تحويل البيانات في السحابة باستخدام نشاط Spark في Azure Data Factory
ينطبق على:  Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
تلميح
جرب Data Factory في Microsoft Fabric، وهو حل تحليلي متكامل للمؤسسات. يغطي Microsoft Fabric كل شيء بدءا من حركة البيانات إلى علم البيانات والتحليلات في الوقت الحقيقي والمعلومات المهنية وإعداد التقارير. تعرف على كيفية بدء إصدار تجريبي جديد مجانا!
في هذا البرنامج التعليمي، يمكنك استخدام مدخل Azure لإنشاء مسار Azure Data Factory. يحول هذا المسار البيانات باستخدام نشاط Spark وخدمة Azure HDInsight المرتبطة حسب الطلب.
نفذ الخطوات التالية في هذا البرنامج التعليمي:
- إنشاء data factory.
- إنشاء مسار يستخدم نشاط Spark.
- تتبع تشغيل البنية الأساسية
- مراقبة تشغيل المسار.
في حال لم يكن لديك اشتراك Azure، فأنشئ حساباً مجانيّاً قبل البدء.
المتطلبات الأساسية
إشعار
نوصي باستخدام الوحدة النمطية Azure Az PowerShell للتفاعل مع Azure. للبدء، راجع تثبيت Azure PowerShell. لمعرفة كيفية الترحيل إلى الوحدة النمطية Az PowerShell، راجع ترحيل Azure PowerShell من AzureRM إلى Az.
- حساب Azure Storage. يمكنك إنشاء برنامج نصي في Python وملف إدخال، وتحميلهما إلى Azure Storage. يتم تخزين الإخراج الناتج من برنامج Spark في حساب التخزين هذا. تستخدم مجموعة Spark حسب الطلب حساب التخزين نفسه كمساحة تخزين أساسية لها.
إشعار
لا يدعم HdInsight إلا حسابات التخزين ذات الأغراض العامة ذات المستوى القياسي. تأكد من أن الحساب ليس حساب تخزين مميز أو حساب تخزين كائنات بيانات ثنائية كبيرة الحجم فقط.
- Azure PowerShell. اتبع الإرشادات الموجودة في كيفية تثبيت وتكوين Azure PowerShell.
تحميل برنامج Python النصي إلى حساب التخزين كائنات بيانات ثنائية كبيرة الحجم
أنشئ ملف Python باسم WordCount_Spark.py يحتوي على المحتوى التالي:
import sys from operator import add from pyspark.sql import SparkSession def main(): spark = SparkSession\ .builder\ .appName("PythonWordCount")\ .getOrCreate() lines = spark.read.text("wasbs://adftutorial@<storageaccountname>.blob.core.windows.net/spark/inputfiles/minecraftstory.txt").rdd.map(lambda r: r[0]) counts = lines.flatMap(lambda x: x.split(' ')) \ .map(lambda x: (x, 1)) \ .reduceByKey(add) counts.saveAsTextFile("wasbs://adftutorial@<storageaccountname>.blob.core.windows.net/spark/outputfiles/wordcount") spark.stop() if __name__ == "__main__": main()استبدل <storageAccountName> باسم حسابك في Azure storage. ثم حفظ الملف.
في مساحة تخزين Azure Blob، أنشئ حاوية باسم adftutorial إذا لم تكن موجودة بالفعل.
أنشئ مجلدًا باسم spark.
أنشئ مجلدًا فرعيًّا باسم script ضمن مجلد spark.
حمّل الملف WordCount_Spark.py إلى المجلد الفرعي script.
قم بتحميل ملف الإدخال
- أنشئ ملفاً باسم minecraftstory.txt يتضمن نصاً. يتولى برنامج Spark حساب عدد الكلمات في هذا النص.
- أنشئ مجلدًا فرعيًّا باسم inputfiles في مجلد spark.
- حمل ملف minecraftstory.txt إلى المجلد الفرعي inputfiles.
إنشاء مصدرًا للبيانات
اتبع الخطوات الواردة في المقالة التشغيل السريع: إنشاء مصنع بيانات باستخدام مدخل Microsoft Azure لإنشاء مصنع بيانات إذا لم يكن لديك مصنع بالفعل للعمل معه.
إنشاء linked services
يمكنك تأليف خدمتين مرتبطتين في هذا القسم:
- تربط Azure Storage linked service حساب تخزين Azure بمصنع البيانات. يتم استخدام هذا التخزين بواسطة مجموعة HDInsight عند الطلب. كما تحتوي على برنامج Spark النصي المطلوب تشغيله.
- خدمة HDInsight المرتبطة عند الطلب. يقوم Azure Data Factory بإنشاء مجموعة HDInsight تلقائيًّا، كما يقوم بتشغيل برنامج Spark. ثم يقوم بحذف مجموعة HDInsight بعد أن تكون الكتلة خامدة لفترة محددة مسبقًا.
أنشئ خدمة مرتبطة بالتخزين في Azure
في الصفحة الرئيسية، الانتقال إلى علامة تبويب Manage في اللوحة اليسرى.
حدد Connections في أسفل النافذة، ثم حدد + New.
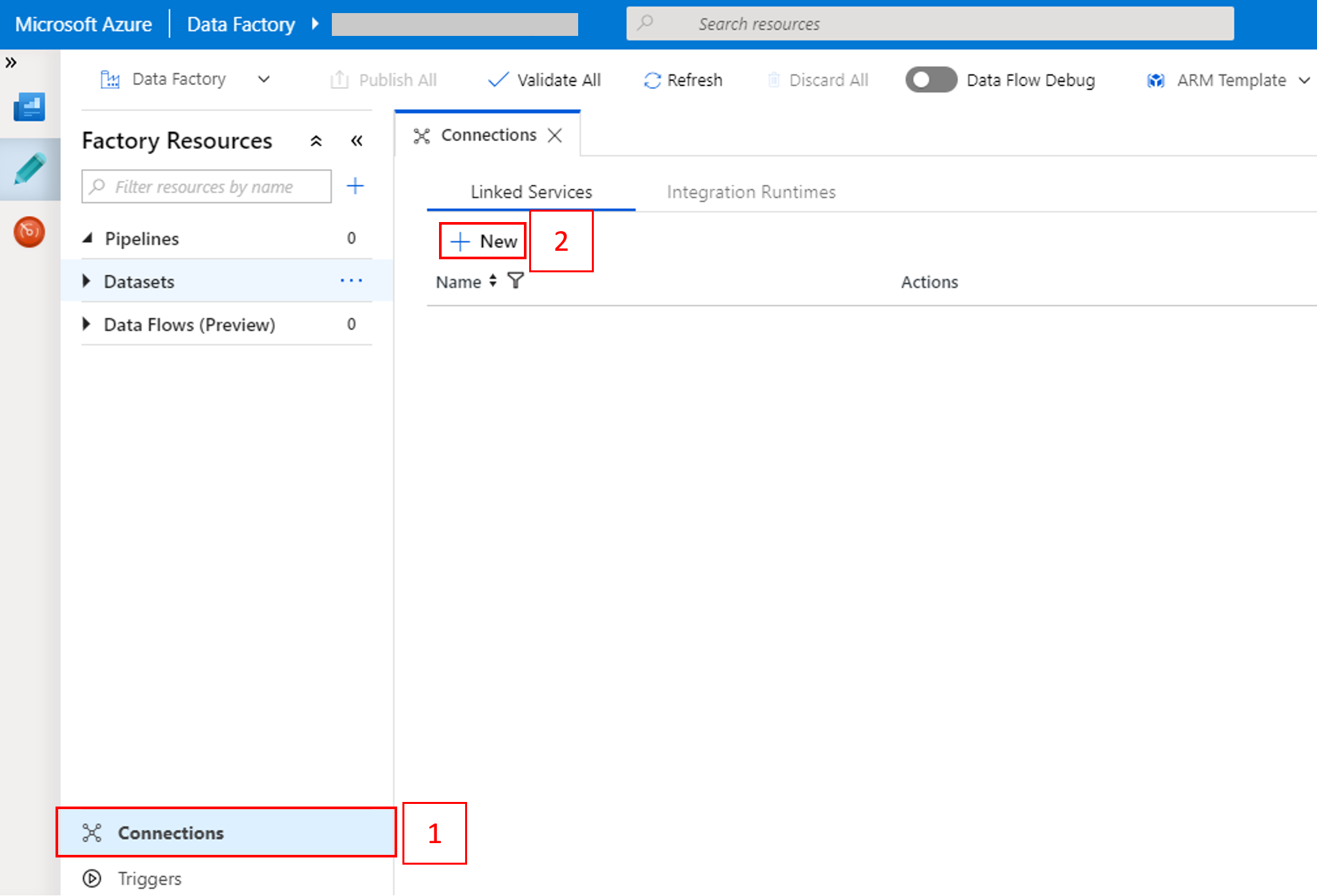
في نافذة "New Linked Service"، حدد "Data Store">"Azure Blob Storage"، ثم حدد Continue.

بالنسبة Storage account name، حدد الاسم من القائمة، ثم حدد Save.
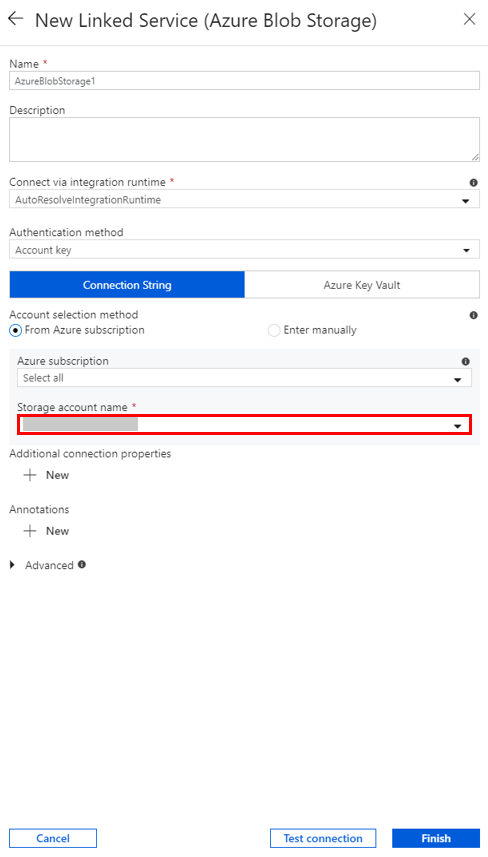
إنشاء خدمة HDInsight مرتبطة عند الطلب
حدد الزر + New مرة أخرى لإنشاء خدمة مرتبطة أخرى.
في نافذة New Linked Service، حدد Compute>Azure HDInsight، ثم حدد Continue.

في نافذة New Linked Service، أكمل الخطوات التالية:
أ. أدخل AzureHDInsightLinkedServiceفي خانة Name.
ب. بالنسبة إلى Type، قم بالتأكد من تحديد On-demand HDInsight.
جـ. بالنسبة لـ Azure Storage Linked Service، حدد AzureBlobStorage1. قمت بإنشاء هذه الخدمة المرتبطة في وقت سابق. إذا كنت تستخدم اسمًا مختلفًا، حدد الاسم الصحيح هنا.
د. بالنسبة لـCluster type، حدد spark.
هـ. بالنسبة لـ Service principal id، أدخل معرف كيان الخدمة الذي لديه إذن لإنشاء مجموعة HDInsight.
يجب أن يكون كيان الخدمة هذا عضوًا بدور مساهم في الاشتراك أو مجموعة الموارد التي تُنشأ فيها المجموعة. لمزيد من المعلومات، راجع إنشاء تطبيق Microsoft Entra ومدير الخدمة. يعد Service principal id مكافئًا لـ Application ID، ويعد Service principal key مكافئًا لقيمة Client secret.
و. بالنسبة Service principal key, ادخل المفتاح.
ز. بالنسبة إلى Resource group، حدد نفس مجموعة الموارد التي استخدمتها عند إنشاء مصنع البيانات. يتم إنشاء مجموعة Spark في مجموعة الموارد هذه.
ح. وسع OS type.
1. أدخل اسمًا Cluster user name.
ي. أدخِل Cluster password للمستخدم.
k. حدد إنهاء.
إشعار
يضع Azure HDInsight قيودًا على العدد الإجمالي للنوى التي يمكنك استخدامها في كل منطقة Azure تدعمها. بالنسبة لخدمة HDInsight المرتبطة عند الطلب، تُنشأ مجموعة HDInsight في نفس الموقع Azure Storage المستخدم كمساحة تخزين أساسية. تأكد من أن لديك عددًا من حصص النوى كافيًا لإنشاء المجموعة بنجاح. لمزيد من المعلومات، راجع إعداد المجموعات في HDInsight باستخدام Hadoop وSpark وKafka وغير ذلك.
إنشاء البنية الأساسية لبرنامج ربط العمليات التجارية
حدد زر (علامة الزائد) + ثم حدد Pipeline المُتاح في القائمة.
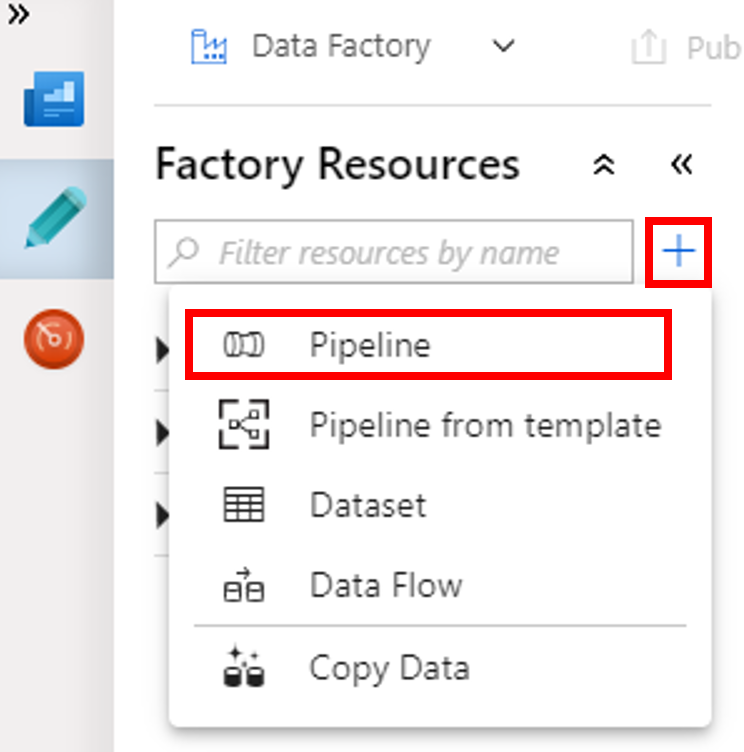
في مربع أدوات Activities، قم بتوسيع HDInsight. اسحَب نشاط Spark من مربع أدوات Activities إلى سطح مصمم المسارات.
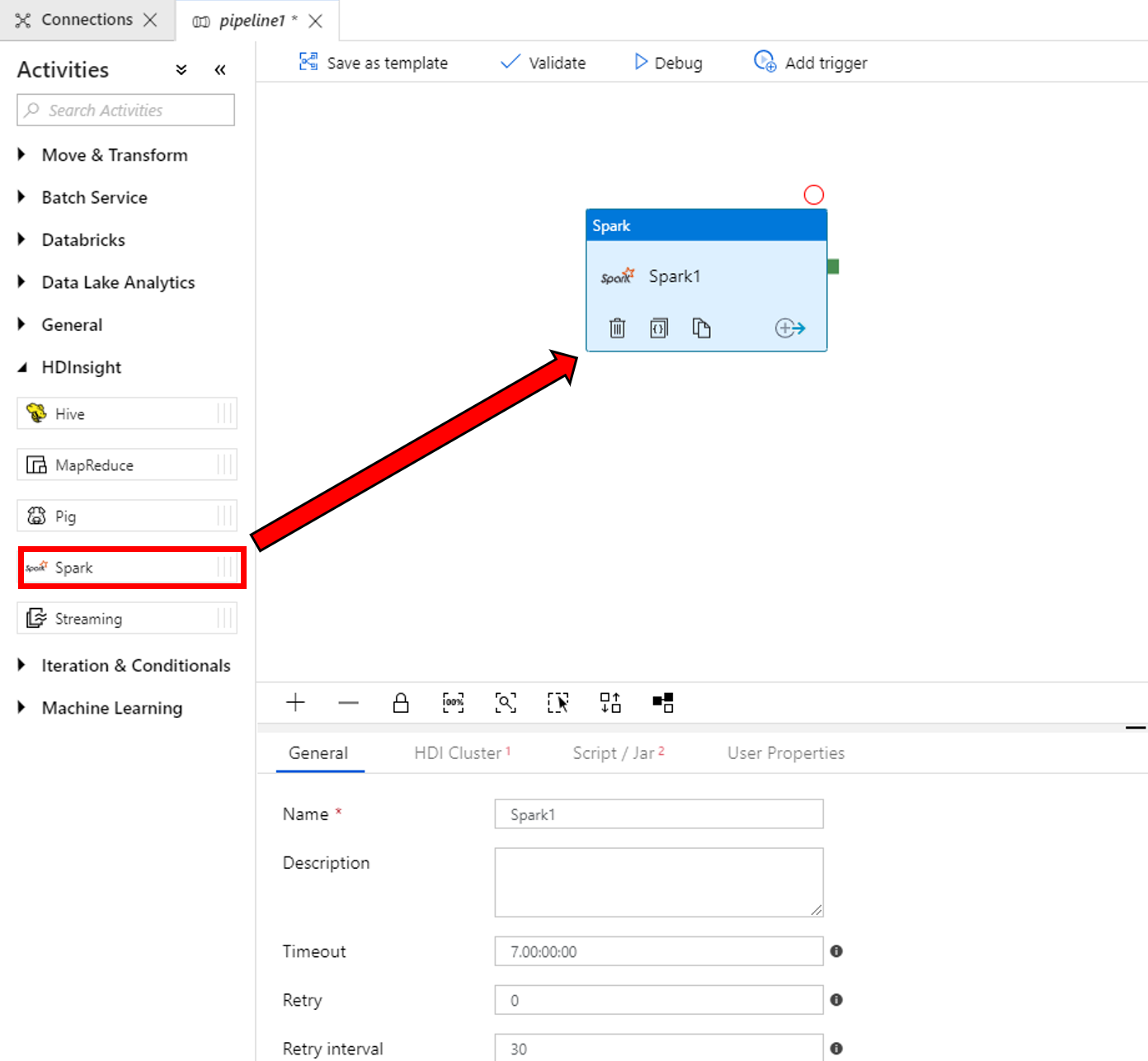
في خصائص نافذة نشاط Spark في الأسفل، أكمل الخطوات التالية:
أ. قم بالتبديل إلى علامة التبويب HDI Cluster.
ب. حدد AzureHDInsightLinkedService (التي جرى إنشاؤها في الإجراء السابق).
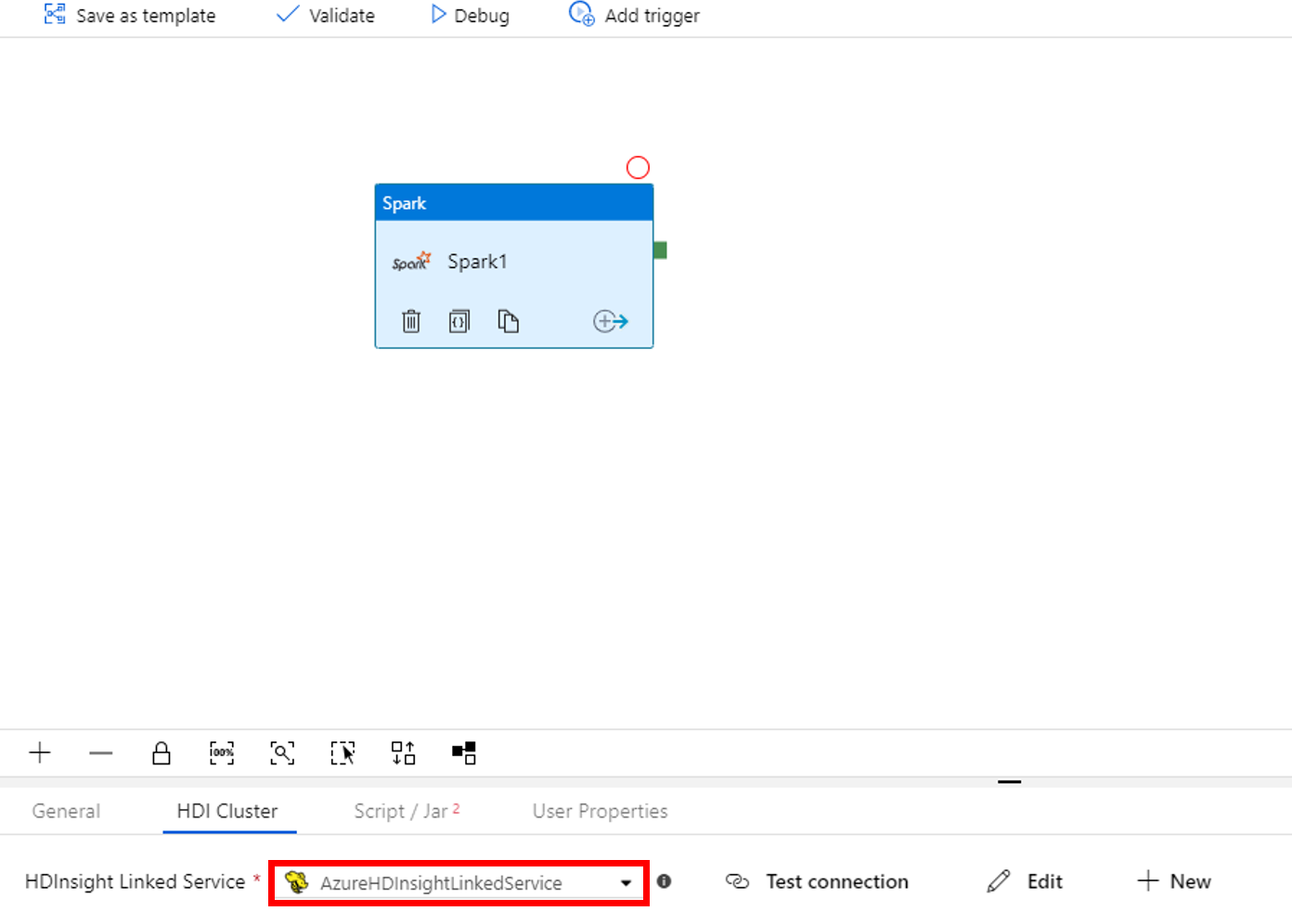
انتقل إلى علامة التبويب Script/Jar ثم أكمل الخطوات التالية:
أ. بالنسبة لـ Job Linked Service، حدد AzureBlobStorage1.
ب. حدد Browse Storage.

جـ. استعرض مجلد adftutorial/spark/script وحدد WordCount_Spark.py،ثم حدد Finish.
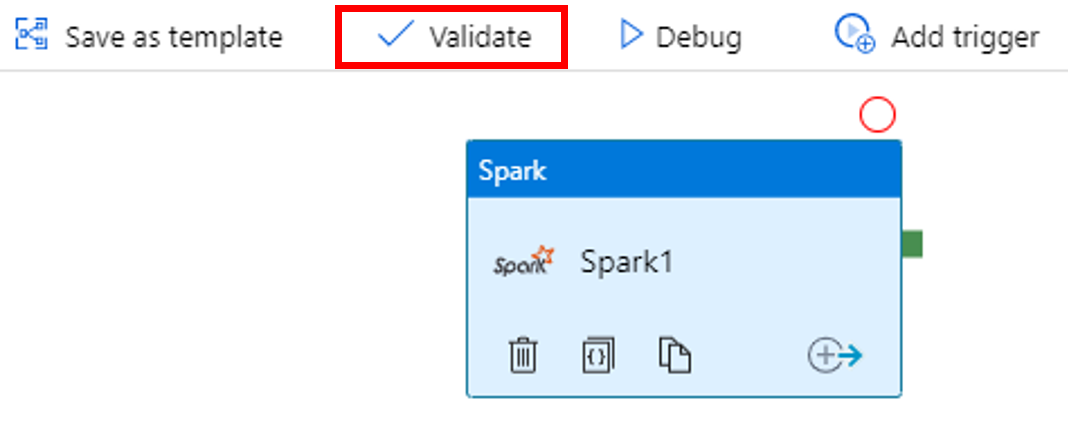
للتحقق من صحة المسار، حدد زرالتحقق المُتاح على شريط الأدوات. حدد زر (السهم الأيمن)>> لإغلاق نافذة التحقق من الصحة.
حدد "Publish All". تقوم The Data Factory UI بنشر الكيانات المتمثلة في (الخدمات المرتبطة والمسار) إلى خدمة Azure Data Factory.
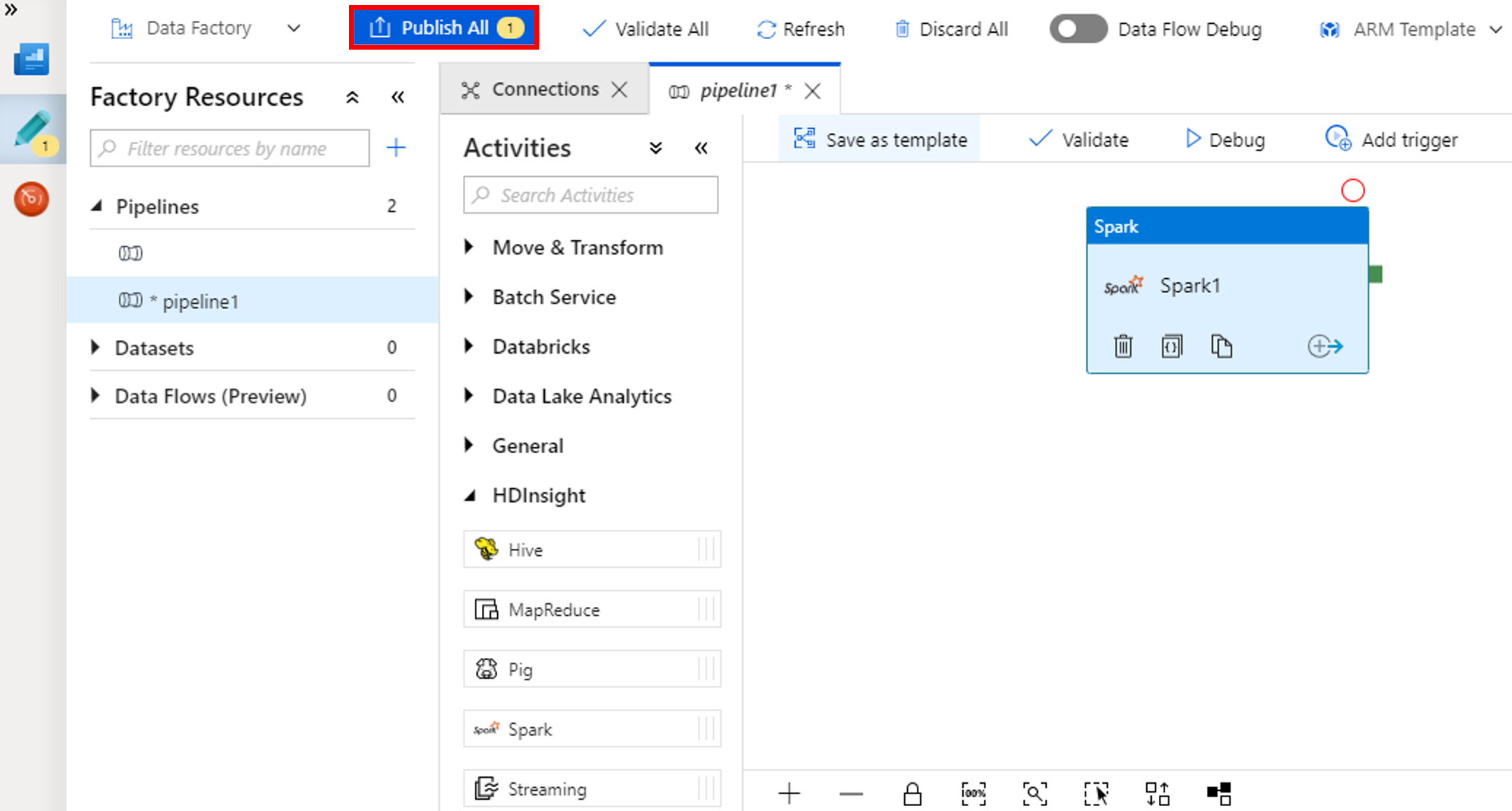
تتبع تشغيل البنية الأساسية
حدد Add Trigger على شريط الأدوات، ثم حدد Trigger Now.
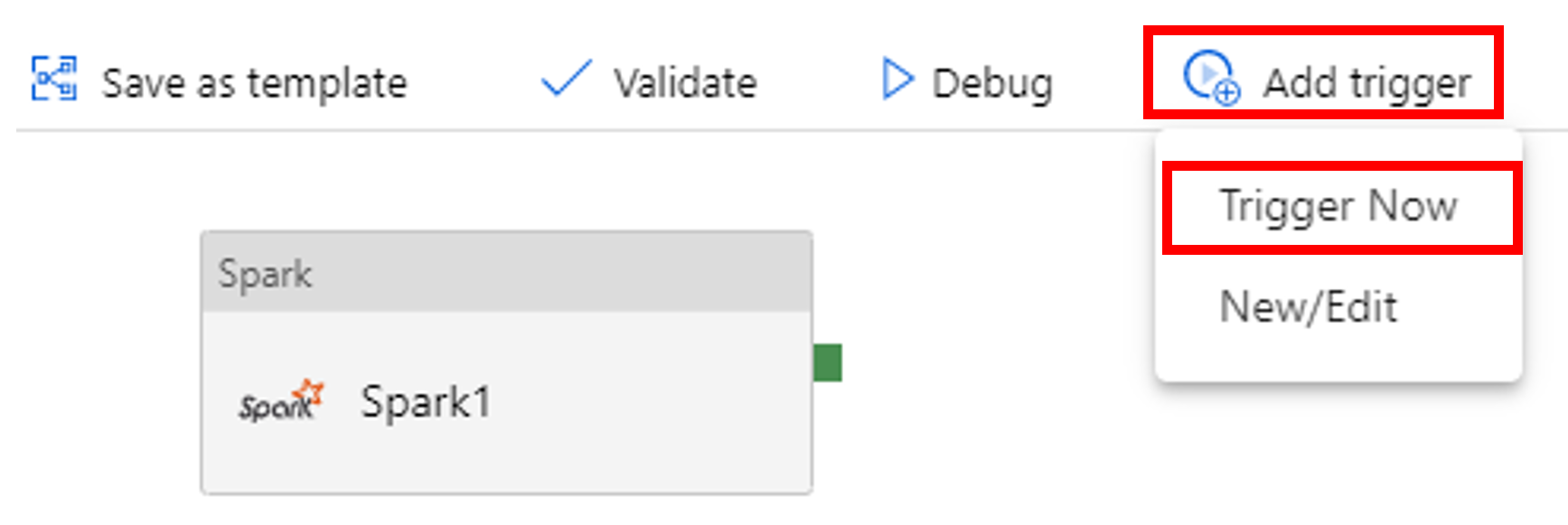
راقب عملية تشغيل البنية الأساسية لبرنامج ربط العمليات التجارية
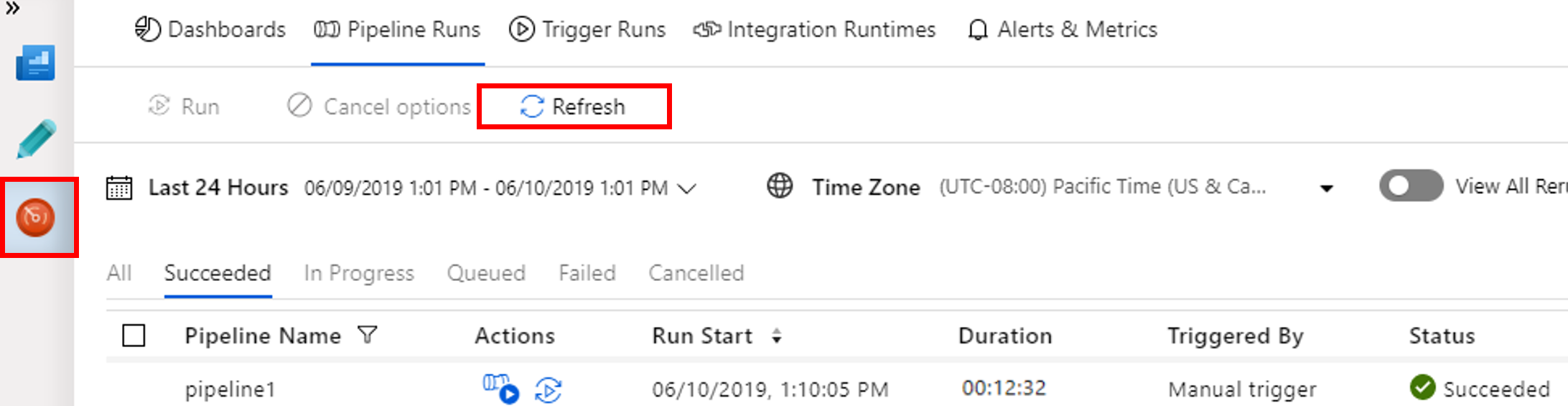
انتقل إلى علامة تبويب Monitor. وتأكد من الاطلاع على تشغيل المسار. يستغرق إنشاء كتلة Spark حوالي 20 دقيقة.
حدد تحديث بشكل دوري للتحقق من حالة تشغيل البنية الأساسية لبرنامج ربط العمليات التجارية.
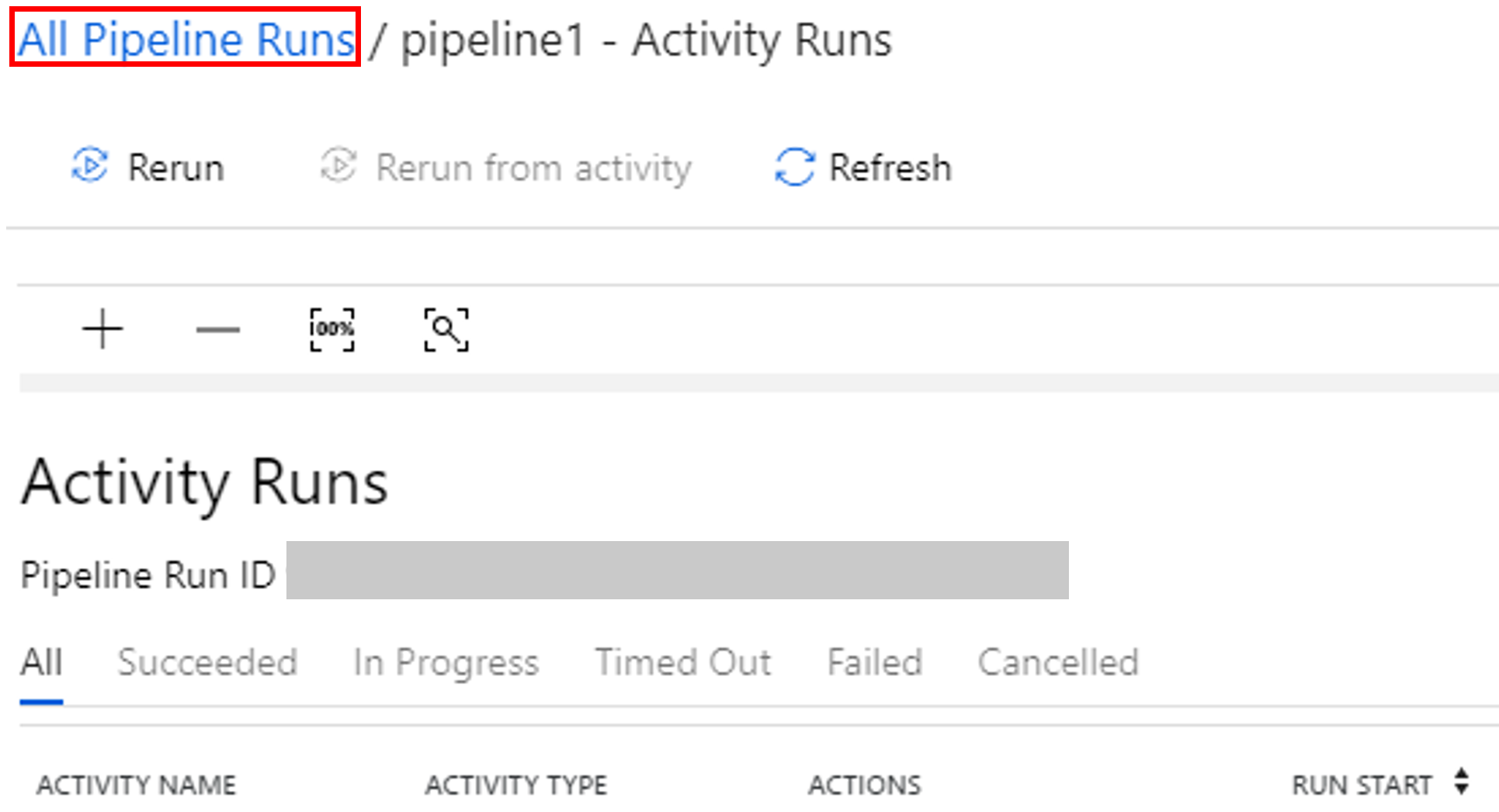
لمشاهدة عمليات تشغيل النشاط المقترنة بتشغيل البنية الأساسية لبرنامج ربط العمليات التجارية، حدد عرض تشغيل النشاط في عمود الإجراءات .
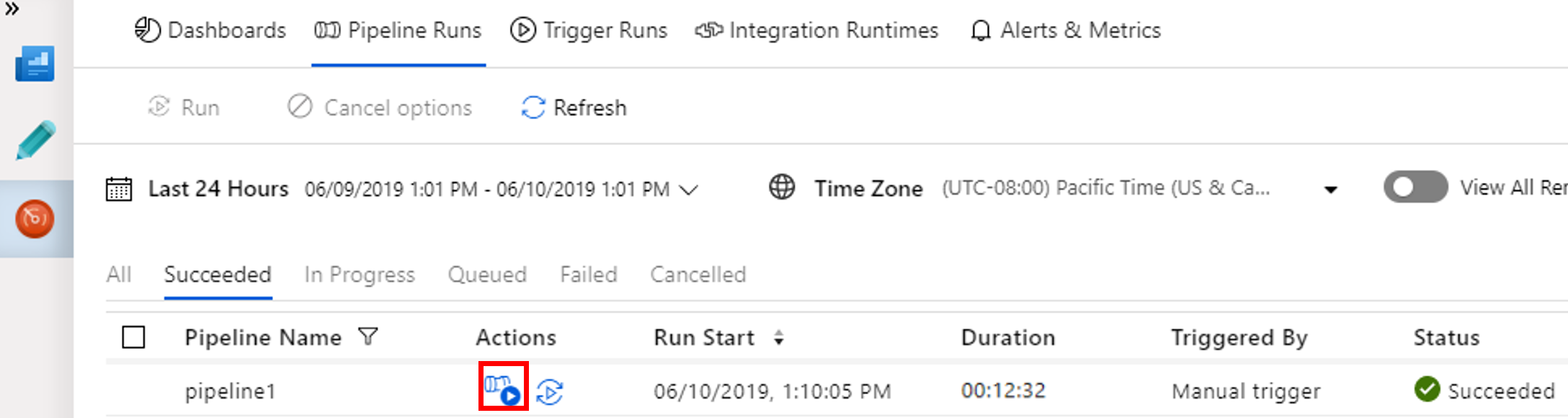
يُمكنك الانتقال مرة أخرى إلى طريقة عرض تشغيل المسار عن طريق تحديد ارتباط All Pipeline Runs في الأعلى.
تحقق من الإخراج
تحقق من إنشاء ملف الناتج في مجلد spark/otuputfiles/wordcount لحاوية adftutorial.
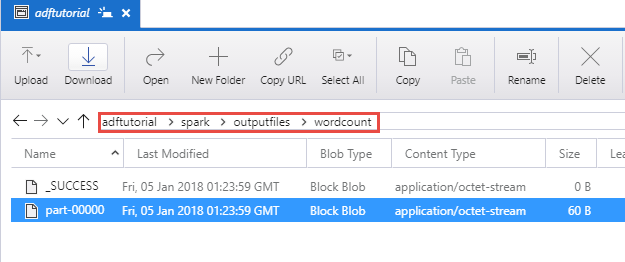
يجب أن يحتوي الملف على كل كلمة من ملف نص الإدخال ورقم يشير إلى عدد المرات التي ظهرت فيها الكلمة في الملف. على سبيل المثال:
(u'This', 1)
(u'a', 1)
(u'is', 1)
(u'test', 1)
(u'file', 1)
المحتوى ذو الصلة
يحول المسار في هذه العينة البيانات باستخدام نشاط Spark وخدمة Azure HDInsight المرتبطة حسب الطلب. لقد تعرفت على كيفية:
- إنشاء data factory.
- إنشاء مسار يستخدم نشاط Spark.
- تتبع تشغيل البنية الأساسية
- مراقبة تشغيل المسار.
تقدَّم إلى البرنامج التعليمي التالي للتعرّف على كيفية تحويل البيانات عن طريق تشغيل برنامج Hive نصي على مجوعة Azure HDInsight موجودة في شبكة ظاهرية: