درجة الثقة للإجابة
عند مطابقة استعلام مستخدم مقابل قاعدة معارف، يقوم QnA Maker بإرجاع الإجابات ذات الصلة، بالإضافة إلى درجة الثقة. تشير هذه النتيجة إلى الثقة بأن الإجابة هي المطابقة الصحيحة لاستعلام المستخدم المحدد.
درجة الثقة هي عدد بين 0 و100. درجة 100 من المرجح أن تكون مطابقة تماماً في حين أن درجة 0 يعني، أنه لم يتم العثور على إجابة مطابقة. كلما زادت النتيجة - زادت الثقة في الإجابة. لاستعلام معين، قد يكون هناك إجابات متعددة تم إرجاعها. في هذه الحالة، يتم إرجاع الإجابات من أجل تقليل درجة الثقة.
في المثال أدناه، يمكنك مشاهدة كيان QnA واحد، مع سؤالين.

على سبيل المثال أعلاه - يمكنك توقع درجات مثل نطاق نقاط العينة أدناه - للأنواع المختلفة من استعلامات المستخدم:
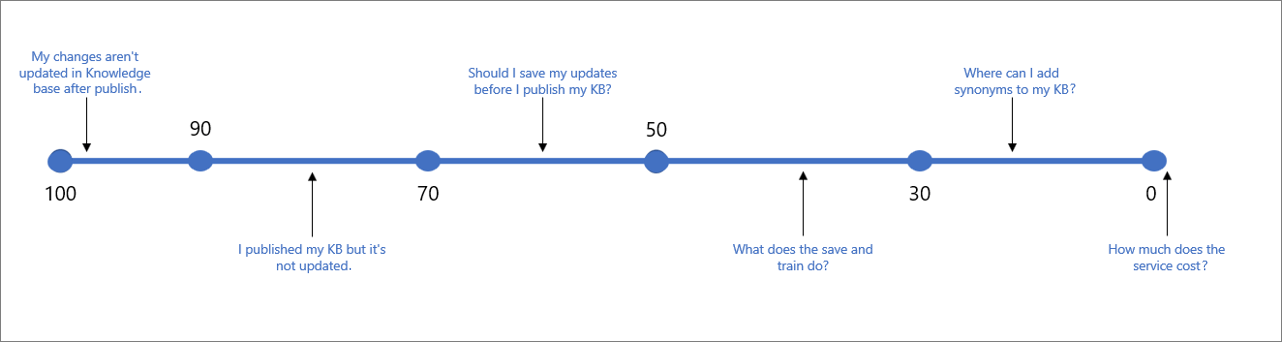
يشير الجدول التالي إلى الثقة النموذجية المقترنة بنتيجة معينة.
| قيمة الدرجة | معنى الدرجة | نموذج استعلام |
|---|---|---|
| 90 - 100 | تطابق دقيق تقريباً لاستعلام المستخدم وسؤال قاعدة المعارف | "لا يتم تحديث تغييراتي في KB بعد النشر" |
| > 70 | ثقة عالية - عادة ما تكون إجابة جيدة تجيب تماماً عن استعلام المستخدم | "لقد نشرت KB الخاص بي ولكن لم يتم تحديثه" |
| 50 - 70 | ثقة متوسطة - عادة إجابة جيدة إلى حد ما يجب أن تجيب عن الهدف الرئيسي لاستعلام المستخدم | "هل يجب حفظ تحديثاتي قبل نشر KB الخاص بي؟" |
| 30 - 50 | انخفاض الثقة -- عادة ما تكون إجابة ذات صلة، أن يجيب جزئياً على هدف المستخدم | "ماذا يفعل الحفظ والتدريب؟" |
| < 30 | ثقة منخفضة جداً - عادة لا يجيب عن استعلام المستخدم، ولكن لديه بعض الكلمات أو العبارات المطابقة | " أين يمكنني إضافة مرادفات إلى KB الخاص بي" |
| 0 | لا تطابق، لذلك لا يتم إرجاع الإجابة. | "كم تكلفة الخدمة" |
اختيار حد درجة
يعرض الجدول أعلاه الدرجات المتوقعة على معظم KBs. ومع ذلك، نظرا لأن كل كيلوبايت مختلف، ولديه أنواع مختلفة من الكلمات والأهداف - نوصيك باختبار واختيار الحد الذي يناسبك بشكل أفضل. بشكل افتراضي، يتم تعيين الحد إلى 0، بحيث يتم إرجاع جميع الإجابات المحتملة. الحد الموصى به الذي يجب أن يعمل لمعظم KBs، هو 50.
عند اختيار الحد الخاص بك، ضع في اعتبارك التوازن بين الدقة والتغطية، وقم بتعديل الحد الخاص بك بناء على متطلباتك.
إذا كانت الدقة أكثر أهمية للسيناريو الخاص بك، فقم بزيادة الحد الخاص بك. بهذه الطريقة، في كل مرة تقوم فيها بإرجاع إجابة، ستكون حالة أكثر ثقة، وأكثر احتمالاً أن تكون الإجابة التي يبحث عنها المستخدمون. في هذه الحالة، قد ينتهي بك الأمر إلى ترك المزيد من الأسئلة دون إجابة. على سبيل المثال: إذا قمت بإجراء الحد 70، فقد تفوتك بعض الأمثلة الغامضة مثل "ما هو الحفظ والتدريب؟".
إذا كانت التغطية (أو الاسترجاع) أكثر أهمية- وتريد الإجابة عن أكبر عدد ممكن من الأسئلة، حتى إذا كانت هناك علاقة جزئية فقط بسؤال المستخدم- فعندئذ قم بخفض الحد. وهذا يعني أنه قد يكون هناك المزيد من الحالات التي لا تجيب فيها الإجابة عن الاستعلام الفعلي للمستخدم، ولكنها تعطي إجابة أخرى ذات صلة إلى حد ما. على سبيل المثال: إذا قمت بإجراء الحد 30، فقد تقدم إجابات للاستعلامات مثل "أين يمكنني تحرير KB الخاص بي؟"
إشعار
تتضمن الإصدارات الأحدث من QnA Maker تحسينات على منطق التسجيل، ويمكن أن تؤثر على الحد الخاص بك. في أي وقت تقوم فيه بتحديث الخدمة، تأكد من اختبار العتبة وتعديلها إذا لزم الأمر. يمكنك التحقق من إصدار QnA Service هنا، ومعرفة كيفية الحصول على آخر التحديثات هنا.
عين الحد
تعيين درجة الحد كخاصية لنص GenerateAnswer API JSON. وهذا يعني أنك قمت بتعيينه لكل استدعاء إلى GenerateAnswer.
من إطار عمل الروبوت، قم بتعيين النتيجة كجزء من عنصر الخيارات باستخدام C# أو Node.js.
تحسين درجات الثقة
لتحسين درجة الثقة استجابة معينة إلى استعلام مستخدم يمكنك إضافة استعلام المستخدم إلى قاعدة المعارف لسؤال بديل على تلك الاستجابة. يمكنك أيضا استخدام تعديلات الكلمات غير الحساسة لحالة الأحرف لإضافة مرادفات إلى الكلمات الأساسية في KB الخاص بك.
درجات ثقة مماثلة
عندما يكون للاستجابات المتعددة درجة ثقة مماثلة، فمن المحتمل أن يكون الاستعلام عاماً للغاية وبالتالي يتطابق مع احتمالية متساوية مع إجابات متعددة. حاول أن تنظم QnAs بشكل أفضل بحيث يكون لكل كيان QnA هدف مميز.
فروق درجة الثقة بين الاختبار والإنتاج
قد تتغير درجة الثقة للإجابة بشكل ضئيل بين الاختبار والإصدار المنشور من قاعدة معارف حتى لو كان المحتوى هو نفسه. وذلك لأن محتوى الاختبار قاعدة المعارف (KB) المنشورة موجودان في فهارس بحث Azure الذكاء الاصطناعي مختلفة.
يحتوي فهرس الاختبار على جميع أزواج QnA لقواعد المعرفة الخاصة بك. عند الاستعلام عن فهرس الاختبار، ينطبق الاستعلام على الفهرس بأكمله ثم تقتصر النتائج على القسم لهذا قاعدة معارف المحدد. إذا كانت نتائج استعلام الاختبار تؤثر سلبا على قدرتك على التحقق من صحة قاعدة معارف، يمكنك:
- تنظيم قاعدة المعارف (KB) باستخدام أحد الإجراءات التالية:
- مورد واحد مقيد ب 1 كيلوبايت: تقييد مورد QnA واحد (وفهرس اختبار Azure الذكاء الاصطناعي Search الناتج) إلى قاعدة المعارف (KB) واحد.
- موارد 2 - 1 للاختبار، 1 للإنتاج: لديك موردان من QnA Maker، باستخدام واحد للاختبار (بفهرسي الاختبار والإنتاج الخاصين به) والآخر للمنتج (أيضا له فهارس الاختبار والإنتاج الخاصة به)
- واستخدم دائما نفس المعلمات، مثل أعلى عند الاستعلام عن كل من الاختبار والإنتاج قاعدة معارف
عند نشر قاعدة معارف تنتقل محتويات السؤال والإجابة للمشروع من قاعدة معارف الاختبار إلى فهرس إنتاج في بحث Azure. تعرف على كيفية عمل عملية النشر.
إذا كان لديك قاعدة المعارف (KB) في مناطق مختلفة، فإن كل منطقة تستخدم فهرس Azure الذكاء الاصطناعي Search الخاص بها. نظراً لاستخدام فهارس مختلفة، لن تكون الدرجات متطابقة تماماً.
لم يتم العثور على تطابق
عند عدم العثور على تطابق جيد من قبل المرتب، يتم إرجاع درجة الثقة 0.0 أو "None" والاستجابة الافتراضية هي "لم يتم العثور على تطابق جيد في KB". يمكنك تجاوز هذه الاستجابة الافتراضية في الروبوت أو التعليمات البرمجية للتطبيق التي تستدعي نقطة النهاية. بدلا من ذلك، يمكنك أيضا تعيين استجابة التجاوز في Azure وهذا يغير الإعداد الافتراضي لكافة قواعد المعرفة المنشورة في خدمة QnA Maker معينة.