ترحيل البيانات من MongoDB إلى حساب Azure Cosmos DB لحساب MongoDB باستخدام Azure Databricks
ينطبق على: ![]() MongoDB
MongoDB
يعد دليل الترحيل هذا جزءا من سلسلة حول ترحيل قواعد البيانات من MongoDB إلى واجهة برمجة تطبيقات Azure Cosmos DB ل MongoDB. خطوات الترحيل المهمة هي ما قبل الترحيلوالترحيل و ما بعد الترحيل، كما هو موضح أدناه.
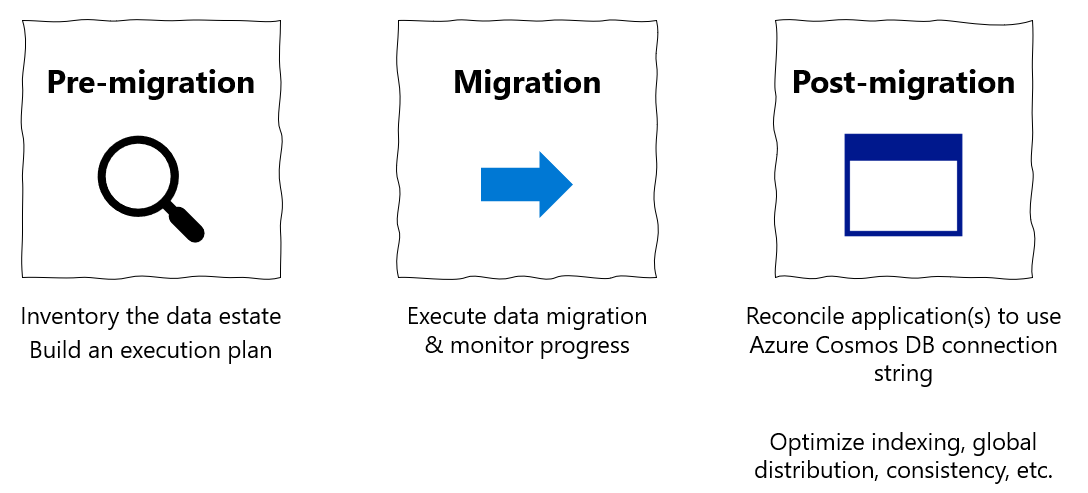
ترحيل البيانات باستخدام Azure Databricks
Azure Databricks عبارة عن نظام أساسي كخدمة (PaaS) تقدم لـ Apache Spark. يوفر طريقة لإجراء عمليات الترحيل في وضع عدم الاتصال على مجموعة بيانات واسعة النطاق. يمكنك استخدام Azure Databricks لإجراء ترحيل غير متصل لقواعد البيانات من MongoDB إلى Azure Cosmos DB ل MongoDB.
في هذا البرنامج التعليمي، سوف تتعلم كيفية:
توفير مجموعة Azure Databricks
إضافة تبعيات
قم بإنشاء وتشغيل دفتر Scala أو Python
تحسين أداء الترحيل
استكشاف أخطاء تحديد المعدل وإصلاحها التي يمكن ملاحظتها أثناء الترحيل
المتطلبات الأساسية
لإكمال هذا البرنامج التعليمي، تحتاج إلى:
- أكمل خطوات ما قبل الترحيل مثل تقدير الإنتاجية واختيار مفتاح الجزء.
- إنشاء Azure Cosmos DB لحساب MongoDB.
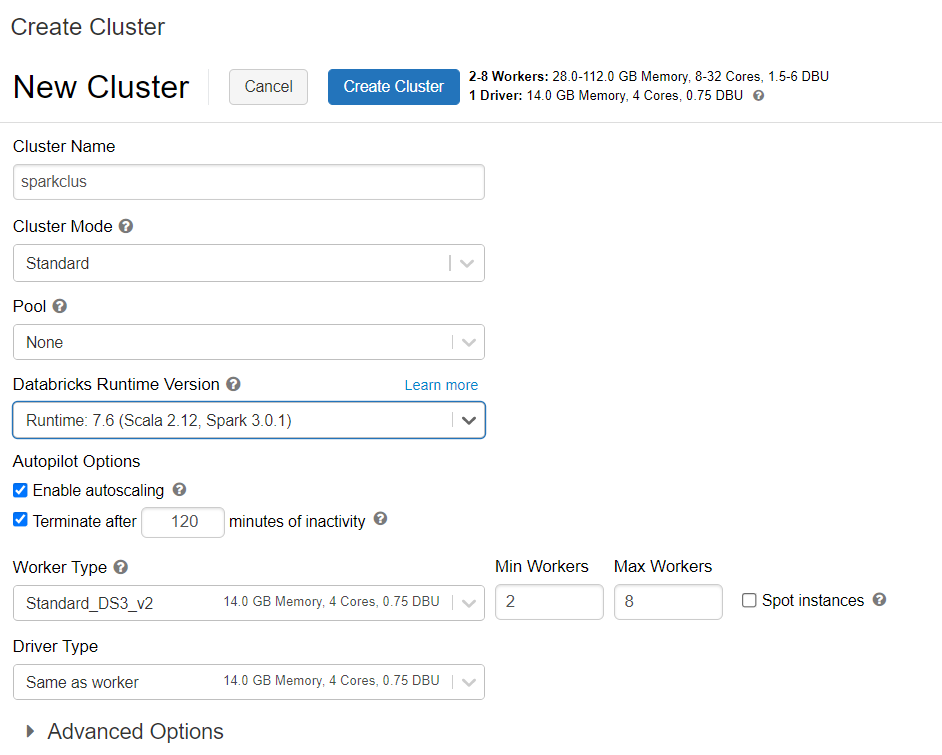
توفير مجموعة Azure Databricks
يمكنك اتباع الإرشادات لتوفير مجموعة Azure Databricks. نوصي بتحديد Databricks runtime الإصدار 7.6، والذي يدعم Spark 3.0.
إضافة تبعيات
أضف MongoDB Connector لمكتبة Spark إلى مجموعتك للاتصال بكل من MongoDB الأصلي وAzure Cosmos DB لنقاط نهاية MongoDB. في مجموعتك، حدد Libraries>Install New>Maven، ثم أضف إحداثيات org.mongodb.spark:mongo-spark-connector_2.12:3.0.1 Maven.
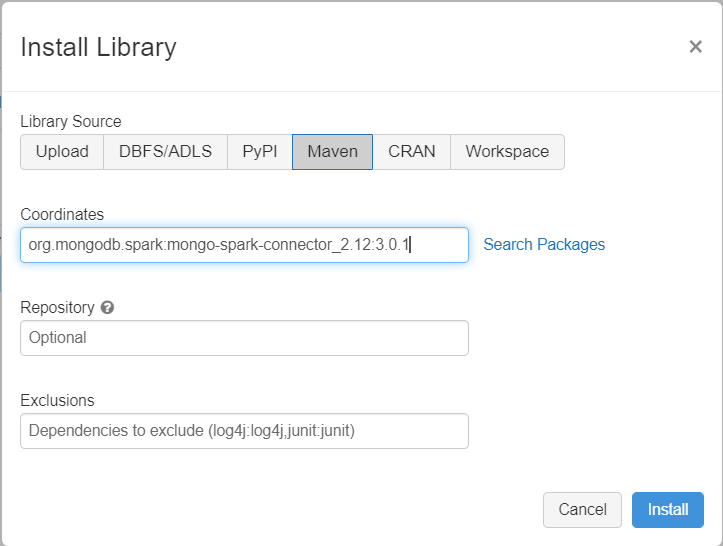
حدد Install، ثم أعد تشغيل نظام المجموعة عند اكتمال التثبيت.
إشعار
تأكد من إعادة تشغيل مجموعة Databricks بعد تثبيت MongoDB Connector لمكتبة Spark.
بعد ذلك، يمكنك إنشاء دفتر Scala أو Python للترحيل.
