إشعار
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
ينطبق على: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
تلميح
Data Factory في Microsoft Fabric هو الجيل القادم من Azure Data Factory، مع بنية أبسط، وذكاء اصطناعي مدمج، وميزات جديدة. إذا كنت جديدا في تكامل البيانات، ابدأ مع Fabric Data Factory. يمكن لأعباء عمل ADF الحالية الترقية إلى Fabric للوصول إلى قدرات جديدة في علوم البيانات، والتحليلات اللحظية، والتقارير.
Azure Data Factory هو خدمة تكامل البيانات وETL من Microsoft في السحابة. توفر هذه الورقة إرشادات ل DataOps في مصنع البيانات. لا يقصد به أن يكون تعليميا كاملا على CI/CD أو Git أو DevOps. بدلا من ذلك، ستجد إرشادات فريق مصنع البيانات لتحقيق DataOps في الخدمة مع مراجع لروابط التنفيذ التفصيلية لأفضل ممارسات نشر مصنع البيانات وإدارة المصنع والحوكمة. هناك قسم الموارد في نهاية هذه الورقة مع روابط إلى البرامج التعليمية.
ما هي DataOps؟
DataOps هي عملية تمارسها مؤسسات البيانات لإدارة البيانات التعاونية تهدف إلى توفير قيمة أسرع لصانعي القرار.
يوفر Gartner هذا التعريف الواضح ل DataOps:
DataOps هي ممارسة تعاونية لإدارة البيانات تركز على تحسين الاتصال والتكامل والتشغيل التلقائي لتدفقات البيانات بين مديري البيانات ومستهلكي البيانات عبر المؤسسة. الهدف من DataOps هو تقديم قيمة أسرع من خلال إنشاء تسليم قابل للتنبؤ وتغيير إدارة البيانات ونماذج البيانات والبيانات الاصطناعية ذات الصلة. يستخدم DataOps التكنولوجيا لأتمتة تصميم وتوزيع وإدارة تسليم البيانات مع مستويات مناسبة من الحوكمة ويستخدم بيانات التعريف لتحسين قابلية استخدام البيانات وقيمتها في بيئة ديناميكية.
كيف تحقق DataOps في Azure Data Factory؟
يوفر Azure Data Factory لمهندسي البيانات نموذجا بصريا لخط أنابيب البيانات لبناء تكامل بيانات على نطاق سحابة ومشاريع ETL بسهولة. تعتمد Data Factory على التكاملات الأصلية مع أدوات التحكم في الإصدارات الناضجة مثل GitHub وAzure DevOps، بالإضافة إلى نظام Azure الأوسع، لتوفير العديد من الميزات المدمجة لتسهيل DataOps التي تشمل التعاون الغني، والحوكمة، وعلاقات القطع الأثرية.
تحديدا، بمجرد إحضار مستودع GitHub أو Azure DevOps الخاص بك إلى مصنع البيانات، توفر الخدمة خيارات واجهة مستخدم مدمجة بديهية للأوامر الشائعة، مثل الالتزامات، وحفظ التشويهات، والتحكم في الإصدارات. توفر الخدمة أيضا خيار توفير أفضل ممارسات CI/CD وتسجيل الوصول إلى التعليمات البرمجية، لحماية سلامة بيئة الإنتاج وصحتها.
"Code" in Azure Data Factory
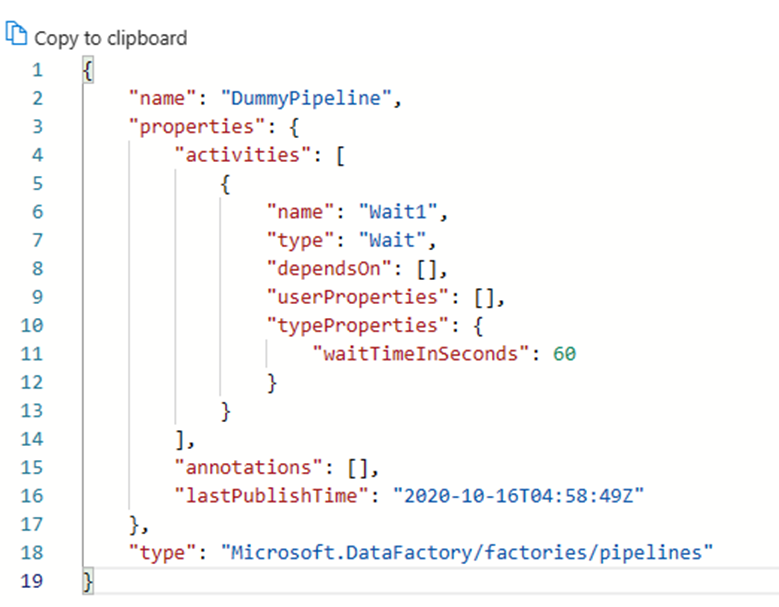
جميع القطع الأثرية في Azure Data Factory، سواء كانت خطوط أنابيب أو خدمات مرتبطة أو مشغلات، لها تمثيلات "كود" مقابلة في JSON خلف تكامل واجهة المستخدم البصرية. تعمل هذه القطع الأثرية وفقا لمعايير Azure Resource Manager القوالب. يمكنك العثور على التعليمات البرمجية بالنقر فوق أيقونة القوس في الجزء العلوي الأيسر من اللوحة. نموذج JSON "التعليمات البرمجية" سيبدو كما يلي:
الوضع المباشر والتحكم في إصدار Git
كل مصنع لديه مصدر واحد للحقيقة: المسارات والخدمات المرتبطة وتعريفات المشغل المخزنة داخل الخدمة. مصدر الحقيقة هذا هو ما يتم تشغيل البنية الأساسية لبرنامج ربط العمليات التجارية تنفيذه وما يحدد سلوكيات المشغلات. إذا كنت في الوضع المباشر، في كل مرة تنشر فيها، فإنك تعدل مباشرة مصدر الحقيقة الوحيد. تظهر الصورة التالية شكل الزر نشر الكل في الوضع المباشر.

يمكن أن يكون الوضع المباشر مناسبا لشخص واحد يعمل على مشاريع جانبية، لأنه يسمح للمطورين برؤية التأثيرات الفورية لتغييرات التعليمات البرمجية الخاصة بهم. ومع ذلك، لا ينصح بفريق من المطورين الذين يعملون على مشاريع العمل على مستوى الإنتاج. وتشمل المخاطر أصابع الدهون، والحذف العرضي للموارد الهامة، ونشر الرموز غير المختبرة، وما إلى ذلك، على سبيل المثال لا الحصر. عند العمل على المشاريع والأنظمة الأساسية المهمة للمهمة، ضع في اعتبارك إحضار مستودع Git واستخدام وضع Git في مصنع البيانات لتبسيط عملية التطوير. يساعدك التحكم في الإصدار وقدرات تسجيل الوصول المسورة في وضع Git على منع معظم الحوادث المرتبطة باللمس مباشرة، إن لم يكن كلها.
إشعار
في وضع Git، سيتم استبدال الزر نشر أو نشر الكل بحفظ أو حفظ الكل، ويتم الالتزام بالتغييرات الخاصة بك إلى الفروع الخاصة بك (وليس تغيير قواعد التعليمات البرمجية المباشرة مباشرة).
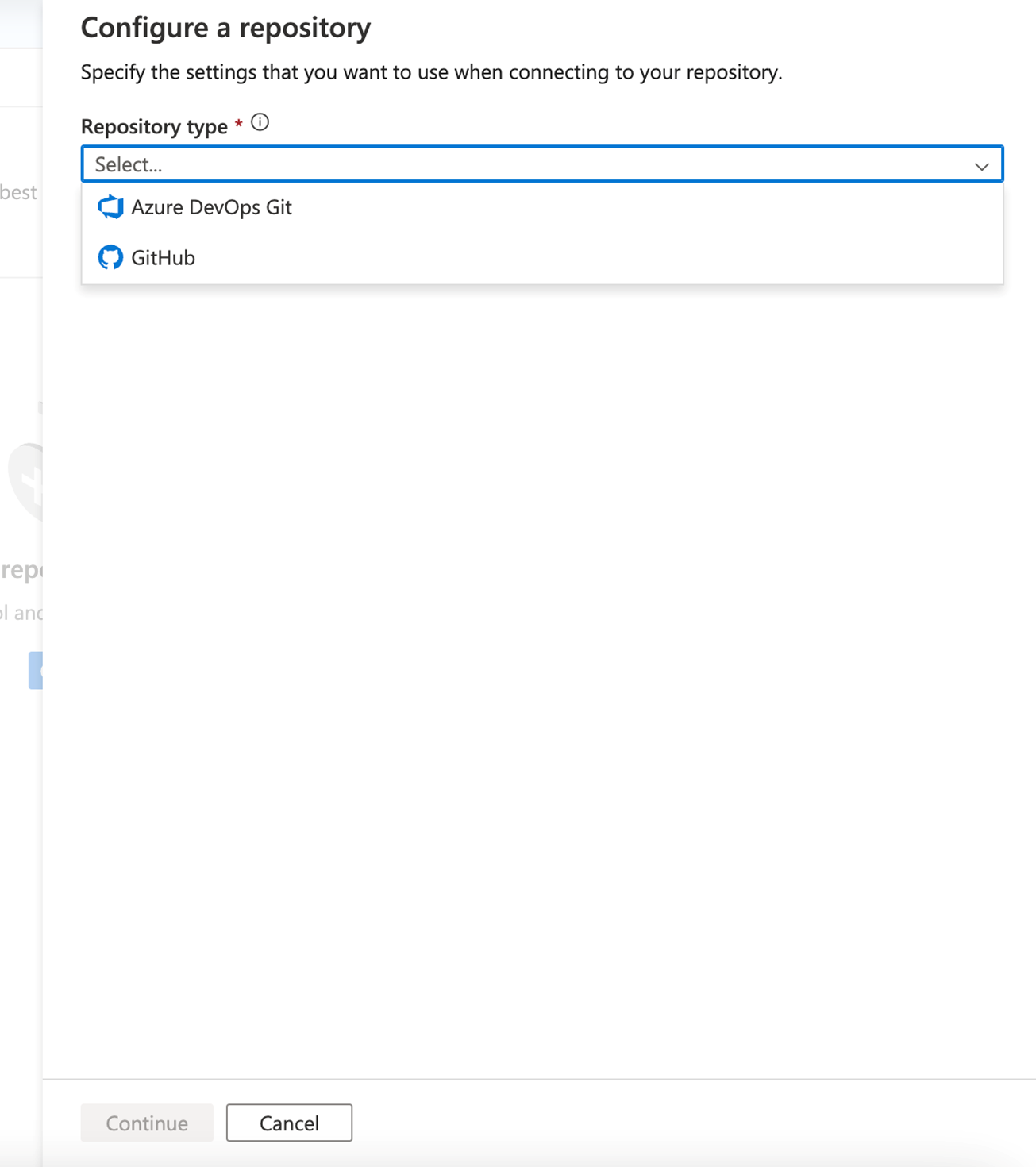
إعداد دمج GitHub و Azure DevOps
في Azure Data Factory، ينصح بشدة بتخزين مستودعك إما في GitHub أو Azure DevOps. تدعم الخدمة بشكل كامل كلا الأسلوبين ويعتمد اختيار المستودع الذي سيتم استخدامه على معايير مؤسستك الفردية. هناك طريقتان لإنشاء مستودع جديد أو للاتصال بمستودع موجود: استخدام بوابة Azure أو الإنشاء من واجهة Azure Data Factory Studio UI
إنشاء مصنع بوابة Azure
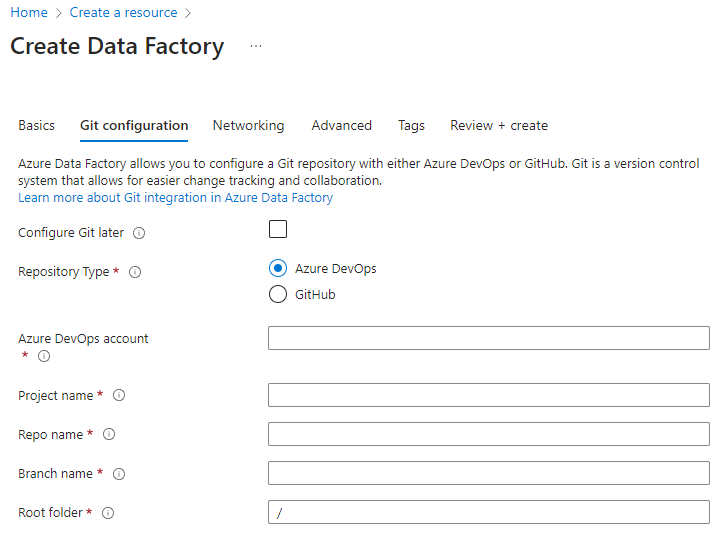
عندما تنشئ مصنع بيانات جديد من بوابة Azure، يكون المستودع الافتراضي ل Git هو Azure DevOps. يمكنك أيضا اختيار GitHub كمستودع وضبط إعدادات المستودع.
من بوابة Azure، اختر نوع المستودع وأدخل أسماء المستودعات والفروع لإنشاء مصنع جديد مدمج أصليا مع Git.
تطبيق استخدام Git مع Azure Policy في مؤسستك
استخدام Git في مشاريع Azure Data Factory هو ممارسة موصى بها بشدة. حتى إذا كنت لا تنفذ عملية CI/CD كاملة، فإن تكامل Git مع ADF يتيح حفظ البيانات الاصطناعية لموردك في بيئة الاختبار المعزولة الخاصة بك (فرع Git) حيث يمكنك اختبار تغييراتك بشكل مستقل عن بقية فروع المصنع. يمكنك use Azure Policy لفرض استخدام Git في مصنع مؤسستك.
Azure Data Factory Studio
بعد إنشاء مصنع البيانات الخاص بك، يمكنك أيضا الاتصال بمستودعك عبر Azure Data Factory Studio. في علامة التبويب إدارة ، سترى خيار تكوين إعدادات المستودع والردع.

من خلال عملية موجهة، يتم توجيهك من خلال سلسلة من الخطوات لمساعدتك في تكوين المستودع الذي تختاره والاتصال به بسهولة. بمجرد الإعداد الكامل، يمكنك البدء في العمل بشكل تعاوني وحفظ مواردك في المستودع الخاص بك.
الدمج المستمر والتسليم المستمر (CI/CD)
CI/CD هو نموذج لتطوير التعليمات البرمجية حيث يتم فحص التغييرات واختبارها أثناء انتقالها عبر مراحل مختلفة - التطوير والاختبار والتقسيم المرحلي وما إلى ذلك. بعد مراجعتها واختبارها من خلال كل مرحلة يتم نشرها أخيرا على قواعد التعليمات البرمجية المباشرة في بيئة إنتاج.
التكامل المستمر (CI) هو ممارسة الاختبار والتحقق تلقائيا في كل مرة يقوم فيها المطور بإجراء تغيير على قاعدة التعليمات البرمجية الخاصة بك. التسليم المستمر (CD) يعني أنه بعد نجاح اختبارات التكامل المستمر، يتم إحضار التغييرات إلى المرحلة التالية بشكل مستمر.
كما نوقش بإيجاز سابقا، فإن "الكود" في Azure Data Factory يأخذ شكل قالب Azure Resource Manager JSON. ومن ثم، تتضمن التغييرات التي تمر بعملية التكامل والتسليم المستمر (CI/CD) الإضافات والحذف والتحرير إلى الكائنات الثنائية كبيرة الحجم JSON.
Pipeline يعمل في Azure Data Factory
قبل الحديث عن CI/CD في Azure Data Factory، نحتاج أولا إلى الحديث عن كيفية تشغيل الخدمة لخط الأنابيب. قبل أن يقوم مصنع البيانات بتشغيل البنية الأساسية لبرنامج ربط العمليات التجارية، فإنه يقوم بالأشياء التالية:
- يسحب أحدث تعريف منشور للبنية الأساسية لبرنامج ربط العمليات التجارية، والأصول المرتبطة به، مثل مجموعة (مجموعات البيانات) والخدمة (الخدمات) المرتبطة وما إلى ذلك.
- تجميعها إلى إجراءات؛ إذا قام مصنع البيانات بتنفيذه مؤخرا، فإنه يسترد الإجراءات من التجميعات المخزنة مؤقتا.
- تشغيل البنية الأساسية لبرنامج ربط العمليات التجارية.
يتطلب تشغيل البنية الأساسية لبرنامج ربط العمليات التجارية الخطوات التالية:
- تأخذ الخدمة لقطة النقطة الزمنية لتعريف البنية الأساسية لبرنامج ربط العمليات التجارية.
- طوال مدة البنية الأساسية لبرنامج ربط العمليات التجارية، لا تتغير التعريفات.
- حتى إذا كانت البنية الأساسية لبرنامج ربط العمليات التجارية الخاصة بك تعمل لفترة طويلة، فإنها لا تتأثر بالتغييرات اللاحقة التي تم إجراؤها بعد بدء تشغيلها. إذا قمت بنشر تغييرات على الخدمة المرتبطة، والتدفقات، وما إلى ذلك، أثناء التشغيل، فلن تؤثر هذه التغييرات على عمليات التشغيل قيد التقدم.
- عند نشر التغييرات، بدأت عمليات التشغيل اللاحقة بعد النشر باستخدام التعريفات المحدثة.
Publishing in Azure Data Factory
بغض النظر عما إذا كنت تنشر خطوط الأنابيب باستخدام Azure Release Pipeline لأتمتة النشر، أو باستخدام Manual Deploy لقوالب Resource Manager، في الخلفية، النشر هو سلسلة من عمليات الإنشاء/التحديث على datasets، services linked, pipelines، و triggers، لكل من التشويهات. التأثير هو نفس إجراء استدعاءات Rest API الأساسية مباشرة.
تأتي بعض الأشياء من الإجراءات هنا:
- كل استدعاءات واجهة برمجة التطبيقات هذه متزامنة، ما يعني أن الاستدعاء يرجع فقط عند نجاح/فشل النشر. لن تكون هناك حالة توزيع جزئي للبيانات الاصطناعية.
- استدعاءات واجهة برمجة التطبيقات متسلسلة إلى حد كبير. نحاول موازاة الاستدعاءات، مع الحفاظ على التبعيات المرجعية للبيانات الاصطناعية. ترتيب عمليات التوزيع هو خدمة مرتبطة -> مجموعة البيانات / وقت تشغيل التكامل -> البنية الأساسية لبرنامج ربط العمليات التجارية -> المشغل. يضمن هذا الترتيب أن البيانات الاصطناعية التابعة يمكنها الرجوع إلى تبعياتها بشكل صحيح. على سبيل المثال، تعتمد البنية الأساسية لبرنامج ربط العمليات التجارية على مجموعات البيانات، ومن ثم ينشرها مصنع البيانات بعد مجموعات البيانات.
- توزيع الخدمات المرتبطة ومجموعات البيانات وما إلى ذلك مستقلة عن المسارات. هناك حالات يقوم فيها مصنع البيانات بتحديث الخدمات المرتبطة قبل تحديث البنية الأساسية لبرنامج ربط العمليات التجارية. سنتحدث عن هذا الموقف في القسم متى يتم إيقاف المشغل.
- لن يؤدي النشر إلى حذف البيانات الاصطناعية من المصانع. تحتاج إلى استدعاء واجهات برمجة تطبيقات الحذف بشكل صريح لكل نوع من أنواع البيانات الاصطناعية (البنية الأساسية لبرنامج ربط العمليات التجارية، ومجموعة البيانات، والخدمة المرتبطة، وما إلى ذلك) لتنظيف المصنع. راجع على سبيل المثال نص ما بعد النشر من Azure Data Factory.
- حتى إذا لم تقم بلمس مسار أو مجموعة بيانات أو خدمة مرتبطة، فإنه لا يزال يستدعي استدعاء واجهة برمجة تطبيقات تحديث سريع للمصنع.
مشغلات النشر
- المشغلات لها حالات: بدأت أو توقفت.
- لا يمكنك إجراء تغييرات على مشغل في وضع البدء . تحتاج إلى إيقاف مشغل قبل نشر أي تغييرات.
- يمكنك استدعاء إنشاء أو تحديث واجهة برمجة تطبيقات المشغل على مشغل في وضع البدء .
- إذا تغيرت الحمولة، تفشل واجهة برمجة التطبيقات.
- إذا ظلت الحمولة دون تغيير، تنجح واجهة برمجة التطبيقات.
- هذا السلوك له تأثير عميق على وقت إيقاف المشغل.
متى يتم إيقاف مشغل
عندما يتعلق الأمر بالنشر في مصنع بيانات الإنتاج، مع تشغيل المشغلات المباشرة للبنية الأساسية لبرنامج ربط العمليات التجارية طوال الوقت، يصبح السؤال "هل يجب علينا إيقافها؟".
الجواب المختصر هو أنه في السيناريوهات القليلة التالية فقط يجب أن تفكر في إيقاف المشغل:
- تحتاج إلى إيقاف المشغل إذا كنت تقوم بتحديث تعريفات المشغل، بما في ذلك حقول مثل تاريخ الانتهاء والتردد واقتران المسار.
- يوصى بإيقاف المشغل إذا كنت تقوم بتحديث مجموعات البيانات أو الخدمات المرتبطة المشار إليها في مسار مباشر. على سبيل المثال، إذا كنت تقوم بتدوير بيانات الاعتماد ل SQL Server.
- يمكنك اختيار إيقاف المشغل إذا كان المسار المقترن يطرح أخطاء ويفشل ويثقل الخوادم الخاصة بك.
فيما يلي النقاط القليلة التي يجب مراعاتها فيما يتعلق بإيقاف المشغلات:
- كما هو موضح في القسم تشغيل خطوط الأنابيب في Azure Data Factory، عندما يبدأ مشغل تشغيل خط الأنابيب، فإنه يأخذ لقطة سريعة من خط الأنابيب، ومجموعة البيانات، ووقت تشغيل التكامل، وتعريفات الخدمات المرتبطة. إذا تم تشغيل البنية الأساسية لبرنامج ربط العمليات التجارية قبل ملء التغييرات في الخلفية، يبدأ المشغل تشغيل بالإصدار القديم. في معظم الحالات، يجب أن يكون هذا على ما يرام.
- كما هو موضح في قسم Publishing Triggers. عندما يكون المشغل في حالة البدء ، لا يمكن تحديثه. لذلك، إذا كنت بحاجة إلى تغيير تفاصيل حول تعريف المشغل، فقم بإيقاف المشغل قبل نشر التغييرات.
- كما هو موضح في القسم النشر في Azure Data Factory، تنشر التعديلات على مجموعات البيانات أو الخدمات المرتبطة قبل تغييرات خط الأنابيب. للتأكد من أن تشغيل البنية الأساسية لبرنامج ربط العمليات التجارية يستخدم بيانات الاعتماد الصحيحة ويتصل بالخوادم الصحيحة، نوصي بإيقاف المشغل المقترن أيضا.
إعداد تغييرات "التعليمات البرمجية"
نوصي باتباع أفضل الممارسات لطلبات السحب.
- يجب أن يعمل كل مطور على فروعه الفردية، وفي نهاية اليوم، أنشئ طلبات سحب إلى الفرع الرئيسي للمستودع. راجع الدروس حول طلبات السحب في GitHub و DevOps.
- عندما يوافق حافظو البوابة على طلبات السحب ويدمجون التغييرات في الفرع الرئيسي، يمكن بدء عملية CI/CD. هناك طريقتان مقترحتان لتعزيز التغييرات في جميع أنحاء البيئات: تلقائية ويدوية.
- بمجرد أن تكون جاهزا لبدء خطوط أنابيب CI/CD، يمكنك القيام بذلك بشكل عام باستخدام Azure Pipeline Release أو إجراء عمليات نشر لخطوط أنابيب محددة باستخدام هذه الأداة open source من Azure Player.
النشر التلقائي للتغييرات
للمساعدة في النشر الآلي، نوصي باستخدام حزمة npm الخاصة ب Azure Data Factory Utilities. يساعد استخدام حزمة npm في التحقق من صحة جميع الموارد في البنية الأساسية لبرنامج ربط العمليات التجارية وإنشاء قوالب ARM للمستخدم.
للبدء مع حزمة npm Azure Data Factory ، راجع النشر الآلي للتكامل المستمر وتسليم الطلبات.
النشر اليدوي للتغييرات
بعد أن تدمج فرعك مرة أخرى مع فرع التعاون الرئيسي في مستودع Git الخاص بك، يمكنك نشر تغييراتك يدويا على خدمة Azure Data Factory المباشرة. توفر الخدمة تحكم واجهة المستخدم في النشر من المصانع غير التطويرية مع خيار تعطيل النشر (من ADF Studio).
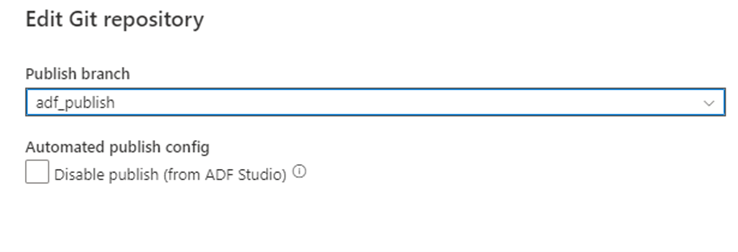
التوزيع الانتقائي
يعتمد النشر الانتقائي على ميزة GitHub و Azure DevOps، تعرف باسم <اختيار >cherizing. تسمح لك هذه الميزة بنشر تغييرات معينة فقط ولكن ليس غيرها. على سبيل المثال، قام مطور واحد بإجراء تغييرات على مسارات متعددة، ولكن بالنسبة للنشر اليوم، قد نرغب في نشر تغييرات على واحد فقط.
اتبع الدروس من Azure DevOps و GitHub لاختيار الالتزامات ذات الصلة بخط الأنابيب الذي تحتاجه. تأكد من اختيار جميع التغييرات، بما في ذلك التغييرات ذات الصلة التي تم إجراؤها على المشغلات والخدمات المرتبطة والتبعيات المرتبطة بالبنية الأساسية لبرنامج ربط العمليات التجارية.
بمجرد اختيار الكرز للتغييرات ودمجها في مسار التعاون الرئيسي، يمكنك بدء عملية CI/CD للتغييرات المقترحة. معلومات إضافية حول كيفية الإصلاح السريع أو اختيار الكرز أو استخدام أطر العمل الخارجية للتوزيع الانتقائي كما هو موضح في قسم الاختبار التلقائي من هذه المقالة.
اختبار الوحدة
يعد اختبار الوحدة جزءا مهما من عملية تطوير مسارات جديدة أو تحرير البيانات الاصطناعية لمصنع البيانات الموجودة، والتي تركز على اختبار مكونات التعليمات البرمجية. يسمح Data Factory باختبار الوحدة الفردية على كل من مستوى البيانات الاصطناعية للمسار وتدفق البيانات باستخدام ميزة تتبع أخطاء البنية الأساسية لبرنامج ربط العمليات التجارية.

عند تطوير تدفقات البيانات، ستتمكن من الحصول على رؤى حول كل تحويل فردي وتغيير في التعليمات البرمجية باستخدام ميزة معاينة البيانات لتحقيق اختبار الوحدة قبل نشر تغييراتك على الإنتاج.

توفر الخدمة تغذية راجعة حية وتفاعلية حول أنشطة خط الأنابيب الخاص بك في واجهة المستخدم عند التصحيح واختبار الوحدات في Azure Data Factory.
الاختبار الآلي
هناك عدة أدوات متاحة للاختبار الآلي يمكنك استخدامها مع Azure Data Factory. نظرا لأن الخدمة تخزن الكائنات داخل الخدمة ككيانات JSON، فقد يكون من الملائم استخدام إطار اختبار وحدات .NET مفتوح المصدر NUnit مع Visual Studio. راجع هذا المنشور إعداد الاختبار الآلي ل Azure Data Factory الذي يقدم شرحا معمقا لكيفية إعداد بيئة اختبار وحدة آلية لمصنعك. (شكرا خاصا لريتشارد سوينبانك للحصول على إذن لاستخدام هذه المدونة.)
يمكن للعملاء أيضا تشغيل مسارات TEST باستخدام PowerShell أو AZ CLI كجزء من عملية CI/CD لخطوات ما قبل النشر وما بعده.
تكمن القوة الرئيسية لمصنع البيانات في تحديد معلمات مجموعات البيانات. تمكن هذه الميزة العملاء من تشغيل نفس المسارات مع مجموعات بيانات مختلفة للتأكد من أن تطويرهم الجديد يلبي جميع متطلبات المصدر والوجهة.
أطر CI/CD أخرى ل Azure Data Factory
كما ذكر سابقا، يتوفر تكامل Git المدمج بشكل أصلي من خلال واجهة Azure Data Factory التي تشمل الدمج، والتفرع، والمقارنة، والنشر. ومع ذلك، هناك أطر CI/CD مفيدة أخرى تحظى بشعبية في مجتمع Azure، توفر آليات بديلة لتوفير قدرات مماثلة. منهجية Git Azure Data Factory تعتمد على قوالب ARM، بينما أطر مثل ADFTools لكاميل نوينسكي تتبع نهجا مختلفا بالاعتماد على تشوهات JSON الفردية من مصنعك. قد يجد مهندسو البيانات الذين لديهم خبرة في Azure DevOps ويفضلون العمل في تلك البيئة (على عكس نهج واجهة المستخدم المعتمد على ARM الذي تقدمه الخدمة مباشرة من الصندوق) أن هذا الإطار يعمل جيدا معهم ومع السيناريوهات الشائعة مثل النشر الجزئي. يمكن أن يبسط إطار العمل هذا أيضا معالجة المشغلات عند النشر في البيئات التي تحتوي على حالات مشغل قيد التشغيل.
Data Governance in Azure Data Factory
أحد الجوانب المهمة ل DataOps الفعالة هو إدارة البيانات. بالنسبة لأدوات ETL لتكامل البيانات، يمكن أن يوفر توفير دورة حياة البيانات وعلاقات البيانات الاصطناعية معلومات مهمة لمهندس البيانات لفهم تأثير تغييرات انتقال البيانات من الخادم. يوفر مصنع البيانات طرق عرض البيانات الاصطناعية ذات الصلة المضمنة التي تشكل تنفيذ المصنع الخاص بك.
يوفر التكامل الأصلي مع Microsoft Purview أيضا نتائج الربط وتحليل التأثيرات وفهرسة البيانات.
يوفر Microsoft Purview حلا موحدا لحوكمة البيانات للمساعدة في إدارة وإدارة بياناتك المحلية والسحابية والبرمجية كخدمة (SaaS). فهو يسمح لك بسهولة بإنشاء خريطة شاملة ومحدثة لمشهد البيانات الخاص بك مع اكتشاف البيانات تلقائيا وتصنيف البيانات الحساسة و دورة حياة البيانات من طرف إلى طرف. تمكن هذه الميزات مستهلكي البيانات من الوصول إلى إدارة البيانات القيمة الجديرة بالثقة.
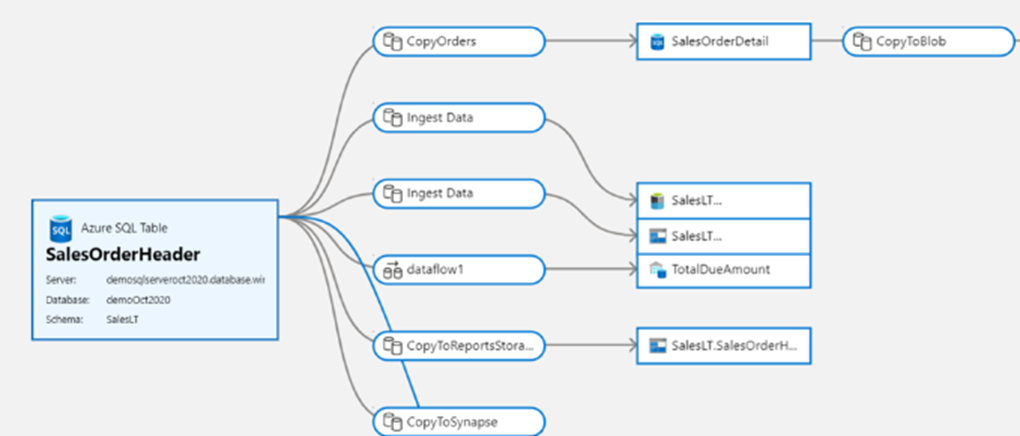
مع التكامل الأصلي في Purview Data Catalog الخاص بك، يتيح Data Factory البحث السهل واكتشاف أصول البيانات لاستخدامها في خطوط تكامل البيانات عبر كامل نطاق بيانات مؤسستك.

يمكنك استخدام شريط البحث الرئيسي من Azure Data Factory Studio للعثور على أصول البيانات في كتالوج Purview الخاص بك.
