ملاحظة
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
ينطبق على:
![]() NoSQL
NoSQL
![]() MongoDB
MongoDB
![]() العفريت
العفريت
هام
النسخ المتطابق ل Azure Cosmos DB في Microsoft Fabric متاح الآن لواجهة برمجة تطبيقات NoSql. توفر هذه الميزة جميع إمكانيات Azure Synapse Link بأداء تحليلي أفضل، والقدرة على توحيد ملكية بياناتك باستخدام Fabric OneLake والوصول المفتوح إلى بياناتك بتنسيق Delta Parquet. إذا كنت تفكر في Azure Synapse Link، نوصي بتجربة النسخ المتطابق لتقييم ملاءمة مؤسستك بشكل عام. ابدأ مع النسخ المتطابق في Microsoft Fabric.
لبدء استخدام Azure Synapse Link، يرجى زيارة "البدء باستخدام Azure Synapse Link"
مخزن Azure Cosmos DB التحليلي هو مخزن أعمدة معزول تمامًا لتمكين التحليلات واسعة النطاق مقابل البيانات التشغيلية في Azure Cosmos DB الخاص بك، دون أي تأثير على أحمال العمل الخاصة بك.
متجر المعاملات Azure Cosmos DB عبارة عن مخطط منطقي، ويسمح لك بالتكرير على تطبيقات المعاملات الخاصة بك دون الحاجة إلى التعامل مع إدارة المخطط أو الفهرس. على النقيض من هذا، يتم تخطيط متجر التحليل Azure Cosmos DB لتحسين أداء الاستعلام التحليلي. توضح هذه المقالة بالتفصيل التخزين التحليلي.
التحديات المتعلقة بالتحليلات واسعة النطاق على البيانات التشغيلية
يتم تخزين البيانات التشغيلية متعددة النماذج في حاوية Azure Cosmos DB داخلياً في "متجر معاملات" يستند إلى صف مفهرس. تم تصميم تنسيق متجر الصفوف للسماح بقراءة المعاملات السريعة والكتابة في أوقات استجابة تبلغ ميلي ثانية، والاستعلامات التشغيلية. إذا أصبحت مجموعة البيانات الخاصة بك كبيرة، يمكن أن تكون الاستعلامات التحليلية المعقدة مكلفة من حيث معدل النقل المقدم على البيانات المخزنة في هذا الشكل. يؤثر الاستهلاك العالي لمعدل النقل المقدم بدوره على أداء أحمال العمل المتعلقة بالمعاملات التي تستخدمها التطبيقات والخدمات في الوقت الفعلي.
تقليدياً، لتحليل كميات كبيرة من البيانات، يتم استخراج البيانات التشغيلية من متجر المعاملات Azure Cosmos DB وتخزينها في طبقة بيانات منفصلة. على سبيل المثال، يتم تخزين البيانات في مستودع بيانات أو مستودع بيانات بتنسيق مناسب. يتم استخدام هذه البيانات لاحقا للتحليلات واسعة النطاق وتحليلها باستخدام محركات الحوسبة مثل مجموعات Apache Spark. ويؤدي فصل البيانات التحليلية عن البيانات التشغيلية إلى تأخيرات للمحللين الذين يرغبون في استخدام أحدث البيانات.
كما تصبح بنية ETL معقدة عند معالجة التحديثات بالبيانات التشغيلية بالمقارنة مع التعامل مع البيانات التشغيلية التي تم إدخالها حديثاً فقط.
مخزن تحليلي موجه للعمود
يعالج متجر Azure Cosmos DB التحليلي تحديات زمن الانتقال ووقت الاستجابة التي تحدث مع مسارات ETL التقليدية. يمكن لمخزن Azure Cosmos DB التحليلي مزامنة بياناتك التشغيلية تلقائياً في مخزن أعمدة منفصل. تنسيق مخزن العمود مناسب للاستعلامات التحليلية واسعة النطاق التي يتم إجراؤها بطريقة محسّنة، ما يؤدي إلى تحسين زمن انتقال هذه الاستعلامات.
باستخدام Azure Synapse Link، يمكنك الآن إنشاء حلول HTAP دون استخراج وتحويل وتحميل عن طريق الارتباط المباشر بمتجر Azure Cosmos DB التحليلي من Azure Synapse Analytics. فهو يتيح لك تشغيل تحليلات واسعة النطاق في وقت قريب من الوقت الحقيقي على بياناتك التشغيلية.
ميزات المتجر التحليلي
عند تمكين متجر تحليلي على حاوية Azure Cosmos DB، يتم إنشاء مخزن أعمدة جديد داخلياً استناداً إلى البيانات التشغيلية في الحاوية. يستمر مخزن الأعمدة هذا بشكل منفصل عن مخزن المعاملات الموجه للصف لتلك الحاوية، في حساب تخزين تتم إدارته بالكامل بواسطة Azure Cosmos DB، في اشتراك داخلي. لا يحتاج العملاء إلى قضاء بعض الوقت مع إدارة التخزين. تتم مزامنة الإدخالات والتحديثات والحذف بالبيانات التشغيلية تلقائياً إلى متجر تحليلي. لا تحتاج إلى تغيير الموجز أو ETL لمزامنة البيانات.
متجر الأعمدة لأحمال العمل التحليلية على البيانات التشغيلية
تتضمن أحمال العمل التحليلية عادة التجميعات والمسح التسلسلي للحقول المحددة. يتم تخزين مخزن البيانات التحليلي بترتيب عمودي رئيسي، مما يسمح بتسلسل قيم كل حقل معا، حيثما أمكن ذلك. يقلل هذا التنسيق من عملية IOPS المطلوبة لمسح أو حساب الإحصائيات عبر حقول معينة. ويحسن بشكل كبير أوقات استجابة الاستعلامات للمسح الضوئي عبر مجموعات البيانات الكبيرة.
على سبيل المثال، إذا كانت جداول العمليات بالتنسيق التالي:
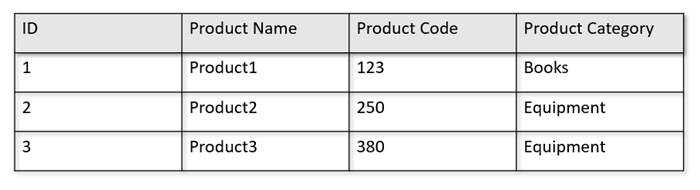
يحافظ مخزن الصف على البيانات أعلاه بتنسيق متسلسل، لكل صف، على القرص. يسمح هذا التنسيق بقراءة المعاملات والكتابة والاستعلامات التشغيلية بشكل أسرع، مثل "إرجاع معلومات حول المنتج 1". ومع ذلك، تصبح مجموعة البيانات كبيرة وإذا كنت تريد تشغيل استعلامات تحليلية معقدة على البيانات، يمكن أن تكون مكلفة. على سبيل المثال، إذا كنت ترغب في الحصول على "اتجاهات المبيعات لمنتج ما ضمن الفئة المسماة 'Equipment' عبر وحدات الأعمال والأشهر المختلفة"، فأنت بحاجة إلى تشغيل استعلام معقد. يمكن أن تكون عمليات المسح الكبيرة على مجموعة البيانات هذه مكلفة من حيث معدل النقل المقدم ويمكن أن تؤثر أيضاً على أداء أحمال عمل المعاملات التي تعمل على تشغيل التطبيقات والخدمات في الوقت الحقيقي.
متجر التحليل، متجر أعمدة أكثر ملاءمة لمثل هذه الاستعلامات لأنه تسلسل حقول مماثلة من البيانات معاً ويقلل من عملية IOPS على القرص.
تعرض الصورة التالية متجر صف المعاملات مقابل متجر الأعمدة التحليلية في Azure Cosmos DB:
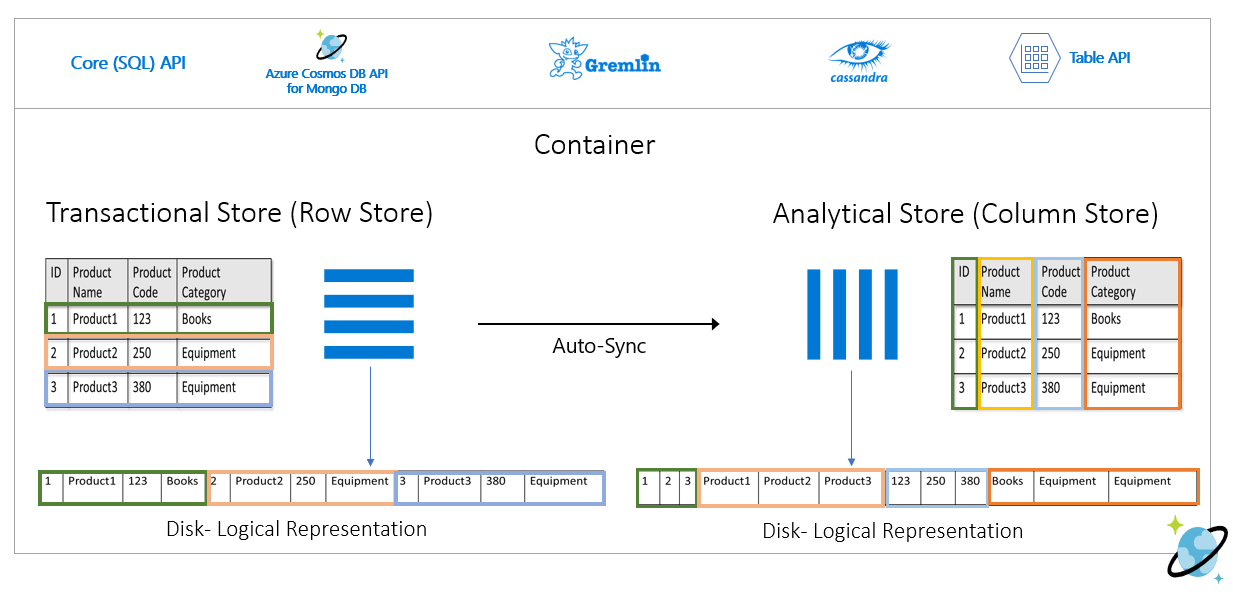
أداء مفكك لأحمال العمل التحليلية
ليس هناك أي تأثير على أداء أحمال العمل الخاصة بالعمليات بسبب الاستعلامات التحليلية، حيث إن المخزن التحليلي منفصل عن مخزن العمليات. لا يحتاج المخزن التحليلي إلى تخصيص وحدات طلب (RU) منفصلة.
المزامنة التلقائية
تشير المزامنة التلقائية إلى القدرة المدارة بالكامل في Azure Cosmos DB حيث تتم مزامنة الإدراجات والتحديثات والحذف بالبيانات التشغيلية تلقائياً من متجر المعاملات إلى المتجر التحليلي في الوقت الحقيقي تقريباً. عادة ما يكون زمن انتقال المزامنة التلقائية في غضون دقيقتين. في حالات قاعدة بيانات معدل النقل المشترك عبر عدد كبير من الحاويات، قد يكون زمن انتقال المزامنة التلقائية للحاويات الفردية أعلى ويستغرق ما يصل إلى 5 دقائق.
في نهاية كل تنفيذ لعملية المزامنة التلقائية، ستكون بيانات المعاملات متوفرة على الفور لوقت تشغيل Azure Synapse Analytics:
يمكن لتجمعات Azure Synapse Analytics Spark قراءة جميع البيانات، بما في ذلك آخر التحديثات، من خلال جداول Spark، التي يتم تحديثها تلقائيا، أو عبر الأمر
spark.read، والذي يقرأ دائماً الحالة الأخيرة للبيانات.يمكن لمجموعات Azure Synapse Analytics SQL Serverless قراءة جميع البيانات، بما في ذلك آخر التحديثات، من خلال طرق العرض، التي يتم تحديثها تلقائياً، أو عبر
SELECTمع أوامرOPENROWSET، التي تقرأ دائماً أحدث حالة للبيانات.
إشعار
ستتم مزامنة بيانات العمليات الخاصة بك إلى المخزن التحليلي حتى إذا كانت مدة بقاء العمليات (TTL) أقل من دقيقتين.
إشعار
يرجى ملاحظة أنه إذا قمت بحذف الحاوية الخاصة بك، فسيتم أيضاً حذف المخزن التحليلي.
قابلية التوسع والمرونة
يستخدم مخزن معاملات Azure Cosmos DB التقسيم الأفقي لتوسيع نطاق التخزين ومعدل النقل بشكل مرن دون أي وقت تعطل. يوفر التقسيم الأفقي في متجر المعاملات قابلية التوسع والمرونة في المزامنة التلقائية لضمان مزامنة البيانات بالمتجر التحليلي في الوقت الفعلي القريب. تحدث مزامنة البيانات بغض النظر عن معدل نقل البيانات للعمليات، سواء كان 1000 عملية/ثانية أو مليون عملية/ثانية، ولا تؤثر على معدل النقل المقدم في مخزن العمليات.
معالجة تحديثات المخطط تلقائياً
متجر المعاملات Azure Cosmos DB عبارة عن مخطط منطقي، ويسمح لك بالتكرير على تطبيقات المعاملات الخاصة بك دون الحاجة إلى التعامل مع إدارة المخطط أو الفهرس. على النقيض من هذا، يتم تخطيط متجر التحليل Azure Cosmos DB لتحسين أداء الاستعلام التحليلي. ومع إمكانية المزامنة التلقائية، يدير Azure Cosmos DB استنتاج المخطط عبر آخر التحديثات من متجر المعاملات. كما أنه يدير تمثيل المخطط في المتجر التحليلي خارج الصندوق، والذي يتضمن معالجة أنواع البيانات المتداخلة.
ومع تطور المخطط الخاص بك، وإضافة خصائص جديدة مع مرور الوقت، يعرض المتجر التحليلي تلقائياً مخطط توحيد عبر جميع المخططات التاريخية في متجر المعاملات.
إشعار
في سياق المتجر التحليلي، نعتبر البنية التالية كخاصية:
- "عناصر" JSON أو "أزواج قيمة سلسلة مفصولة بـ
:". - عناصر JSON، محددة بواسطة
{و}. - صفائف JSON، محددة بواسطة
[و].
قيود المخطط
القيود التالية قابلة للتطبيق على البيانات التشغيلية في Azure Cosmos DB عند تمكين متجر تحليلي للاستدلال تلقائياً وتمثيل المخطط بشكل صحيح:
يمكنك الحصول على 1000 خاصية كحد أقصى عبر جميع المستويات المتداخلة في مخطط المستند وأقصى عمق تداخل يبلغ 127.
- يتم تمثيل أول 1000 خاصية فقط في متجر التحليل.
- يتم تمثيل أول 127 مستوى متداخل فقط في متجر التحليل.
- المستوى الأول من مستند JSON هو
/مستوى الجذر. - سيتم تمثيل الخصائص في المستوى الأول من المستند كأعمدة.
نماذج السيناريوهات:
- إذا كان المستوى الأول لمستندك يحتوي على 2000 خاصية، فستمثل عملية المزامنة أول 1000 خاصية منها.
- إذا كانت مستنداتك تحتوي على خمسة مستويات تحتوي على 200 خاصية في كل منها، فستمثل عملية المزامنة جميع الخصائص.
- إذا كانت مستنداتك تحتوي على 10 مستويات مع 400 خاصية في كل منها، فإن عملية المزامنة ستمثل بشكل كامل المستويين الأولين ونصف المستوى الثالث فقط.
تحتوي الوثيقة الافتراضية أدناه على أربع خصائص وثلاثة مستويات.
- المستويات هي
root،myArrayوالبنية المتداخلة داخلmyArray. - الخصائص هي
idوmyArrayوmyArray.nested1وmyArray.nested2. - سيتكون تمثيل المخزن التحليلي من عمودين،
idوmyArray. يمكنك استخدام وظائف Spark أو T-SQL لعرض البنيات المتداخلة كأعمدة.
- المستويات هي
{
"id": "1",
"myArray": [
"string1",
"string2",
{
"nested1": "abc",
"nested2": "cde"
}
]
}
في حين أن مستندات JSON (ومجموعات/حاويات Azure Cosmos DB) حساسة لحالة الأحرف من منظور التفرد، فإن المخزن التحليلي ليس كذلك.
-
في نفس المستند: يجب أن تكون أسماء الخصائص في نفس المستوى فريدة عند مقارنتها بعدم حساسية لحالة الأحرف. على سبيل المثال، يحتوي مستند JSON التالي على "Name" و"name" في نفس المستوى. على الرغم من كونه مستندَ JSON صالحاً، إلا أنه لا يفي بقيد التفرد وبالتالي لن يتم تمثيله بالكامل في المخزن التحليلي. في هذا المثال، "Name" و"name" هما نفس الشيء عند المقارنة بطريقة غير حساسة لحالة الأحرف. سيتم تمثيل
"Name": "fred"فقط في المخزن التحليلي، لأنه أول حدث. ولن يتم تمثيل"name": "john"على الإطلاق.
{"id": 1, "Name": "fred", "name": "john"}-
في وثائق مختلفة: سيتم تمثيل الخصائص في نفس المستوى وبنفس الاسم، ولكن في حالات مختلفة، داخل نفس العمود، باستخدام تنسيق اسم التكرار الأول. على سبيل المثال، تحتوي مستندات JSON التالية على
"Name"و"name"في نفس المستوى. بما أن تنسيق المستند الأول هو"Name"، فهذا ما سيتم استخدامه لتمثيل اسم الخاصية في متجر تحليلي. وبعبارة أخرى، سيكون اسم العمود في المتجر التحليلي"Name". سيتم تمثيل"fred"و"john"، في العمود"Name".
{"id": 1, "Name": "fred"} {"id": 2, "name": "john"}-
في نفس المستند: يجب أن تكون أسماء الخصائص في نفس المستوى فريدة عند مقارنتها بعدم حساسية لحالة الأحرف. على سبيل المثال، يحتوي مستند JSON التالي على "Name" و"name" في نفس المستوى. على الرغم من كونه مستندَ JSON صالحاً، إلا أنه لا يفي بقيد التفرد وبالتالي لن يتم تمثيله بالكامل في المخزن التحليلي. في هذا المثال، "Name" و"name" هما نفس الشيء عند المقارنة بطريقة غير حساسة لحالة الأحرف. سيتم تمثيل
يحدد المستند الأول من المجموعة مخطط المتجر التحليلي الأولي.
- ستؤدي المستندات ذات الخصائص أكثر من المخطط الأولي إلى إنشاء أعمدة جديدة في متجر تحليلي.
- لا يمكن إزالة الأعمدة.
- لا يؤدي حذف جميع المستندات في مجموعة إلى إعادة تعيين مخطط المتجر التحليلي.
- لا يوجد تعيين إصدار مخطط. الإصدار الأخير الذي تم استنتاجه من مخزن العمليات هو ما ستراه في المخزن التحليلي.
لا يمكن لـ Azure Synapse Spark حالياً قراءة الخصائص التي تحتوي على بعض الأحرف الخاصة في أسمائهم، المدرجة أدناه. لا يتأثر Azure Synapse SQL دون خادم.
- :
- `
- ,
- ;
- {}
- ()
- \n
- \t
- =
- "
إشعار
يتم أيضاً سرد المسافات البيضاء في رسالة الخطأ Spark التي يتم إرجاعها عندما تصل إلى هذا القيد. لكننا أضفنا معاملة خاصة للمساحات البيضاء، يرجى الاطلاع على مزيد من التفاصيل في العناصر أدناه.
- إذا كانت لديك أسماء خصائص باستخدام الأحرف المذكورة أعلاه، فإن البدائل هي:
- تغيير نموذج البيانات مقدماً لتجنب هذه الأحرف.
- نظراً لأننا لا ندعم حالياً إعادة تعيين المخطط، يمكنك تغيير التطبيق الخاص بك لإضافة خاصية مكررة باسم مشابه، مع تجنب هذه الأحرف.
- استخدم موجز تغيير لإنشاء طريقة عرض تجسد الحاوية دون هذه الأحرف في أسماء الخصائص.
- استخدم الخيار
dropColumnSpark لتجاهل الأعمدة المتأثرة وتحميل جميع الأعمدة الأخرى في DataFrame. يتشكل بناء الجملة من:
# Removing one column:
df = spark.read\
.format("cosmos.olap")\
.option("spark.synapse.linkedService","<your-linked-service-name>")\
.option("spark.synapse.container","<your-container-name>")\
.option("spark.cosmos.dropColumn","FirstName,LastName")\
.load()
# Removing multiple columns:
df = spark.read\
.format("cosmos.olap")\
.option("spark.synapse.linkedService","<your-linked-service-name>")\
.option("spark.synapse.container","<your-container-name>")\
.option("spark.cosmos.dropColumn","FirstName,LastName;StreetName,StreetNumber")\
.option("spark.cosmos.dropMultiColumnSeparator", ";")\
.load()
- يدعم Azure Synapse Spark الآن الخصائص التي تحتوي على مسافات بيضاء في أسمائها. لذلك، تحتاج إلى استخدام الخيار
allowWhiteSpaceInFieldNamesSpark لتحميل الأعمدة المتأثرة في DataFrame، مع الاحتفاظ بالاسم الأصلي. يتشكل بناء الجملة من:
df = spark.read\
.format("cosmos.olap")\
.option("spark.synapse.linkedService","<your-linked-service-name>")\
.option("spark.synapse.container","<your-container-name>")\
.option("spark.cosmos.allowWhiteSpaceInFieldNames", "true")\
.load()
أنواع بيانات BSON التالية غير مدعومة ولن يتم تمثيلها في المخزن التحليلي:
- رقم عشري128
- التعبير العادي
- مؤشر DB
- JavaScript
- الرمز
- MinKey/MaxKey
عند استخدام سلاسل DateTime التي تتبع معيار ISO 8601 UTC، توقع السلوك التالي:
- تمثل تجمعات Spark في Azure Synapse هذه الأعمدة ك
string. - تمثل تجمعات SQL بلا خادم في Azure Synapse هذه الأعمدة ك
varchar(8000).
- تمثل تجمعات Spark في Azure Synapse هذه الأعمدة ك
يتم تمثيل الخصائص ذات أنواع
UNIQUEIDENTIFIER (guid)كـstringفي المخزن التحليلي ويجب تحويلها إلىVARCHARفي SQL أو إلىstringفي Spark للتصور الصحيح.تدعم تجمعات SQL التي لا تحتوي على خادم في Azure Synapse مجموعات النتائج التي تحتوي على ما يصل إلى 1000 عمود، كما يُحتسب عرض الأعمدة المتداخلة ضمن هذا الحد. من الممارسات الجيدة مراعاة هذه المعلومات في بنية بيانات المعاملات والنمذجة.
إذا أعدت تسمية خاصية، في مستند واحد أو أكثر، فسيتم معاملتها بوصفها عموداً جديداً. إذا نفذت نفس إعادة التسمية في جميع المستندات في المجموعة، فسيتم ترحيل جميع البيانات إلى العمود الجديد وسيتم تمثيل العمود القديم بقيم
NULL.
تمثيل المخطط
هناك طريقتان لتمثيل المخطط في المخزن التحليلي، صالحة لجميع الحاويات في حساب قاعدة البيانات. لديهم مفاضلات بين بساطة تجربة الاستعلام مقابل ملاءمة تمثيل عمودي أكثر شمولا للمخططات متعددة الأشكال.
- تمثيل مخطط محدد جيدا، الخيار الافتراضي لواجهة برمجة التطبيقات لحسابات NoSQL وGremlin.
- تمثيل مخطط الدقة الكامل، الخيار الافتراضي لواجهة برمجة التطبيقات لحسابات MongoDB.
تمثيل مخطط محدد جيدًا
يقوم تمثيل المخطط المحدد بإنشاء تمثيل جدولي بسيط من بيانات المخطط المحايد في متجر المعاملات. يتضمن تمثيل المخطط المحدد جيداً الاعتبارات التالية:
- يحدد المستند الأول المخطط الأساسي ويجب أن يكون للخصائص دائما نفس النوع عبر جميع المستندات. الاستثناءات الوحيدة هي:
- بالنسبة إلى تجمعات SQL بلا خادم في Azure Synapse: من
NULLإلى أي نوع بيانات آخر. يحدد التواجد الأول غير الفارغ نوع بيانات العمود. لن يتم تمثيل أي مستند لا يتبع نوع البيانات غير الخالي الأول في المتجر التحليلي. - بالنسبة لتجمعات Spark وAzure Data Factory Change Data Capture في Azure Synapse: من
NULLإلىINT. التطور من خصائص فارغة إلى أنواع بيانات أخرى غير INT غير مدعوم لتجمعات Spark وAzure Data Factory Change Data Capture في Azure Synapse. يجب أن تكون القيمة الأولى غير الفارغة عددا صحيحا، ولن يتم تمثيل أي مستند ذي نوع بيانات مختلف في المخزن التحليلي. - من
floatإلىinteger. يتم تمثيل جميع المستندات في مخزن تحليلي. - من
integerإلىfloat. يتم تمثيل جميع المستندات في مخزن تحليلي. ومع ذلك، لقراءة هذه البيانات عبر تجمعات Azure Synapse SQL دون خادم، يجب استخدام جملة WITH لتحويل العمود إلىvarchar. وبعد هذا التحويل الأولي، يمكن تحويله مرة أخرى إلى رقم. يرجى التحقق من المثال أدناه، حيث إن قيمة الرقم الأولية كانت عدداً صحيحاً والثاني كان حُراً.
- بالنسبة إلى تجمعات SQL بلا خادم في Azure Synapse: من
SELECT CAST (num as float) as num
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<account-name>;Database=<database-name>;Region=<region-name>',
OBJECT = '<container-name>',
[ CREDENTIAL | SERVER_CREDENTIAL ] = '<credential-name>'
)
WITH (num varchar(100)) AS [IntToFloat]
لن يتم تمثيل الخصائص التي لا تتبع نوع بيانات المخطط الأساسي في المتجر التحليلي. على سبيل المثال، ضع في اعتبارك المستندات أدناه: حددت الوثيقة الأولى مخطط قاعدة المخزن التحليلي. المستند الثاني، حيث يكون
idهو"2"، لا يحتوي على مخطط محدد جيداً لأن الخاصية"code"عبارة عن سلسلة والمستند الأول به"code"على هيئة رقم. في هذه الحالة، يسجل متجر التحليل نوع البيانات"code"كـintegerلعمر الحاوية. سيستمر تضمين المستند الثاني في المخزن التحليلي، ولكن لن يتم تضمين الخاصية"code"الخاصة به.{"id": "1", "code":123}{"id": "2", "code": "123"}
إشعار
لا يطبق الشرط أعلاه على خصائص NULL. على سبيل المثال، لا يزال {"a":123} and {"a":NULL} محدداً جيداً.
إشعار
لا يتغير الشرط أعلاه إذا قمت بتحديث "code" المستند "1" إلى سلسلة في مخزن العمليات الخاص بك. في المخزن التحليلي، سيتم الاحتفاظ بـ "code" على هيئة integer نظراً لأننا لا ندعم حالياً إعادة تعيين المخطط.
- ينبغي أن تحتوي أنواع الصفيف على نوع واحد متكرر. على سبيل المثال،
{"a": ["str",12]}ليس مخططاً محدداً جيداً لأن المصفوفة تحتوي على مزيج من الأعداد الصحيحة وأنواع السلاسل.
إشعار
إذا كان المخزن التحليلي Azure Cosmos DB يتبع تمثيل المخطط المحدد جيداً وانتهكت المواصفات المذكورة أعلاه بواسطة عناصر معينة، فلن يتم تضمين هذه العناصر في المخزن التحليلي.
توقع سلوكاً مختلفاً فيما يتعلق بأنواع مختلفة في مخطط محدد جيداً:
- تمثل تجمعات Spark في Azure Synapse هذه القيم ك
undefined. - تمثل تجمعات SQL بلا خادم في Azure Synapse هذه القيم ك
NULL.
- تمثل تجمعات Spark في Azure Synapse هذه القيم ك
توقع سلوك مختلف فيما يتعلق بالقيم
NULLالصريحة:- تقرأ تجمعات Spark في Azure Synapse هذه القيم ك
0(صفر)، وبمجردundefinedأن يحتوي العمود على قيمة غير خالية. - تقرأ تجمعات SQL بلا خادم في Azure Synapse هذه القيم ك
NULL.
- تقرأ تجمعات Spark في Azure Synapse هذه القيم ك
توقع سلوك مختلف فيما يتعلق بالأعمدة المفقودة:
- تمثل تجمعات Spark في Azure Synapse هذه الأعمدة ك
undefined. - تمثل تجمعات SQL بلا خادم في Azure Synapse هذه الأعمدة ك
NULL.
- تمثل تجمعات Spark في Azure Synapse هذه الأعمدة ك
حلول تحديات التمثيل
من الممكن استخدام مستند قديم، مع مخطط غير صحيح، لإنشاء مخطط قاعدة مخزن تحليلي للحاوية. استنادا إلى جميع القواعد المعروضة أعلاه، قد تتلقى NULL خصائص معينة عند الاستعلام عن متجرك التحليلي باستخدام Azure Synapse Link. لن يساعد حذف المستندات المسببة للمشاكل أو تحديثها لأن إعادة تعيين المخطط الأساسي غير مدعومة حاليا. الحلول الممكنة هي:
- لترحيل البيانات إلى حاوية جديدة، تأكد من أن جميع المستندات تحتوي على المخطط الصحيح.
- للتخلي عن الخاصية مع المخطط الخطأ وإضافة مخطط جديد باسم آخر يحتوي على المخطط الصحيح في جميع المستندات. مثال: لديك مليارات المستندات في حاوية الطلبات حيث تكون خاصية الحالة سلسلة. ولكن المستند الأول في تلك الحاوية له حالة معرفة مع عدد صحيح. لذلك، سيكون لمستند واحد حالة ممثلة بشكل صحيح وستمتلك
NULLجميع المستندات الأخرى . يمكنك إضافة الخاصية status2 إلى جميع المستندات والبدء في استخدامها، بدلا من الخاصية الأصلية.
تمثيل مخطط الدقة الكاملة
تم تصميم تمثيل مخطط الدقة الكامل لمعالجة الاتساع الكامل للمخططات متعددة الأشكال في البيانات التشغيلية ذات المخططات المحايدة. في تمثيل المخطط هذا، لا يتم إسقاط أي عناصر من المتجر التحليلي حتى إذا تم انتهاك قيود المخطط المحدد جيداً (التي ليست حقول أنواع بيانات مختلطة أو صفائف أنواع بيانات المختلطة).
ويتحقق ذلك عن طريق ترجمة خصائص الكائن الطرفي للبيانات التشغيلية إلى المخزن التحليلي كأزواج JSON key-value ، حيث يكون نوع البيانات هو key ومحتوى الخاصية valueهو . يسمح تمثيل كائن JSON هذا بالاستعلامات دون غموض، ويمكنك تحليل كل نوع بيانات بشكل فردي.
بمعنى آخر، في تمثيل مخطط الدقة الكامل، سينشئ كل نوع بيانات لكل خاصية من كل مستند زوجا key-valueفي كائن JSON لتلك الخاصية. كل واحد منهم يعد واحدا من حد الخصائص الأقصى البالغ 1000.
على سبيل المثال، لنأخذ نموذج المستند التالي في مخزن العمليات:
{
name: "John Doe",
age: 32,
profession: "Doctor",
address: {
streetNo: 15850,
streetName: "NE 40th St.",
zip: 98052
},
salary: 1000000
}
الكائن address المتداخل هو خاصية في المستوى الجذر للمستند وسيتم تمثيله ك عمود. سيتم تمثيل كل خاصية طرفية address في الكائن ككائن JSON: {"object":{"streetNo":{"int32":15850},"streetName":{"string":"NE 40th St."},"zip":{"int32":98052}}}.
على عكس تمثيل المخطط المحدد جيدا، يسمح أسلوب الدقة الكامل بالتباين في أنواع البيانات. إذا كان المستند التالي في هذه المجموعة من المثال أعلاه يحتوي streetNo على كسلسلة، تمثيله في المخزن التحليلي ك "streetNo":{"string":15850}. في أسلوب المخطط المحدد جيدا، لن يتم تمثيله.
مخطط أنواع البيانات لمخطط الدقة الكامل
فيما يلي خريطة أنواع بيانات MongoDB وتمثيلاتها في المخزن التحليلي بتمثيل مخطط الدقة الكاملة. الخريطة أدناه غير صالحة لحسابات NoSQL API.
| نوع البيانات الأصلي | اللاحقة | مثال |
|---|---|---|
| مزدوج | ".float64" | 24.99 |
| صفيف | "صفيف" | ["a", "b"] |
| ثنائي | "ثنائي" | 1 |
| قيمة منطقية | ".bool" | صواب |
| Int32 | ".int32" | 123 |
| int64 | ".int64" | 255486129307 |
| قيمة فارغة | ". NULL" | قيمة فارغة |
| السلسلة | "سلسلة" | "ABC" |
| طابع زمني | ".الطابع الزمني" | الطابع الزمني (0, 0) |
| معرف الكائن | "معرف الكائن" | ObjectId("5f3f7b59330ec25c132623a2") |
| مستند | "كائن" | {"a": "a"} |
توقع سلوك مختلف فيما يتعلق بالقيم
NULLالصريحة:- تجمعات Spark في Azure Synapse ستقرأ هذه القيم كـ
0(صفر). - تجمعات SQL دون خادم في Azure Synapse ستقرأ هذه القيم كـ
NULL.
- تجمعات Spark في Azure Synapse ستقرأ هذه القيم كـ
توقع سلوك مختلف فيما يتعلق بالأعمدة المفقودة:
- تجمعات Spark في Azure Synapse ستمثل هذه الأعمدة كـ
undefined. - تجمعات SQL دون خادم في Azure Synapse ستمثل هذه الأعمدة كـ
NULL.
- تجمعات Spark في Azure Synapse ستمثل هذه الأعمدة كـ
توقع سلوكا مختلفا فيما يتعلق بالقيم
timestamp:- ستقرأ تجمعات Spark في Azure Synapse هذه القيم ك
TimestampTypeأوDateTypeأو .Floatيعتمد ذلك على النطاق وكيفية إنشاء الطابع الزمني. - ستقرأ تجمعات SQL Serverless في Azure Synapse هذه القيم ك
DATETIME2، بدءا من0001-01-01خلال9999-12-31. القيم التي تتجاوز هذا النطاق غير مدعومة وستتسبب في فشل تنفيذ استعلاماتك. إذا كانت هذه هي حالتك، يمكنك:- إزالة العمود من الاستعلام. للاحتفاظ بالتمثيل، يمكنك إنشاء خاصية جديدة تعكس هذا العمود ولكن ضمن النطاق المدعوم. واستخدمه في استعلاماتك.
- استخدم Change Data Capture من المخزن التحليلي، بدون تكلفة وحدات الطلب، لتحويل البيانات وتحميلها إلى تنسيق جديد، داخل أحد المتلقيات المدعومة.
- ستقرأ تجمعات Spark في Azure Synapse هذه القيم ك
استخدام مخطط الدقة الكامل مع Spark
سيقوم Spark بإدارة كل نوع بيانات ك عمود عند التحميل في DataFrame. لنفترض وجود مجموعة تحتوي على المستندات أدناه.
{
"_id" : "1" ,
"item" : "Pizza",
"price" : 3.49,
"rating" : 3,
"timestamp" : 1604021952.6790195
},
{
"_id" : "2" ,
"item" : "Ice Cream",
"price" : 1.59,
"rating" : "4" ,
"timestamp" : "2022-11-11 10:00 AM"
}
بينما يحتوي rating المستند الأول على رقم وتنسيق timestamp utc، فإن المستند الثاني يحتوي rating على و timestamp كسلاسل. بافتراض أن هذه المجموعة تم تحميلها في DataFrame دون أي تحويل للبيانات، فإن إخراج df.printSchema() هو:
root
|-- _rid: string (nullable = true)
|-- _ts: long (nullable = true)
|-- id: string (nullable = true)
|-- _etag: string (nullable = true)
|-- _id: struct (nullable = true)
| |-- objectId: string (nullable = true)
|-- item: struct (nullable = true)
| |-- string: string (nullable = true)
|-- price: struct (nullable = true)
| |-- float64: double (nullable = true)
|-- rating: struct (nullable = true)
| |-- int32: integer (nullable = true)
| |-- string: string (nullable = true)
|-- timestamp: struct (nullable = true)
| |-- float64: double (nullable = true)
| |-- string: string (nullable = true)
|-- _partitionKey: struct (nullable = true)
| |-- string: string (nullable = true)
في تمثيل المخطط المحدد جيدا، لن يتم تمثيل كل rating من المستند الثاني و timestamp . في مخطط الدقة الكاملة، يمكنك استخدام الأمثلة التالية للوصول بشكل فردي إلى كل قيمة لكل نوع بيانات.
في المثال أدناه، يمكننا استخدام PySpark لتشغيل تجميع:
df.groupBy(df.item.string).sum().show()
في المثال أدناه، يمكننا استخدام PySQL لتشغيل تجميع آخر:
df.createOrReplaceTempView("Pizza")
sql_results = spark.sql("SELECT sum(price.float64),count(*) FROM Pizza where timestamp.string is not null and item.string = 'Pizza'")
sql_results.show()
استخدام مخطط الدقة الكامل مع SQL
يمكنك استخدام مثال بناء الجملة التالي، مع نفس مستندات مثال Spark أعلاه:
SELECT rating,timestamp_string,timestamp_utc
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<account-name>;Database=<database-name>;Region=<region-name>',
OBJECT = '<container-name>',
[ CREDENTIAL | SERVER_CREDENTIAL ] = '<credential-name>'
) WITH (
rating integer '$.rating.int32',
timestamp varchar(50) '$.timestamp.string',
timestamp_utc float '$.timestamp.float64'
) as HTAP
WHERE timestamp is not null or timestamp_utc is not null
يمكنك تنفيذ التحويلات باستخدام cast، convert أو أي دالة T-SQL أخرى لمعالجة بياناتك. يمكنك أيضا إخفاء بنيات أنواع البيانات المعقدة باستخدام طرق العرض.
create view MyView as
SELECT MyRating=rating,MyTimestamp = convert(varchar(50),timestamp_utc)
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<account-name>;Database=<database-name>;Region=<region-name>',
OBJECT = '<container-name>',
[ CREDENTIAL | SERVER_CREDENTIAL ] = '<credential-name>'
) (
rating integer '$.rating.int32',
timestamp_utc float '$.timestamp.float64'
) as HTAP
WHERE timestamp_utc is not null
union all
SELECT MyRating=convert(integer,rating_string),MyTimestamp = timestamp_string
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<account-name>;Database=<database-name>;Region=<region-name>',
OBJECT = '<container-name>',
[ CREDENTIAL | SERVER_CREDENTIAL ] = '<credential-name>'
) WITH (
rating_string varchar(50) '$.rating.string',
timestamp_string varchar(50) '$.timestamp.string'
) as HTAP
WHERE timestamp_string is not null
العمل مع حقل MongoDB _id
يعد حقل MongoDB _id أساسيا لكل مجموعة في MongoDB ويحتوي في الأصل على تمثيل سداسي عشري. كما ترى في الجدول أعلاه، سيحافظ مخطط الدقة الكاملة على خصائصه، ما يخلق تحديا لتصوره في Azure Synapse Analytics. للتصور الصحيح، يجب تحويل نوع البيانات _id كما يلي:
العمل مع حقل MongoDB _id في Spark
يعمل المثال أدناه على إصدارات Spark 2.x و3.x:
val df = spark.read.format("cosmos.olap").option("spark.synapse.linkedService", "xxxx").option("spark.cosmos.container", "xxxx").load()
val convertObjectId = udf((bytes: Array[Byte]) => {
val builder = new StringBuilder
for (b <- bytes) {
builder.append(String.format("%02x", Byte.box(b)))
}
builder.toString
}
)
val dfConverted = df.withColumn("objectId", col("_id.objectId")).withColumn("convertedObjectId", convertObjectId(col("_id.objectId"))).select("id", "objectId", "convertedObjectId")
display(dfConverted)
العمل مع حقل MongoDB _id في SQL
SELECT TOP 100 id=CAST(_id as VARBINARY(1000))
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=<account-name>;Database=<database-name>;Region=<region-name>',
OBJECT = '<container-name>',
[ CREDENTIAL | SERVER_CREDENTIAL ] = '<credential-name>'
HTAP) WITH (_id VARCHAR(1000)) as HTAP
العمل مع حقل MongoDB id
id يتم تجاوز الخاصية في حاويات MongoDB تلقائيا مع تمثيل Base64 للخاصية "_id" في كل من المخزن التحليلي. حقل "المعرف" مخصص للاستخدام الداخلي من قبل تطبيقات MongoDB. حاليا، الحل البديل الوحيد هو إعادة تسمية خاصية "المعرف" إلى شيء آخر غير "المعرف".
مخطط الدقة الكامل لواجهة برمجة التطبيقات لحسابات NoSQL أو Gremlin
من الممكن استخدام مخطط الدقة الكامل لواجهة برمجة التطبيقات لحسابات NoSQL، بدلا من الخيار الافتراضي، عن طريق تعيين نوع المخطط عند تمكين Synapse Link على حساب Azure Cosmos DB للمرة الأولى. فيما يلي الاعتبارات حول تغيير نوع تمثيل المخطط الافتراضي:
- حاليا، إذا قمت بتمكين Synapse Link في حساب NoSQL API الخاص بك باستخدام مدخل Microsoft Azure، تمكينه كمخطط محدد جيدا.
- حاليا، إذا كنت ترغب في استخدام مخطط الدقة الكامل مع حسابات NoSQL أو Gremlin API، يجب عليك تعيينه على مستوى الحساب في نفس أمر CLI أو PowerShell الذي سيمكن Synapse Link على مستوى الحساب.
- لا يتوافق Azure Cosmos DB ل MongoDB حاليا مع إمكانية تغيير تمثيل المخطط. تحتوي جميع حسابات MongoDB على نوع تمثيل مخطط الدقة الكامل.
- خريطة أنواع بيانات مخطط الدقة الكاملة المذكورة أعلاه غير صالحة لحسابات NoSQL API التي تستخدم أنواع بيانات JSON. على سبيل المثال،
floatيتم تمثيل القيم كماintegerهو الحالnumفي المخزن التحليلي. - لا يمكن إعادة تعيين نوع تمثيل المخطط، من الدقة المحددة جيدا إلى الدقة الكاملة أو العكس.
- حاليا، يتم تعريف مخططات الحاويات في المخزن التحليلي عند إنشاء الحاوية، حتى إذا لم يتم تمكين Synapse Link في حساب قاعدة البيانات.
- الحاويات أو الرسوم البيانية التي تم إنشاؤها قبل تمكين Synapse Link مع مخطط الدقة الكاملة على مستوى الحساب سيكون لها مخطط محدد جيدا.
- سيكون للحاويات أو الرسوم البيانية التي تم إنشاؤها بعد تمكين Synapse Link مع مخطط الدقة الكاملة على مستوى الحساب مخطط كامل الدقة.
يجب أن يتم اتخاذ قرار نوع تمثيل المخطط في نفس وقت تمكين ارتباط Synapse على الحساب، وذلك باستخدام Azure CLI أو PowerShell.
مع Azure CLI:
az cosmosdb create --name MyCosmosDBDatabaseAccount --resource-group MyResourceGroup --subscription MySubscription --analytical-storage-schema-type "FullFidelity" --enable-analytical-storage true
إشعار
في الأمر أعلاه، استبدل create بـ update بالحسابات الموجودة.
مع PowerShell:
New-AzCosmosDBAccount -ResourceGroupName MyResourceGroup -Name MyCosmosDBDatabaseAccount -EnableAnalyticalStorage true -AnalyticalStorageSchemaType "FullFidelity"
إشعار
في الأمر أعلاه، استبدل New-AzCosmosDBAccount بـ Update-AzCosmosDBAccount بالحسابات الموجودة.
مدة البقاء التحليلية (TTL)
يشير TTL التحليلي (ATTL) إلى المدة التي يجب الاحتفاظ فيها بالبيانات في مخزنك التحليلي، للحاوية.
يتم تمكين المخزن التحليلي عند تعيين ATTL بقيمة أخرى غير NULL و0. عند التمكين، تتم مزامنة الإدخالات والتحديثات والحذف إلى البيانات المشغلة تلقائياً من مخزن العمليات إلى المخزن التحليلي، بغض النظر عن تكوين TTL للعمليات (TTTL). يمكن التحكم في الاحتفاظ بهذه البيانات للعمليات في المخزن التحليلي على مستوى الحاوية بواسطة خاصية AnalyticalStoreTimeToLiveInSeconds.
تكوينات ATTL المحتملة هي:
إذا تم تعيين القيمة إلى
0: يتم تعطيل المخزن التحليلي ولا يتم نسخ أي بيانات من مخزن المعاملات إلى المخزن التحليلي. يرجى فتح حالة دعم لتعطيل المخزن التحليلي في حاوياتك.إذا تم حذف الحقل، فلن يحدث أي شيء ويتم الاحتفاظ بالقيمة السابقة.
إذا تم تعيين القيمة على
-1: يحتفظ المخزن التحليلي بجميع البيانات السابقة، بغض النظر عن الاحتفاظ بالبيانات في مخزن العمليات. يشير هذا الإعداد إلى أن المتجر التحليلي يحتوي على احتفاظ لا نهائي ببيانات التشغيل الخاصة بكإذا تم تعيين القيمة على أي عدد صحيح موجب
n: ستنتهي صلاحية العناصر من المخزن التحليلي بعدnثانية من وقت آخر تعديل لها في مخزن العمليات. يمكن الاستفادة من هذا الإعداد إذا كنت ترغب في الاحتفاظ ببيانات التشغيل الخاصة بك لفترة محدودة من الوقت في متجر التحليل، بغض النظر عن الاحتفاظ بالبيانات في متجر المعاملات
بعض النقاط التي يجب مراعاتها:
- بعد تمكين المخزن التحليلي بقيمة ATTL، يمكن تحديثه إلى قيمة صالحة مختلفة لاحقاً.
- بينما يمكن تعيين TTTL على مستوى الحاوية أو العنصر، لا يمكن تعيين ATTL إلا على مستوى الحاوية حالياً.
- يمكنك تحقيق استبقاء أطول لبياناتك التشغيلية في المخزن التحليلي عن طريق ضبط ATTL >= TTTL على مستوى الحاوية.
- يمكن إجراء المخزن التحليلي لعكس مخزن العمليات عن طريق تعيين ATTL = TTTL.
- إذا كان لديك ATTL أكبر من TTTL، في وقت ما سيكون لديك بيانات موجودة فقط في المخزن التحليلي. هذه البيانات للقراءة فقط.
- حاليا لا نحذف أي بيانات من مخزن تحليلي. إذا قمت بتعيين ATTL إلى أي عدد صحيح موجب، فلن يتم تضمين البيانات في استعلاماتك ولن تتم محاسبتك عليها. ولكن إذا قمت بتغيير ATTL مرة أخرى إلى
-1، فستظهر جميع البيانات مرة أخرى، ستبدأ في الفوترة لجميع وحدات تخزين البيانات.
كيفية تمكين متجر تحليلي على حاوية:
من مدخل Microsoft Azure، يتم تعيين خيار ATTL، عند تشغيله، على القيمة الافتراضية -1. يمكنك تغيير هذه القيمة إلى 'n' ثانية، عن طريق التنقل إلى إعدادات الحاوية ضمن مستكشف البيانات.
من Azure Management SDK أو Azure Cosmos DB SDKs أو PowerShell أو Azure CLI، يمكن تمكين خيار ATTL عن طريق تعيينه على -1 أو 'n' ثانية.
لمعرفة المزيد، راجع كيفية تكوين TTL التحليلي على حاوية.
تحليلات فعالة من حيث التكلفة على البيانات التاريخية
يشير تدرج البيانات إلى فصل البيانات بين البنية الأساسية للتخزين المحسنة لسيناريوهات مختلفة. وبالتالي، تحسين الأداء العام والفعالية من حيث التكلفة لمكدس ذاكرة البيانات المؤقتة بشكل شامل. يدعم Azure Cosmos DB عبر المتجر التحليلي الآن التدرج التلقائي للبيانات من متجر المعاملات إلى المتجر التحليلي عبر تخطيطات البيانات المختلفة. يتيح لك المتجر التحليلي المُحسن من حيث تكلفة التخزين مقارنة بمتجر المعاملات بالاحتفاظ بآفاق أطول بكثير من البيانات التشغيلية للتحليل التاريخي.
بعد تمكين المخزن التحليلي، بناءً على احتياجات استبقاء البيانات لأحمال العمل الخاصة بالعمليات، يمكنك تكوين خاصية transactional TTL بحيث يتم حذف السجلات تلقائياً من مخزن العمليات بعد فترة زمنية معينة. وبالمثل، يتيح لك analytical TTL إدارة دورة حياة البيانات المحفوظة في المخزن التحليلي بشكل مستقل عن مخزن العمليات. من خلال تمكين المتجر التحليلي وتكوين خصائص TTL المتعلقة بالمعاملات والخصائص التحليلية، يمكنك بسهولة تقسيم وتحديد فترة الاحتفاظ بالبيانات للمتجرين.
إشعار
عند analytical TTL تعيين إلى قيمة أكبر من transactional TTL القيمة، سيكون للحاوية بيانات موجودة فقط في المخزن التحليلي. يجري قراءة هذه البيانات فقط ولا ندعم حاليا مستوى المستند TTL في المخزن التحليلي. إذا كانت بيانات الحاوية قد تحتاج إلى تحديث أو حذف في وقت ما في المستقبل، فلا تستخدم analytical TTL أكبر من transactional TTL. يوصى بهذه الإمكانية للبيانات التي لن تحتاج إلى تحديثات أو حذف في المستقبل.
إشعار
إذا لم يتطلب السيناريو الخاص بك عمليات حذف فعلية، يمكنك اعتماد نهج حذف/تحديث منطقي. أدرج في مخزن المعاملات إصدارًا آخر من نفس المستند موجود فقط في المخزن التحليلي ولكنه يحتاج إلى نهج حذف / تحديث منطقي. ربما بعلامة تشير إلى أنه حذف أو تحديث لمستند منتهي الصلاحية. سيتواجد كلا الإصدارين من نفس المستند معًا في المتجر التحليلي، ويجب أن يراعي تطبيقك الإصدار الأخير فقط.
المرونة
يعتمد المتجر التحليلي على Azure Storage ويوفر الحماية التالية ضد الفشل الفعلي:
- بشكل افتراضي، تخصص حسابات قاعدة بيانات Azure Cosmos DB مخزنا تحليليا في حسابات التخزين المكرر محليا (LRS). يوفر LRS ما لا يقل عن 99.999999999% (11 تسعة) من القدرة على الصمود للأشياء خلال سنة معينة.
- إذا تم تكوين أي منطقة جغرافية لحساب قاعدة البيانات لتكرار المنطقة، يتم تخصيصها في حسابات التخزين المتكرر للمنطقة (ZRS). تحتاج إلى تمكين مناطق التوفر على منطقة من حساب قاعدة بيانات Azure Cosmos DB الخاص بها للحصول على بيانات تحليلية لتلك المنطقة مخزنة في مساحة تخزين زائدة عن الحاجة في المنطقة. يوفر ZRS متانة لموارد التخزين لا تقل عن 99.9999999999٪ (12 9) خلال سنة معينة.
لمزيد من المعلومات حول متانة تخزين Azure، راجع هذا الارتباط.
نسخة احتياطية
على الرغم من أن المخزن التحليلي يحتوي على حماية مضمنة ضد الأعطال المادية، إلا أن النسخ الاحتياطي يمكن أن يكون ضروريًا للحذف أو التحديث العرضي في مخزن المعاملات. في هذه الحالات، يمكنك استعادة حاوية واستخدام الحاوية المستعادة لإعادة تعبئة البيانات الموجودة في الحاوية الأصلية، أو إعادة إنشاء المخزن التحليلي بالكامل إذا لزم الأمر.
إشعار
لا يتم حاليًا نسخ المخزن التحليلي احتياطيًا، لذلك لا يمكن استعادته. لا يمكن التخطيط سياسة النسخ الاحتياطي الخاصة بك بالاعتماد على ذلك.
يحتوي Synapse Link والمخزن التحليلي وفقا لذلك على مستويات توافق مختلفة مع أوضاع النسخ الاحتياطي ل Azure Cosmos DB:
- وضع النسخ الاحتياطي الدوري متوافق تماماً مع Synapse Link ويمكن استخدام هاتين الميزتين في نفس حساب قاعدة البيانات.
- رابط Synapse لحسابات قاعدة البيانات باستخدام وضع النسخ الاحتياطي المستمر هو GA.
- وضع النسخ الاحتياطي المستمر للحسابات الممكنة ل Synapse Link في المعاينة العامة. حاليا، لا يمكنك الترحيل إلى النسخ الاحتياطي المستمر إذا قمت بتعطيل Synapse Link على أي من مجموعاتك في حساب Cosmos DB.
سياسات النسخ الاحتياطي
هناك نهجان محتملان للنسخ الاحتياطي وفهم كيفية استخدامها، التفاصيل التالية حول النسخ الاحتياطية ل Azure Cosmos DB مهمة جدا:
- تتم استعادة الحاوية الأصلية بدون مخزن تحليلي في كلا وضعي النسخ الاحتياطي.
- لا يدعم Azure Cosmos DB الحاويات الكتابة فوقها من الاستعادة.
لنرَ الآن كيفية استخدام النسخ الاحتياطي والاستعادة من منظور المخزن التحليلي.
استعادة حاوية باستخدام TTTL >= ATTL
عندما تكون transactional TTL متساوية أو أكبر من analytical TTL، فإن جميع البيانات في المخزن التحليلي لا تزال موجودة في مخزن المعاملات. في حالة الاستعادة، لديك حالتان محتملتان:
- لاستخدام الحاوية المستعادة كبديل للحاوية الأصلية. لإعادة إنشاء المخزن التحليلي، ما عليك سوى تمكين Synapse Link على مستوى الحساب ومستوى الحاوية.
- لاستخدام الحاوية المستعادة كمصدر بيانات لإعادة تعبئة البيانات الموجودة في الحاوية الأصلية أو تحديثها. في هذه الحالة، سيعكس المخزن التحليلي تلقائيًا عمليات البيانات.
استعادة حاوية باستخدام TTTL < ATTL
عندما يكون transactional TTL أصغر من analytical TTL، توجد بعض البيانات فقط في المخزن التحليلي ولن تكون في الحاوية المستعادة. مرة أخرى، لديك حالتان محتملتان:
- لاستخدام الحاوية المستعادة كبديل للحاوية الأصلية. في هذه الحالة ، عند تمكين Synapse Link على مستوى الحاوية، سيتم تضمين البيانات الموجودة في مخزن المعاملات فقط في المخزن التحليلي الجديد. لكن يُرجى ملاحظة أن المخزن التحليلي للحاوية الأصلية يظل متاحًا للاستعلامات طالما أن الحاوية الأصلية موجودة. قد ترغب في تغيير التطبيق للاستعلام عن كليهما.
- لاستخدام الحاوية المستعادة كمصدر بيانات لإعادة تعبئة البيانات الموجودة في الحاوية الأصلية أو تحديثها:
- سيعكس المخزن التحليلي تلقائيًا عمليات البيانات للبيانات الموجودة في مخزن المعاملات.
- إذا قمت بإعادة إدراج البيانات التي تمت إزالتها مسبقا من مخزن المعاملات بسبب
transactional TTL، فسيتم تكرار هذه البيانات في المخزن التحليلي.
مثال:
- تم تعيين TTTL للحاوية
OnlineOrdersعلى شهر واحد وتعيين ATTL لمدة عام واحد. - عند استعادته إلى
OnlineOrdersNewوتشغيل المخزن التحليلي لإعادة بنائه، سيكون هناك شهر واحد فقط من البيانات في كل من مخزن العمليات والتحليل. - لم يتم حذف الحاوية الأصلية
OnlineOrdersولا يزال مخزنها التحليلي متاحاً. - يتم نقل البيانات الجديدة إلى
OnlineOrdersNewفقط. - ستعمل الاستعلامات التحليلية على إجراء UNION ALL من المتاجر التحليلية بينما لا تزال البيانات الأصلية ذات صلة.
إذا كنت تريد حذف الحاوية الأصلية ولكن لا تريد أن تفقد بيانات المخزن التحليلية، يمكنك الاستمرار في المخزن التحليلي للحاوية الأصلية في خدمة بيانات Azure أخرى. لدى Synapse Analytics القدرة على ضم البيانات المخزنة في مواقع مختلفة. مثال: يجمع استعلام Synapse Analytics بيانات المخزن التحليلية مع الجداول الخارجية الموجودة في Azure Blob Storage وAzure Data Lake Store وما إلى ذلك.
من المهم ملاحظة أن البيانات الموجودة في المخزن التحليلي لها مخطط مختلف عن الموجودة في مخزن العمليات. بينما يمكنك إنشاء لقطات لبيانات مخزنك التحليلي، وتصديرها إلى أي خدمة بيانات Azure، بدون تكاليف RU، لا يمكننا ضمان استخدام هذه اللقطة لإعادة تغذية مخزن العمليات. هذه العملية غير مدعومة.
التوزيع العالمي
إذا كان لديك حساب Azure Cosmos DB موزع عالمياً، وبعد تمكينك للمتجر التحليلي لحاوية، فإنه سيكون متوفرا في جميع مناطق هذا الحساب. وتتكرر جميع التغييرات في البيانات التشغيلية على الصعيد العالمي في جميع المناطق. يمكنك تشغيل الاستعلامات التحليلية بشكل فعال وفق أقرب نسخة إقليمية من بياناتك في Azure Cosmos DB.
التقسيم
يعد تقسيم المخزن التحليلي مستقلاً تماماً عن التقسيم في مخزن العمليات. افتراضياً، لا يتم تقسيم البيانات الموجودة في المخزن التحليلي. إذا كانت الاستعلامات التحليلية الخاصة بك تستخدم عوامل التصفية بشكل متكرر، فلديك خيار التقسيم استناداً إلى هذه الحقول للحصول على استعلام أفضل. لمعرفة المزيد، راجع مقدمة عن التقسيم المخصص وكيفية تكوين التقسيم المخصص.
الأمان
المصادقة مع المخزن التحليلي - تختلف أساليب المصادقة المدعومة بناء على ما إذا كانت ميزات الشبكات ممكنة أم لا.
المصادقة المستندة إلى المفتاح: يتم دعم هذا السيناريو لجميع الحسابات في جميع السيناريوهات، بما في ذلك تلك التي لم يتم تمكين نقاط النهاية الخاصة أو VNet.
كيان الخدمة أو الهوية المدارة: يتم دعم استخدام معرف Entra أو مصادقة الهوية المدارة فقط للحسابات التي لا تستخدم نقاط النهاية الخاصة أو تمكن الوصول إلى Vnet. لاستخدام هذا النوع من المصادقة، يجب على المستخدمين تطبيق RBAC لمستوى البيانات وإنشاء دور جديد للقراءة فقط مع إجراءات البيانات هذه أدناه.
- إضافة MyAnalyticsReadOnlyRole مخصص باستخدام PowerShell وتعيين إجراءات التحكم في الوصول استنادا إلى الدور "readMetadata" و"readAnalytics" RBAC.
$resourceGroupName = "<myResourceGroup>" $accountName = "<myCosmosAccount>" New-AzCosmosDBSqlRoleDefinition -AccountName $accountName ` -ResourceGroupName $resourceGroupName ` -Type CustomRole -RoleName 'MyAnalyticsReadOnlyRole' ` -DataAction @( ` 'Microsoft.DocumentDB/databaseAccounts/readMetadata', 'Microsoft.DocumentDB/databaseAccounts/readAnalytics' ) ` -AssignableScope "/"- سرد تعريفات الدور للحساب للحصول على معرف تعريف الدور الجديد.
$roleDefinitionId = Get-AzCosmosDBSqlRoleDefinition -AccountName $accountName ` -ResourceGroupName $resourceGroupName- إنشاء تعيين الدور عن طريق تعيين الدور الجديد إلى Synapse MSI Principal.
$synapsePrincipalId = "<Synapse MSI Principal>" New-AzCosmosDBSqlRoleAssignment -AccountName $accountName ` -ResourceGroupName $resourceGroupName ` -RoleDefinitionId $readOnlyRoleDefinitionId ` -Scope "/" ` -PrincipalId $synapsePrincipalId
عزل الشبكة باستخدام نقاط النهاية الخاصة - يمكنك التحكم في وصول الشبكة إلى البيانات في مخازن العمليات والتحليل بشكل مستقل. يتم عزل الشبكة باستخدام نقاط نهاية خاصة مدارة منفصلة لكل مخزن، داخل الشبكات الظاهرية المدارة في مساحات عمل Azure Synapse. لمعرفة المزيد، راجع كيفية تكوين نقاط النهاية الخاصة لمقالة المخزن التحليلي. ملاحظة: يجب استخدام المصادقة المستندة إلى المفتاح عند تمكين هذا. راجع القسم السابق.
تشفير البيانات الثابتة - يتم تمكين تشفير المخزن التحليلي بشكل افتراضي.
تشفير البيانات باستخدام المفاتيح المدارة من قبل العملاء - يمكنك تشفير البيانات بسلاسة عبر مخازن المعاملات والتحليل باستخدام نفس المفاتيح التي يديرها العميل بتلقائية وشفافية. يدعم Azure Synapse Link فقط تكوين المفاتيح المُدارة بواسطة العميل باستخدام الهوية المُدارة لحساب Azure Cosmos DB. يجب عليك تكوين الهوية المُدارة لحسابك في نهج الوصول إلى Azure Key Vault قبل تمكين ارتباط Azure Synapse على حسابك. لمعرفة المزيد، راجع كيفية تكوين المفاتيح التي يديرها العملاء باستخدام مقالة الهويات المدارة لحسابات Azure Cosmos DB.
إشعار
إذا قمت بتغيير حساب قاعدة البيانات من الطرف الأول إلى النظام أو Identy المعين من قبل المستخدم، وقمت بتمكين Azure Synapse Link في حساب قاعدة البيانات الخاص بك، فلن تتمكن من العودة إلى هوية الطرف الأول نظرا لأنه لا يمكنك تعطيل Synapse Link من حساب قاعدة البيانات الخاص بك.
دعم أوقات تشغيل Azure Synapse Analytics
تم تحسين المتجر التحليلي لتوفير قابلية التوسع والمرونة والأداء لأحمال العمل التحليلية دون أي اعتماد على أوقات تشغيل الحوسبة. تتم إدارة تكنولوجيا التخزين ذاتياً لتحسين أحمال العمل التحليلي دون بذل جهود يدوية.
يمكن الاستعلام عن البيانات في مخزن Azure Cosmos DB التحليلي في وقت واحد من أوقات تشغيل التحليلات المختلفة التي يدعمها Azure Synapse Analytics. يدعم Azure Synapse Analytics Apache Spark وتجمع SQL بلا خادم مع مخزن Azure Cosmos DB التحليلي.
إشعار
يمكنك فقط القراءة من متجر تحليلي باستخدام أوقات تشغيل Azure Synapse Analytics. والعكس صحيح أيضاً، يمكن أن تقرأ أوقات تشغيل Azure Synapse Analytics فقط من المتجر التحليلي. يمكن فقط لعملية المزامنة التلقائية تغيير البيانات في متجر التحليل. يمكنك كتابة البيانات مرة أخرى إلى مخزن معاملات Azure Cosmos DB باستخدام تجمع Azure Synapse Analytics Spark، باستخدام Azure Cosmos DB OLTP SDK المضمن.
التسعير
يتبع المخزن التحليلي نموذج أسعار قائماً على الاستهلاك حيث يتم محاسبتك على:
التخزين: حجم البيانات المحفوظة في المخزن التحليلي كل شهر بما في ذلك البيانات التاريخية على النحو المحدد بواسطة TTL التحليلي.
عمليات الكتابة التحليلية: المزامنة المدارة بالكامل لتحديثات البيانات التشغيلية إلى متجر التحليل من متجر المعاملات (المزامنة التلقائية)
عمليات القراءة التحليلية: عمليات القراءة التي تتم وفق متجر التحليل من تجمع Azure Synapse Analytics Spark وأوقات تشغيل تجمع SQL دون خادم.
تسعير المتجر التحليلي منفصل عن نموذج تسعير متجر المعاملات. لا يوجد مفهوم وحدات RU المتوفرة في المخزن التحليلي. انظر صفحة التسعير Azure Cosmos DB للحصول على التفاصيل الكاملة حول نموذج التسعير للمتجر التحليلي.
لا يمكن الوصول إلى البيانات في متجر التحليلات إلا من خلال Azure Synapse Link، وهو ما يتم في أوقات تشغيل Azure Synapse Analytics: تجمعات Azure Synapse Apache Spark وتجمعات azure Synapse SQL دون خادم. راجع صفحة التسعير في Azure Synapse Analytics للحصول على التفاصيل الكاملة حول نموذج التسعير للوصول إلى البيانات في المتجر التحليلي.
من أجل الحصول على تقدير التكلفة عالية المستوى لتمكين المتجر التحليلي على حاوية Azure Cosmos DB، من منظور متجر التحليلي، يمكنك استخدام مخطط سعة Azure Cosmos DB والحصول على تقدير للتخزين التحليلي الخاص بك وتكاليف عمليات الكتابة.
لا يتم تضمين تقديرات عمليات قراءة المخزن التحليلي في حاسبة تكلفة Azure Cosmos DB لأنها وظيفة لحمل العمل التحليلي الخاص بك. ولكن كتقدير عالي المستوى، يؤدي فحص 1 تيرابايت من البيانات في المخزن التحليلي عادة إلى 130,000 عملية قراءة تحليلية، وينتج عن ذلك تكلفة قدرها 0.065 دولار. على سبيل المثال، إذا كنت تستخدم تجمعات SQL بلا خادم في Azure Synapse لإجراء هذا الفحص بسعة 1 تيرابايت، فستتكلف 5.00 دولار وفقا لصفحة تسعير Azure Synapse Analytics. ستكون التكلفة الإجمالية النهائية لمسح 1 تيرابايت هذا 5.065 دولار.
في حين أن التقدير أعلاه هو لمسح 1 تيرابايت من البيانات في متجر التحليل، يقلل تطبيق عوامل التصفية من حجم البيانات الممسوحة ضوئياً، وهذا يحدد العدد الدقيق لعمليات القراءة التحليلية نظراً لنموذج تسعير الاستهلاك. ومن شأن إثبات المفهوم حول عبء العمل التحليلي أن يوفر تقديرا أدق لعمليات القراءة التحليلية. لا يشمل هذا التقدير تكلفة Azure Synapse Analytics.
الخطوات التالية
لمعرفة المزيد، راجع المستندات التالية:
تحقق من وحدة التدريب المتعلقة بكيفية تصميم المعالجة العملية والتحليلية المختلطة باستخدام Azure Synapse Analytics