استكشاف أخطاء مجموعة مقاييس Prometheus وإصلاحها في Azure Monitor
اتبع الخطوات الواردة في هذه المقالة لتحديد سبب عدم تجميع مقاييس Prometheus كما هو متوقع في Azure Monitor.
تقوم pod النسخة المتماثلة بالتخلص من المقاييس من kube-state-metrics، وأهداف الكشط المخصصة في ama-metrics-prometheus-config configmap وأهداف الكشط المخصصة المحددة في الموارد المخصصة. تقوم وحدات الجراب DaemonSet باستخراج المقاييس من الأهداف التالية على العقدة الخاصة بها: kubeletcAdvisornode-exporter، وأهداف الكشط المخصصة في ama-metrics-prometheus-config-node configmap. تعتمد الحجيرة التي تريد عرض السجلات وواجهة مستخدم Prometheus لها على هدف القصاصة الذي تحقق فيه.
استكشاف الأخطاء وإصلاحها باستخدام برنامج powershell النصي
إذا واجهت خطأ أثناء محاولة تمكين المراقبة لنظام مجموعة AKS، يرجى اتباع الإرشادات المذكورة هنا لتشغيل البرنامج النصي لاستكشاف الأخطاء وإصلاحها. تم تصميم هذا البرنامج النصي لإجراء تشخيص أساسي لأي مشكلات في التكوين على نظام المجموعة الخاص بك ويمكنك تحديد الملفات التي تم إنشاؤها أثناء إنشاء طلب دعم لحل حالة الدعم بشكل أسرع.
المقاييس المفقودة
تقييد المقاييس
في مدخل Microsoft Azure، انتقل إلى مساحة عمل Azure Monitor. انتقل إلى Metrics وتحقق من أن المقاييس Active Time Series % Utilization وأقل Events Per Minute Ingested % Utilization من 100٪.

إذا كان أي منهما أكثر من 100٪، يتم تقييد الاستيعاب في مساحة العمل هذه. في نفس مساحة العمل، انتقل إلى New Support Request لإنشاء طلب لزيادة الحدود. حدد نوع المشكلة ك Service and subscription limits (quotas) ونوع الحصة النسبية ك Managed Prometheus.
يمكنك أيضا مراقبة تنبيه وإعداده على حدود الاستيعاب. راجع مراقبة حدود الاستيعاب لتجنب تقييد استيعاب المقاييس.
فجوات متقطعة في جمع البيانات المترية
أثناء تحديثات العقدة، قد ترى فجوة من 1 إلى 2 دقيقة في البيانات القياسية للمقاييس التي تم جمعها من مجمع مستوى نظام المجموعة لدينا. هذه الفجوة بسبب تحديث العقدة التي يتم تشغيلها كجزء من عملية تحديث عادية. يؤثر على أهداف على مستوى المجموعة مثل kube-state-metrics وأهداف التطبيق المخصصة المحددة. يحدث ذلك عند تحديث نظام المجموعة يدويا أو عن طريق التحديث التلقائي. هذا السلوك متوقع ويحدث بسبب العقدة التي يتم تشغيلها عند تحديثها. لا تتأثر أي من قواعد التنبيه الموصى بها بهذا السلوك.
حالة الجراب
تحقق من حالة الجراب باستخدام الأمر التالي:
kubectl get pods -n kube-system | grep ama-metrics
- يجب أن يكون هناك جراب نسخة متماثلة واحدة
ama-metrics-xxxxxxxxxx-xxxxx، وواحدama-metrics-operator-targets-*، وجراب واحدama-metrics-ksm-*، وجرابama-metrics-node-*لكل عقدة على نظام المجموعة. - يجب أن تكون كل حالة جراب وينبغي أن يكون
Runningلها عدد متساو من عمليات إعادة التشغيل إلى عدد تغييرات configmap التي تم تطبيقها. قد يكون لدى جراب ama-metrics-operator-targets-* إعادة تشغيل إضافية في البداية وهذا متوقع:

إذا كانت كل حالة جراب ما هي Running إلا واحدة أو أكثر من الجرابات التي تمت إعادة تشغيلها، فقم بتشغيل الأمر التالي:
kubectl describe pod <ama-metrics pod name> -n kube-system
- يوفر هذا الأمر سبب إعادة التشغيل. من المتوقع إعادة تشغيل Pod إذا تم إجراء تغييرات في configmap. إذا كان سبب إعادة التشغيل هو
OOMKilled، فلا يمكن للحجيرة مواكبة حجم المقاييس. راجع توصيات المقياس لحجم المقاييس.
