البرنامج التعليمي: إجراء بحث تشابه المتجهات على تضمينات Azure OpenAI باستخدام ذاكرة التخزين المؤقت Azure ل Redis
في هذا البرنامج التعليمي، ستتعرف على حالة استخدام بحث تشابه المتجهات الأساسية. ستستخدم التضمينات التي تم إنشاؤها بواسطة خدمة Azure OpenAI وقدرات البحث عن المتجهات المضمنة في طبقة المؤسسة من ذاكرة التخزين المؤقت Azure ل Redis للاستعلام عن مجموعة بيانات من الأفلام للعثور على التطابق الأكثر صلة.
يستخدم البرنامج التعليمي مجموعة بيانات Wikipedia Movie Plots التي تحتوي على أوصاف رسم لأكثر من 35000 فيلم من ويكيبيديا تغطي السنوات من 1901 إلى 2017. تتضمن مجموعة البيانات ملخص رسم لكل فيلم، بالإضافة إلى بيانات تعريف مثل السنة التي تم فيها إصدار الفيلم، والمخرج (المخرجين)، والمسرح الرئيسي، والنوع. ستتبع خطوات البرنامج التعليمي لإنشاء تضمينات استنادا إلى ملخص الرسم واستخدام بيانات التعريف الأخرى لتشغيل الاستعلامات المختلطة.
في هذا البرنامج التعليمي، تتعلم كيفية:
- إنشاء مثيل Azure Cache for Redis تم تكوينه للبحث في المتجهات
- تثبيت Azure OpenAI ومكتبات Python المطلوبة الأخرى.
- قم بتنزيل مجموعة بيانات الفيلم وإعدادها للتحليل.
- استخدم نموذج text-embedding-ada-002 (الإصدار 2) لإنشاء تضمينات.
- إنشاء فهرس متجه في ذاكرة التخزين المؤقت Azure ل Redis
- استخدم تشابه التمام لترتيب نتائج البحث.
- استخدم وظيفة الاستعلام المختلط من خلال RediSearch لتصفية البيانات مسبقا وجعل البحث المتجه أكثر قوة.
هام
سيرشدك هذا البرنامج التعليمي خلال إنشاء Jupyter Notebook. يمكنك متابعة هذا البرنامج التعليمي باستخدام ملف تعليمة Python البرمجية (.py) والحصول على نتائج مماثلة ، ولكن ستحتاج إلى إضافة جميع كتل التعليمات البرمجية في هذا البرنامج التعليمي إلى .py الملف وتنفيذها مرة واحدة لمشاهدة النتائج. بمعنى آخر، توفر Jupyter Notebooks نتائج وسيطة أثناء تنفيذ الخلايا، ولكن هذا ليس السلوك الذي يجب أن تتوقعه عند العمل في ملف التعليمات البرمجية ل Python.
هام
إذا كنت ترغب في المتابعة في دفتر ملاحظات Jupyter مكتمل بدلا من ذلك، فنزل ملف دفتر ملاحظات Jupyter المسمى tutorial.ipynb واحفظه في مجلد redis-vector الجديد.
المتطلبات الأساسية
- اشتراك Azure - إنشاء اشتراك مجاناً
- الوصول الممنوح إلى Azure OpenAI في اشتراك Azure المطلوب حاليا، يجب عليك التقدم بطلب للوصول إلى Azure OpenAI. يمكنك التقدم بطلب للوصول إلى Azure OpenAI عن طريق إكمال النموذج في https://aka.ms/oai/access.
- Python 3.7.1 أو إصدار أحدث
- Jupyter Notebooks (اختياري)
- مورد Azure OpenAI مع نشر نموذج text-embedding-ada-002 (الإصدار 2 ). يتوفر هذا النموذج حاليا فقط في مناطق معينة. راجع دليل توزيع الموارد للحصول على إرشادات حول كيفية نشر النموذج.
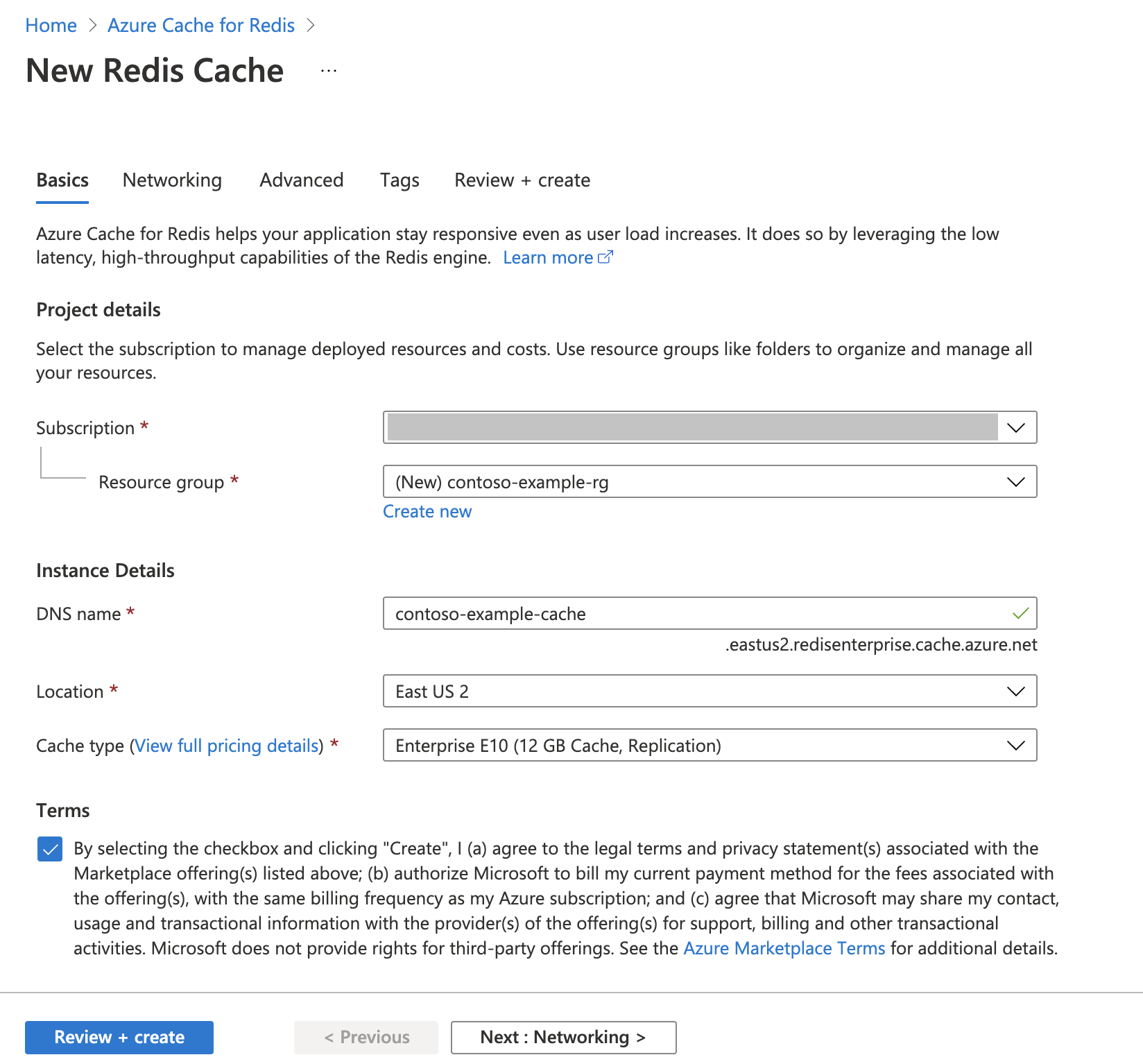
إنشاء Azure Cache لمثيل Redis
اتبع دليل التشغيل السريع: إنشاء ذاكرة التخزين المؤقت ل Redis Enterprise. في الصفحة خيارات متقدمة ، تأكد من إضافة الوحدة النمطية RediSearch واختيار نهج مجموعة المؤسسات . يمكن أن تتطابق جميع الإعدادات الأخرى مع الإعداد الافتراضي الموضح في التشغيل السريع.
يستغرق إنشاء ذاكرة التخزين المؤقت بضع دقائق. يمكنك الانتقال إلى الخطوة التالية في هذه الأثناء.
إعداد بيئة التطوير
أنشئ مجلدا على الكمبيوتر المحلي يسمى redis-vector في الموقع الذي تحفظ فيه مشاريعك عادة.
إنشاء ملف python جديد (tutorial.py) أو دفتر ملاحظات Jupyter (tutorial.ipynb) في المجلد.
تثبيت حزم Python المطلوبة:
pip install "openai==1.6.1" num2words matplotlib plotly scipy scikit-learn pandas tiktoken redis langchain
تنزيل مجموعة البيانات
في مستعرض الويب، انتقل إلى https://www.kaggle.com/datasets/jrobischon/wikipedia-movie-plots.
تسجيل الدخول أو التسجيل باستخدام Kaggle. التسجيل مطلوب لتنزيل الملف.
حدد الارتباط Download على Kaggle لتنزيل ملف archive.zip.
استخرج ملف archive.zip وانقل wiki_movie_plots_deduped.csv إلى المجلد redis-vector.
استيراد المكتبات وإعداد معلومات الاتصال
لإجراء مكالمة بنجاح مقابل Azure OpenAI، تحتاج إلى نقطة نهاية ومفتاح. تحتاج أيضا إلى نقطة نهاية ومفتاح للاتصال بذاكرة التخزين المؤقت Azure ل Redis.
انتقل إلى مورد Azure OpenAI في مدخل Microsoft Azure.
حدد موقع نقطة النهاية والمفاتيح في قسم إدارة الموارد. انسخ نقطة النهاية ومفتاح الوصول حيث ستحتاج إلى كليهما لمصادقة استدعاءات واجهة برمجة التطبيقات. مثال على نقطة النهاية هو:
https://docs-test-001.openai.azure.com. يمكنك استخدام إماKEY1أوKEY2.انتقل إلى صفحة نظرة عامة على Azure Cache لمورد Redis في مدخل Microsoft Azure. انسخ نقطة النهاية.
حدد موقع مفاتيح Access في قسم الإعدادات . انسخ مفتاح الوصول الخاص بك. يمكنك استخدام إما
PrimaryأوSecondary.أضف التعليمات البرمجية التالية إلى خلية تعليمات برمجية جديدة:
# Code cell 2 import re from num2words import num2words import os import pandas as pd import tiktoken from typing import List from langchain.embeddings import AzureOpenAIEmbeddings from langchain.vectorstores.redis import Redis as RedisVectorStore from langchain.document_loaders import DataFrameLoader API_KEY = "<your-azure-openai-key>" RESOURCE_ENDPOINT = "<your-azure-openai-endpoint>" DEPLOYMENT_NAME = "<name-of-your-model-deployment>" MODEL_NAME = "text-embedding-ada-002" REDIS_ENDPOINT = "<your-azure-redis-endpoint>" REDIS_PASSWORD = "<your-azure-redis-password>"قم بتحديث قيمة
API_KEYوRESOURCE_ENDPOINTبقيم المفتاح ونقطة النهاية من توزيع Azure OpenAI.DEPLOYMENT_NAMEيجب تعيين إلى اسم النشر الخاص بك باستخدامtext-embedding-ada-002 (Version 2)نموذج التضمينات،MODEL_NAMEويجب أن يكون نموذج التضمينات المحدد المستخدم.قم بتحديث
REDIS_ENDPOINTوREDIS_PASSWORDبنقطة النهاية وقيمة المفتاح من Azure Cache لمثيل Redis.هام
نوصي بشدة باستخدام المتغيرات البيئية أو مدير سري مثل Azure Key Vault لتمرير مفتاح API ونقطة النهاية ومعلومات اسم النشر. يتم تعيين هذه المتغيرات في نص عادي هنا من أجل البساطة.
تنفيذ خلية التعليمات البرمجية 2.
استيراد مجموعة البيانات إلى pandas ومعالجة البيانات
بعد ذلك، ستقرأ ملف csv في pandas DataFrame.
أضف التعليمات البرمجية التالية إلى خلية تعليمات برمجية جديدة:
# Code cell 3 df=pd.read_csv(os.path.join(os.getcwd(),'wiki_movie_plots_deduped.csv')) dfتنفيذ خلية التعليمات البرمجية 3. ينبغي أن تشاهد المخرج التالي:

بعد ذلك، قم بمعالجة البيانات عن طريق إضافة فهرس، وإزالة المسافات من عناوين الأعمدة، وتصفية الأفلام لالتقاط الأفلام التي تم إنشاؤها
idفقط بعد عام 1970 ومن البلدان الناطقة باللغة الإنجليزية. تقلل خطوة التصفية هذه من عدد الأفلام في مجموعة البيانات، ما يقلل من التكلفة والوقت اللازمين لإنشاء عمليات التضمين. يمكنك تغيير معلمات عامل التصفية أو إزالتها استنادا إلى تفضيلاتك.لتصفية البيانات، أضف التعليمات البرمجية التالية إلى خلية تعليمات برمجية جديدة:
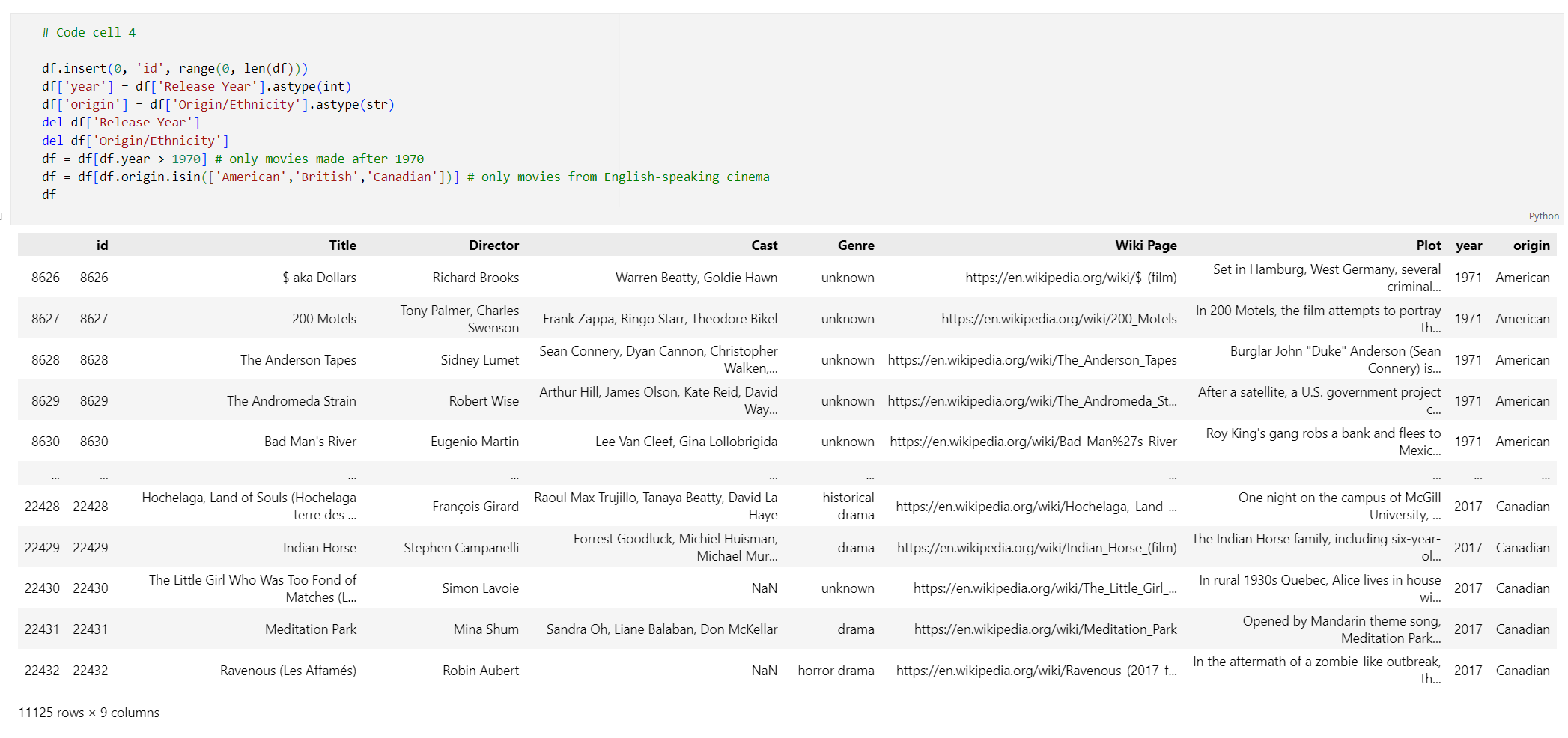
# Code cell 4 df.insert(0, 'id', range(0, len(df))) df['year'] = df['Release Year'].astype(int) df['origin'] = df['Origin/Ethnicity'].astype(str) del df['Release Year'] del df['Origin/Ethnicity'] df = df[df.year > 1970] # only movies made after 1970 df = df[df.origin.isin(['American','British','Canadian'])] # only movies from English-speaking cinema dfتنفيذ خلية التعليمات البرمجية 4. يجب أن تشاهد النتائج التالية:
إنشاء دالة لتنظيف البيانات عن طريق إزالة المسافة البيضاء وعلامات الترقيم، ثم استخدامها مقابل إطار البيانات الذي يحتوي على الرسم.
أضف التعليمات البرمجية التالية إلى خلية تعليمات برمجية جديدة وقم بتنفيذها:
# Code cell 5 pd.options.mode.chained_assignment = None # s is input text def normalize_text(s, sep_token = " \n "): s = re.sub(r'\s+', ' ', s).strip() s = re.sub(r". ,","",s) # remove all instances of multiple spaces s = s.replace("..",".") s = s.replace(". .",".") s = s.replace("\n", "") s = s.strip() return s df['Plot']= df['Plot'].apply(lambda x : normalize_text(x))وأخيرا، قم بإزالة أي إدخالات تحتوي على أوصاف رسم طويلة جدا لنموذج التضمينات. (بمعنى آخر، تتطلب رموزا مميزة أكثر من حد الرمز المميز 8192.) ثم حساب أرقام الرموز المميزة المطلوبة لإنشاء عمليات التضمين. يؤثر هذا أيضا على تسعير إنشاء التضمين.
أضف التعليمات البرمجية التالية إلى خلية تعليمات برمجية جديدة:
# Code cell 6 tokenizer = tiktoken.get_encoding("cl100k_base") df['n_tokens'] = df["Plot"].apply(lambda x: len(tokenizer.encode(x))) df = df[df.n_tokens<8192] print('Number of movies: ' + str(len(df))) print('Number of tokens required:' + str(df['n_tokens'].sum()))تنفيذ خلية التعليمات البرمجية 6. ينبغي لك أن تشاهد هذا الإخراج:
Number of movies: 11125 Number of tokens required:7044844هام
راجع تسعير خدمة Azure OpenAI لتحديد تكلفة إنشاء عمليات التضمين استنادا إلى عدد الرموز المميزة المطلوبة.


تحميل DataFrame إلى LangChain
تحميل DataFrame في LangChain باستخدام DataFrameLoader الفئة . بمجرد أن تكون البيانات في مستندات LangChain، من الأسهل بكثير استخدام مكتبات LangChain لإنشاء عمليات تضمين وإجراء عمليات بحث عن التشابه. قم بتعيين رسم ك page_content_column بحيث يتم إنشاء عمليات التضمين في هذا العمود.
أضف التعليمات البرمجية التالية إلى خلية تعليمات برمجية جديدة وقم بتنفيذها:
# Code cell 7 loader = DataFrameLoader(df, page_content_column="Plot" ) movie_list = loader.load()
إنشاء التضمينات وتحميلها في Redis
الآن بعد أن تمت تصفية البيانات وتحميلها في LangChain، ستقوم بإنشاء تضمينات حتى تتمكن من الاستعلام عن الرسم لكل فيلم. تقوم التعليمات البرمجية التالية بتكوين Azure OpenAI، وإنشاء عمليات التضمين، وتحميل متجهات التضمين في ذاكرة التخزين المؤقت Azure ل Redis.
أضف التعليمات البرمجية التالية خلية تعليمات برمجية جديدة:
# Code cell 8 embedding = AzureOpenAIEmbeddings( deployment=DEPLOYMENT_NAME, model=MODEL_NAME, azure_endpoint=RESOURCE_ENDPOINT, openai_api_type="azure", openai_api_key=API_KEY, openai_api_version="2023-05-15", show_progress_bar=True, chunk_size=16 # current limit with Azure OpenAI service. This will likely increase in the future. ) # name of the Redis search index to create index_name = "movieindex" # create a connection string for the Redis Vector Store. Uses Redis-py format: https://redis-py.readthedocs.io/en/stable/connections.html#redis.Redis.from_url # This example assumes TLS is enabled. If not, use "redis://" instead of "rediss:// redis_url = "rediss://:" + REDIS_PASSWORD + "@"+ REDIS_ENDPOINT # create and load redis with documents vectorstore = RedisVectorStore.from_documents( documents=movie_list, embedding=embedding, index_name=index_name, redis_url=redis_url ) # save index schema so you can reload in the future without re-generating embeddings vectorstore.write_schema("redis_schema.yaml")تنفيذ خلية التعليمات البرمجية 8. قد يستغرق هذا أكثر من 30 دقيقة حتى يكتمل.
redis_schema.yamlيتم إنشاء ملف أيضا. هذا الملف مفيد إذا كنت تريد الاتصال بفهرسك في Azure Cache لمثيل Redis دون إعادة إنشاء عمليات التضمين.
هام
تعتمد السرعة التي يتم بها إنشاء عمليات التضمين على الحصة النسبية المتاحة لنموذج Azure OpenAI. مع حصة تبلغ 240 ألف رمز مميز في الدقيقة، سيستغرق الأمر حوالي 30 دقيقة لمعالجة الرموز المميزة 7M في مجموعة البيانات.
تشغيل استعلامات البحث عن المتجهات
الآن بعد إعداد مجموعة البيانات وواجهة برمجة تطبيقات خدمة Azure OpenAI ومثيل Redis، يمكنك البحث باستخدام المتجهات. في هذا المثال، يتم إرجاع أفضل 10 نتائج لاستعلام معين.
أضف التعليمات البرمجية التالية إلى ملف التعليمات البرمجية ل Python:
# Code cell 9 query = "Spaceships, aliens, and heroes saving America" results = vectorstore.similarity_search_with_score(query, k=10) for i, j in enumerate(results): movie_title = str(results[i][0].metadata['Title']) similarity_score = str(round((1 - results[i][1]),4)) print(movie_title + ' (Score: ' + similarity_score + ')')تنفيذ خلية التعليمات البرمجية 9. ينبغي أن تشاهد المخرج التالي:
Independence Day (Score: 0.8348) The Flying Machine (Score: 0.8332) Remote Control (Score: 0.8301) Bravestarr: The Legend (Score: 0.83) Xenogenesis (Score: 0.8291) Invaders from Mars (Score: 0.8291) Apocalypse Earth (Score: 0.8287) Invasion from Inner Earth (Score: 0.8287) Thru the Moebius Strip (Score: 0.8283) Solar Crisis (Score: 0.828)يتم إرجاع درجة التشابه جنبا إلى جنب مع الترتيب الترتيبي للأفلام حسب التشابه. لاحظ أن الاستعلامات الأكثر تحديدا لها درجات تشابه تقل بشكل أسرع في القائمة.
عمليات البحث المختلطة
نظرا لأن RediSearch يتميز أيضا بوظائف بحث غنية أعلى البحث عن المتجهات، فمن الممكن تصفية النتائج حسب بيانات التعريف في مجموعة البيانات، مثل نوع الفيلم أو المدلى به أو سنة الإصدار أو المخرج. في هذه الحالة، قم بالتصفية استنادا إلى النوع
comedy.أضف التعليمات البرمجية التالية إلى خلية تعليمات برمجية جديدة:
# Code cell 10 from langchain.vectorstores.redis import RedisText query = "Spaceships, aliens, and heroes saving America" genre_filter = RedisText("Genre") == "comedy" results = vectorstore.similarity_search_with_score(query, filter=genre_filter, k=10) for i, j in enumerate(results): movie_title = str(results[i][0].metadata['Title']) similarity_score = str(round((1 - results[i][1]),4)) print(movie_title + ' (Score: ' + similarity_score + ')')تنفيذ خلية التعليمات البرمجية 10. ينبغي أن تشاهد المخرج التالي:
Remote Control (Score: 0.8301) Meet Dave (Score: 0.8236) Elf-Man (Score: 0.8208) Fifty/Fifty (Score: 0.8167) Mars Attacks! (Score: 0.8165) Strange Invaders (Score: 0.8143) Amanda and the Alien (Score: 0.8136) Suburban Commando (Score: 0.8129) Coneheads (Score: 0.8129) Morons from Outer Space (Score: 0.8121)
باستخدام Azure Cache ل Redis وخدمة Azure OpenAI، يمكنك استخدام التضمينات والبحث المتجه لإضافة قدرات بحث قوية إلى التطبيق الخاص بك.
تنظيف الموارد
إذا كنت تريد الاستمرار في استخدام الموارد التي قمت بإنشائها في هذه المقالة، فاحتفظ بمجموعة الموارد.
وإلا، إذا انتهيت من الموارد، يمكنك حذف مجموعة موارد Azure التي قمت بإنشائها لتجنب الرسوم.
هام
حذف مجموعة الموارد لا يمكن التراجع عنه. عند حذف مجموعة موارد، يتم حذف كافة الموارد الموجودة فيها نهائيًا. تأكد من عدم حذف مجموعة الموارد الخاطئة أو الموارد غير الصحيحة بطريق الخطأ. إذا قمت بإنشاء الموارد داخل مجموعة موارد موجودة تحتوي على الموارد التي تريد الاحتفاظ بها، يمكنك حذف كل مورد على حدة بدلا من حذف مجموعة الموارد.
لحذف مجموعة موارد
سجل الدخول إلى مدخل Azure، وحدد "Resource groups".
حدد مجموعة الموارد التي تريد حذفها.
إذا كان هناك العديد من مجموعات الموارد، فاستخدم المربع تصفية لأي حقل... ، واكتب اسم مجموعة الموارد التي أنشأتها لهذه المقالة. حدد مجموعة الموارد في قائمة النتائج.
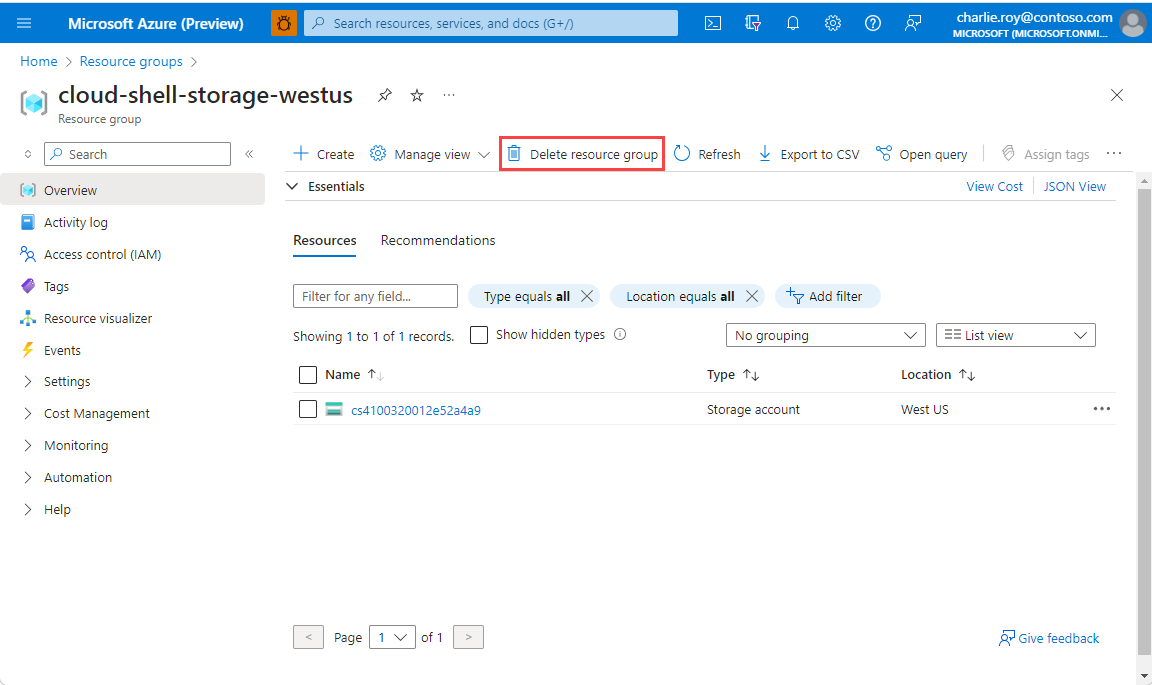
حدد Delete resource group.
يُطلب منك تأكيد حذف مجموعة الموارد. اكتب اسم مجموعة الموارد لتأكيده، واختر "Delete".
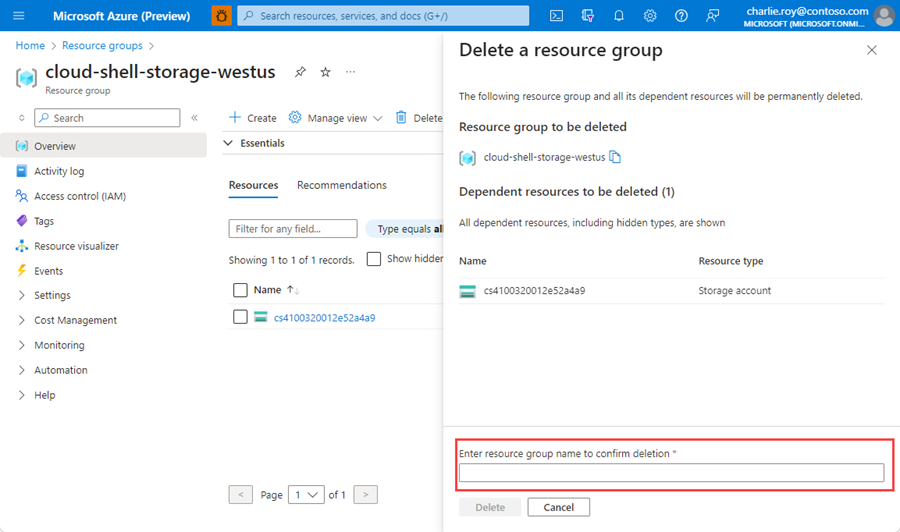
بعد مرور لحظات قليلة، يتم حذف مجموعة الموارد وجميع مواردها.
المحتوى ذي الصلة
- تعرف على المزيد حول Azure Cache for Redis
- تعرف على المزيد حول ذاكرة التخزين المؤقت Azure لإمكانيات البحث عن متجهات Redis
- تعرف على المزيد حول التضمينات التي تم إنشاؤها بواسطة خدمة Azure OpenAI
- تعرف على المزيد حول تشابه جيب التمام
- اقرأ كيفية إنشاء تطبيق مدعوم الذكاء الاصطناعي باستخدام OpenAI وRedis
- إنشاء تطبيق Q&A مع إجابات دلالية