كيفية تصميم وتقسيم البيانات على Azure Cosmos DB باستخدام مثال من العالم الحقيقي
ينطبق على: ![]() NoSQL
NoSQL
تعتمد هذه المقالة على العديد من مفاهيم Azure Cosmos DB مثل نمذجة البيانات والتقسيم ومعدل النقل المقدم لتوضيح كيفية معالجة تمرين تصميم البيانات في العالم الحقيقي.
إذا كنت تعمل عادةً مع قواعد البيانات الارتباطية فمن المحتمل أنك قمت ببناء عادات وحدس حول كيفية تصميم نموذج بيانات. نظراً للقيود المحددة، ولكن أيضاً نقاط القوة الفريدة لـ Azure Cosmos DB، فإن معظم هذه الممارسات الأفضل لا تُترجم جيداً وقد تجذبك إلى حلول دون المستوى الأمثل. الهدف من هذه المقالة هو إرشادك خلال العملية الكاملة لنمذجة حالة استخدام في العالم الحقيقي على Azure Cosmos DB، من نمذجة العنصر إلى موقع الكيان وتقسيم الحاوية.
قم بتنزيل أو عرض التعليمات البرمجية المصدر التي أنشأها المجتمع والتي توضح المفاهيم من هذه المقالة.
هام
ساهم مساهم مجتمع بعينة التعليمات البرمجية هذه ولا يدعم فريق Azure Cosmos DB صيانته.
السيناريو
لهذا التمرين، سننظر في مجال منصة التدوين حيث يمكن للمستخدمين إنشاء منشورات. يمكن للمستخدمين أيضا الإعجاب بهذه المنشورات وإضافة تعليقات إليها.
تلميح
لقد سلطنا الضوء على بعض الكلمات بشكل مائل؛ هذه الكلمات تحدد نوع "الأشياء" التي سيتعين على نموذجنا معالجتها.
إضافة المزيد من المتطلبات لمواصفاتنا:
- تعرض الصفحة الأولى موجزاً بالمشاركات التي تم إنشاؤها مؤخراً،
- يمكننا جلب جميع المنشورات للمستخدم، وجميع التعليقات على المنشور وكل الإعجابات للمنشور،
- يتم إرجاع المشاركات مع اسم المستخدم لمؤلفيها وعدد التعليقات والإعجابات التي لديهم،
- يتم إرجاع التعليقات والإعجابات أيضاً باسم المستخدم الخاص بالمستخدمين الذين قاموا بإنشائها،
- عند عرضها كقوائم، يجب أن تقدم المشاركات فقط ملخصاً مبتوراً لمحتواها.
تحديد أنماط الوصول الرئيسية
للبدء، نعطي بعض الهيكل لمواصفاتنا الأولية من خلال تحديد أنماط الوصول إلى الحل الخاص بنا. عند تصميم نموذج بيانات ل Azure Cosmos DB، من المهم فهم الطلبات التي يجب أن يخدمها نموذجنا للتأكد من أن النموذج يخدم هذه الطلبات بكفاءة.
لتسهيل متابعة العملية الشاملة، نقوم بتصنيف هذه الطلبات المختلفة إما كأوامر أو استعلامات، ونقترض بعض المفردات من CQRS. في CQRS، الأوامر هي طلبات الكتابة (أي أهداف تحديث النظام) والاستعلامات هي طلبات للقراءة فقط.
فيما يلي قائمة بالطلبات التي تعرضها منصتنا:
- [C1] إنشاء/تحرير مستخدم
- [Q1] استرداد مستخدم
- [C2] إنشاء/تحرير منشور
- [Q2] استرداد منشور
- [Q3] سرد منشورات المستخدم في نموذج قصير
- [C3] إنشاء تعليق
- [Q4] سرد تعليقات المنشور
- [C4] الإعجاب بمنشور
- [Q5] سرد الإعجابات الخاصة بمنشور
- [Q6] سرد x أحدث المنشورات التي تم إنشاؤها في نموذج قصير (موجز)
في هذه المرحلة، لم نفكر في تفاصيل ما يحتوي عليه كل كيان (مستخدم، نشر وما إلى ذلك). عادة ما تكون هذه الخطوة من بين الخطوات الأولى التي يجب معالجتها عند التصميم مقابل متجر علائقي. نبدأ بهذه الخطوة أولا لأنه يجب علينا معرفة كيفية ترجمة هذه الكيانات من حيث الجداول والأعمدة والمفاتيح الخارجية وما إلى ذلك. الأمر أقل بكثير من القلق بشأن قاعدة بيانات المستندات التي لا تفرض أي مخطط عند الكتابة.
السبب الرئيسي الذي يجعل من المهم تحديد أنماط الوصول لدينا من البداية، هو أن قائمة الطلبات هذه ستكون مجموعة الاختبار لدينا. في كل مرة نكرر فيها نموذج البيانات الخاص بنا، نتصفح كل طلب من الطلبات ونتحقق من أدائه وقابليته للتوسع. نقوم بحساب وحدات الطلب المستهلكة في كل نموذج وتحسينها. تستخدم جميع هذه النماذج سياسة الفهرسة الافتراضية ويمكنك تجاوزها عن طريق فهرسة خصائص معينة، ما قد يؤدي إلى زيادة تحسين استهلاك وحدة الطلب ووقت الاستجابة.
V1: نسخة أولى
نبدأ مع حاويتين: users و posts.
حاوية المستخدمين
هذه الحاوية تخزن فقط عناصر المستخدم:
{
"id": "<user-id>",
"username": "<username>"
}
نقوم بتقسيم هذه الحاوية حسب id، ما يعني أن كل قسم منطقي داخل تلك الحاوية يحتوي على عنصر واحد فقط.
حاوية المشاركات
تستضيف هذه الحاوية كيانات مثل المنشورات والتعليقات والإعجابات:
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"title": "<post-title>",
"content": "<post-content>",
"creationDate": "<post-creation-date>"
}
{
"id": "<comment-id>",
"type": "comment",
"postId": "<post-id>",
"userId": "<comment-author-id>",
"content": "<comment-content>",
"creationDate": "<comment-creation-date>"
}
{
"id": "<like-id>",
"type": "like",
"postId": "<post-id>",
"userId": "<liker-id>",
"creationDate": "<like-creation-date>"
}
نقوم بتقسيم هذه الحاوية حسب postId، ما يعني أن كل قسم منطقي داخل تلك الحاوية يحتوي على منشور واحد، وجميع التعليقات لهذا المنشور وجميع الإعجابات لهذا المنشور.
لقد قدمنا type خاصية في العناصر المخزنة في هذه الحاوية للتمييز بين الأنواع الثلاثة من الكيانات التي تستضيفها هذه الحاوية.
أيضا، اخترنا الإشارة إلى البيانات ذات الصلة بدلا من تضمينها (راجع هذا القسم للحصول على تفاصيل حول هذه المفاهيم) بسبب:
- ليس هناك حد أقصى لعدد المشاركات التي يمكن للمستخدم إنشاؤها،
- يمكن أن تكون المشاركات طويلة بشكل تعسفي،
- ليس هناك حد أقصى لعدد التعليقات وإعجابات المنشور،
- نريد أن نتمكن من إضافة تعليق أو ما شابه إلى منشور دون الحاجة إلى تحديث المنشور نفسه.
ما مدى جودة أداء نموذجنا؟
حان الوقت الآن لتقييم الأداء وقابلية التوسع لإصدارنا الأول. لكل من الطلبات التي تم تحديدها مسبقاً، نقيس وقت الاستجابة وعدد وحدات الطلبات التي يستهلكها. يتم إجراء هذا القياس مقابل مجموعة بيانات وهمية تحتوي على 100000 مستخدم مع 5 إلى 50 مشاركة لكل مستخدم، وما يصل إلى 25 تعليقاً و100 إعجاب لكل منشور.
[C1] إنشاء / تحرير مستخدم
هذا الطلب سهل التنفيذ حيث نقوم فقط بإنشاء عنصر أو تحديثه في الحاوية users . تنتشر الطلبات بشكل جيد عبر جميع الأقسام بفضل id مفتاح القسم.

| كمون | رسوم وحدة الطلب | اداء |
|---|---|---|
7 مللي ثانية |
5.71 رو |
✅ |
[Q1] استرداد مستخدم
يتم استرداد مستخدم عن طريق قراءة العنصر المقابل من الحاوية users .

| كمون | رسوم وحدة الطلب | اداء |
|---|---|---|
2 مللي ثانية |
1 رو |
✅ |
[C2] إنشاء / تعديل وظيفة
على غرار [C1]، علينا فقط الكتابة في الحاوية posts.

| كمون | رسوم وحدة الطلب | اداء |
|---|---|---|
9 مللي ثانية |
8.76 رو |
✅ |
[Q2] استرداد وظيفة
نبدأ باسترداد المستند المقابل من الحاوية posts . ولكن هذا ليس كافيا، وفقا لمواصفاتنا لدينا أيضا لتجميع اسم المستخدم لمؤلف المنشور، وعدد التعليقات، وعدد الإعجابات للمنشور. تتطلب التجميعات المدرجة إصدار 3 استعلامات SQL أخرى.

يقوم كل استعلامات أكثر بتصفية مفتاح القسم للحاوية الخاصة به، وهو بالضبط ما نريده لزيادة الأداء وقابلية التوسع إلى أقصى حد. لكن علينا في النهاية إجراء أربع عمليات لإعادة منشور واحد، لذا سنعمل على تحسين ذلك في التكرار التالي.
| كمون | رسوم وحدة الطلب | اداء |
|---|---|---|
9 مللي ثانية |
19.54 رو |
⚠ |
[Q3] اذكر مشاركات المستخدم في شكل قصير
أولاً، يتعين علينا استرداد المنشورات المطلوبة باستخدام استعلام SQL الذي يجلب المنشورات المقابلة لهذا المستخدم المحدد. ولكن علينا أيضا إصدار المزيد من الاستعلامات لتجميع اسم المستخدم للمؤلف وعدد التعليقات والإعجابات.

يقدم هذا التنفيذ العديد من العيوب:
- يجب إصدار الاستعلامات التي تجمع عدد التعليقات والإعجابات لكل منشور يتم إرجاعه بواسطة الاستعلام الأول،
- لا يقوم الاستعلام الرئيسي بالتصفية على مفتاح القسم للحاوية
posts، مما يؤدي إلى توزيع المهام وفحص القسم عبر الحاوية.
| كمون | رسوم وحدة الطلب | اداء |
|---|---|---|
130 مللي ثانية |
619.41 رو |
⚠ |
[C3] قم بإنشاء تعليق
يتم إنشاء تعليق عن طريق كتابة العنصر المقابل في الحاوية posts .
| كمون | رسوم وحدة الطلب | اداء |
|---|---|---|
7 مللي ثانية |
8.57 رو |
✅ |
[Q4] قائمة تعليقات المنشور
نبدأ باستعلام يجلب جميع التعليقات الخاصة بهذا المنشور ومرة أخرى، نحتاج أيضاً إلى تجميع أسماء المستخدمين بشكل منفصل لكل تعليق.

على الرغم من أن الاستعلام الرئيسي يقوم بالتصفية على مفتاح قسم الحاوية، فإن تجميع أسماء المستخدمين بشكل منفصل يعاقب الأداء الكلي. نقوم بتحسين ذلك لاحقا.
| كمون | رسوم وحدة الطلب | اداء |
|---|---|---|
23 مللي ثانية |
27.72 رو |
⚠ |
[C4] مثل المنشور
تمامًا مثل [C3]، نقوم بإنشاء العنصر المقابل في posts الحاوية.
| كمون | رسوم وحدة الطلب | اداء |
|---|---|---|
6 مللي ثانية |
7.05 رو |
✅ |
[Q5] ضع قائمة بإعجابات المنشور
تماما مثل [Q4]، نقوم بالاستعلام عن الإعجابات لهذا المنشور، ثم تجميع أسماء المستخدمين الخاصة بهم.

| كمون | رسوم وحدة الطلب | اداء |
|---|---|---|
59 مللي ثانية |
58.92 رو |
⚠ |
[Q6] قم بإدراج x أحدث المشاركات التي تم إنشاؤها في شكل قصير (موجز)
نقوم بإحضار أحدث المنشورات عن طريق الاستعلام عن posts الحاوية التي تم فرزها حسب تاريخ الإنشاء التنازلي، ثم تجميع أسماء المستخدمين وعدد التعليقات والإعجابات لكل من المنشورات.

مرة أخرى، لا يقوم استعلامنا الأولي بالتصفية على مفتاح القسم للحاوية posts ، مما يؤدي إلى توزيع المهام بشكل مكلف. هذا هو أسوأ من ذلك لأننا نستهدف مجموعة نتائج أكبر وفرز النتائج مع عبارة ORDER BY ، مما يجعلها أكثر تكلفة من حيث وحدات الطلب.
| كمون | رسوم وحدة الطلب | اداء |
|---|---|---|
306 مللي ثانية |
2063.54 رو |
⚠ |
التفكير في أداء V1
بالنظر إلى مشكلات الأداء التي واجهناها في القسم السابق، يمكننا تحديد فئتين رئيسيتين من المشكلات:
- تتطلب بعض الطلبات إصدار استعلامات متعددة من أجل جمع كل البيانات التي نحتاج إلى إرجاعها،
- لا يتم تصفية بعض الاستعلامات على مفتاح القسم للحاويات التي تستهدفها، ما يؤدي إلى انتشار واسع يعوق قابلية التوسع لدينا.
دعونا نحل كل مشكلة من هذه المشاكل، بدءاً من المشكلة الأولى.
V2: تقديم عدم التطابق لتحسين استعلامات القراءة
السبب في أننا يجب أن نصدر المزيد من الطلبات في بعض الحالات هو أن نتائج الطلب الأولي لا تحتوي على جميع البيانات التي نحتاج إلى إرجاعها. يعمل نشر تكرار البيانات على حل هذا النوع من المشكلات عبر مجموعة البيانات لدينا عند العمل مع مخزن بيانات غير علائقي مثل Azure Cosmos DB.
في مثالنا، نقوم بتعديل عناصر المنشور لإضافة اسم مستخدم مؤلف المنشور وعدد التعليقات وعدد الإعجابات:
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"userUsername": "<post-author-username>",
"title": "<post-title>",
"content": "<post-content>",
"commentCount": <count-of-comments>,
"likeCount": <count-of-likes>,
"creationDate": "<post-creation-date>"
}
نقوم أيضاً بتعديل التعليقات وإبداء الإعجاب بالعناصر لإضافة اسم المستخدم الخاص بالمستخدم الذي قام بإنشائها:
{
"id": "<comment-id>",
"type": "comment",
"postId": "<post-id>",
"userId": "<comment-author-id>",
"userUsername": "<comment-author-username>",
"content": "<comment-content>",
"creationDate": "<comment-creation-date>"
}
{
"id": "<like-id>",
"type": "like",
"postId": "<post-id>",
"userId": "<liker-id>",
"userUsername": "<liker-username>",
"creationDate": "<like-creation-date>"
}
إضفاء الطابع الطبيعي على التعليق ومثل التهم
ما نريد تحقيقه هو أنه في كل مرة نضيف تعليقا أو ما شابه ذلك، نقوم أيضا بزيادة commentCount أو likeCount في المنشور المقابل. كما postId يقسم الحاوية لدينا posts ، العنصر الجديد (تعليق أو مثل)، وما بعده المقابلة تقع في نفس القسم المنطقي. ونتيجة لذلك، يمكننا استخدام إجراء مخزن لتنفيذ هذه العملية.
عند إنشاء تعليق ([C3])، بدلا من مجرد إضافة عنصر جديد في الحاوية posts ، نستدعي الإجراء المخزن التالي على تلك الحاوية:
function createComment(postId, comment) {
var collection = getContext().getCollection();
collection.readDocument(
`${collection.getAltLink()}/docs/${postId}`,
function (err, post) {
if (err) throw err;
post.commentCount++;
collection.replaceDocument(
post._self,
post,
function (err) {
if (err) throw err;
comment.postId = postId;
collection.createDocument(
collection.getSelfLink(),
comment
);
}
);
})
}
يأخذ هذا الإجراء المخزن معرف المنشور ونص التعليق الجديد كمعلمات، ثم:
- يستعيد المنشور
- زيادة
commentCount - يستبدل آخر
- يضيف التعليق الجديد
نظرا لتنفيذ الإجراءات المخزنة كمعاملات ذرية، تظل قيمة commentCount وعدد التعليقات الفعلي متزامنة دائما.
من الواضح أننا نستدعي إجراء مخزنا مشابها عند إضافة تسجيلات إعجاب جديدة لزيادة likeCount.
تشويه أسماء المستخدمين
تتطلب أسماء المستخدمين نهجاً مختلفاً حيث لا يجلس المستخدمون في أقسام مختلفة فحسب، بل في حاوية مختلفة. عندما يتعين علينا نشر تكرار البيانات عبر الأقسام والحاويات، يمكننا استخدام موجز تغيير الحاوية المصدر.
في مثالنا، نستخدم موجز التغيير للحاوية users للرد كلما حدث المستخدمون أسماء المستخدمين الخاصة بهم. عند حدوث ذلك، نقوم بنشر التغيير عن طريق استدعاء إجراء مخزن آخر على الحاوية posts :

function updateUsernames(userId, username) {
var collection = getContext().getCollection();
collection.queryDocuments(
collection.getSelfLink(),
`SELECT * FROM p WHERE p.userId = '${userId}'`,
function (err, results) {
if (err) throw err;
for (var i in results) {
var doc = results[i];
doc.userUsername = username;
collection.upsertDocument(
collection.getSelfLink(),
doc);
}
});
}
يأخذ هذا الإجراء المخزن معرف المستخدم واسم المستخدم الجديد الخاص بالمستخدم كمعلمات، ثم:
- إحضار كافة العناصر المطابقة
userIdل (والتي يمكن أن تكون منشورات أو تعليقات أو الإعجابات) - لكل عنصر من هذه العناصر
- يستبدل
userUsername - يستبدل العنصر
- يستبدل
هام
هذه العملية مكلفة لأنها تتطلب تنفيذ هذا الإجراء المخزن على كل قسم من الحاوية posts . نفترض أن معظم المستخدمين يختارون اسم مستخدم مناسباً أثناء التسجيل ولن يغيروه أبداً، لذلك نادراً ما يتم تشغيل هذا التحديث.
ما هي مكاسب أداء V2؟
لنتحدث عن بعض مكاسب الأداء ل V2.
[Q2] استرداد وظيفة
الآن بعد أن تم إلغاء التسوية لدينا، علينا فقط إحضار عنصر واحد للتعامل مع هذا الطلب.

| كمون | رسوم وحدة الطلب | اداء |
|---|---|---|
2 مللي ثانية |
1 رو |
✅ |
[Q4] قائمة تعليقات المنشور
هنا مرة أخرى، يمكننا تجنب الطلبات الإضافية التي جلبت أسماء المستخدمين وينتهي بها الأمر باستعلام واحد يقوم بالتصفية على مفتاح القسم.

| كمون | رسوم وحدة الطلب | اداء |
|---|---|---|
4 مللي ثانية |
7.72 رو |
✅ |
[Q5] ضع قائمة بإعجابات المنشور
نفس الموقف بالضبط عند سرد الإعجابات.

| كمون | رسوم وحدة الطلب | اداء |
|---|---|---|
4 مللي ثانية |
8.92 رو |
✅ |
V3: التأكد من أن جميع الطلبات قابلة للتطوير
لا يزال هناك طلبان لم نحسنهما بالكامل عند النظر في تحسينات الأداء الشاملة. هذه الطلبات هي [Q3] و [Q6]. إنها الطلبات التي تتضمن استعلامات لا تقوم بالتصفية على مفتاح القسم للحاويات التي تستهدفها.
[Q3] اذكر مشاركات المستخدم في شكل قصير
يستفيد هذا الطلب بالفعل من التحسينات المقدمة في V2، والتي توفر المزيد من الاستعلامات.

ولكن الاستعلام المتبقي لا يزال لا يقوم بالتصفية على مفتاح القسم للحاوية posts .
طريقة التفكير في هذا الوضع بسيطة:
- يجب تصفية هذا الطلب على
userIdلأننا نريد جلب جميع المنشورات لمستخدم معين. - لا يعمل بشكل جيد لأنه يتم تنفيذه على الحاوية
posts، والتي لا تحتويuserIdعلى تقسيمها. - بذكر ما هو واضح، سنحل مشكلة الأداء الخاصة بنا عن طريق تنفيذ هذا الطلب مقابل حاوية مقسمة مع
userId. - اتضح أن لدينا بالفعل مثل هذه الحاوية: الحاوية
users!
لذلك نقدم مستوى ثانيا من نشر التكرار عن طريق تكرار منشورات بأكملها إلى الحاوية users . من خلال القيام بذلك، نحصل بشكل فعال على نسخة من منشوراتنا، مقسمة فقط على بعد مختلف، ما يجعلها أكثر كفاءة لاستردادها بواسطة userId.
تحتوي الحاوية users الآن على نوعين من العناصر:
{
"id": "<user-id>",
"type": "user",
"userId": "<user-id>",
"username": "<username>"
}
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"userUsername": "<post-author-username>",
"title": "<post-title>",
"content": "<post-content>",
"commentCount": <count-of-comments>,
"likeCount": <count-of-likes>,
"creationDate": "<post-creation-date>"
}
في هذا المثال:
- لقد قدمنا حقلا
typeفي عنصر المستخدم لتمييز المستخدمين عن المنشورات، - لقد أضفنا أيضا حقلا
userIdفي عنصر المستخدم، وهو زائد عن الحاجة معidالحقل ولكنه مطلوب لأن الحاويةusersمقسمة الآن معuserId(وليسidكما كان من قبل)
لتحقيق ذلك إلغاء التطبيع، نستخدم تغذية التغيير مرة أخرى. هذه المرة، نتفاعل مع موجز التغيير للحاوية posts لإرسال أي منشور جديد أو محدث إلى الحاوية users . ولأن سرد المنشورات لا يتطلب إرجاع المحتوى الكامل، يمكننا اقتطاعها في العملية.

يمكننا الآن توجيه استعلامنا إلى الحاوية users ، والتصفية على مفتاح قسم الحاوية.

| كمون | رسوم وحدة الطلب | اداء |
|---|---|---|
4 مللي ثانية |
6.46 رو |
✅ |
[Q6] قم بإدراج x أحدث المشاركات التي تم إنشاؤها في شكل قصير (موجز)
علينا التعامل مع موقف مماثل هنا: حتى بعد توفير المزيد من الاستعلامات التي تركت غير ضرورية من خلال إلغاء التسوية المقدمة في V2، لا يقوم الاستعلام المتبقي بالتصفية على مفتاح قسم الحاوية:

باتباع نفس النهج، يتطلب تعظيم أداء هذا الطلب وقابلية التوسع أن يصل إلى قسم واحد فقط. يمكن تصور الوصول إلى قسم واحد فقط لأنه يتعين علينا فقط إرجاع عدد محدود من العناصر. من أجل ملء الصفحة الرئيسية لمنصة التدوين الخاصة بنا، نحتاج فقط إلى الحصول على أحدث 100 وظيفة، دون الحاجة إلى ترقيم الصفحات عبر مجموعة البيانات بأكملها.
لتحسين هذا الطلب الأخير، نقدم حاوية ثالثة لتصميمنا، مخصصة بالكامل لخدمة هذا الطلب. نقوم بنشر منشوراتنا على تلك الحاوية الجديدة feed :
{
"id": "<post-id>",
"type": "post",
"postId": "<post-id>",
"userId": "<post-author-id>",
"userUsername": "<post-author-username>",
"title": "<post-title>",
"content": "<post-content>",
"commentCount": <count-of-comments>,
"likeCount": <count-of-likes>,
"creationDate": "<post-creation-date>"
}
يقسم type الحقل هذه الحاوية، الموجودة دائما post في عناصرنا. يؤدي القيام بذلك إلى ضمان وضع جميع العناصر الموجودة في هذه الحاوية في نفس القسم.
لتحقيق عدم التطابق، علينا فقط ربط خط أنابيب التغذية المتغير الذي قدمناه سابقاً لإرسال المنشورات إلى تلك الحاوية الجديدة. من الأمور المهمة التي يجب مراعاتها هو أننا نحتاج إلى التأكد من أننا نقوم فقط بتخزين أحدث 100 مشاركة؛ وبخلاف ذلك، قد يزيد محتوى الحاوية عن الحد الأقصى لحجم القسم. يمكن تنفيذ هذا القيد عن طريق استدعاء مشغل لاحق في كل مرة تتم فيها إضافة مستند في الحاوية:
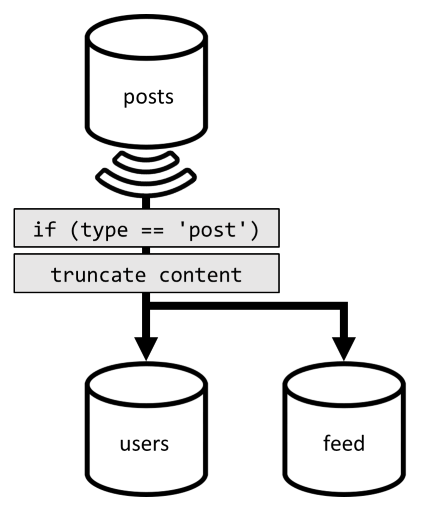
هذا هو نص عامل التشغيل اللاحق الذي يقطع المجموعة:
function truncateFeed() {
const maxDocs = 100;
var context = getContext();
var collection = context.getCollection();
collection.queryDocuments(
collection.getSelfLink(),
"SELECT VALUE COUNT(1) FROM f",
function (err, results) {
if (err) throw err;
processCountResults(results);
});
function processCountResults(results) {
// + 1 because the query didn't count the newly inserted doc
if ((results[0] + 1) > maxDocs) {
var docsToRemove = results[0] + 1 - maxDocs;
collection.queryDocuments(
collection.getSelfLink(),
`SELECT TOP ${docsToRemove} * FROM f ORDER BY f.creationDate`,
function (err, results) {
if (err) throw err;
processDocsToRemove(results, 0);
});
}
}
function processDocsToRemove(results, index) {
var doc = results[index];
if (doc) {
collection.deleteDocument(
doc._self,
function (err) {
if (err) throw err;
processDocsToRemove(results, index + 1);
});
}
}
}
الخطوة الأخيرة هي إعادة توجيه استعلامنا إلى الحاوية الجديدة feed :

| كمون | رسوم وحدة الطلب | اداء |
|---|---|---|
9 مللي ثانية |
16.97 رو |
✅ |
الخاتمة
دعونا نلقي نظرة على الأداء العام وتحسينات قابلية التوسع التي قدمناها عبر الإصدارات المختلفة من تصميمنا.
| V1 | V2 | V3 | |
|---|---|---|---|
| [C1] | 7 ms / 5.71 RU |
7 ms / 5.71 RU |
7 ms / 5.71 RU |
| [Q1] | 2 ms / 1 RU |
2 ms / 1 RU |
2 ms / 1 RU |
| [C2] | 9 ms / 8.76 RU |
9 ms / 8.76 RU |
9 ms / 8.76 RU |
| [Q2] | 9 ms / 19.54 RU |
2 ms / 1 RU |
2 ms / 1 RU |
| [Q3] | 130 ms / 619.41 RU |
28 ms / 201.54 RU |
4 ms / 6.46 RU |
| [C3] | 7 ms / 8.57 RU |
7 ms / 15.27 RU |
7 ms / 15.27 RU |
| [Q4] | 23 ms / 27.72 RU |
4 ms / 7.72 RU |
4 ms / 7.72 RU |
| [C4] | 6 ms / 7.05 RU |
7 ms / 14.67 RU |
7 ms / 14.67 RU |
| [Q5] | 59 ms / 58.92 RU |
4 ms / 8.92 RU |
4 ms / 8.92 RU |
| [Q6] | 306 ms / 2063.54 RU |
83 ms / 532.33 RU |
9 ms / 16.97 RU |
لقد قمنا بتحسين سيناريو ثقيل القراءة
ربما لاحظت أننا ركزنا جهودنا نحو تحسين أداء طلبات القراءة (الاستعلامات) على حساب طلبات الكتابة (الأوامر). في كثير من الحالات، تؤدي عمليات الكتابة الآن إلى عدم التطابق اللاحق من خلال تغذيات التغيير، ما يجعلها أكثر تكلفة من الناحية الحسابية وأطول في الواقع.
نحن نبرر هذا التركيز على أداء القراءة من خلال حقيقة أن منصة التدوين (مثل معظم التطبيقات الاجتماعية) ثقيلة القراءة. يشير حمل العمل الثقيل للقراءة إلى أن كمية طلبات القراءة التي يجب أن تخدمها عادة ما تكون طلبات ذات حجم أعلى من عدد طلبات الكتابة. لذلك من المنطقي جعل تنفيذ طلبات الكتابة أكثر تكلفة من أجل جعل طلبات القراءة أرخص وأفضل أداءً.
إذا نظرنا إلى التحسين الأكثر تطرفا الذي أجريناه، فقد انتقل [Q6] من 2000+ وحدة طلب إلى 17 وحدة طلب فقط؛ لقد حققنا ذلك من خلال نشر تكرار المنشورات بتكلفة تبلغ حوالي 10 وحدات طلب لكل عنصر. نظراً لأننا سنخدم عدداً أكبر بكثير من طلبات الخلاصة من إنشاء المنشورات أو تحديثها، فإن تكلفة إلغاء التطابق هذه ضئيلة بالنظر إلى المدخرات الإجمالية.
يمكن تطبيق عدم التطابق بشكل تدريجي
تتضمن تحسينات قابلية التوسع التي اكتشفناها في هذه المقالة إلغاء التطابق وتكرار البيانات عبر مجموعة البيانات. وتجدر الإشارة إلى أن هذه التحسينات لا يلزم تنفيذها في اليوم الأول. تعمل الاستعلامات التي تقوم بالتصفية على مفاتيح الأقسام بشكل أفضل على نطاق واسع، ولكن يمكن قبول الاستعلامات عبر الأقسام إذا تم استدعاؤها نادرا أو مقابل مجموعة بيانات محدودة. إذا كنت تقوم فقط ببناء نموذج أولي، أو إطلاق منتج مع قاعدة مستخدمين صغيرة ويتم التحكم فيها، يمكنك على الأرجح توفير هذه التحسينات في وقت لاحق. ما هو مهم بعد ذلك هو مراقبة أداء النموذج الخاص بك حتى تتمكن من تحديد ما إذا كان الوقت قد حان لإحضارهم ومتى.
تُخزن خلاصة التغيير التي نستخدمها لتوزيع التحديثات على الحاويات الأخرى كل هذه التحديثات باستمرار. هذا الثبات يجعل من الممكن طلب جميع التحديثات منذ إنشاء الحاوية وطرق العرض التي تم إلغاء تكرارها كتشغيل اللحاق بالركب لمرة واحدة حتى إذا كان نظامك يحتوي بالفعل على العديد من البيانات.
الخطوات التالية
بعد هذه المقدمة لنمذجة البيانات العملية وتقسيمها، قد تحتاج إلى التحقق من المقالات التالية لمراجعة المفاهيم التي قمنا بتغطيتها: