ملاحظة
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
هام
تم إيقاف هذه الوثائق وقد لا يتم تحديثها.
يتم إهمال تمرير بيانات الاعتماد بدءا من Databricks Runtime 15.0 وستتم إزالتها في إصدارات وقت تشغيل Databricks المستقبلية. توصي Databricks بالترقية إلى كتالوج Unity. يبسط كتالوج Unity أمان بياناتك وإدارتها من خلال توفير مكان مركزي لإدارة الوصول إلى البيانات وتدقيطها عبر مساحات عمل متعددة في حسابك. راجع ما هو كتالوج Unity؟.
للحصول على وضع الأمان والحوكمة المتزايد، اتصل بفريق حساب Azure Databricks لتعطيل تمرير بيانات الاعتماد في حساب Azure Databricks الخاص بك.
إشعار
تحتوي هذه المقالة على مراجع للمصطلح المدرج في القائمة البيضاء، وهو مصطلح لا يستخدمه Azure Databricks. عند إزالة المصطلح من البرنامج، سنزيله من هذه المقالة.
يمكنك المصادقة تلقائيا على الوصول إلى Azure Data Lake Storage Gen1 من Azure Databricks (ADLS Gen1) وADS Gen2 من مجموعات Azure Databricks باستخدام نفس هوية معرف Microsoft Entra التي تستخدمها لتسجيل الدخول إلى Azure Databricks. عند تمكين تمرير بيانات اعتماد Azure Data Lake Storage للمجموعة الخاصة بك، يمكن للأوامر التي تقوم بتشغيلها على هذه المجموعة قراءة البيانات وكتابتها في Azure Data Lake Storage دون مطالبتك بتكوين بيانات اعتماد كيان الخدمة للوصول إلى التخزين.
يتم دعم تمرير بيانات اعتماد Azure Data Lake Storage مع Azure Data Lake Storage Gen1 وGen2 فقط. لا يدعم تخزين Azure Blob تمرير بيانات الاعتماد.
يغطي هذا المقال:
- تمكين تمرير بيانات الاعتماد للمجموعات القياسية وعالية التزامن.
- تكوين تمرير بيانات الاعتماد وتهيئة موارد التخزين في حسابات ADLS.
- الوصول إلى موارد ADLS مباشرة عند تمكين تمرير بيانات الاعتماد.
- الوصول إلى موارد ADLS من خلال نقطة تحميل عند تمكين تمرير بيانات الاعتماد.
- الميزات والقيود المدعومة عند استخدام تمرير بيانات الاعتماد.
يتم تضمين دفاتر الملاحظات لتوفير أمثلة لاستخدام تمرير بيانات الاعتماد مع حسابات تخزين ADLS Gen1 وADS Gen2.
المتطلبات
- الخطة المميزة . راجع ترقية مساحة عمل Azure Databricks أو الرجوع إليها للحصول على تفاصيل حول ترقية خطة قياسية إلى خطة متميزة.
- حساب تخزين Azure Data Lake Storage Gen1 أو Gen2. يجب أن تستخدم حسابات تخزين Azure Data Lake Storage Gen2 مساحة الاسم الهرمية للعمل مع مرور بيانات اعتماد Azure Data Lake Storage. راجع إنشاء حساب تخزين للحصول على إرشادات حول إنشاء حساب ADLS Gen2 جديد، بما في ذلك كيفية تمكين مساحة الاسم الهرمية.
- أذونات المستخدم المكونة بشكل صحيح إلى Azure Data Lake Storage. يحتاج مسؤول Azure Databricks إلى التأكد من أن المستخدمين لديهم الأدوار الصحيحة، على سبيل المثال، Storage Blob Data Contributor، لقراءة وكتابة البيانات المخزنة في Azure Data Lake Storage. راجع استخدام مدخل Microsoft Azure لتعيين دور Azure للوصول إلى بيانات النقطة وقائمة الانتظار.
- فهم امتيازات مسؤولي مساحة العمل في مساحات العمل التي تم تمكينها للتمرير، ومراجعة تعيينات مسؤول مساحة العمل الحالية. يمكن لمسؤولي مساحة العمل إدارة العمليات لمساحة العمل الخاصة بهم بما في ذلك إضافة المستخدمين وكيانات الخدمة وإنشاء مجموعات وتفويض مستخدمين آخرين ليكونوا مسؤولين في مساحة العمل. قد تمنح مهام إدارة مساحة العمل، مثل إدارة ملكية المهمة وعرض دفاتر الملاحظات، وصولا غير مباشر إلى البيانات المسجلة في Azure Data Lake Storage. مسؤول مساحة العمل هو دور متميز يجب توزيعه بعناية.
- لا يمكنك استخدام نظام مجموعة تم تكوينه باستخدام بيانات اعتماد ADLS، على سبيل المثال، بيانات اعتماد كيان الخدمة، مع مرور بيانات الاعتماد.
هام
لا يمكنك المصادقة على Azure Data Lake Storage باستخدام بيانات اعتماد معرف Microsoft Entra إذا كنت خلف جدار حماية لم يتم تكوينه للسماح بنسبة استخدام الشبكة إلى معرف Microsoft Entra. جدار حماية Azure Firewall يمنع الوصول إلى Active Directory بشكل افتراضي. للسماح بالوصول، قم بتكوين علامة خدمة AzureActiveDirectory. يمكنك العثور على معلومات مكافئة للأجهزة الظاهرية للشبكة ضمن علامة AzureActiveDirectory في نطاقات IP Azure وعلامات الخدمة ملف JSON. لمزيد من المعلومات، راجع علامات خدمة Azure Firewall.
توصيات التسجيل
يمكنك تسجيل الهويات التي تم تمريرها إلى تخزين ADLS في سجلات تشخيص تخزين Azure. تسمح هويات التسجيل بربط طلبات ADLS بمستخدمين فرديين من مجموعات Azure Databricks. قم بتشغيل التسجيل التشخيصي على حساب التخزين لبدء تلقي هذه السجلات:
- Azure Data Lake Storage Gen1: اتبع الإرشادات الواردة في تمكين التسجيل التشخيصي لحساب Data Lake Storage Gen1.
- Azure Data Lake Storage Gen2: تكوين باستخدام PowerShell باستخدام
Set-AzStorageServiceLoggingPropertyالأمر . حدد 2.0 كإصدار، لأن تنسيق إدخال السجل 2.0 يتضمن اسم المستخدم الأساسي في الطلب.
تمكين تمرير بيانات اعتماد Azure Data Lake Storage لنظام مجموعة عالية التزامن
يمكن مشاركة مجموعات التزامن العالية من قبل عدة مستخدمين. وهي تدعم فقط Python وSQL مع بيانات اعتماد Azure Data Lake Storage passthrough.
هام
يؤدي تمكين بيانات اعتماد Azure Data Lake Storage إلى حظر جميع المنافذ على نظام المجموعة باستثناء المنافذ 44 و53 و80.
- عند إنشاء نظام مجموعة، قم بتعيين وضع نظام المجموعة إلى التزامن العالي.
- ضمن خيارات متقدمة، حدد تمكين تمرير بيانات الاعتماد للوصول إلى البيانات على مستوى المستخدم والسماح فقط لأوامر Python وSQL.

تمكين تمرير بيانات اعتماد Azure Data Lake Storage لمجموعة قياسية
تقتصر المجموعات القياسية مع تمرير بيانات الاعتماد على مستخدم واحد. تدعم المجموعات القياسية Python وSQL وSc scala وR. في Databricks Runtime 10.4 LTS وما فوق، يتم دعم sparklyr.
يجب تعيين مستخدم عند إنشاء نظام المجموعة، ولكن يمكن تحرير نظام المجموعة من قبل مستخدم بأذونات CAN MANAGE في أي وقت لاستبدال المستخدم الأصلي.
هام
يجب أن يكون لدى المستخدم المعين إلى نظام المجموعة إذن CAN ATTACH TO على الأقل للمجموعة من أجل تشغيل الأوامر على نظام المجموعة. يمتلك مسؤولو مساحة العمل ومنشئ نظام المجموعة أذونات CAN MANAGE، ولكن لا يمكنهم تشغيل الأوامر على نظام المجموعة ما لم يكونوا مستخدم نظام المجموعة المعين.
- عند إنشاء نظام مجموعة، قم بتعيين وضع نظام المجموعة إلى قياسي.
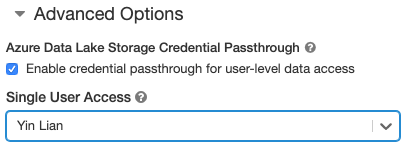
- ضمن خيارات متقدمة، حدد Enable credential passthrough للوصول إلى البيانات على مستوى المستخدم وحدد اسم المستخدم من القائمة المنسدلة Single User Access .
إنشاء حاوية
توفر الحاويات طريقة لتنظيم العناصر في حساب تخزين Azure.
الوصول إلى Azure Data Lake Storage مباشرة باستخدام تمرير بيانات الاعتماد
بعد تكوين تمرير بيانات اعتماد Azure Data Lake Storage وإنشاء حاويات التخزين، يمكنك الوصول إلى البيانات مباشرة في Azure Data Lake Storage Gen1 باستخدام adl:// مسار وAzure Data Lake Storage Gen2 باستخدام abfss:// مسار.
Azure Data Lake Storage Gen1
Python
spark.read.format("csv").load("adl://<storage-account-name>.azuredatalakestore.net/MyData.csv").collect()
R
# SparkR
library(SparkR)
sparkR.session()
collect(read.df("adl://<storage-account-name>.azuredatalakestore.net/MyData.csv", source = "csv"))
# sparklyr
library(sparklyr)
sc <- spark_connect(method = "databricks")
sc %>% spark_read_csv("adl://<storage-account-name>.azuredatalakestore.net/MyData.csv") %>% sdf_collect()
- استبدل
<storage-account-name>باسم حساب تخزين ADLS Gen1.
Azure Data Lake Storage Gen2
Python
spark.read.format("csv").load("abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/MyData.csv").collect()
R
# SparkR
library(SparkR)
sparkR.session()
collect(read.df("abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/MyData.csv", source = "csv"))
# sparklyr
library(sparklyr)
sc <- spark_connect(method = "databricks")
sc %>% spark_read_csv("abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/MyData.csv") %>% sdf_collect()
- استبدل
<container-name>باسم حاوية في حساب تخزين ADLS Gen2. - استبدل
<storage-account-name>باسم حساب تخزين ADLS Gen2.
تحميل Azure Data Lake Storage إلى DBFS باستخدام تمرير بيانات الاعتماد
يمكنك تحميل حساب Azure Data Lake Storage أو مجلد بداخله إلى ما هو DBFS؟. التحميل هو مؤشر إلى مخزن مستودع بيانات، لذلك لا تتم مزامنة البيانات محليا أبدا.
عند تحميل البيانات باستخدام نظام مجموعة ممكن مع مرور بيانات اعتماد Azure Data Lake Storage، تستخدم أي قراءة أو كتابة إلى نقطة التحميل بيانات اعتماد معرف Microsoft Entra. ستكون نقطة التحميل هذه مرئية للمستخدمين الآخرين، ولكن المستخدمين الوحيدين الذين سيكون لديهم حق الوصول للقراءة والكتابة هم الذين:
- الحصول على حق الوصول إلى حساب تخزين Azure Data Lake Storage الأساسي
- تستخدم مجموعة ممكنة لتمرير بيانات اعتماد Azure Data Lake Storage
Azure Data Lake Storage Gen1
لتحميل مورد Azure Data Lake Storage Gen1 أو مجلد بداخله، استخدم الأوامر التالية:
Python
configs = {
"fs.adl.oauth2.access.token.provider.type": "CustomAccessTokenProvider",
"fs.adl.oauth2.access.token.custom.provider": spark.conf.get("spark.databricks.passthrough.adls.tokenProviderClassName")
}
# Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "adl://<storage-account-name>.azuredatalakestore.net/<directory-name>",
mount_point = "/mnt/<mount-name>",
extra_configs = configs)
Scala
val configs = Map(
"fs.adl.oauth2.access.token.provider.type" -> "CustomAccessTokenProvider",
"fs.adl.oauth2.access.token.custom.provider" -> spark.conf.get("spark.databricks.passthrough.adls.tokenProviderClassName")
)
// Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "adl://<storage-account-name>.azuredatalakestore.net/<directory-name>",
mountPoint = "/mnt/<mount-name>",
extraConfigs = configs)
- استبدل
<storage-account-name>باسم حساب تخزين ADLS Gen2. - استبدل
<mount-name>باسم نقطة التحميل المقصودة في DBFS.
Azure Data Lake Storage Gen2
لتحميل نظام ملفات Azure Data Lake Storage Gen2 أو مجلد بداخله، استخدم الأوامر التالية:
Python
configs = {
"fs.azure.account.auth.type": "CustomAccessToken",
"fs.azure.account.custom.token.provider.class": spark.conf.get("spark.databricks.passthrough.adls.gen2.tokenProviderClassName")
}
# Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/",
mount_point = "/mnt/<mount-name>",
extra_configs = configs)
Scala
val configs = Map(
"fs.azure.account.auth.type" -> "CustomAccessToken",
"fs.azure.account.custom.token.provider.class" -> spark.conf.get("spark.databricks.passthrough.adls.gen2.tokenProviderClassName")
)
// Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/",
mountPoint = "/mnt/<mount-name>",
extraConfigs = configs)
- استبدل
<container-name>باسم حاوية في حساب تخزين ADLS Gen2. - استبدل
<storage-account-name>باسم حساب تخزين ADLS Gen2. - استبدل
<mount-name>باسم نقطة التحميل المقصودة في DBFS.
تحذير
لا توفر مفاتيح الوصول إلى حساب التخزين أو بيانات اعتماد كيان الخدمة للمصادقة على نقطة التحميل. من شأن ذلك أن يمنح المستخدمين الآخرين حق الوصول إلى نظام الملفات باستخدام بيانات الاعتماد هذه. الغرض من مرور بيانات اعتماد Azure Data Lake Storage هو منعك من استخدام بيانات الاعتماد هذه والتأكد من تقييد الوصول إلى نظام الملفات للمستخدمين الذين لديهم حق الوصول إلى حساب Azure Data Lake Storage الأساسي.
الأمان
من الآمن مشاركة مجموعات بيانات اعتماد Azure Data Lake Storage مع مستخدمين آخرين. سيتم عزلك عن بعضها البعض ولن تتمكن من قراءة بيانات اعتماد بعضها البعض أو استخدامها.
الميزات المدعومة
| ميزة | الحد الأدنى من إصدار وقت تشغيل Databricks | ملاحظات |
|---|---|---|
| Python وSQL | 5.5 | |
| Azure Data Lake Storage الجيل الأول | 5.5 | |
%run |
5.5 | |
| DBFS | 5.5 | يتم تمرير بيانات الاعتماد فقط إذا تم حل مسار DBFS إلى موقع في Azure Data Lake Storage Gen1 أو Gen2. بالنسبة إلى مسارات DBFS التي يتم حلها إلى أنظمة تخزين أخرى، استخدم أسلوبا مختلفا لتحديد بيانات الاعتماد الخاصة بك. |
| Azure Data Lake Storage Gen2 | 5.5 | |
| التخزين المؤقت للقرص | 5.5 | |
| واجهة برمجة تطبيقات PySpark ML | 5.5 | فئات التعلم الآلي التالية غير مدعومة: - org/apache/spark/ml/classification/RandomForestClassifier- org/apache/spark/ml/clustering/BisectingKMeans- org/apache/spark/ml/clustering/GaussianMixture- org/spark/ml/clustering/KMeans- org/spark/ml/clustering/LDA- org/spark/ml/evaluation/ClusteringEvaluator- org/spark/ml/feature/HashingTF- org/spark/ml/feature/OneHotEncoder- org/spark/ml/feature/StopWordsRemover- org/spark/ml/feature/VectorIndexer- org/spark/ml/feature/VectorSizeHint- org/spark/ml/regression/IsotonicRegression- org/spark/ml/regression/RandomForestRegressor- org/spark/ml/util/DatasetUtils |
| متغيرات البث | 5.5 | ضمن PySpark، هناك حد لحجم Python UDFs التي يمكنك إنشاؤها، حيث يتم إرسال UDFs الكبيرة كمتغيرات بث. |
| المكتبات ذات نطاق دفتر الملاحظات | 5.5 | |
| Scala | 5.5 | |
| سبارك | 6.0 | |
| sparklyr | 10.1 | |
| تشغيل دفتر ملاحظات Databricks من دفتر ملاحظات آخر | 6.1 | |
| واجهة برمجة تطبيقات PySpark ML | 6.1 | جميع فئات التعلم الآلي من PySpark مدعومة. |
| مقاييس نظام المجموعة | 6.1 | |
| Databricks Connect | 7.3 | يتم دعم Passthrough على أنظمة المجموعات القياسية. |
القيود
الميزات التالية غير مدعومة مع مرور بيانات اعتماد Azure Data Lake Storage:
%fs(استخدم الأمر dbutils.fs المكافئ بدلا من ذلك).- وظائف Databricks.
- مرجع Databricks REST API.
- كتالوج Unity.
- التحكم في الوصول إلى الجدول. يمكن استخدام الأذونات الممنوحة من قبل تمرير بيانات اعتماد Azure Data Lake Storage لتجاوز الأذونات الدقيقة لقوائم التحكم في الوصول بالجدول، في حين أن القيود الإضافية لقوائم التحكم بالوصول للجدول ستقيد بعض الفوائد التي تحصل عليها من تمرير بيانات الاعتماد. على وجه الخصوص:
- إذا كان لديك إذن معرف Microsoft Entra للوصول إلى ملفات البيانات التي تكمن وراء جدول معين، فستتوفر لديك أذونات كاملة على هذا الجدول عبر واجهة برمجة تطبيقات RDD، بغض النظر عن القيود المفروضة عليها عبر قوائم التحكم في الوصول للجدول.
- سيتم تقييدك بواسطة أذونات قوائم التحكم بالوصول للجدول فقط عند استخدام واجهة برمجة تطبيقات DataFrame. سترى تحذيرات حول عدم وجود إذن
SELECTعلى أي ملف إذا حاولت قراءة الملفات مباشرة باستخدام واجهة برمجة تطبيقات DataFrame، على الرغم من أنه يمكنك قراءة هذه الملفات مباشرة عبر واجهة برمجة تطبيقات RDD. - لن تتمكن من القراءة من الجداول المدعومة من قبل أنظمة الملفات بخلاف Azure Data Lake Storage، حتى إذا كان لديك إذن ACL الجدول لقراءة الجداول.
- الأساليب التالية على كائنات SparkContext (
sc) وSparkSession (spark):- أساليب مهملة.
- أساليب مثل
addFile()وaddJar()التي تسمح للمستخدمين غير المسؤولين باستدعاء تعليمة Scala البرمجية. - أي أسلوب يصل إلى نظام ملفات غير Azure Data Lake Storage Gen1 أو Gen2 (للوصول إلى أنظمة الملفات الأخرى على نظام مجموعة مع تمكين تمرير بيانات اعتماد Azure Data Lake Storage، استخدم أسلوبا مختلفا لتحديد بيانات الاعتماد الخاصة بك ورؤية القسم على أنظمة الملفات الموثوق بها ضمن استكشاف الأخطاء وإصلاحها).
- واجهات برمجة التطبيقات Hadoop القديمة (
hadoopFile()وhadoopRDD()). - واجهات برمجة التطبيقات المتدفقة، حيث ستنتهي صلاحية بيانات الاعتماد التي تم تمريرها أثناء استمرار تشغيل الدفق.
- تتوفر عمليات تحميل DBFS (
/dbfs) فقط في Databricks Runtime 7.3 LTS وما فوق. نقاط التحميل مع تمرير بيانات الاعتماد المكونة غير مدعومة من خلال هذا المسار. - Azure Data Factory.
- MLflow على مجموعات التزامن العالية.
- حزمة azureml-sdk Python على مجموعات التزامن العالية.
- لا يمكنك تمديد مدة بقاء الرموز المميزة لمعرف Microsoft Entra باستخدام نهج مدة بقاء الرمز المميز لمعرف Microsoft Entra. ونتيجة لذلك، إذا قمت بإرسال أمر إلى نظام المجموعة الذي يستغرق أكثر من ساعة، فسيفشل إذا تم الوصول إلى مورد Azure Data Lake Storage بعد علامة الساعة الواحدة.
- عند استخدام Hive 2.3 وما فوق، لا يمكنك إضافة قسم على مجموعة مع تمكين تمرير بيانات الاعتماد. لمزيد من المعلومات، راجع قسم استكشاف الأخطاء وإصلاحها ذات الصلة.
أمثلة على دفاتر الملاحظات
توضح دفاتر الملاحظات التالية مرور بيانات اعتماد Azure Data Lake Storage ل Azure Data Lake Storage Gen1 وGen2.
دفتر ملاحظات تمرير Azure Data Lake Storage Gen1
دفتر ملاحظات تمرير Azure Data Lake Storage Gen2
استكشاف الاخطاء
py4j.security.Py4JSecurityException: ... غير مدرج في القائمة البيضاء
يتم طرح هذا الاستثناء عند الوصول إلى أسلوب لم يتم وضع علامة عليه بشكل صريح على Azure Databricks على أنه آمن لمجموعات بيانات اعتماد Azure Data Lake Storage. في معظم الحالات، يعني هذا أن الأسلوب يمكن أن يسمح للمستخدم على نظام مجموعة بيانات اعتماد Azure Data Lake Storage بالوصول إلى بيانات اعتماد مستخدم آخر.
org.apache.spark.api.python.PythonSecurityException: Path ... يستخدم نظام ملفات غير موثوق به
يتم طرح هذا الاستثناء عند محاولة الوصول إلى نظام ملفات غير معروف من قبل مجموعة بيانات اعتماد Azure Data Lake Storage لتكون آمنة. قد يسمح استخدام نظام ملفات غير موثوق به للمستخدم على نظام مجموعة بيانات اعتماد Azure Data Lake Storage بالوصول إلى بيانات اعتماد مستخدم آخر، لذلك لا نسمح باستخدام جميع أنظمة الملفات التي لا نثق في أنها تستخدم بأمان.
لتكوين مجموعة أنظمة الملفات الموثوق بها على نظام مجموعة بيانات اعتماد Azure Data Lake Storage، قم بتعيين مفتاح spark.databricks.pyspark.trustedFilesystems تكوين Spark على نظام المجموعة هذا ليكون قائمة مفصولة بفواصل لأسماء الفئات التي هي تطبيقات موثوق بها ل org.apache.hadoop.fs.FileSystem.
فشل إضافة قسم عند AzureCredentialNotFoundException تمكين تمرير بيانات الاعتماد
عند استخدام Hive 2.3-3.1، إذا حاولت إضافة قسم على مجموعة مع تمكين تمرير بيانات الاعتماد، يحدث الاستثناء التالي:
org.apache.spark.sql.AnalysisException: org.apache.hadoop.hive.ql.metadata.HiveException: MetaException(message:com.databricks.backend.daemon.data.client.adl.AzureCredentialNotFoundException: Could not find ADLS Gen2 Token
للتغلب على هذه المشكلة، أضف أقساما على نظام مجموعة دون تمكين تمرير بيانات الاعتماد.