب لا يزال معطل بعد عدد كبير من عمليات إعادة المحاولة، فمن الأفضل للتطبيق منع المزيد من الطلبات من الانتقال إلى نفس المورد والإبلاغ ببساطة عن عطل على الفور. وعند انتهاء الفترة الزمنية، يمكن للتطبيق السماح مبدئيا بطلب واحد أو أكثر لمعرفة ما إذا كانت ناجحة أم لا. لمزيد من التفاصيل حول هذه الاستراتيجية، راجعنمط Circuit Breaker.
التكرار
ضع في اعتبارك احتمالية عدم فعالية العملية. في حالة كان الأمر كذلك، فمن الآمن بطبيعته إعادة المحاولة. وإلا، فقد تتسبب عمليات إعادة المحاولة في تنفيذ العملية أكثر من مرة واحدة، مع التأثيرات الجانبية غير المقصودة. على سبيل المثال، قد تتلقى الخدمة الطلب، وتعالج الطلب بنجاح، ولكنها تعطل في إرسال الاستجابة. عند هذه النقطة، قد يعيد المنطق الخاص بإعادة المحاولة إرسال الطلب، على افتراض أنه لم يتم تلقي الطلب الأول.
نوع الاستثناء
يمكن أن يعطل طلب خدمة لمجموعة متنوعة من الأسباب التي تثير الاستثناءات المختلفة اعتمادا على طبيعة العطل. تشير بعض الاستثناءات إلى العطل الذي يمكن حله بسرعة، بينما تشير الاستثناءات الأخرى إلى أن العطل أطول أمدا. من المفيد لسياسة إعادة المحاولة ضبط الوقت بين محاولات إعادة المحاولة استنادا إلى نوع الاستثناء.
تناسق المعاملة
ضع في اعتبارك كيفية تأثير إعادة محاولة العملية التي تشكل جزءا من معاملة على تناسق المعاملة الكلي. اضبط سياسة إعادة المحاولة لعمليات المعاملات لتحقيق أقصى قدر من فرصة النجاح وتقليل الحاجة إلى التراجع عن جميع خطوات المعاملة.
الإرشادات العامة
تأكد من اختبار كافة التعليمات البرمجية لإعادة المحاولة بالكامل مقابل مجموعة متنوعة من شروط العطل. تحقق من عدم تأثيره الكبير في أداء التطبيق أو موثوقيته، أو يتسبب في تحميل مفرط على الخدمات والموارد، أو إنشاء حالة تعارض أو ازدحام.
لا تنفّذ منطق إعادة المحاولة إلّا في حالة فهم السياق الكامل للعملية المعطلة. في حالة استدعاء مهمة تحتوي على سياسة إعادة المحاولة مهمة أخرى تحتوي أيضا على سياسة إعادة المحاولة على سبيل المثال، يمكن لهذه الطبقة الإضافية من عمليات إعادة المحاولة إضافة تأخيرات طويلة إلى المعالجة. يكون من الأفضل تكوين المهمة ذات المستوى الأدنى للفشل بسرعة والإبلاغ عن سبب الفشل مرة أخرى إلى المهمة التي استدعتها. يمكن لهذه المهمة ذات المستوى الأعلى بعد ذلك معالجة العطل اعتمادًا على نهجها الخاص.
سجل جميع حالات فشل الاتصال التي تتسبب في إعادة المحاولة بحيث يمكن تحديد المشاكل الأساسية في التطبيق أو الخدمات أو الموارد.
تحقق من الأخطاء التي من المرجح أن تحدث لخدمة أو مورد لاكتشاف ما إذا كان من المتوقع أن تكون طويلة الأمد أو محطة طرفية. في حالة كانت كذلك، فمن الأفضل التعامل مع الخطأ كاستثناء. يمكن للتطبيق الإبلاغ عن الاستثناء أو تسجيله، ثم محاولة المتابعة إما عن طريق استدعاء خدمة بديلة (في حالة كانت متوفرة)، أو عن طريق تقديم وظائف متدهورة. لمزيد من المعلومات حول كيفية الكشف عن الأخطاء طويلة الأمد ومعالجتها، راجعCircuit Breaker pattern.