إنشاء Scala Notebook للترحيل
قم بإنشاء Scala Notebook في Databricks. تأكد من إدخال القيم الصحيحة للمتغيرات قبل تشغيل التعليمة البرمجية التالية:
import com.mongodb.spark._
import com.mongodb.spark.config._
import org.apache.spark._
import org.apache.spark.sql._
var sourceConnectionString = "mongodb://<USERNAME>:<PASSWORD>@<HOST>:<PORT>/<AUTHDB>"
var sourceDb = "<DB NAME>"
var sourceCollection = "<COLLECTIONNAME>"
var targetConnectionString = "mongodb://<ACCOUNTNAME>:<PASSWORD>@<ACCOUNTNAME>.mongo.cosmos.azure.com:10255/?ssl=true&replicaSet=globaldb&retrywrites=false&maxIdleTimeMS=120000&appName=@<ACCOUNTNAME>@"
var targetDb = "<DB NAME>"
var targetCollection = "<COLLECTIONNAME>"
val readConfig = ReadConfig(Map(
"spark.mongodb.input.uri" -> sourceConnectionString,
"spark.mongodb.input.database" -> sourceDb,
"spark.mongodb.input.collection" -> sourceCollection,
))
val writeConfig = WriteConfig(Map(
"spark.mongodb.output.uri" -> targetConnectionString,
"spark.mongodb.output.database" -> targetDb,
"spark.mongodb.output.collection" -> targetCollection,
"spark.mongodb.output.maxBatchSize" -> "8000"
))
val sparkSession = SparkSession
.builder()
.appName("Data transfer using spark")
.getOrCreate()
val customRdd = MongoSpark.load(sparkSession, readConfig)
MongoSpark.save(customRdd, writeConfig)
قم بإنشاء دفتر ملاحظات Python للترحيل
قم بإنشاء دفتر ملاحظات Python في Databricks. تأكد من إدخال القيم الصحيحة للمتغيرات قبل تشغيل التعليمة البرمجية التالية:
from pyspark.sql import SparkSession
sourceConnectionString = "mongodb://<USERNAME>:<PASSWORD>@<HOST>:<PORT>/<AUTHDB>"
sourceDb = "<DB NAME>"
sourceCollection = "<COLLECTIONNAME>"
targetConnectionString = "mongodb://<ACCOUNTNAME>:<PASSWORD>@<ACCOUNTNAME>.mongo.cosmos.azure.com:10255/?ssl=true&replicaSet=globaldb&retrywrites=false&maxIdleTimeMS=120000&appName=@<ACCOUNTNAME>@"
targetDb = "<DB NAME>"
targetCollection = "<COLLECTIONNAME>"
my_spark = SparkSession \
.builder \
.appName("myApp") \
.getOrCreate()
df = my_spark.read.format("com.mongodb.spark.sql.DefaultSource").option("uri", sourceConnectionString).option("database", sourceDb).option("collection", sourceCollection).load()
df.write.format("mongo").mode("append").option("uri", targetConnectionString).option("maxBatchSize",2500).option("database", targetDb).option("collection", targetCollection).save()
تحسين أداء الترحيل
يمكن ضبط أداء الترحيل من خلال هذه التكوينات:
عدد العمال والذاكرات الأساسية في مجموعة Spark: يعني المزيد من العمال المزيد من القطع الحسابية لتنفيذ المهام.
maxBatchSize: تتحكم قيمة
maxBatchSizeفي معدل حفظ البيانات في مجموعة Azure Cosmos DB المستهدفة. ومع ذلك، إذا كان maxBatchSize مرتفعًا جدًا بالنسبة إلى إنتاجية المجموعة، فقد يتسبب ذلك في حدوث أخطاء في تحديد المعدل .ستحتاج إلى ضبط عدد العمال و maxBatchSize، اعتمادًا على عدد المنفذين في مجموعة Spark، ومن المحتمل الحجم (وهذا هو سبب تكلفة RU) لكل مستند تتم كتابته، وحدود إنتاجية المجموعة المستهدفة.
تلميح
maxBatchSize = معدل نقل المجموعة / (تكلفة RU لمستند واحد * عدد عمال Spark * عدد مراكز وحدة المعالجة المركزية لكل عامل)
قسم MongoDB Spark ومفتاح التقسيم: التقسيم الظاهري المستخدم هو MongoDefaultPartitioner ومفتاح التقسيم الظاهري هو _id. يمكن تغيير القسم عن طريق تعيين القيمة
MongoSamplePartitionerلخاصية تكوين الإدخالspark.mongodb.input.partitioner. وبالمثل، يمكن تغيير partitionKey عن طريق تعيين اسم الحقل المناسب لخاصية تكوين الإدخالspark.mongodb.input.partitioner.partitionKey. يمكن أن يساعد partitionKey الأيمن في تجنب انحراف البيانات (يتم كتابة عدد كبير من السجلات لنفس قيمة مفتاح الجزء).تعطيل الفهارس أثناء نقل البيانات: بالنسبة للكميات الكبيرة من ترحيل البيانات، ضع في الاعتبار تعطيل الفهارس، وخاصة فهرس أحرف البدل في المجموعة المستهدفة. تزيد الفهارس من تكلفة RU لكتابة كل مستند. يمكن أن يساعد تحرير وحدات RU هذه في تحسين معدل نقل البيانات. يمكنك تمكين الفهارس بمجرد ترحيل البيانات.
استكشاف الأخطاء وإصلاحها
خطأ المهلة (رمز الخطأ 50)
قد ترى رمز خطأ 50 للعمليات مقابل قاعدة بيانات Azure Cosmos DB لقاعدة بيانات MongoDB. يمكن أن تتسبب السيناريوهات التالية في حدوث أخطاء في المهلة:
- الإنتاجية المخصصة لقاعدة البيانات منخفضة: تأكد من أن المجموعة المستهدفة لديها إنتاجية كافية مخصصة لها.
- انحراف مفرط في البيانات بسبب حجم البيانات الكبير. إذا كان لديك قدر كبير من البيانات للترحيل إلى جدول معين ولكن لديك انحراف كبير في البيانات، فقد لا تزال تواجه قيودًا على المعدل حتى إذا كان لديك العديد من وحدات الطلب المتوفرة في الجدول الخاص بك. يتم تقسيم وحدات الطلب بالتساوي بين الأقسام المادية، ويمكن أن يتسبب انحراف البيانات الثقيل في اختناق الطلبات لجزء واحد. انحراف البيانات يعني عددًا كبيرًا من السجلات لنفس قيمة مفتاح الجزء.
تحديد المعدل (رمز الخطأ 16500)
قد ترى رمز خطأ 16500 للعمليات ضد قاعدة بيانات Azure Cosmos DB لقاعدة بيانات MongoDB. هذه أخطاء تحد من المعدل ويمكن ملاحظتها على الحسابات أو الحسابات القديمة حيث يتم تعطيل ميزة إعادة المحاولة من جانب الخادم.
- تمكين إعادة المحاولة من جانب الخادم: قم بتمكين ميزة إعادة المحاولة من جانب الخادم (SSR) ودع الخادم يعيد محاولة العمليات محدودة المعدل تلقائيًا.
تطوير ما بعد الترحيل
بعد ترحيل البيانات، يمكنك الاتصال بـ Azure Cosmos DB، وإدارة البيانات. يمكنك أيضًا اتباع خطوات أخرى بعد الترحيل؛ مثل: تحسين نهج الفهرسة، أو تحديث مستوى التناسق الظاهري، أو تكوين التوزيع العام لحساب Azure Cosmos DB الخاص بك. للمزيد من المعلومات، راجع مقالة التطوير ما بعد الترحيل.
الموارد الإضافية
- هل تحاول القيام بتخطيط السعة للترحيل إلى Azure Cosmos DB؟
- في حال كان كل ما تعرفه هو عدد vcores والخوادم في مجموعة قاعدة البيانات الحالية، فاقرأ عن تقدير وحدات الطلب باستخدام vCores أو vCPUs
- إذا كان كل ما تعرفه هو عدد vcores والخوادم الموجودة في مجموعة قاعدة البيانات، اقرأ عن تقدير وحدات الطلب باستخدام vCores أو vCPUs
الخطوات التالية
الملاحظات
قريبًا: خلال عام 2024، سنتخلص تدريجيًا من GitHub Issues بوصفها آلية إرسال ملاحظات للمحتوى ونستبدلها بنظام ملاحظات جديد. لمزيد من المعلومات، راجع https://aka.ms/ContentUserFeedback.
إرسال الملاحظات وعرضها المتعلقة بـ