إذا كانت القرون تعمل كما هو متوقع، فإن المكان التالي للتحقق هو سجلات الحاوية.
التحقق من تكوينات إعادة التسمية
إذا كانت المقاييس مفقودة، يمكنك أيضا التحقق مما إذا كان لديك تكوينات إعادة تسمية. مع تكوينات إعادة التسمية، تأكد من أن إعادة التسمية لا تقوم بتصفية الأهداف، وأن التسميات التي تم تكوينها تتطابق بشكل صحيح مع الأهداف. راجع وثائق تكوين إعادة تسمية Prometheus لمزيد من التفاصيل.
سجلات الحاوية
عرض سجلات الحاوية باستخدام الأمر التالي:
kubectl logs <ama-metrics pod name> -n kube-system -c prometheus-collector
عند بدء التشغيل، تتم طباعة أي أخطاء أولية باللون الأحمر، بينما تتم طباعة التحذيرات باللون الأصفر. (يتطلب عرض السجلات الملونة الإصدار 7 على الأقل من PowerShell أو توزيع linux.)
- تحقق مما إذا كانت هناك مشكلة في الحصول على الرمز المميز للمصادقة:
- يتم تسجيل الرسالة لا يوجد تكوين لمورد AKS كل 5 دقائق.
- يتم إعادة تشغيل الجراب كل 15 دقيقة للمحاولة مرة أخرى مع الخطأ: لا يوجد تكوين لمورد AKS.
- إذا كان الأمر كذلك، فتحقق من وجود قاعدة تجميع البيانات ونقطة نهاية تجميع البيانات في مجموعة الموارد الخاصة بك.
- تحقق أيضا من وجود مساحة عمل Azure Monitor.
- تحقق من أنه ليس لديك نظام مجموعة AKS خاص وأنه غير مرتبط لنطاق ارتباط خاص ل Azure Monitor لأي خدمة أخرى. هذا السيناريو غير معتمد حاليا.
معالجة التكوين
عرض سجلات الحاوية باستخدام الأمر التالي:
kubectl logs <ama-metrics-operator-targets pod name> -n kube-system -c config-reader
- تحقق من عدم وجود أخطاء في تحليل تكوين Prometheus، والدمج مع تمكين أي أهداف كشط افتراضية، والتحقق من صحة التكوين الكامل.
- إذا قمت بتضمين تكوين Prometheus مخصص، فتحقق من أنه تم التعرف عليه في السجلات. إذا لم يكن:
- تحقق من أن configmap الخاص بك له الاسم الصحيح:
ama-metrics-prometheus-configفيkube-systemمساحة الاسم. - تحقق من أنه في تكوين تكوين Prometheus الخاص بك تحت قسم يسمى
prometheus-configضمنdataكما هو موضح هنا:kind: ConfigMap apiVersion: v1 metadata: name: ama-metrics-prometheus-config namespace: kube-system data: prometheus-config: |- scrape_configs: - job_name: <your scrape job here>
- تحقق من أن configmap الخاص بك له الاسم الصحيح:
- إذا قمت بإنشاء موارد مخصصة، يجب أن تشاهد أي أخطاء في التحقق من الصحة أثناء إنشاء شاشات pod/service. إذا كنت لا تزال لا ترى المقاييس من الأهداف، فتأكد من أن السجلات لا تظهر أي أخطاء.
kubectl logs <ama-metrics-operator-targets pod name> -n kube-system -c targetallocator
- تحقق من عدم وجود أخطاء فيما
MetricsExtensionيتعلق بالمصادقة مع مساحة عمل Azure Monitor. - تحقق من عدم وجود أخطاء من
OpenTelemetry collectorحول إلغاء الأهداف.
شغّل الأمر التالي:
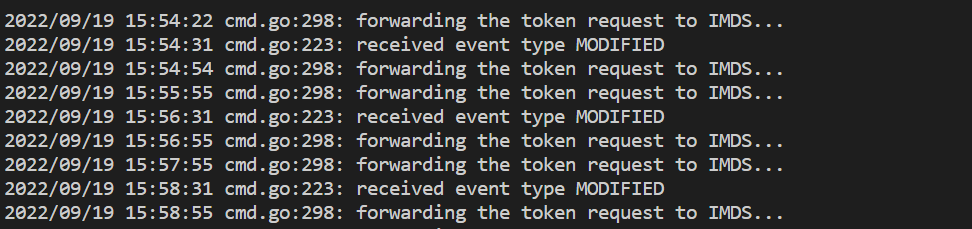
kubectl logs <ama-metrics pod name> -n kube-system -c addon-token-adapter
- يظهر هذا الأمر خطأ إذا كانت هناك مشكلة في المصادقة مع مساحة عمل Azure Monitor. يوضح المثال أدناه السجلات التي لا توجد بها مشكلات:

إذا لم تكن هناك أخطاء في السجلات، يمكن استخدام واجهة Prometheus لتصحيح الأخطاء للتحقق من التكوين المتوقع والأهداف التي يتم استخراجها.
واجهة Prometheus
كل ama-metrics-* جراب لديه وضع عامل Prometheus واجهة المستخدم المتاحة على المنفذ 9090.
يتم استخراج أهداف التكوين المخصص والموارد المخصصة بواسطة ama-metrics-* الجراب وأهداف العقدة ama-metrics-node-* بواسطة الجراب.
المنفذ إلى الأمام إما إلى جراب النسخة المتماثلة أو أحد القرون التي تم تعيينها الخفي للتحقق من التكوين واكتشاف الخدمة ونقاط النهاية المستهدفة كما هو موضح هنا للتحقق من صحة التكوينات المخصصة، تم اكتشاف الأهداف المقصودة لكل وظيفة، ولا توجد أخطاء في استخراج أهداف محددة.
تشغيل الأمر kubectl port-forward <ama-metrics pod> -n kube-system 9090.
افتح مستعرضا إلى العنوان
127.0.0.1:9090/config. تحتوي واجهة المستخدم هذه على تكوين الكشط الكامل. تحقق من تضمين جميع المهام في التكوين.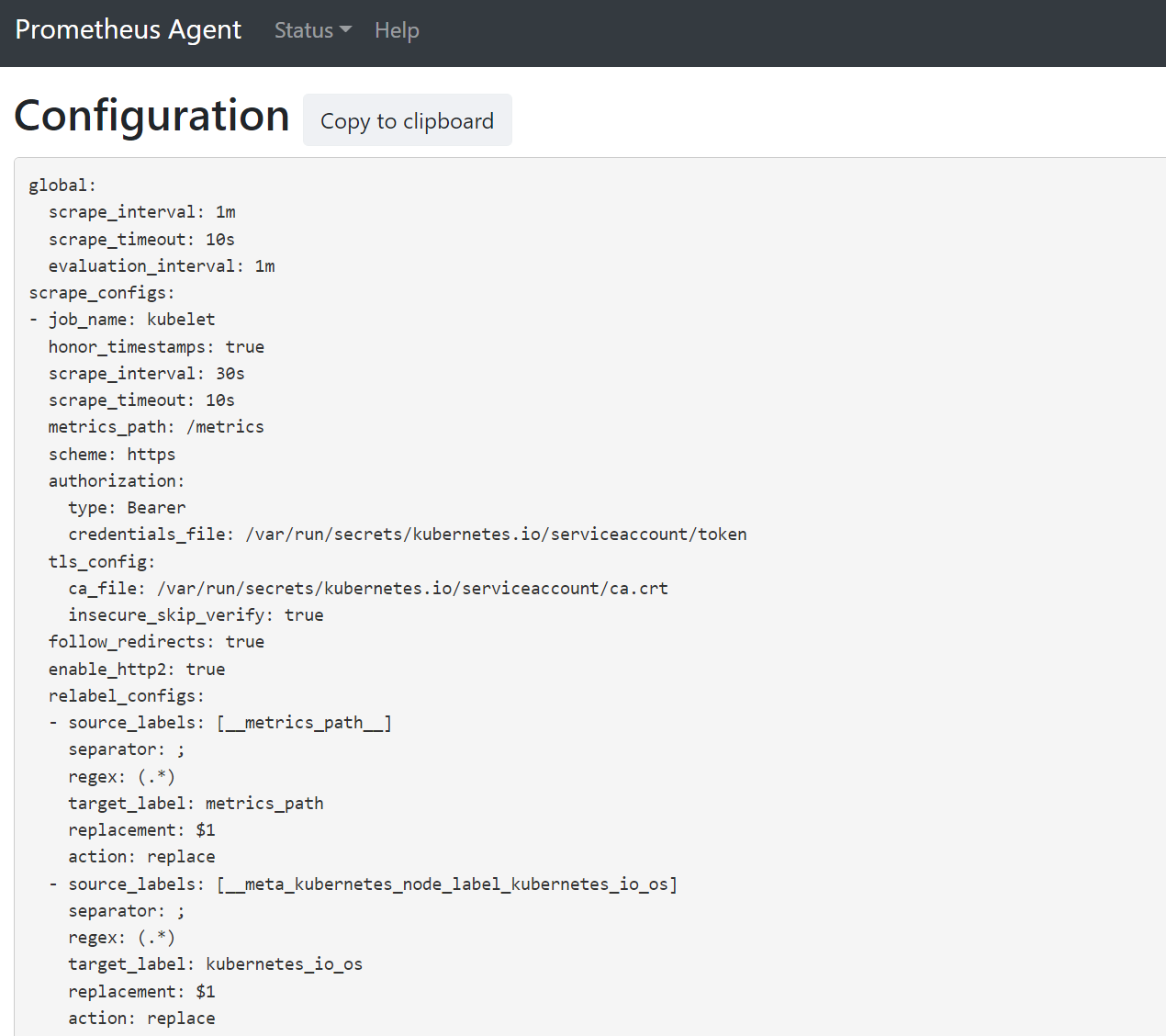
انتقل إلى
127.0.0.1:9090/service-discoveryلعرض الأهداف التي اكتشفها كائن اكتشاف الخدمة المحدد وما قام relabel_configs بتصفية الأهداف. على سبيل المثال، عند فقدان مقاييس من جراب معين، يمكنك العثور على ما إذا تم اكتشاف هذا الجراب وما هو URI الخاص به. يمكنك بعد ذلك استخدام URI هذا عند النظر إلى الأهداف لمعرفة ما إذا كانت هناك أي أخطاء في القصاصة.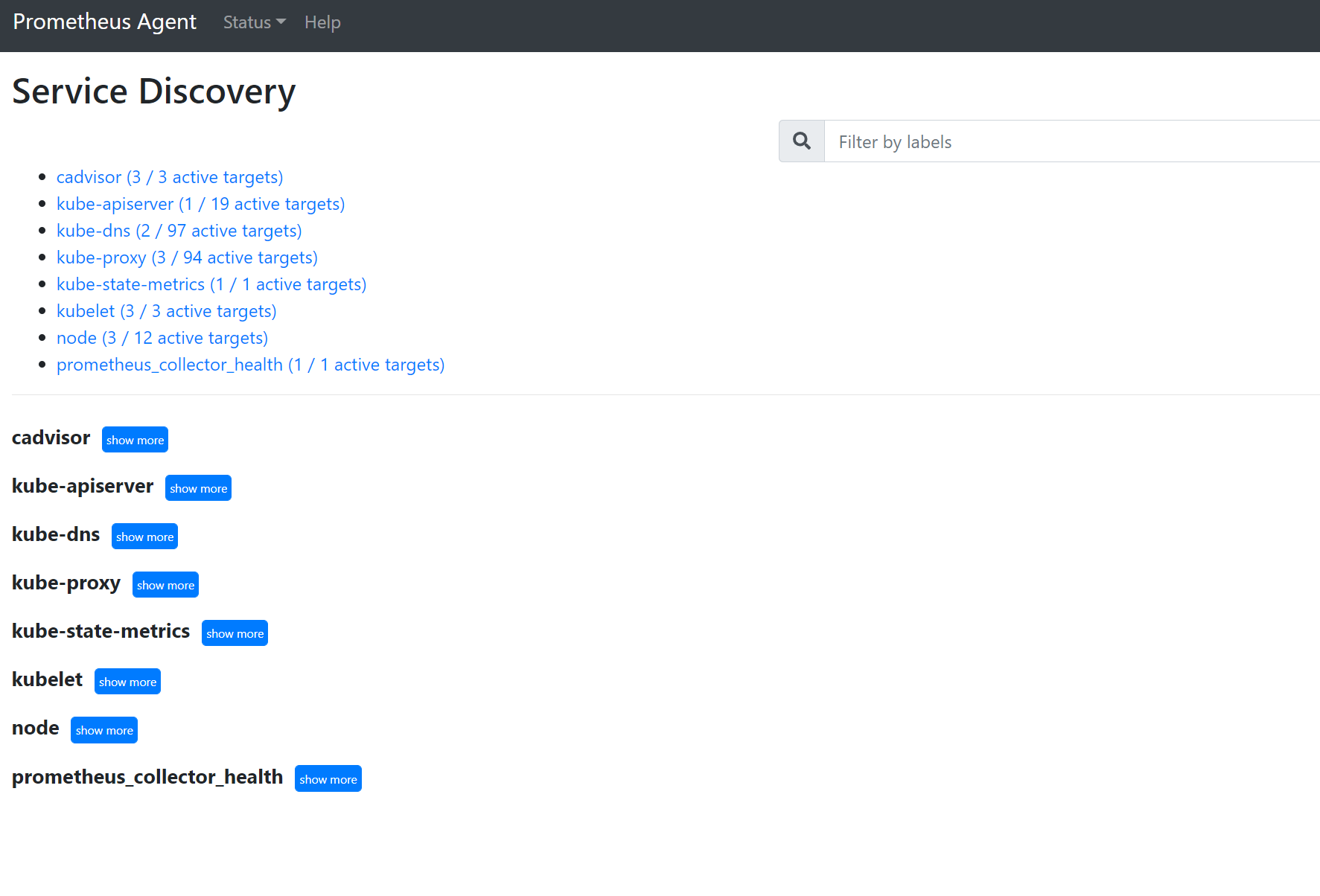
انتقل إلى
127.0.0.1:9090/targetsلعرض جميع المهام، وآخر مرة تم فيها إلغاء نقطة النهاية لهذه المهمة، وأي أخطاء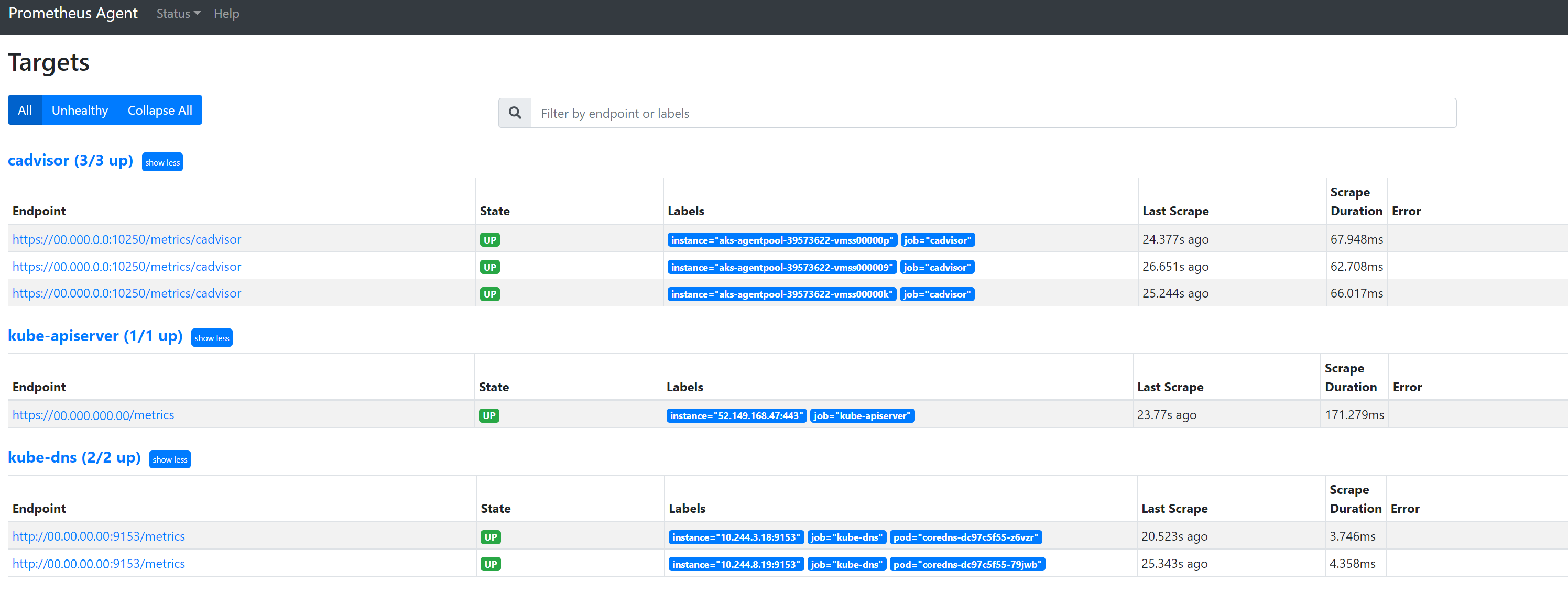



الموارد المخصصة
- إذا قمت بتضمين Custom Resources، فتأكد من ظهورها ضمن التكوين واكتشاف الخدمة والأهداف.
التكوين

اكتشاف الخدمة

الأهداف

إذا لم تكن هناك مشكلات ويتم استخراج الأهداف المقصودة، يمكنك عرض المقاييس الدقيقة التي يتم استخراجها عن طريق تمكين وضع التصحيح.
وضع تصحيح الأخطاء
تحذير
يمكن أن يؤثر هذا الوضع على الأداء ويجب تمكينه لفترة قصيرة فقط لأغراض تصحيح الأخطاء.
يمكن تكوين إضافة المقاييس للتشغيل في وضع تتبع الأخطاء عن طريق تغيير إعداد enabled configmap ضمن debug-mode إلى true باتباع الإرشادات هنا.
عند التمكين، تتم استضافة جميع مقاييس Prometheus التي تم استخراجها في المنفذ 9091. شغّل الأمر التالي:
kubectl port-forward <ama-metrics pod name> -n kube-system 9091
انتقل إلى 127.0.0.1:9091/metrics في مستعرض لمعرفة ما إذا كانت المقاييس قد تم استخراجها من قبل OpenTelemetry Collector. يمكن الوصول إلى واجهة المستخدم هذه لكل ama-metrics-* جراب. إذا لم تكن المقاييس موجودة، فقد تكون هناك مشكلة في أطوال اسم المقياس أو التسمية أو عدد التسميات. تحقق أيضا من تجاوز حصة الاستيعاب لمقاييس Prometheus كما هو محدد في هذه المقالة.
أسماء المقاييس وأسماء التسميات وقيم التسمية
يحتوي استخراج المقاييس حاليا على القيود الموجودة في الجدول التالي:
| الخاصية | الحد |
|---|---|
| طول اسم التسمية | أقل من أو يساوي 511 حرفا. عند تجاوز هذا الحد لأي سلسلة زمنية في الوظيفة، تفشل مهمة الاستخراج بأكملها، ويتم إسقاط المقاييس من تلك المهمة قبل الاستيعاب. يمكنك مشاهدة ما يصل إلى =0 لهذه المهمة وأيضا تظهر تجربة المستخدم الهدف سبب up=0. |
| طول قيمة التسمية | أقل من أو يساوي 1023 حرفا. عند تجاوز هذا الحد لأي سلسلة زمنية في وظيفة، تفشل القصاصة بأكملها، ويتم إسقاط المقاييس من تلك المهمة قبل الاستيعاب. يمكنك مشاهدة ما يصل إلى =0 لهذه المهمة وأيضا تظهر تجربة المستخدم الهدف سبب up=0. |
| عدد التسميات لكل سلسلة زمنية | أقل من أو يساوي 63. عند تجاوز هذا الحد لأي سلسلة زمنية في الوظيفة، تفشل مهمة الاستخراج بأكملها، ويتم إسقاط المقاييس من تلك المهمة قبل الاستيعاب. يمكنك مشاهدة ما يصل إلى =0 لهذه المهمة وأيضا تظهر تجربة المستخدم الهدف سبب up=0. |
| طول اسم القياس | أقل من أو يساوي 511 حرفا. عند تجاوز هذا الحد لأي سلسلة زمنية في مهمة، يتم إسقاط هذه السلسلة المعينة فقط. يحتوي MetricextensionConsoleDebugLog على تتبعات للمقياس الذي تم إسقاطه. |
| أسماء التسميات ذات غلاف مختلف | يتم التعامل مع تسميتين داخل نفس نموذج القياس، مع غلاف مختلف على أنهما يحتويان على تسميات مكررة ويتم إسقاطهما عند تناولهما. على سبيل المثال، يتم إسقاط السلسلة my_metric{ExampleLabel="label_value_0", examplelabel="label_value_1} الزمنية بسبب تسميات مكررة نظرا ExampleLabel examplelabel لأنه ينظر إليها على أنها نفس اسم التسمية. |
التحقق من حصة الاستيعاب على مساحة عمل Azure Monitor
إذا رأيت مقاييس فائتة، يمكنك أولا التحقق مما إذا كان يتم تجاوز حدود الاستيعاب لمساحة عمل Azure Monitor. في مدخل Microsoft Azure، يمكنك التحقق من الاستخدام الحالي لأي مساحة عمل مراقبة Azure. يمكنك مشاهدة مقاييس الاستخدام الحالية ضمن Metrics القائمة لمساحة عمل Azure Monitor. تتوفر مقاييس الاستخدام التالية كمقاييس قياسية لكل مساحة عمل Azure Monitor.
- Active Time Series - عدد السلاسل الزمنية الفريدة التي تم إدخالها مؤخرا في مساحة العمل خلال ال 12 ساعة السابقة
- حد السلسلة الزمنية النشطة - الحد الأقصى لعدد السلاسل الزمنية الفريدة التي يمكن استيعابها بنشاط في مساحة العمل
- استخدام النسبة المئوية للسلسلة الزمنية النشطة - النسبة المئوية للسلسلة الزمنية النشطة الحالية المستخدمة
- الأحداث في الدقيقة التي تم استيعابها - عدد الأحداث (العينات) في الدقيقة التي تم تلقيها مؤخرا
- الحد الأقصى لاستيعاب الأحداث في الدقيقة - الحد الأقصى لعدد الأحداث في الدقيقة التي يمكن استيعابها قبل تقييدها
- استخدام النسبة المئوية لاستيعاب الأحداث في الدقيقة - النسبة المئوية للحد الحالي لمعدل الاستيعاب القياسي هي الاستخدام
لتجنب تقييد استيعاب المقاييس، يمكنك مراقبة وإعداد تنبيه على حدود الاستيعاب. راجع مراقبة حدود الاستيعاب.
راجع حصص الخدمة وحدودها للحصص النسبية الافتراضية وأيضا لفهم ما يمكن زيادته بناء على استخدامك. يمكنك طلب زيادة الحصة النسبية لمساحات عمل Azure Monitor باستخدام Support Request القائمة لمساحة عمل Azure Monitor. تأكد من تضمين المعرف والمعرف الداخلي والموقع/المنطقة لمساحة عمل Azure Monitor في طلب الدعم، والتي يمكنك العثور عليها في قائمة "الخصائص" لمساحة عمل Azure Monitor في مدخل Microsoft Azure.
فشل إنشاء مساحة عمل Azure Monitor بسبب تقييم نهج Azure
إذا فشل إنشاء مساحة عمل Azure Monitor مع ظهور خطأ يقول "المورد 'resource-name-xyz' غير مسموح به من قبل النهج"، فقد يكون هناك نهج Azure يمنع إنشاء المورد. إذا كان هناك نهج يفرض اصطلاح تسمية لموارد Azure أو مجموعات الموارد الخاصة بك، فستحتاج إلى إنشاء استثناء لاصطلاح التسمية لإنشاء مساحة عمل Azure Monitor.
عند إنشاء مساحة عمل Azure Monitor، بشكل افتراضي، سيتم إنشاء قاعدة تجميع بيانات ونقطة نهاية تجميع بيانات في النموذج "azure-monitor-workspace-name" تلقائيا في مجموعة موارد في النموذج "MA_azure-monitor-workspace-name_location_managed". حاليا لا توجد طريقة لتغيير أسماء هذه الموارد، وستحتاج إلى تعيين استثناء على نهج Azure لإعفاء الموارد المذكورة أعلاه من تقييم النهج. راجع بنية الإعفاء من نهج Azure.
الخطوات التالية
الملاحظات
قريبًا: خلال عام 2024، سنتخلص تدريجيًا من GitHub Issues بوصفها آلية إرسال ملاحظات للمحتوى ونستبدلها بنظام ملاحظات جديد. لمزيد من المعلومات، راجع https://aka.ms/ContentUserFeedback.
إرسال الملاحظات وعرضها المتعلقة بـ