إشعار
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
ينطبق على: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
تلميح
Data Factory في Microsoft Fabric هو الجيل القادم من Azure Data Factory، مع بنية أبسط، وذكاء اصطناعي مدمج، وميزات جديدة. إذا كنت جديدا في تكامل البيانات، ابدأ مع Fabric Data Factory. يمكن لأعباء عمل ADF الحالية الترقية إلى Fabric للوصول إلى قدرات جديدة في علوم البيانات، والتحليلات اللحظية، والتقارير.
نشاط Azure Databricks Python في pipeline يشغل ملف Python في عنقود Azure Databricks الخاص بك. تعتمد هذه المقالة على مقالة أنشطة تحويل البيانات، والتي تقدم نظرة عامة على تحويل البيانات وأنشطة التحويل المدعومة. Azure Databricks هو منصة مدارة لتشغيل Apache Spark.
للحصول على مقدمة لمدة إحدى عشرة دقيقة وعرض توضيحي لهذه الميزة، شاهد الفيديو التالي:
Add a Python activity for Azure Databricks إلى خط أنابيب مع واجهة مستخدم
لاستخدام نشاط Python ل Azure Databricks في خط أنابيب، أكمل الخطوات التالية:
ابحث عن Python في لوحة أنشطة خط الأنابيب، واسحب نشاطا Python إلى لوحة خط الأنابيب.
اختر نشاط Python الجديد على اللوحة إذا لم يكن محددا بالفعل.
اختر علامة التبويب Azure Databricks لاختيار أو إنشاء خدمة Azure Databricks مرتبطة جديدة تنفذ نشاط Python.
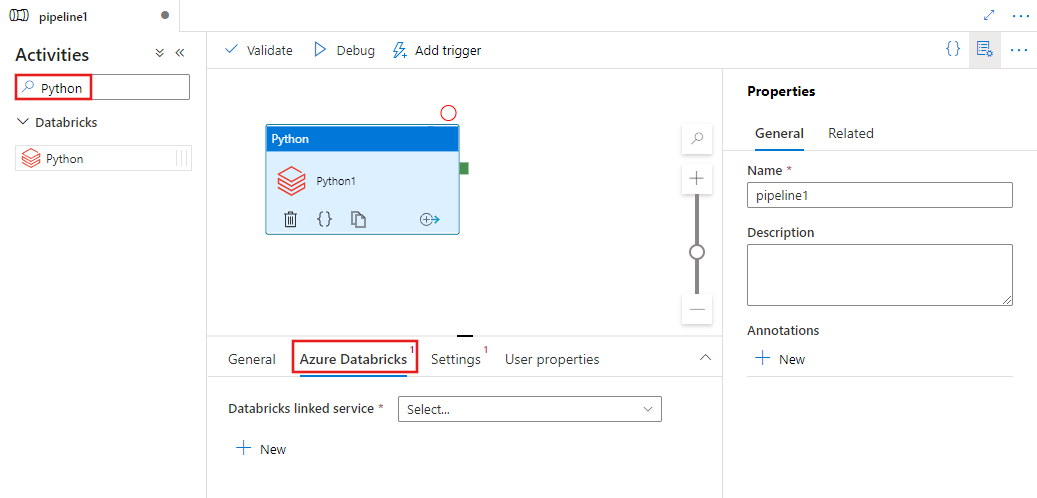
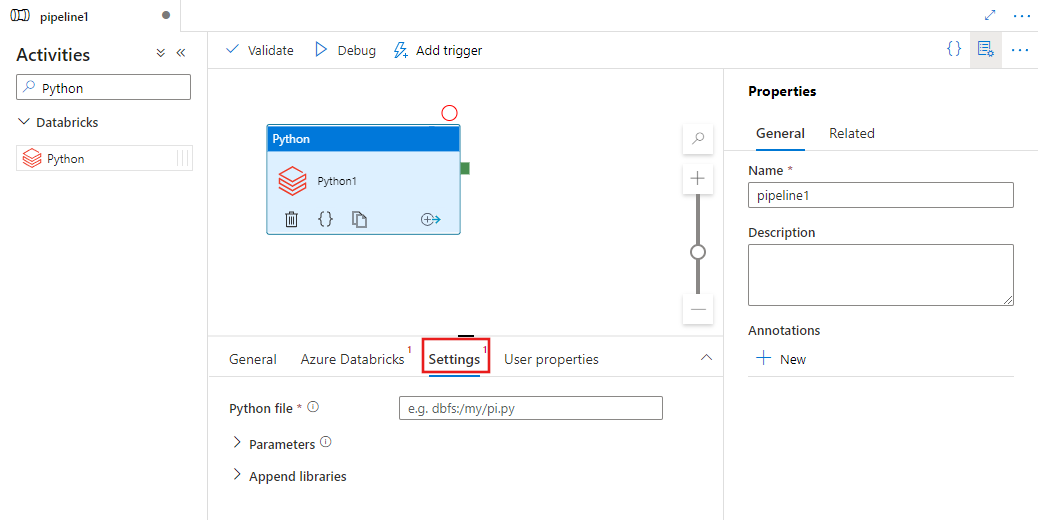
اختر علامة التبويب Settings وحدد المسار ضمن Azure Databricks إلى ملف Python الذي سيتم تنفيذه، والمعلمات الاختيارية التي يجب تمريرها، وأي مكتبات إضافية يجب تثبيتها على العنقود لتنفيذ المهمة.
تعريف نشاط Databricks Python
إليك تعريف نموذجي ل JSON لنشاط Databricks Python:
{
"activity": {
"name": "MyActivity",
"description": "MyActivity description",
"type": "DatabricksSparkPython",
"linkedServiceName": {
"referenceName": "MyDatabricksLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"pythonFile": "dbfs:/docs/pi.py",
"parameters": [
"10"
],
"libraries": [
{
"pypi": {
"package": "tensorflow"
}
}
]
}
}
}
خصائص نشاط Databricks Python
يصف الجدول التالي خصائص JSON المستخدمة في تعريف JSON:
| الخاصية | الوصف | مطلوب |
|---|---|---|
| الاسم | اسم النشاط في التدفق. | نعم |
| الوصف | نص يصف ما يفعله النشاط. | لا |
| النوع | بالنسبة لنشاط Databricks Python، نوع النشاط هو DatabricksSparkPython. | نعم |
| linkedServiceName | اسم خدمة Databricks Linked التي تعمل عليها نشاط Python. للتعرف على هذه الخدمة المرتبطة، راجع مقالة خدمات الحوسبة المرتبطة. | نعم |
| pythonFile | رابط المستخدمين لملف Python الذي سيتم تنفيذه. يتم دعم مسارات DBFS فقط. | نعم |
| المعلمات | معلمات سطر الأوامر التي سيتم تمريرها إلى ملف Python. هذه مصفوفة من السلاسل. | لا |
| المصادقة | قائمة بالمكتبات التي سيتم تثبيتها على نظام المجموعة الذي سيقوم بتنفيذ المهمة. يمكن أن تكون مصفوفة <سلسلة، عنصر> | لا |
المكتبات المدعومة لأنشطة Databricks
في تعريف نشاط Databricks أعلاه، يمكنك تحديد أنواع هذه المكتبات: jar، وegg، وmaven، وpypi، وcran.
{
"libraries": [
{
"jar": "dbfs:/mnt/libraries/library.jar"
},
{
"egg": "dbfs:/mnt/libraries/library.egg"
},
{
"maven": {
"coordinates": "org.jsoup:jsoup:1.7.2",
"exclusions": [ "slf4j:slf4j" ]
}
},
{
"pypi": {
"package": "simplejson",
"repo": "http://my-pypi-mirror.com"
}
},
{
"cran": {
"package": "ada",
"repo": "https://cran.us.r-project.org"
}
}
]
}
لمزيد من التفاصيل، راجع وثائق Databricks لأنواع المكتبات.
كيفية تحميل مكتبة في Databricks
يمكنك استخدام واجهة مستخدم مساحة العمل:
يمكنك استخدام Databricks CLI لحصول على مسار dbfs من المكتبة المضافة باستخدام واجهة المستخدم.
عادةً ما يتم تخزين مكتبات Jar في الدليل dbfs:/FileStore/jars أثناء استخدام واجهة المستخدم. يمكنك سردها بالكامل من خلال CLI: databricks fs ls dbfs:/FileStore/job-jars
أو يمكنك استخدام Databricks CLI:
استخدام Databricks CLI (خطوات التثبيت)
على سبيل المثال، لنسخ JAR إلى dbfs:
dbfs cp SparkPi-assembly-0.1.jar dbfs:/docs/sparkpi.jar