نظرة عامة على الفهرسة في Azure Cosmos DB
ينطبق على: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() كاساندرا
كاساندرا ![]() العفريت
العفريت ![]() جدول
جدول
Azure Cosmos DB هي قاعدة بيانات لمخطط منطقي يسمح لك بالتكرير على التطبيق الخاص بك دون الحاجة إلى التعامل مع إدارة المخطط أو الفهرس. بشكل افتراضي، يقوم Azure Cosmos DB تلقائيا بفهرسة كل خاصية لكافة العناصر الموجودة في الحاوية دون الحاجة إلى تعريف أي مخطط أو تكوين الفهارس الثانوية.
الهدف من هذه المقالة هو شرح كيفية بيانات فهارس Azure Cosmos DB وكيفية استخدام الفهارس لتحسين أداء الاستعلام. يوصى بتصفح هذا القسم قبل استكشاف كيفية تخصيص نهج الفهرسة.
من العناصر إلى الأشجار
في كل مرة يتم تخزين عنصر في حاوية، يتم إسقاط محتواه كمستند JSON، ثم تحويله إلى تمثيل شجرة. يعني هذا التحويل أن كل خاصية من خصائص هذا العنصر يتم تمثيلها كعقدة في شجرة. يتم إنشاء عقدة جذر زائفة كأحد أصل لكافة خصائص المستوى الأول من العنصر. تحتوي العقد الطرفية على القيم التحجيمية الفعلية التي يحملها عنصر.
كمثال، خذ بعين الاعتبار هذا العنصر:
{
"locations": [
{ "country": "Germany", "city": "Berlin" },
{ "country": "France", "city": "Paris" }
],
"headquarters": { "country": "Belgium", "employees": 250 },
"exports": [
{ "city": "Moscow" },
{ "city": "Athens" }
]
}
تمثل هذه الشجرة مثال عنصر JSON:
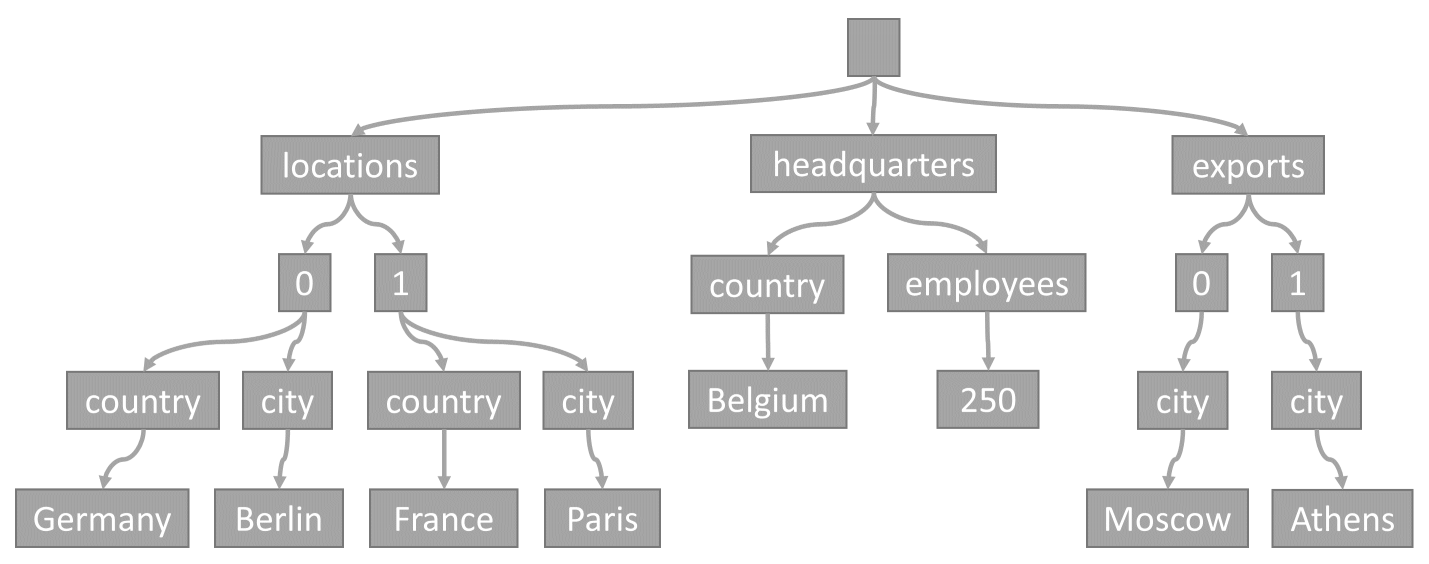
لاحظ كيف يتم ترميز صفائف في الشجرة: يحصل كل إدخال في صفيف عقدة متوسطة المسمى مع فهرس هذا الإدخال داخل الصفيف (0، 1 إلخ).
من الأشجار إلى مسارات الملكية
السبب في تحويل Azure Cosmos DB للعناصر إلى أشجار هو أنه يسمح للنظام بالإشارة إلى الخصائص باستخدام مساراتها داخل تلك الأشجار. للحصول على مسار خاصية، يمكننا اجتياز الشجرة من العقدة الجذر إلى تلك الخاصية، وسلسلة تسميات كل عقدة اجتاز.
فيما يلي المسارات لكل خاصية من عنصر المثال الموضح سابقا:
/locations/0/country: "ألمانيا"/locations/0/city: "برلين"/locations/1/country: "فرنسا"/locations/1/city: "باريس"/headquarters/country: "بلجيكا"/headquarters/employees: 250/exports/0/city: "موسكو"/exports/1/city: "أثينا"
يقوم Azure Cosmos DB بفهرسة مسار كل خاصية وقيمتها المقابلة بشكل فعال عند كتابة عنصر.
أنواع الفهارس
يدعم Azure Cosmos DB حاليا ثلاثة أنواع من الفهارس. يمكنك تكوين أنواع الفهرس هذه عند تعريف نهج الفهرسة.
مؤشر النطاق
تستند فهارس النطاق إلى بنية مرتبة تشبه الشجرة. يستخدم نوع فهرس النطاق ل:
استعلامات المساواة:
SELECT * FROM container c WHERE c.property = 'value'SELECT * FROM c WHERE c.property IN ("value1", "value2", "value3")تطابق المساواة على عنصر صفيف
SELECT * FROM c WHERE ARRAY_CONTAINS(c.tags, "tag1")استعلامات النطاق:
SELECT * FROM container c WHERE c.property > 'value'إشعار
(يعمل لـ
>و<و>=و<=و!=)التحقق من وجود أي خاصية:
SELECT * FROM c WHERE IS_DEFINED(c.property)وظائف نظام السلسلة:
SELECT * FROM c WHERE CONTAINS(c.property, "value")SELECT * FROM c WHERE STRINGEQUALS(c.property, "value")ORDER BYاستعلامات:SELECT * FROM container c ORDER BY c.propertyJOINاستعلامات:SELECT child FROM container c JOIN child IN c.properties WHERE child = 'value'
يمكن استخدام فهارس النطاق على قيم تحجيمية (سلسلة أو رقم). يفرض نهج الفهرسة الافتراضي للحاويات المنشأة حديثا فهارس النطاق لأي سلسلة أو رقم. لمعرفة كيفية تكوين فهارس النطاقات، راجع أمثلة نهج فهرسة النطاقات
إشعار
ORDER BYعبارة التي أوامر حسب خاصية واحدة دائما تحتاج فهرس نطاق وستفشل إذا لم يكن المسار التي تشير إليه واحد. وبالمثل، ORDER BYاستعلام الذي أوامر حسب خصائص متعددة دائما يحتاج فهرس مركب.