موعد استخدام النمط
استخدم هذا النمط عندما يواجه التطبيق لأخطاء العابرة أثناء تفاعله مع الخدمة البعيدة أو الوصول إلى مورد بعيد. من المتوقع أن تكون هذه الأخطاء قصيرة الأجل، وربما ينجح تكرار طلب تعطل مسبقا في محاولة لاحقة.
وربما لا يكون هذا النمط مفيدا:
- عندما يكون الخطأ طويل الأمد على الأرجح، لأن هذا يمكن أن يؤثر على الاستجابة الخاصة بالتطبيق. ربما يضيع التطبيق الوقت والموارد التي تحاول تكرار طلب من المحتمل أن يتعطل.
- لمعالجة حالات التعطل التي لا ترجع إلى أخطاء عابرة، مثل الاستثناءات الداخلية الناتجة عن الأخطاء في منطق العمل للخاص بالتطبيق.
- بصفته بديل لمعالجة مشكلات قابلية التوسع في النظام. في حالة كان التطبيق يواجه أخطاء مشغولة متكررة، فغالبا ما تكون علامة على أنه يجب توسيع الخدمة أو المورد الذي يتم الوصول إليه.
تصميم حمل العمل
يجب على المهندس المعماري تقييم كيفية استخدام نمط إعادة المحاولة في تصميم حمل العمل الخاص بهم لمعالجة الأهداف والمبادئ التي تغطيها ركائز Azure Well-Architected Framework. على سبيل المثال:
| الركيزة | كيف يدعم هذا النمط أهداف الركيزة |
|---|---|
| تساعد قرارات تصميم الموثوقية حمل العمل الخاص بك على الصمود في وجه الخلل وضمان استرداده إلى حالة تعمل بشكل كامل بعد حدوث فشل. | يعد التخفيف من الأخطاء العابرة في النظام الموزع تقنية أساسية لتحسين مرونة حمل العمل. - RE:07 الحفاظ على الذات - RE:07 أخطاء عابرة |
كما هو الحال مع أي قرار تصميم، ضع في اعتبارك أي مفاضلات ضد أهداف الركائز الأخرى التي يمكن إدخالها مع هذا النمط.
مثال
راجع دليل تنفيذ نهج إعادة المحاولة باستخدام .NET للحصول على مثال مفصل باستخدام Azure SDK مع دعم آلية إعادة المحاولة المضمنة.
الخطوات التالية
قبل كتابة المنطق الخاص بإعادة المحاولة المخصص، ضع في اعتبارك استخدام إطار عمل عام مثل Polly لـ .NET أو Resilience4j لـ Java.
عند معالجة الأوامر التي تغير بيانات العمل، يجب أن تدرك أن عمليات إعادة المحاولة يمكن أن تؤدي إلى تنفيذ الإجراء مرتين، مما قد يكون مشكلة في حالة كان هذا الإجراء يشبه شحن بطاقة ائتمان العميل. يمكن أن يساعد استخدام نمط Idempotence الموضح في المنشور الخاص بالمدونة هذا في التعامل مع هذه الحالات.
الموارد ذات الصلة
يوضح لك نمط تطبيق الويب الموثوق به كيفية تطبيق نمط إعادة المحاولة على تطبيقات الويب المتقاربة على السحابة.
بالنسبة لمعظم خدمات Azure، تتضمن حزمة SDKs الخاصة بالعميل منطق إعادة المحاولة المضمنة. لمزيد من المعلومات، راجع إعادة محاولة التوجيه لخدمات Azure .
نمط Circuit Breaker. في حالة كان من المتوقع أن يكون العطل أطول أمدا، فقد يكون من الأنسب تنفيذ نمط قاطع الدائرة. يوفر الجمع بين نمطي Retry وأنماط Circuit Breaker نهجًا شاملا لمعالجة الأخطاء.