إشعار
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
هام
لم يعد Azure Cosmos DB ل PostgreSQL مدعوما للمشاريع الجديدة. لا تستخدم هذه الخدمة لمشاريع جديدة. بدلا من ذلك، استخدم إحدى هاتين الخدمتين:
استخدم Azure Cosmos DB ل NoSQL لحل قاعدة بيانات موزعة مصمم للسيناريوهات عالية النطاق مع اتفاقية مستوى خدمة توفر 99.999% (SLA) والتحجيم التلقائي الفوري وتجاوز الفشل التلقائي عبر مناطق متعددة.
استخدم ميزة المجموعات المرنة في قاعدة بيانات Azure ل PostgreSQL المجزأة باستخدام ملحق Citus مفتوح المصدر.
في هذا البرنامج التعليمي، يمكنك استخدام Azure Cosmos DB ل PostgreSQL لمعرفة كيفية:
- إنشاء نظام مجموعة
- استخدام الأداة المساعدة psql لإنشاء مخطط
- تقطيع الجداول عبر العقد
- إنشاء عينات البيانات
- تنفيذ عمليات تجميع
- الاستعلام عن البيانات الأولية والمجمعة
- انتهاء صلاحية البيانات
المتطلبات الأساسية
في حال لم يكن لديك اشتراك Azure، فأنشئ حساباً مجانيّاً قبل البدء.
إنشاء نظام مجموعة
سجل الدخول إلى مدخل Microsoft Azure واتبع هذه الخطوات لإنشاء نظام مجموعة Azure Cosmos DB ل PostgreSQL:
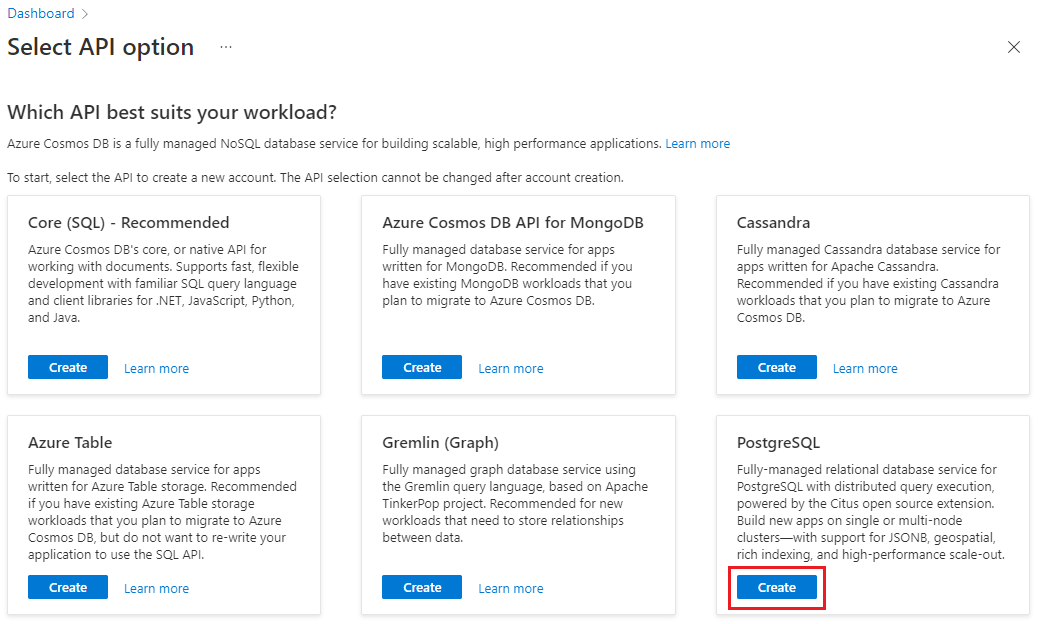
انتقل إلى إنشاء Azure Cosmos DB لنظام مجموعة PostgreSQL في مدخل Microsoft Azure.
في نموذج إنشاء Azure Cosmos DB لنظام مجموعة PostgreSQL:
املأ المعلومات في علامة التبويب الأساسيات .
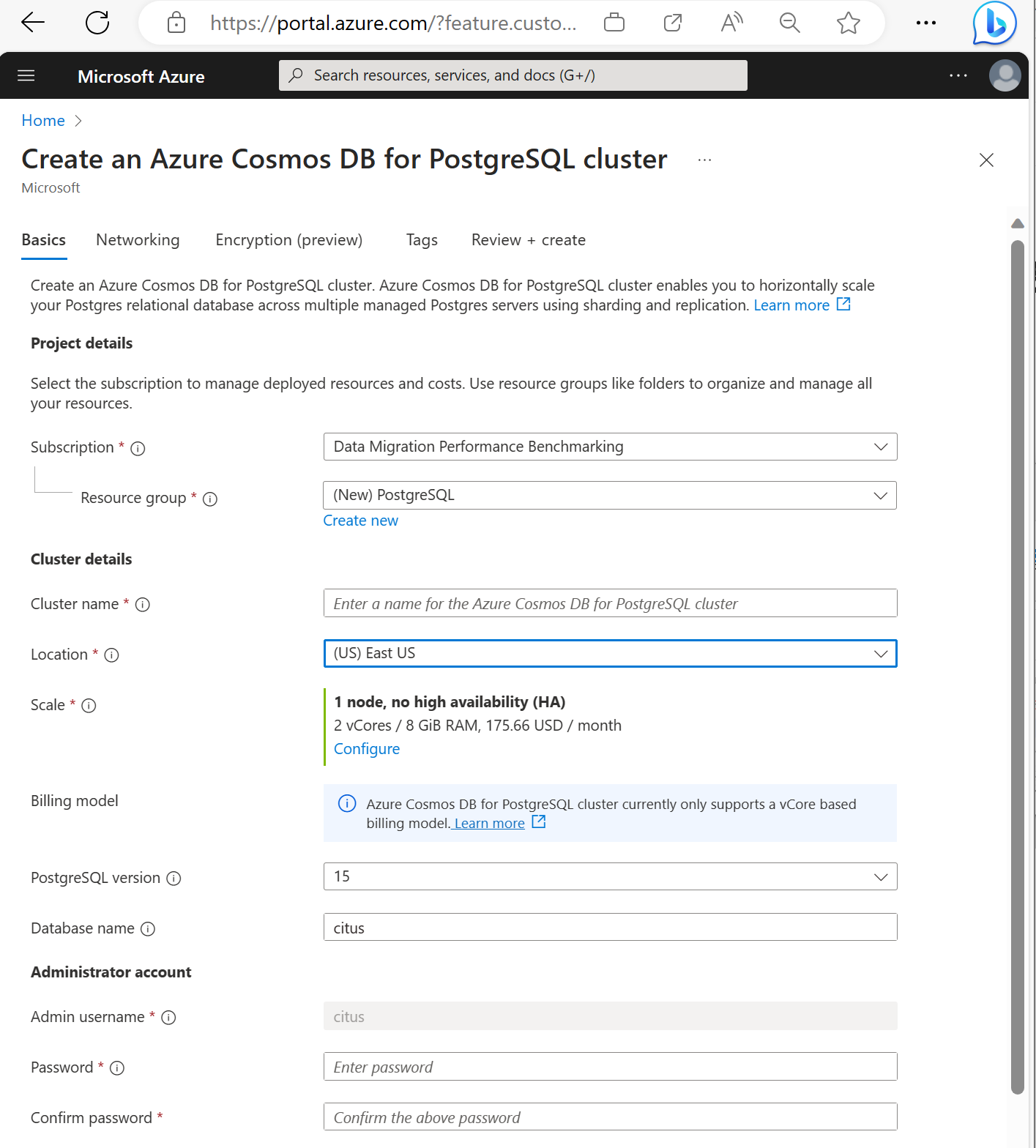
معظم الخيارات تفسر بعضها بعضًا، لكن ضع في اعتبارك:
- يحدد اسم نظام المجموعة اسم DNS الذي تستخدمه التطبيقات للاتصال، في النموذج
<node-qualifier>-<clustername>.<uniqueID>.postgres.cosmos.azure.com. - يمكنك اختيار إصدار PostgreSQL رئيسي مثل 15. يدعم Azure Cosmos DB ل PostgreSQL دائما أحدث إصدار من Citus لإصدار Postgres الرئيسي المحدد.
- يجب أن يكون اسم المستخدم المسؤول هو القيمة
citus. - يمكنك ترك اسم قاعدة البيانات بقيمته الافتراضية "citus" أو تعريف اسم قاعدة البيانات الوحيد. لا يمكنك إعادة تسمية قاعدة البيانات بعد توفير نظام المجموعة.
- يحدد اسم نظام المجموعة اسم DNS الذي تستخدمه التطبيقات للاتصال، في النموذج
حدد Next : Networking أسفل الشاشة.
في شاشة Networking ، حدد Allow public access from Azure services and resources within Azure to this cluster.
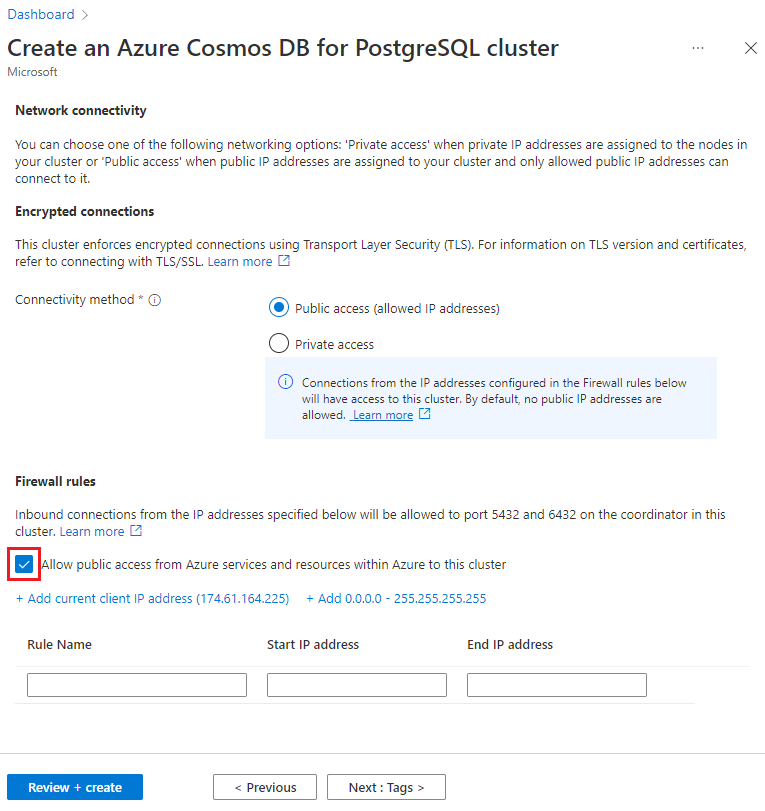
حدد Review + create، وعند اجتياز التحقق من الصحة، حدد Create لإنشاء نظام المجموعة.
يستغرق التزويد بضع دقائق. تعيد الصفحة توجيهها لمراقبة التوزيع. عندما تتغير الحالة من النشر قيد التقدم إلى اكتمال النشر الخاص بك، حدد Go to resource.
استخدام الأداة المساعدة psql لإنشاء مخطط
بمجرد الاتصال ب Azure Cosmos DB ل PostgreSQL باستخدام psql، يمكنك إكمال بعض المهام الأساسية. يرشدك هذا البرنامج التعليمي خلال استيعاب بيانات نسبة استخدام الشبكة من تحليلات الويب، ثم تجميع البيانات لتوفير لوحات معلومات في الوقت الفعلي استنادًا إلى تلك البيانات.
لننشئ جدولاً يستهلك جميع بيانات استخدام شبكة الويب الأولية لدينا. شغّل الأوامر التالية في وحدة psql الطرفية:
CREATE TABLE http_request (
site_id INT,
ingest_time TIMESTAMPTZ DEFAULT now(),
url TEXT,
request_country TEXT,
ip_address TEXT,
status_code INT,
response_time_msec INT
);
سنقوم أيضًا بإنشاء جدول يحتوي على تجميعاتنا لكل دقيقة، وجدول يحافظ على موضع آخر مجموعة لدينا. شغّل الأوامر التالية في psql أيضًا:
CREATE TABLE http_request_1min (
site_id INT,
ingest_time TIMESTAMPTZ, -- which minute this row represents
error_count INT,
success_count INT,
request_count INT,
average_response_time_msec INT,
CHECK (request_count = error_count + success_count),
CHECK (ingest_time = date_trunc('minute', ingest_time))
);
CREATE INDEX http_request_1min_idx ON http_request_1min (site_id, ingest_time);
CREATE TABLE latest_rollup (
minute timestamptz PRIMARY KEY,
CHECK (minute = date_trunc('minute', minute))
);
يمكنك الآن رؤية الجداول التي تم إنشاؤها حديثًا في قائمة الجداول باستخدام الأمر psql هذا:
\dt
تقطيع الجداول عبر العقد
يخزن Azure Cosmos DB لتوزيع PostgreSQL صفوف الجدول على عقد مختلفة استنادا إلى قيمة عمود معين من قبل المستخدم. يشير "عمود التوزيع" هذا إلى كيفية تجزئة البيانات عبر العقد.
لنقم بتعيين عمود التوزيع ليكون site_id، وهو مفتاح الجزء. في psql، شغّل هذه الدوال:
SELECT create_distributed_table('http_request', 'site_id');
SELECT create_distributed_table('http_request_1min', 'site_id');
هام
يعد توزيع الجداول أو استخدام التقسيم المستند إلى المخطط ضروريا للاستفادة من Azure Cosmos DB لميزات أداء PostgreSQL. إذا لم توزع الجداول أو المخططات، فلن تساعد العقد العاملة في تشغيل الاستعلامات التي تتضمن بياناتها.
إنشاء عينات البيانات
الآن يجب أن تكون مجموعتنا جاهزة لاستيعاب بعض البيانات. يمكننا تشغيل ما يلي محليا من اتصالنا psql لإدراج البيانات باستمرار.
DO $$
BEGIN LOOP
INSERT INTO http_request (
site_id, ingest_time, url, request_country,
ip_address, status_code, response_time_msec
) VALUES (
trunc(random()*32), clock_timestamp(),
concat('http://example.com/', md5(random()::text)),
('{China,India,USA,Indonesia}'::text[])[ceil(random()*4)],
concat(
trunc(random()*250 + 2), '.',
trunc(random()*250 + 2), '.',
trunc(random()*250 + 2), '.',
trunc(random()*250 + 2)
)::inet,
('{200,404}'::int[])[ceil(random()*2)],
5+trunc(random()*150)
);
COMMIT;
PERFORM pg_sleep(random() * 0.25);
END LOOP;
END $$;
يعمل الاستعلام على إدراج ثمانية صفوف تقريبًا كل ثانية. يتم تخزين الصفوف على عقد عاملة مختلفة كما هو موجه بواسطة عمود التوزيع، site_id.
إشعار
اترك استعلام إنشاء البيانات قيد التشغيل، وافتح اتصال psql ثانٍ للأوامر المتبقية في هذا البرنامج التعليمي.
الاستعلام
يسمح Azure Cosmos DB ل PostgreSQL لعقد متعددة بمعالجة الاستعلامات بالتوازي مع السرعة. على سبيل المثال، تحسب قاعدة البيانات تجميعات مثل SUM وCOUNT في عقد عاملة، وتجمع النتائج في إجابة نهائية.
إليك استعلام لحساب عدد طلبات الويب في الدقيقة مع بعض الإحصائيات. حاول تشغيله في psql، ولاحظ النتائج.
SELECT
site_id,
date_trunc('minute', ingest_time) as minute,
COUNT(1) AS request_count,
SUM(CASE WHEN (status_code between 200 and 299) THEN 1 ELSE 0 END) as success_count,
SUM(CASE WHEN (status_code between 200 and 299) THEN 0 ELSE 1 END) as error_count,
SUM(response_time_msec) / COUNT(1) AS average_response_time_msec
FROM http_request
WHERE date_trunc('minute', ingest_time) > now() - '5 minutes'::interval
GROUP BY site_id, minute
ORDER BY minute ASC;
تجميع البيانات
يعمل الاستعلام السابق بشكل جيد في المراحل المبكرة؛ لكن أداؤه يتدهور بالتزامن مع تغير حجم بياناتك. حتى في وجود المعالجة الموزعة، يكون الحساب المسبق للبيانات أسرع من إعادة حسابها بشكل متكرر.
يمكننا ضمان بقاء لوحة المعلومات التي نوفرها سريعة عن طريق تجميع البيانات الأولية بانتظام ضمن جدول تجميع. يمكنك تجربة مدة التجميع. استخدمنا جدول تجميع بمعدل كل دقيقة؛ ولكن يمكنك تقسيم البيانات إلى 5 أو 15 أو 60 دقيقة بدلاً من ذلك.
لتشغيل هذا التجميع بسهولة أكبر، سنضعه ضمن دالة plpgsql. قم بتشغيل هذه الأوامر في psql لإنشاء الدالة rollup_http_request .
-- initialize to a time long ago
INSERT INTO latest_rollup VALUES ('10-10-1901');
-- function to do the rollup
CREATE OR REPLACE FUNCTION rollup_http_request() RETURNS void AS $$
DECLARE
curr_rollup_time timestamptz := date_trunc('minute', now());
last_rollup_time timestamptz := minute from latest_rollup;
BEGIN
INSERT INTO http_request_1min (
site_id, ingest_time, request_count,
success_count, error_count, average_response_time_msec
) SELECT
site_id,
date_trunc('minute', ingest_time),
COUNT(1) as request_count,
SUM(CASE WHEN (status_code between 200 and 299) THEN 1 ELSE 0 END) as success_count,
SUM(CASE WHEN (status_code between 200 and 299) THEN 0 ELSE 1 END) as error_count,
SUM(response_time_msec) / COUNT(1) AS average_response_time_msec
FROM http_request
-- roll up only data new since last_rollup_time
WHERE date_trunc('minute', ingest_time) <@
tstzrange(last_rollup_time, curr_rollup_time, '(]')
GROUP BY 1, 2;
-- update the value in latest_rollup so that next time we run the
-- rollup it will operate on data newer than curr_rollup_time
UPDATE latest_rollup SET minute = curr_rollup_time;
END;
$$ LANGUAGE plpgsql;
بعد أن أصبحت الدالة جاهزة، قم بتنفيذها لتجميع البيانات:
SELECT rollup_http_request();
وباستخدام بياناتنا في نموذج مُجمَّع مسبقًا، يمكننا الاستعلام عن جدول التجميع للحصول على التقرير نفسه كما في السابق. قم بتشغيل الاستعلام التالي:
SELECT site_id, ingest_time as minute, request_count,
success_count, error_count, average_response_time_msec
FROM http_request_1min
WHERE ingest_time > date_trunc('minute', now()) - '5 minutes'::interval;
انتهاء صلاحية البيانات القديمة
تعمل التجميعات على جعل الاستعلامات أسرع؛ لكننا ما زلنا بحاجة إلى انتهاء صلاحية البيانات القديمة لتجنب تكاليف التخزين غير المحدودة. حدد المدة التي تريدها للاحتفاظ بالبيانات لكل تنفيذ متكرر، واستخدم الاستعلامات القياسية لحذف البيانات منتهية الصلاحية. في المثال التالي، قررنا الاحتفاظ بالبيانات الأولية ليوم واحد، والاحتفاظ بالتجميعات التي تتم كل دقيقة لمدة شهر واحد:
DELETE FROM http_request WHERE ingest_time < now() - interval '1 day';
DELETE FROM http_request_1min WHERE ingest_time < now() - interval '1 month';
في الإنتاج، يمكنك تضمين هذه الاستعلامات في دالة، واستدعاؤها كل دقيقة في وظيفة cron.
تنظيف الموارد
في الخطوات السابقة، قمت بإنشاء موارد Azure في نظام مجموعة. إذا كنت لا تتوقع أن تحتاج إلى هذه الموارد في المستقبل، فاحذف نظام المجموعة. اضغط على الزر Delete في صفحة Overview لنظام المجموعة. عند مطالبتك في صفحة منبثقة، تأكد من اسم المجموعة وانقر فوق الزر حذف النهائي.
الخطوات التالية
في هذا البرنامج التعليمي، تعلمت كيفية توفير نظام مجموعة. كنت متصلاً معها بواسطة psql، وأنشأت مخططًا، ووزعت البيانات. لقد تعلمت الاستعلام عن البيانات في النموذج الأولي، وتجميع تلك البيانات بانتظام، والاستعلام عن الجداول المجمعة، وإنهاء صلاحية البيانات القديمة.
- تعرف على أنواع عقد نظام المجموعة
- تحديد أفضل حجم أولي لنظام المجموعة