الفهرس المكاني
تمكن المؤشراتالمكانية من إجراء استعلامات فعالة على الكائنات الجيوفضائية مثل - النقاط والخطوط والمضلعات والمضلعات المتعددة. تستخدم هذه الاستعلامات كلمات أساسية ST_DISTANCE ST_WITHIN ST_INTERSECTS. فيما يلي بعض الأمثلة التي تستخدم نوع الفهرس المكاني:
استعلامات المسافة الجيوفضائية:
SELECT * FROM container c WHERE ST_DISTANCE(c.property, { "type": "Point", "coordinates": [0.0, 10.0] }) < 40الجيوفضائية ضمن الاستعلامات:
SELECT * FROM container c WHERE ST_WITHIN(c.property, {"type": "Point", "coordinates": [0.0, 10.0] })استعلامات التداخل الجيوفضائي:
SELECT * FROM c WHERE ST_INTERSECTS(c.property, { 'type':'Polygon', 'coordinates': [[ [31.8, -5], [32, -5], [31.8, -5] ]] })
يمكن استخدام الفهارس المكانية على كائنات GeoJSON المنسقة بشكل صحيح. يتم حاليا اعتماد Points و LineStrings و Polygons و MultiPolygons. لمعرفة كيفية تكوين الفهارس المكانية، راجع أمثلة نهج الفهرسة المكانية
الفهارس المركبة
تزيد الفهارس المركبة من الكفاءة عند تنفيذ عمليات على حقول متعددة. يستخدم نوع الفهرس المركب ل:
ORDER BYالاستعلامات على خصائص متعددة:SELECT * FROM container c ORDER BY c.property1, c.property2استعلامات باستخدام عامل تصفية و
ORDER BY. يمكن استخدام هذه الاستعلامات فهرس مركب إذا تمت إضافة خاصية عامل التصفية إلىORDER BYالعبارة.SELECT * FROM container c WHERE c.property1 = 'value' ORDER BY c.property1, c.property2استعلامات باستخدام عامل تصفية على اثنين أو أكثر من الخصائص حيث تُعد خاصية واحدة على الأقل عامل تصفية مساواة
SELECT * FROM container c WHERE c.property1 = 'value' AND c.property2 > 'value'
طالما أن دالة تقييم عامل تصفية واحدة تستخدم أحد أنواع الفهرس، فإن محرك الاستعلام يقيم ذلك أولا قبل مسح الباقي. على سبيل المثال، إذا كان لديك استعلام SQL مثلSELECT * FROM c WHERE c.firstName = "Andrew" and CONTAINS(c.lastName, "Liu")
سيقوم الاستعلام أعلاه أولا تصفية الإدخالات حيث الاسم الأول = "أندرو" باستخدام الفهرس. ثم يمرر جميع إدخالات firstName = "أندرو" من خلال البنية الأساسية لبرنامج ربط العمليات التجارية اللاحقة لتقييم دالة تقييم عامل تصفية CONTAINS.
يمكنك تسريع الاستعلامات وتجنب عمليات فحص الحاوية الكاملة عند استخدام الوظائف التي تقوم بإجراء فحص كامل مثل CONTAINS. يمكنك إضافة المزيد من دالات تقييم التصفية التي تستخدم الفهرس لتسريع هذه الاستعلامات. ترتيب بنود التصفية غير مهم. يحدد محرك الاستعلام دالات التقييم الأكثر انتقائية ويشغل الاستعلام وفقا لذلك.
لمعرفة كيفية تكوين الفهارس المركبة، راجع أمثلة نهج الفهرسة المركبة
فهارس المتجهات
تزيد فهارس المتجهات من الكفاءة عند إجراء عمليات بحث متجهة VectorDistance باستخدام وظيفة النظام. سيكون لعمليات البحث في المتجهات زمن انتقال أقل بكثير، ومعدل نقل أعلى، واستهلاك أقل لوحدة الطلب عند الاستفادة من فهرس المتجهات.
لمعرفة كيفية تكوين فهارس المتجهات، راجع أمثلة نهج فهرسة المتجهات
ORDER BYاستعلامات البحث عن المتجهات:SELECT c.name FROM c ORDER BY VectorDistance(c.vector1, c.vector2)إسقاط درجة التشابه في استعلامات البحث عن المتجهات:
SELECT c.name, VectorDistance(c.vector1, c.vector2) AS SimilarityScore FROM c ORDER BY VectorDistance(c.vector1, c.vector2)عوامل تصفية النطاق على درجة التشابه.
SELECT c.name FROM c WHERE VectorDistance(c.vector1, c.vector2) > 0.8 ORDER BY VectorDistance(c.vector1, c.vector2)هام
يجب تعريف فهارس المتجهات في وقت إنشاء الحاوية ولا يمكن تعديلها بمجرد إنشائها. في الإصدار المستقبلي، ستكون فهارس المتجهات قابلة للتعديل.
استخدام الفهرس
هناك خمس طرق يمكن لمحرك الاستعلام تقييم عوامل تصفية الاستعلام، مرتبة حسب الأكثر كفاءة إلى الأقل كفاءة:
- البحث عن الفهرس
- فحص دقيق للفهرس
- مسح الفهرس الموسع
- مسح كامل للفهرس
- المسح الكامل
عند فهرسة مسارات الخصائص، يستخدم محرك الاستعلام الفهرس تلقائيا بأكبر قدر ممكن من الكفاءة. وبصرف النظر عن فهرسة مسارات الخصائص الجديدة، لا تحتاج إلى تكوين أي شيء لتحسين كيفية استخدام الاستعلامات للفهرس. تكلفة الاستعلام عن وحدة الطلب (RU) هي مزيج لكل من تكلفة وحدة الطلب (RU) من استخدام الفهرس وتكلفة وحدة الطلب (RU) من تحميل العناصر.
فيما يلي جدول يلخص الطرق المختلفة التي يتم بها استخدام الفهارس في Azure Cosmos DB:
| نوع بحث الفهرس | الوصف | أمثلة شائعة | تكلفة وحدة الطلب (RU) من استخدام الفهرس | رسوم RU من تحميل العناصر من مخزن بيانات المعاملات |
|---|---|---|---|---|
| البحث عن الفهرس | قراءة القيم المفهرسة المطلوبة فقط وتحميل العناصر المطابقة فقط من مخزن بيانات المعاملات | مرشحات المساواة و IN | ثابت لكل عامل تصفية مساواة | زيادات استنادا إلى عدد العناصر في نتائج الاستعلام |
| فحص دقيق للفهرس | البحث الثنائي للقيم المفهرسة وتحميل العناصر المطابقة فقط من مخزن بيانات المعاملات | مقارنات النطاق (>، أو < ، أو <= أو >=)، StartsWit | مقارنة بالسعي إلى الفهرس، يزيد قليلا استنادا إلى العلاقة الأساسية للخصائص المفهرسة | زيادات استنادا إلى عدد العناصر في نتائج الاستعلام |
| مسح الفهرس الموسع | البحث الأمثل (ولكن أقل كفاءة من البحث الثنائي) للقيم المفهرسة وتحميل العناصر المطابقة فقط من مخزن بيانات المعاملات | StartsWith (غير متحسس لحالة الأحرف) StringEquals (غير متحسس لحالة الأحرف) | زيادات طفيفة استنادا إلى العلاقة الأساسية للخصائص المفهرسة | زيادات استنادا إلى عدد العناصر في نتائج الاستعلام |
| مسح كامل للفهرس | قراءة مجموعة مميزة من القيم المفهرسة وتحميل العناصر المطابقة فقط من مخزن بيانات المعاملات | يحتوي على، EndsWith, RegexMatch, LIKE | يزيد خطيا استنادا إلى العلاقة الأساسية للخصائص المفهرسة | زيادات استنادا إلى عدد العناصر في نتائج الاستعلام |
| المسح الكامل | تحميل كافة العناصر من مخزن بيانات المعاملات | العلوي والسفلي | غير متوفر | زيادات استنادا إلى عدد العناصر الموجودة في الحاوية |
عند كتابة الاستعلامات، يجب استخدام دالات تقييم التصفية التي تستخدم الفهرس بأكبر قدر ممكن من الكفاءة. على سبيل المثال، إذا كان أي من StartsWith أو Contains سيعمل لحالة الاستخدام الخاصة بك، يجب عليك اختيار StartsWith لأنه يقوم بفحص فهرس دقيق بدلا من فحص الفهرس الكامل.
تفاصيل استخدام الفهرس
في هذا القسم، نغطي المزيد من التفاصيل حول كيفية استخدام الاستعلامات للفهارس. هذا المستوى من التفاصيل ليس ضروريا لتعلم البدء باستخدام Azure Cosmos DB ولكنه موثق بالتفصيل للمستخدمين الفضوليين. نشير إلى مثال العنصر المشترك سابقا في هذا المستند:
مثال على العناصر:
{
"id": 1,
"locations": [
{ "country": "Germany", "city": "Berlin" },
{ "country": "France", "city": "Paris" }
],
"headquarters": { "country": "Belgium", "employees": 250 },
"exports": [
{ "city": "Moscow" },
{ "city": "Athens" }
]
}
{
"id": 2,
"locations": [
{ "country": "Ireland", "city": "Dublin" }
],
"headquarters": { "country": "Belgium", "employees": 200 },
"exports": [
{ "city": "Moscow" },
{ "city": "Athens" },
{ "city": "London" }
]
}
يستخدم Azure Cosmos DB فهرس مقلوب. يعمل الفهرس عن طريق تعيين كل مسار JSON إلى مجموعة العناصر التي تحتوي على تلك القيمة. يتم تمثيل تعيين معرف العنصر عبر العديد من صفحات الفهرس المختلفة للحاوية. فيما يلي نموذج رسم تخطيطي لفهرس مقلوب لحاوية تتضمن مثالين للعناصر:
| المسار | القيمة | قائمة معرفات العناصر |
|---|---|---|
| /المواقع/0/البلد | ألمانيا | 1 |
| /المواقع/0/البلد | أيرلندا | 2 |
| /المواقع/0/المدينة | برلين | 1 |
| /المواقع/0/المدينة | دبلن | 2 |
| /المواقع/1/البلد | فرنسا | 1 |
| /المواقع/1/المدينة | باريس | 1 |
| /المقر/البلد | بلجيكا | 1، 2 |
| /المقر/الموظفين | 200 | 2 |
| /المقر/الموظفين | 250 | 1 |
الفهرس المقلوب له سمتين هامتين:
- بالنسبة لمسار معين، يتم فرز القيم بترتيب تصاعدي. لذلك، يمكن لمشغل الاستعلام أن يخدم بسهولة
ORDER BYمن الفهرس. - بالنسبة لمسار معين، يمكن لمحرك الاستعلام مسح مجموعة القيم الممكنة المميزة لتحديد صفحات الفهرس التي توجد بها نتائج.
مشغل الاستعلام يمكن استخدام الفهرس مقلوب في أربع طرق مختلفة:
البحث عن الفهرس
خذ بعين الاعتبار الاستعلام التالي:
SELECT location
FROM location IN company.locations
WHERE location.country = 'France'
ستتطابق دالة تقييم الاستعلام (التصفية على العناصر حيث يحتوي أي موقع على "فرنسا" كبلد/منطقة) مع المسار المميز في هذا الرسم التخطيطي:
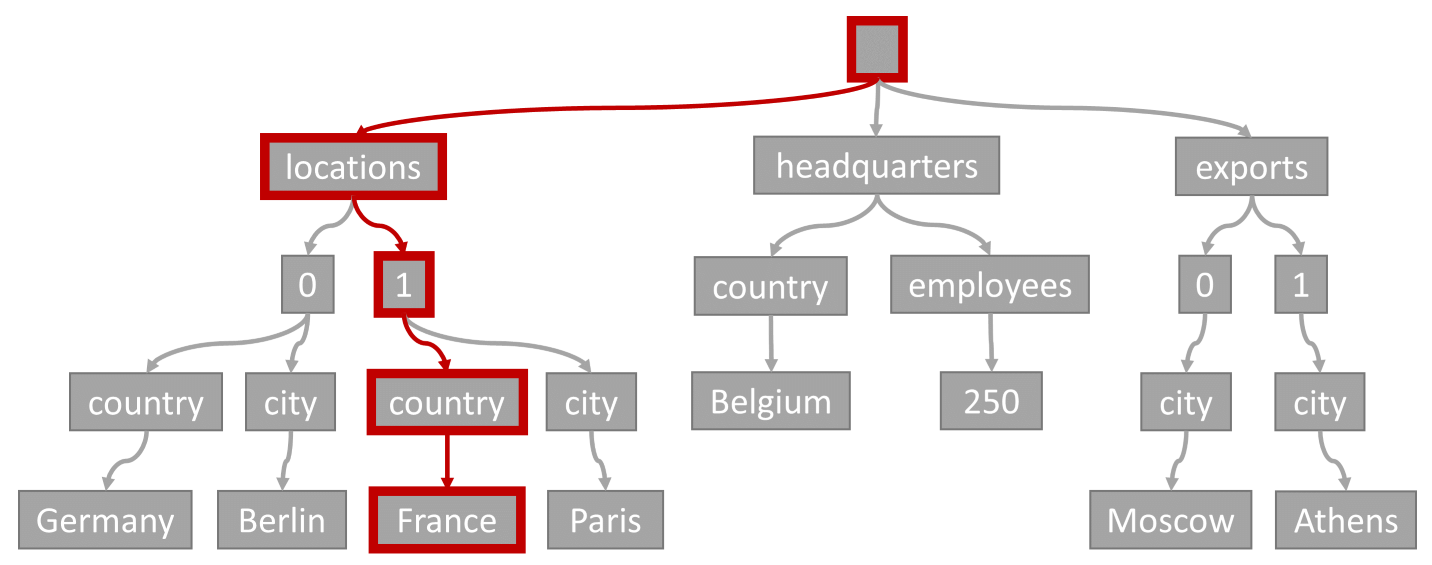
بما أن هذا الاستعلام يحتوي على عامل تصفية مساواة، بعد اجتياز هذه الشجرة، يمكننا التعرف بسرعة على صفحات الفهرس التي تحتوي على نتائج الاستعلام. في هذه الحالة، قد يقرأ مشغل الاستعلام صفحات الفهرس التي تحتوي على العنصر 1. البحث عن فهرس هو الطريقة الأكثر فعالية لاستخدام الفهرس. مع البحث عن فهرس، نقرأ فقط صفحات الفهرس الضرورية ونحمل العناصر الموجودة في نتائج الاستعلام فقط. لذلك، وقت البحث عن الفهرس وتكلفة وحدة الطلب (RU) من البحث عن الفهرس منخفضة بشكل لا يصدق، بغض النظر عن إجمالي حجم البيانات.
فحص دقيق للفهرس
خذ بعين الاعتبار الاستعلام التالي:
SELECT *
FROM company
WHERE company.headquarters.employees > 200
يمكن تقييم دالة تقييم الاستعلام (تصفية على العناصر حيث يوجد أكثر من 200 موظف) مع مسح فهرس دقيق headquarters/employees للمسار. عند القيام بفحص فهرس دقيق، يبدأ مشغل الاستعلام بإجراء بحث ثنائي لمجموعة مميزة من القيم الممكنة للعثور على موقع القيمة200 لـ headquarters/employeesالمسار. نظرا لأن قيم كل مسار يتم فرزها بترتيب تصاعدي، فمن السهل على مشغل الاستعلام إجراء بحث ثنائي. بعد العثور على محرك الاستعلام القيمة 200، تبدأ قراءة كافة صفحات الفهرس المتبقية (الانتقال في الاتجاه التصاعدي).
لأن مشغل الاستعلام يمكنه القيام ببحث ثنائي لتجنب مسح صفحات الفهرس غير الضرورية ومسح مؤشر دقيق يميل إلى أن يكون له زمن انتقال مماثلة وتكاليف وحدة الطلب (RU) لمؤشر البحث عن العمليات.
مسح الفهرس الموسع
خذ بعين الاعتبار الاستعلام التالي:
SELECT *
FROM company
WHERE STARTSWITH(company.headquarters.country, "United", true)
يمكن تقييم دالة تقييم الاستعلام (التصفية على العناصر التي لها مقر رئيسي في موقع يبدأ ب "United" غير حساس لحالة الأحرف) مع فحص فهرس موسع للمسار headquarters/country . العمليات التي تقوم بمسح فهرس موسع لها تحسينات يمكن أن تساعد في تجنب الاحتياجات لمسح كل صفحة فهرس ولكنها أغلى قليلا من البحث الثنائي لفحص الفهرس الدقيق.
على سبيل المثال، عند تقييم غير حساس لحالة الأحرف StartsWith، يتحقق محرك الاستعلام من الفهرس للحصول على مجموعات مختلفة ممكنة من القيم الكبيرة والصغيرة. يسمح هذا التحسين لمحرك الاستعلام بتجنب قراءة معظم صفحات الفهرس. وظائف النظام المختلفة لها تحسينات مختلفة يمكن استخدامها لتجنب قراءة كل صفحة فهرس، لذلك يتم تصنيفها على نطاق واسع على أنها مسح فهرس موسع.
مسح كامل للفهرس
خذ بعين الاعتبار الاستعلام التالي:
SELECT *
FROM company
WHERE CONTAINS(company.headquarters.country, "United")
يمكن تقييم دالة تقييم الاستعلام (التصفية على العناصر التي لها مقر رئيسي في موقع يحتوي على "United") من خلال فحص فهرس المسار headquarters/country . على عكس فحص الفهرس الدقيق، يفحص فحص الفهرس الكامل دائما من خلال مجموعة مميزة من القيم المحتملة لتحديد صفحات الفهرس حيث توجد نتائج. في هذه الحالة،Contains يتم تشغيل على الفهرس. يزيد وقت البحث عن الفهرس وتكلفة RU لمسح الفهرس مع زيادة أساسية المسار. بمعنى آخر، كلما زادت القيم المتميزة الممكنة التي يحتاج محرك الاستعلام إلى مسحها ضوئيا، كلما زاد زمن الوصول وشحن RU المتضمن في إجراء مسح فهرس كامل.
على سبيل المثال، ضع في اعتبارك خاصيتين: town و country. العلاقة الأساسية للمدينة هي 5000 والعلاقة country الأساسية هي 200. فيما يلي مثالين الاستعلامات التي تحتوي على كل دالة يحتوي على نظام يقوم بفحص فهرس كامل على town الخاصية. يستخدم الاستعلام الأول وحدات طلب أكثر من الاستعلام الثاني لأن العلاقة الأساسية للمدينة أعلى من country.
SELECT *
FROM c
WHERE CONTAINS(c.town, "Red", false)
SELECT *
FROM c
WHERE CONTAINS(c.country, "States", false)
المسح الكامل
في بعض الحالات، قد لا يكون مشغل الاستعلام قادرا على تقييم عامل تصفية استعلام باستخدام الفهرس. في هذه الحالة، يحتاج محرك الاستعلام إلى تحميل كافة العناصر من مخزن المعاملات من أجل تقييم عامل تصفية الاستعلام. لا تستخدم عمليات الفحص الكاملة الفهرس وامتلاك تكلفة وحدة طلب تزيد خطيا مع إجمالي حجم البيانات. لحسن الحظ، العمليات التي تتطلب مسح كامل نادرة.
استعلامات البحث عن المتجهات بدون فهرس متجه محدد
إذا لم تقم بتعريف نهج فهرس متجه واستخدم VectorDistance وظيفة النظام في عبارة ORDER BY ، فسينتج عن ذلك فحص كامل وتكلفة وحدة الطلب أعلى مما إذا قمت بتعريف نهج فهرس متجه. التشابه، إذا كنت تستخدم VectorDistance مع تعيين القيمة المنطقية للقوة الغاشمة إلى true، ولم يكن لديك flat فهرس معرف لمسار المتجه، فسيحدث فحص كامل.
استعلامات ذات تعبيرات عوامل تصفية معقدة
في الأمثلة السابقة، اعتبرنا فقط الاستعلامات التي تحتوي على تعبيرات تصفية بسيطة (على سبيل المثال، الاستعلامات مع مساواة واحدة فقط أو عامل تصفية النطاق). في الواقع، تحتوي معظم الاستعلامات تعبيرات تصفية أكثر تعقيدا.
خذ بعين الاعتبار الاستعلام التالي:
SELECT *
FROM company
WHERE company.headquarters.employees = 200 AND CONTAINS(company.headquarters.country, "United")
لتنفيذ هذا الاستعلام، يجب أن يقوم مشغل الاستعلام بالبحث عن الفهرس على headquarters/employees وفحص كامل للفهرس على headquarters/country. يحتوي مشغل الاستعلام على الاستدلالات الداخلية التي يستخدمها لتقييم تعبير عامل تصفية الاستعلام بأكبر قدر ممكن من الكفاءة. في هذه الحالة، قد تجنب مشغل الاستعلام الحاجة إلى قراءة صفحات الفهرس غير الضرورية عن طريق البحث عن الفهرس أولا. على سبيل المثال، إذا تطابق 50 عنصرا فقط مع عامل تصفية المساواة، فسيحتاج محرك الاستعلام فقط إلى التقييم Contains على صفحات الفهرس التي تحتوي على تلك العناصر ال 50. لن يكون من الضروري إجراء مسح فهرس كامل للحاوية بأكملها.
استخدام الفهرس للوظائف التجميعية التدرجية
يجب أن تعتمد الاستعلامات ذات الخصائص التجميعية بشكل حصري على الفهرس لاستخدامه.
في بعض الحالات، يمكن أن يرجع الفهرس النتائج الإيجابية الزائفة. على سبيل المثال، عند تقييم Contains على الفهرس، قد يتجاوز عدد المطابقات في الفهرس عدد نتائج الاستعلام. يقوم مشغل الاستعلام بتحميل كافة تطابقات الفهرس، وتقييم عامل التصفية على العناصر المحملة، وإرجاع النتائج الصحيحة فقط.
بالنسبة لمعظم الاستعلامات، لا يكون لتحميل تطابقات الفهرس الموجبة الخاطئة أي تأثير ملحوظ على استخدام الفهرس.
على سبيل المثال، خذ بعين الاعتبار الاستعلام الآتي:
SELECT *
FROM company
WHERE CONTAINS(company.headquarters.country, "United")
Contains قد ترجع وظيفة النظام بعض التطابقات الإيجابية الخاطئة، لذلك يحتاج محرك الاستعلام إلى التحقق مما إذا كان كل عنصر محمل يطابق تعبير عامل التصفية. في هذا المثال، قد يحتاج محرك الاستعلام فقط إلى تحميل عدد قليل من العناصر الإضافية، لذلك يكون التأثير على استخدام الفهرس وتكلفة RU ضئيلا.
ومع ذلك، يجب أن تعتمد الاستعلامات ذات الوظائف التجميعية بشكل حصري على الفهرس لاستخدامه. على سبيل المثال، خذ بعين الاعتبار الاستعلام التالي مع Count تجميع:
SELECT COUNT(1)
FROM company
WHERE CONTAINS(company.headquarters.country, "United")
كما هو الحال في المثال الأول، Contains قد ترجع خاصية النظام بعض المطابقات الإيجابية الزائفة. على عكسSELECT *الاستعلام، ومع ذلك، Count الاستعلام لا يمكن تقييم تعبير عامل التصفية على العناصر المحملة للتحقق من كافة تطابقات الفهرس. Count يجب أن يعتمد الاستعلام بشكل حصري على الفهرس، لذلك إذا كانت هناك فرصة أن يقوم تعبير عامل التصفية بإرجاع تطابقات إيجابية خاطئة، يلجأ محرك الاستعلام إلى فحص كامل.
يجب أن تعتمد الاستعلامات ذات الوظائف التجميعية التالية بشكل حصري على الفهرس، لذا يتطلب تقييم بعض وظائف النظام فحصا كاملا.
الخطوات التالية
اقرأ المزيد حول الفهرسة في المقالات التالية: