ملاحظة
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
الهامه
تم إيقاف هذه الوثائق وقد لا يتم تحديثها. لم تعد المنتجات أو الخدمات أو التقنيات المذكورة في هذا المحتوى مدعومة. راجع أنماط التاريخ والوقت.
Date تغيرت أنواع البيانات و Timestamp بشكل كبير في Databricks Runtime 7.0. توضح هذه المقالة ما يلي:
-
Dateالنوع والتقويم المقترن. -
Timestampالنوع وكيفية ارتباطه بالمناطق الزمنية. كما يشرح تفاصيل دقة إزاحة المنطقة الزمنية وتغييرات السلوك الدقيقة في واجهة برمجة تطبيقات الوقت الجديدة في Java 8، المستخدمة من قبل Databricks Runtime 7.0. - واجهات برمجة التطبيقات لإنشاء قيم التاريخ والطوابع الزمنية.
- المزالق الشائعة وأفضل الممارسات لجمع عناصر التاريخ والطوابع الزمنية على برنامج تشغيل Apache Spark.
التواريخ والتقويمات
عبارة Date عن مجموعة من حقول السنة والشهر واليوم، مثل (year=2012, month=12, day=31). ومع ذلك، تحتوي قيم حقول السنة والشهر واليوم على قيود لضمان أن قيمة التاريخ هي تاريخ صالح في العالم الحقيقي. على سبيل المثال، يجب أن تتراوح قيمة الشهر من 1 إلى 12، ويجب أن تتراوح قيمة اليوم من 1 إلى 28,29,30 أو 31 (اعتمادا على السنة والشهر)، وما إلى ذلك.
Date لا يعتبر النوع المناطق الزمنية.
التقويمات
يتم تحديد القيود المفروضة على Date الحقول بواسطة أحد التقويمات العديدة الممكنة. يتم استخدام بعضها، مثل التقويم القمري، في مناطق معينة فقط. يتم استخدام بعضها، مثل التقويم اليوليوسي، في المحفوظات فقط. المعيار الدولي الفعلي هو التقويم الميلادي الذي يستخدم في كل مكان تقريبا في العالم لأغراض مدنية. وقد تم تقديمه في عام 1582 وتم تمديده ليشمل تواريخ الدعم قبل عام 1582 أيضا. يسمى هذا التقويم الموسع التقويم الميلادي Proleptic.
يستخدم Databricks Runtime 7.0 التقويم الميلادي Proleptic، والذي يتم استخدامه بالفعل من قبل أنظمة بيانات أخرى مثل pandas وR وApache Arrow. استخدم Databricks Runtime 6.x والإصدارات الأحدث مزيجا من التقويم اليولياني والتقويم الميلادي: بالنسبة للتواريخ قبل عام 1582، تم استخدام التقويم اليولياني، للتواريخ بعد عام 1582 تم استخدام التقويم الميلادي. يتم توريث هذا من واجهة برمجة التطبيقات القديمة java.sql.Date ، والتي تم تغييرها في Java 8 بواسطة java.time.LocalDate، والتي تستخدم التقويم الميلادي Proleptic.
الطوابع الزمنية والمناطق الزمنية
يوسع TimestampDate النوع النوع بالحقول الجديدة: الساعة والدقيقة والثانية (التي يمكن أن تحتوي على جزء كسري) ومع منطقة زمنية عمومية (محددة النطاق لجلسة العمل). وهو يحدد لحظة زمنية ملموسة. على سبيل المثال، (year=2012, month=12, day=31, hour=23, minute=59, second=59.123456) مع المنطقة الزمنية للجلسة UTC+01:00. عند كتابة قيم الطابع الزمني إلى مصادر بيانات غير نصية مثل Parquet، تكون القيم مجرد مثيلات (مثل الطابع الزمني بالتوقيت العالمي المتفق عليه) التي لا تحتوي على معلومات المنطقة الزمنية. إذا قمت بكتابة قيمة طابع زمني وقراءتها بمنطقة زمنية مختلفة لجلسة العمل، فقد ترى قيما مختلفة للحول الساعة والدقيقة والثانية، ولكنها نفس اللحظة الزمنية الملموسة.
تحتوي حقول الساعة والدقيقة والثانية على نطاقات قياسية: 0-23 للساعات و0-59 للدقائق والثوان. يدعم Spark الثوان الكسرية بدقة تصل إلى الميكرو ثانية. يتراوح النطاق الصالح للكسور من 0 إلى 999999 ميكرو ثانية.
في أي لحظة ملموسة، اعتمادا على المنطقة الزمنية، يمكنك مراقبة العديد من قيم ساعة الحائط المختلفة:
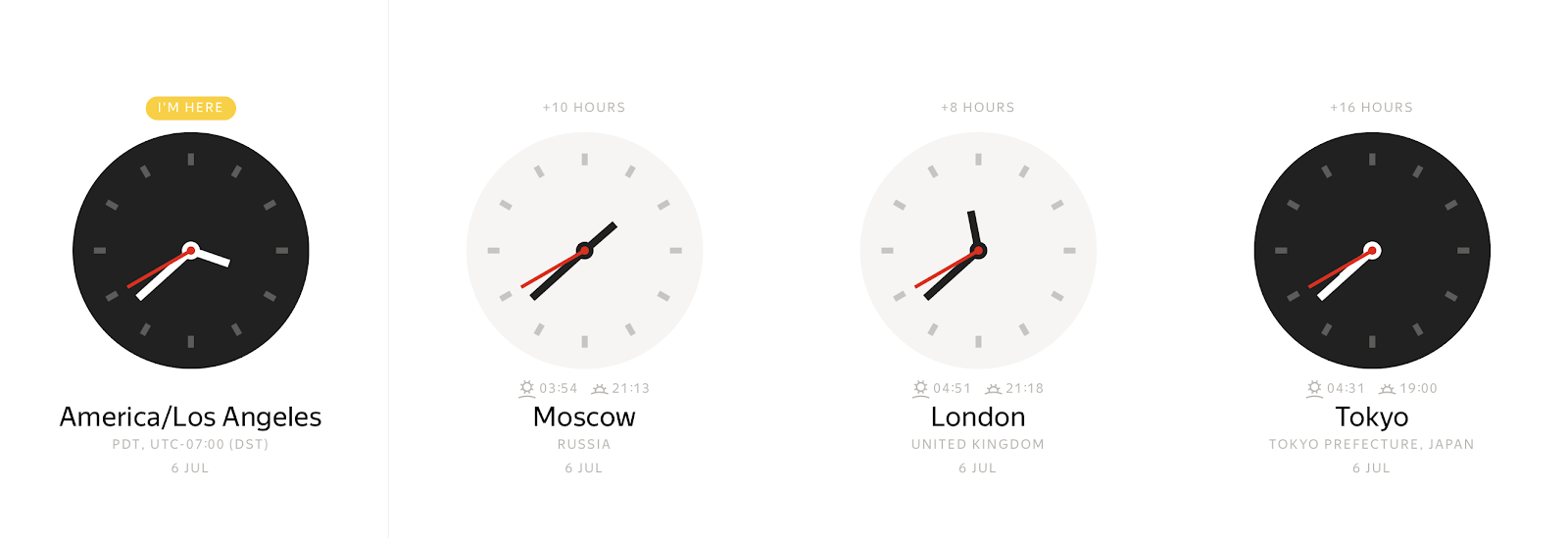
وعلى العكس من ذلك، يمكن أن تمثل قيمة ساعة الحائط العديد من اللحظات الزمنية المختلفة.
تسمح لك إزاحة المنطقة الزمنية بربط طابع زمني محلي بشكل لا لبس فيه بلحظة زمنية. عادة ما يتم تعريف إزاحات المنطقة الزمنية على أنها إزاحات بالساعات من توقيت غرينتش (GMT) أو UTC+0 (التوقيت العالمي المتفق عليه). هذا التمثيل لمعلومات المنطقة الزمنية يلغي الغموض، ولكنه غير مريح. يفضل معظم الأشخاص الإشارة إلى موقع مثل America/Los_Angeles أو Europe/Paris. هذا المستوى الإضافي من التجريد من إزاحات المنطقة يجعل الحياة أسهل ولكنه يجلب مضاعفات. على سبيل المثال، يجب عليك الآن الاحتفاظ بقاعدة بيانات منطقة زمنية خاصة لتعيين أسماء المنطقة الزمنية إلى إزاحات. نظرا لأن Spark يعمل على JVM، فإنه يفوض التعيين إلى مكتبة Java القياسية، والتي تقوم بتحميل البيانات من قاعدة بيانات المنطقة الزمنية لمرجع الأرقام المعينة عبر الإنترنت (IANA TZDB). علاوة على ذلك، تحتوي آلية التعيين في مكتبة Java القياسية على بعض الفروق الدقيقة التي تؤثر على سلوك Spark.
منذ Java 8، كشف JDK واجهة برمجة تطبيقات مختلفة للتلاعب في التاريخ والوقت ودقة إزاحة المنطقة الزمنية ويستخدم Databricks Runtime 7.0 واجهة برمجة التطبيقات هذه. على الرغم من أن تعيين أسماء المنطقة الزمنية إلى الإزاحات له نفس المصدر، IANA TZDB، فإنه يتم تنفيذه بشكل مختلف في Java 8 وما فوق مقارنة ب Java 7.
على سبيل المثال، ألق نظرة على طابع زمني قبل عام 1883 في المنطقة الزمنية America/Los_Angeles : 1883-11-10 00:00:00. هذا العام تبرز من الآخرين لأنه في 18 نوفمبر 1883، تحولت جميع السكك الحديدية في أمريكا الشمالية إلى نظام زمني قياسي جديد. باستخدام واجهة برمجة تطبيقات Java 7 time، يمكنك الحصول على إزاحة المنطقة الزمنية في الطابع الزمني المحلي ك -08:00:
java.time.ZoneId.systemDefault
res0:java.time.ZoneId = America/Los_Angeles
java.sql.Timestamp.valueOf("1883-11-10 00:00:00").getTimezoneOffset / 60.0
res1: Double = 8.0
ترجع واجهة برمجة تطبيقات Java 8 المكافئة نتيجة مختلفة:
java.time.ZoneId.of("America/Los_Angeles").getRules.getOffset(java.time.LocalDateTime.parse("1883-11-10T00:00:00"))
res2: java.time.ZoneOffset = -07:52:58
قبل 18 نوفمبر 1883، كان الوقت من اليوم في أمريكا الشمالية مسألة محلية، واستخدمت معظم المدن والبلدات شكلا من أشكال الوقت الشمسي المحلي، التي تحافظ عليها ساعة معروفة (على شرج كنيسة، على سبيل المثال، أو في نافذة صائغ). لهذا السبب ترى إزاحة منطقة زمنية غريبة.
يوضح المثال أن وظائف Java 8 أكثر دقة وتأخذ في الاعتبار البيانات التاريخية من IANA TZDB. بعد التبديل إلى واجهة برمجة تطبيقات وقت Java 8، استفاد Databricks Runtime 7.0 من التحسين تلقائيا وأصبح أكثر دقة في كيفية حل إزاحات المنطقة الزمنية.
تم أيضا تبديل Databricks Runtime 7.0 إلى التقويم الميلادي Proleptic للنوع Timestamp . يعلن معيار ISO SQL:2016 النطاق الصالح للطوابع الزمنية من 0001-01-01 00:00:00 إلى 9999-12-31 23:59:59.999999. يتوافق Databricks Runtime 7.0 تماما مع المعيار ويدعم جميع الطوابع الزمنية في هذا النطاق. بالمقارنة مع Databricks Runtime 6.x والإصدارات أدناه، لاحظ النطاقات الفرعية التالية:
-
0001-01-01 00:00:00..1582-10-03 23:59:59.999999. يستخدم Databricks Runtime 6.x والإصدارات أدناه التقويم Julian ولا يتوافق مع المعيار. يعمل Databricks Runtime 7.0 على إصلاح المشكلة وتطبيق التقويم الميلادي Proleptic في العمليات الداخلية على الطوابع الزمنية مثل الحصول على السنة والشهر واليوم وما إلى ذلك. نظرا للتقويمات المختلفة، لا توجد بعض التواريخ الموجودة في Databricks Runtime 6.x والإصدارات أدناه في Databricks Runtime 7.0. على سبيل المثال، 1000-02-29 ليس تاريخا صحيحا لأن 1000 ليست سنة كبيسة في التقويم الميلادي. أيضا، يحل Databricks Runtime 6.x والإصدارات أدناه اسم المنطقة الزمنية إلى إزاحات المنطقة بشكل غير صحيح لنطاق الطابع الزمني هذا. -
1582-10-04 00:00:00..1582-10-14 23:59:59.999999. هذا نطاق صحيح من الطوابع الزمنية المحلية في Databricks Runtime 7.0، على عكس Databricks Runtime 6.x والإصدارات أدناه حيث لم تكن هذه الطوابع الزمنية موجودة. -
1582-10-15 00:00:00..1899-12-31 23:59:59.999999. يحل Databricks Runtime 7.0 إزاحات المنطقة الزمنية بشكل صحيح باستخدام البيانات التاريخية من IANA TZDB. بالمقارنة مع Databricks Runtime 7.0، قد يحل Databricks Runtime 6.x والإصدارات أدناه إزاحات المنطقة من أسماء المناطق الزمنية بشكل غير صحيح في بعض الحالات، كما هو موضح في المثال السابق. -
1900-01-01 00:00:00..2036-12-31 23:59:59.999999. يتوافق كل من Databricks Runtime 7.0 وDatabricks Runtime 6.x والإصدارات أدناه مع معيار ANSI SQL ويستخدم التقويم الميلادي في عمليات التاريخ والوقت مثل الحصول على يوم من الشهر. -
2037-01-01 00:00:00..9999-12-31 23:59:59.999999. يمكن أن يحل Databricks Runtime 6.x والإصدارات أدناه إزاحات المنطقة الزمنية وإزاحات التوقيت الصيفي بشكل غير صحيح. Databricks Runtime 7.0 لا.
يتمثل جانب آخر من جوانب تعيين أسماء المناطق الزمنية للإزاحات في تداخل الطوابع الزمنية المحلية التي يمكن أن تحدث بسبب التوقيت الصيفي (DST) أو التبديل إلى إزاحة منطقة زمنية قياسية أخرى. على سبيل المثال، في 3 نوفمبر 2019، 02:00:00، حولت معظم الولايات في الولايات المتحدة الأمريكية الساعات للخلف 1 ساعة إلى 01:00:00. يمكن تعيين الطابع 2019-11-03 01:30:00 America/Los_Angeles الزمني المحلي إما إلى 2019-11-03 01:30:00 UTC-08:00 أو 2019-11-03 01:30:00 UTC-07:00. إذا لم تحدد الإزاحة وقمت فقط بتعيين اسم المنطقة الزمنية (على سبيل المثال، 2019-11-03 01:30:00 America/Los_Angeles)، فإن Databricks Runtime 7.0 يأخذ الإزاحة السابقة، التي تتوافق عادة مع "الصيف". يختلف السلوك عن Databricks Runtime 6.x والإصدارات أدناه التي تأخذ إزاحة "الشتاء". في حالة وجود فجوة، حيث تقفز الساعات إلى الأمام، لا توجد إزاحة صالحة. لتغيير التوقيت الصيفي المعتاد لمدة ساعة واحدة، ينقل Spark مثل هذه الطوابع الزمنية إلى الطابع الزمني الصالح التالي المطابق لوقت "الصيف".
كما ترى من الأمثلة السابقة، فإن تعيين أسماء المناطق الزمنية إلى الإزاحات غامض، وليس واحدا تلو الآخر. في الحالات التي يكون فيها ذلك ممكنا، عند إنشاء الطوابع الزمنية، نوصي بتحديد إزاحات المنطقة الزمنية الدقيقة، على سبيل المثال 2019-11-03 01:30:00 UTC-07:00.
الطوابع الزمنية ANSI SQL وSpark SQL
يحدد معيار ANSI SQL نوعين من الطوابع الزمنية:
-
TIMESTAMP WITHOUT TIME ZONEأوTIMESTAMP: الطابع الزمني المحلي ك (YEAR، ،MONTH،DAYHOUR،MINUTE،SECOND). هذه الطوابع الزمنية غير مرتبطة بأي منطقة زمنية، وهي طوابع زمنية لساعة الحائط. -
TIMESTAMP WITH TIME ZONE: الطابع الزمني للمنطقة ك (YEAR، ،DAYMONTH،HOUR،MINUTE،SECOND، ، ).TIMEZONE_HOURTIMEZONE_MINUTEتمثل هذه الطوابع الزمنية لحظة في المنطقة الزمنية UTC + إزاحة المنطقة الزمنية (بالساعات والدقائق) المقترنة بكل قيمة.
لا تؤثر إزاحة المنطقة الزمنية TIMESTAMP WITH TIME ZONE ل على النقطة المادية في الوقت الذي يمثله الطابع الزمني، حيث يتم تمثيل ذلك بالكامل من خلال فورية التوقيت العالمي المتفق عليه التي تمنحها مكونات الطابع الزمني الأخرى. بدلا من ذلك، تؤثر إزاحة المنطقة الزمنية فقط على السلوك الافتراضي لقيمة الطابع الزمني للعرض واستخراج مكون التاريخ/الوقت (على سبيل المثال، EXTRACT)، والعمليات الأخرى التي تتطلب معرفة منطقة زمنية، مثل إضافة أشهر إلى طابع زمني.
يعرف Spark SQL نوع الطابع الزمني على أنه TIMESTAMP WITH SESSION TIME ZONE، وهو مزيج من الحقول (YEAR، MONTH، DAY، HOUR، MINUTE، SECOND، SESSION TZ) حيث YEAR يحدد الحقل من خلال SECOND لحظة زمنية في المنطقة الزمنية UTC، وحيث يتم أخذ SESSION TZ من تكوين SQL spark.sql.session.timeZone. يمكن تعيين المنطقة الزمنية للجلسة على النحو التالي:
- إزاحة
(+|-)HH:mmالمنطقة . يسمح لك هذا النموذج بتعريف نقطة فعلية في الوقت المحدد بشكل لا لبس فيه. - اسم المنطقة الزمنية في شكل معرف
area/cityالمنطقة ، مثلAmerica/Los_Angeles. يعاني هذا الشكل من معلومات المنطقة الزمنية من بعض المشاكل الموضحة سابقا مثل تداخل الطوابع الزمنية المحلية. ومع ذلك، ترتبط كل لحظة زمنية UTC بشكل لا لبس فيه بإزاحة منطقة زمنية واحدة لأي معرف منطقة، ونتيجة لذلك، يمكن تحويل كل طابع زمني بمنطقة زمنية تستند إلى معرف المنطقة بشكل لا لبس فيه إلى طابع زمني مع إزاحة منطقة. بشكل افتراضي، يتم تعيين المنطقة الزمنية لجلسة العمل إلى المنطقة الزمنية الافتراضية لجهاز Java الظاهري.
يختلف Spark TIMESTAMP WITH SESSION TIME ZONE عن:
-
TIMESTAMP WITHOUT TIME ZONE، لأن قيمة من هذا النوع يمكن تعيينها إلى عدة مثيلات زمنية فعلية، ولكن أي قيمةTIMESTAMP WITH SESSION TIME ZONEهي لحظة زمنية فعلية ملموسة. يمكن محاكاة نوع SQL باستخدام إزاحة منطقة زمنية ثابتة واحدة عبر جميع الجلسات، على سبيل المثال UTC+0. في هذه الحالة، يمكنك اعتبار الطوابع الزمنية في التوقيت العالمي المتفق عليه كطوابع زمنية محلية. -
TIMESTAMP WITH TIME ZONE، لأنه وفقا لقيم العمود القياسي SQL من النوع يمكن أن يكون لها إزاحات مختلفة للمنطقة الزمنية. هذا غير مدعوم من قبل Spark SQL.
يجب أن تلاحظ أن الطوابع الزمنية المقترنة بمنطقة زمنية عمومية (محددة نطاق الجلسة) ليست شيئا تم اختراعه حديثا بواسطة Spark SQL. توفر RDBMSs مثل Oracle نوعا مشابها للطوابع الزمنية: TIMESTAMP WITH LOCAL TIME ZONE.
إنشاء التواريخ والطوابع الزمنية
يوفر Spark SQL بعض الطرق لإنشاء قيم التاريخ والطوابع الزمنية:
- الدالات الإنشائية الافتراضية بدون معلمات:
CURRENT_TIMESTAMP()وCURRENT_DATE(). - من أنواع Spark SQL الأولية الأخرى، مثل
INTوLONGوSTRING - من أنواع خارجية مثل Python datetime أو فئات
java.time.LocalDate/InstantJava . - إلغاء التسلسل من مصادر البيانات مثل CSV وJSON وAvro وParquet وORC وما إلى ذلك.
تأخذ الدالة MAKE_DATE المقدمة في Databricks Runtime 7.0 ثلاث معلمات -YEAR و MONTHو DAY- وتنشئ DATE قيمة. يتم تحويل جميع معلمات الإدخال ضمنيا إلى INT النوع كلما أمكن ذلك. تتحقق الدالة من أن التواريخ الناتجة هي تواريخ صالحة في التقويم الميلادي Proleptic، وإلا فإنها ترجع NULL. على سبيل المثال:
spark.createDataFrame([(2020, 6, 26), (1000, 2, 29), (-44, 1, 1)],['Y', 'M', 'D']).createTempView('YMD')
df = sql('select make_date(Y, M, D) as date from YMD')
df.printSchema()
root
|-- date: date (nullable = true)
لطباعة محتوى DataFrame، استدع show() الإجراء الذي يحول التواريخ إلى سلاسل على المنفذين وينقل السلاسل إلى برنامج التشغيل لإخراجها على وحدة التحكم:
df.show()
+-----------+
| date|
+-----------+
| 2020-06-26|
| null|
|-0044-01-01|
+-----------+
وبالمثل، يمكنك إنشاء قيم الطابع الزمني باستخدام MAKE_TIMESTAMP الدالات. مثل MAKE_DATE، يقوم بإجراء نفس التحقق من صحة حقول التاريخ، ويقبل بالإضافة إلى ذلك حقول الوقت HOUR (0-23) و MINUTE (0-59) و SECOND (0-60). الثاني له نوع عشري (دقة = 8، مقياس = 6) لأنه يمكن تمرير الثوان مع الجزء الكسري حتى دقة microsecond. على سبيل المثال:
df = spark.createDataFrame([(2020, 6, 28, 10, 31, 30.123456), \
(1582, 10, 10, 0, 1, 2.0001), (2019, 2, 29, 9, 29, 1.0)],['YEAR', 'MONTH', 'DAY', 'HOUR', 'MINUTE', 'SECOND'])
df.show()
+----+-----+---+----+------+---------+
|YEAR|MONTH|DAY|HOUR|MINUTE| SECOND|
+----+-----+---+----+------+---------+
|2020| 6| 28| 10| 31|30.123456|
|1582| 10| 10| 0| 1| 2.0001|
|2019| 2| 29| 9| 29| 1.0|
+----+-----+---+----+------+---------+
df.selectExpr("make_timestamp(YEAR, MONTH, DAY, HOUR, MINUTE, SECOND) as MAKE_TIMESTAMP")
ts.printSchema()
root
|-- MAKE_TIMESTAMP: timestamp (nullable = true)
أما بالنسبة للتواريخ، فاطبع محتوى ts DataFrame باستخدام إجراء show(). بطريقة مماثلة، show() يحول الطوابع الزمنية إلى سلاسل ولكنه يأخذ الآن في الاعتبار المنطقة الزمنية لجلسة العمل المحددة بواسطة تكوين spark.sql.session.timeZoneSQL .
ts.show(truncate=False)
+--------------------------+
|MAKE_TIMESTAMP |
+--------------------------+
|2020-06-28 10:31:30.123456|
|1582-10-10 00:01:02.0001 |
|null |
+--------------------------+
يتعذر على Spark إنشاء الطابع الزمني الأخير لأن هذا التاريخ غير صحيح: 2019 ليس سنة كبيسة.
قد تلاحظ عدم وجود معلومات المنطقة الزمنية في المثال السابق. في هذه الحالة، يأخذ Spark منطقة زمنية من تكوين spark.sql.session.timeZone SQL ويطبقها على استدعاءات الوظائف. يمكنك أيضا اختيار منطقة زمنية مختلفة عن طريق تمريرها كمعلمة أخيرة ل MAKE_TIMESTAMP. فيما يلي مثال:
df = spark.createDataFrame([(2020, 6, 28, 10, 31, 30, 'UTC'),(1582, 10, 10, 0, 1, 2, 'America/Los_Angeles'), \
(2019, 2, 28, 9, 29, 1, 'Europe/Moscow')], ['YEAR', 'MONTH', 'DAY', 'HOUR', 'MINUTE', 'SECOND', 'TZ'])
df = df.selectExpr('make_timestamp(YEAR, MONTH, DAY, HOUR, MINUTE, SECOND, TZ) as MAKE_TIMESTAMP')
df = df.selectExpr("date_format(MAKE_TIMESTAMP, 'yyyy-MM-dd HH:mm:ss VV') AS TIMESTAMP_STRING")
df.show(truncate=False)
+---------------------------------+
|TIMESTAMP_STRING |
+---------------------------------+
|2020-06-28 13:31:00 Europe/Moscow|
|1582-10-10 10:24:00 Europe/Moscow|
|2019-02-28 09:29:00 Europe/Moscow|
+---------------------------------+
كما يوضح المثال، يأخذ Spark في الاعتبار المناطق الزمنية المحددة ولكنه يضبط جميع الطوابع الزمنية المحلية إلى المنطقة الزمنية لجلسة العمل. يتم فقدان المناطق الزمنية الأصلية التي تم تمريرها إلى الدالة MAKE_TIMESTAMP لأن TIMESTAMP WITH SESSION TIME ZONE النوع يفترض أن جميع القيم تنتمي إلى منطقة زمنية واحدة، ولا تخزن حتى منطقة زمنية لكل قيمة. وفقا لتعريف TIMESTAMP WITH SESSION TIME ZONE، يخزن Spark الطوابع الزمنية المحلية في المنطقة الزمنية UTC، ويستخدم المنطقة الزمنية لجلسة العمل أثناء استخراج حقول التاريخ والوقت أو تحويل الطوابع الزمنية إلى سلاسل.
أيضا، يمكن إنشاء الطوابع الزمنية من نوع LONG باستخدام الصب. إذا كان عمود LONG يحتوي على عدد الثواني منذ الفترة 1970-01-01 00:00:00Z، فيمكن تحويله إلى Spark SQL TIMESTAMP:
select CAST(-123456789 AS TIMESTAMP);
1966-02-02 05:26:51
لسوء الحظ، لا يسمح لك هذا النهج بتحديد الجزء الكسري من الثوان.
طريقة أخرى هي إنشاء التواريخ والطوابع الزمنية من قيم من STRING النوع. يمكنك إجراء قيم حرفية باستخدام كلمات أساسية خاصة:
select timestamp '2020-06-28 22:17:33.123456 Europe/Amsterdam', date '2020-07-01';
2020-06-28 23:17:33.123456 2020-07-01
بدلا من ذلك، يمكنك استخدام التحويل الذي يمكنك تطبيقه على جميع القيم في عمود:
select cast('2020-06-28 22:17:33.123456 Europe/Amsterdam' as timestamp), cast('2020-07-01' as date);
2020-06-28 23:17:33.123456 2020-07-01
يتم تفسير سلاسل الطابع الزمني للإدخال على أنها طوابع زمنية محلية في المنطقة الزمنية المحددة أو في المنطقة الزمنية لجلسة العمل إذا تم حذف منطقة زمنية في سلسلة الإدخال. يمكن تحويل السلاسل ذات الأنماط غير العادية إلى طابع زمني باستخدام الدالة to_timestamp() . يتم وصف الأنماط المدعومة في أنماط التاريخ والوقت للتنسيق وتحليلها:
select to_timestamp('28/6/2020 22.17.33', 'dd/M/yyyy HH.mm.ss');
2020-06-28 22:17:33
إذا لم تحدد نمطا، فإن الدالة تتصرف بشكل مشابه ل CAST.
لسهولة الاستخدام، يتعرف Spark SQL على قيم السلسلة الخاصة في جميع الطرق التي تقبل سلسلة وترجع طابعا زمنيا أو تاريخا:
-
epochهو اسم مستعار للتاريخ1970-01-01أو الطابع1970-01-01 00:00:00Zالزمني . -
nowهو الطابع الزمني الحالي أو التاريخ في المنطقة الزمنية لجلسة العمل. ضمن استعلام واحد، ينتج دائما نفس النتيجة. -
todayهو بداية التاريخ الحالي للنوعTIMESTAMPأو التاريخ الحالي فقط للنوعDATE. -
tomorrowهو بداية اليوم التالي للطوابع الزمنية أو في اليوم التالي فقط للنوعDATE. -
yesterdayهو اليوم السابق لليوم الحالي أو بدايته للنوعTIMESTAMP.
على سبيل المثال:
select timestamp 'yesterday', timestamp 'today', timestamp 'now', timestamp 'tomorrow';
2020-06-27 00:00:00 2020-06-28 00:00:00 2020-06-28 23:07:07.18 2020-06-29 00:00:00
select date 'yesterday', date 'today', date 'now', date 'tomorrow';
2020-06-27 2020-06-28 2020-06-28 2020-06-29
يسمح لك Spark بإنشاء Datasets من مجموعات موجودة من العناصر الخارجية على جانب برنامج التشغيل وإنشاء أعمدة من الأنواع المقابلة. يحول Spark مثيلات الأنواع الخارجية إلى تمثيلات داخلية مكافئة دلاليا. على سبيل المثال، لإنشاء Dataset مع DATE وأعمدة TIMESTAMP من مجموعات Python، يمكنك استخدام:
import datetime
df = spark.createDataFrame([(datetime.datetime(2020, 7, 1, 0, 0, 0), datetime.date(2020, 7, 1))], ['timestamp', 'date'])
df.show()
+-------------------+----------+
| timestamp| date|
+-------------------+----------+
|2020-07-01 00:00:00|2020-07-01|
+-------------------+----------+
يحول PySpark كائنات التاريخ والوقت في Python إلى تمثيلات Spark SQL الداخلية على جانب برنامج التشغيل باستخدام المنطقة الزمنية للنظام، والتي يمكن أن تكون مختلفة عن إعداد spark.sql.session.timeZoneالمنطقة الزمنية لجلسة Spark . لا تحتوي القيم الداخلية على معلومات حول المنطقة الزمنية الأصلية. تأخذ العمليات المستقبلية عبر قيم التاريخ والطوابع الزمنية المتوازية في الاعتبار المنطقة الزمنية لجلسات Spark SQL فقط وفقا لتعريف TIMESTAMP WITH SESSION TIME ZONE النوع.
بطريقة مماثلة، يتعرف Spark على الأنواع التالية كالأنواع الخارجية لوقت التاريخ في واجهات برمجة تطبيقات Java و Scala:
-
java.sql.Dateو لأنواعjava.time.LocalDateخارجية للنوعDATE -
java.sql.Timestampوللنوعjava.time.InstantTIMESTAMP.
هناك فرق بين java.sql.* والأنواع java.time.* .
java.time.LocalDate
java.time.Instant وأضيفت في Java 8، وتعتمد الأنواع على التقويم الميلادي Proleptic - نفس التقويم الذي يستخدمه Databricks Runtime 7.0 وما فوق.
java.sql.Date وامتلك java.sql.Timestamp تقويما آخر أسفل التقويم المختلط (Julian + الميلادي منذ 1582-10-15)، وهو نفس التقويم القديم المستخدم من قبل Databricks Runtime 6.x والإصدارات أدناه. نظرا لأنظمة التقويم المختلفة، يجب على Spark إجراء عمليات إضافية أثناء التحويلات إلى تمثيلات Spark SQL الداخلية، وإعادة قاعدة تواريخ الإدخال/الطابع الزمني من تقويم إلى آخر. تحتوي عملية إعادة الترس على القليل من النفقات العامة للطوابع الزمنية الحديثة بعد عام 1900، ويمكن أن تكون أكثر أهمية للطوابع الزمنية القديمة.
يوضح المثال التالي كيفية إنشاء طوابع زمنية من مجموعات Scala. يقوم المثال الأول بإنشاء كائن java.sql.Timestamp من سلسلة.
valueOf يفسر الأسلوب سلاسل الإدخال على أنها طابع زمني محلي في المنطقة الزمنية الافتراضية ل JVM والتي يمكن أن تكون مختلفة عن المنطقة الزمنية لجلسة Spark. إذا كنت بحاجة إلى إنشاء مثيلات من java.sql.Timestamp أو java.sql.Date في منطقة زمنية معينة، فلق نظرة على java.text.SimpleDateFormat (وطريقته setTimeZone) أو java.util.Calendar.
Seq(java.sql.Timestamp.valueOf("2020-06-29 22:41:30"), new java.sql.Timestamp(0)).toDF("ts").show(false)
+-------------------+
|ts |
+-------------------+
|2020-06-29 22:41:30|
|1970-01-01 03:00:00|
+-------------------+
Seq(java.time.Instant.ofEpochSecond(-12219261484L), java.time.Instant.EPOCH).toDF("ts").show
+-------------------+
| ts|
+-------------------+
|1582-10-15 11:12:13|
|1970-01-01 03:00:00|
+-------------------+
وبالمثل، يمكنك إنشاء DATE عمود من مجموعات أو java.sql.Datejava.sql.LocalDate. يعد توازي java.sql.LocalDate المثيلات مستقلا تماما عن جلسة Spark أو المناطق الزمنية الافتراضية ل JVM، ولكن نفس الشيء لا ينطبق على توازي java.sql.Date المثيلات. هناك الفروق الدقيقة:
-
java.sql.Dateتمثل المثيلات التواريخ المحلية في المنطقة الزمنية الافتراضية ل JVM على برنامج التشغيل. - للتحويلات الصحيحة إلى قيم Spark SQL، يجب أن تكون المنطقة الزمنية الافتراضية ل JVM على برنامج التشغيل والمنفذين هي نفسها.
Seq(java.time.LocalDate.of(2020, 2, 29), java.time.LocalDate.now).toDF("date").show
+----------+
| date|
+----------+
|2020-02-29|
|2020-06-29|
+----------+
لتجنب أي مشكلات متعلقة بالتقويم والمنطقة الزمنية، نوصي بأنواع Java 8 لأنواع java.sql.LocalDate/Instant خارجية بالتوازي مع مجموعات Java/Scala من الطوابع الزمنية أو التواريخ.
جمع التواريخ والطوابع الزمنية
العملية العكسية للتوازي هي جمع التواريخ والطوابع الزمنية من المنفذين مرة أخرى إلى برنامج التشغيل وإرجاع مجموعة من الأنواع الخارجية. على سبيل المثال أعلاه، يمكنك سحب DataFrame مرة أخرى إلى برنامج التشغيل باستخدام collect() الإجراء :
df.collect()
[Row(timestamp=datetime.datetime(2020, 7, 1, 0, 0), date=datetime.date(2020, 7, 1))]
ينقل Spark القيم الداخلية لأعمدة التواريخ والطوابع الزمنية كلحظات زمنية في المنطقة الزمنية UTC من المنفذين إلى برنامج التشغيل، وينفذ التحويلات إلى كائنات وقت التاريخ Python في المنطقة الزمنية للنظام في برنامج التشغيل، وليس باستخدام المنطقة الزمنية لجلسة Spark SQL.
collect() يختلف عن الإجراء الموضح show() في القسم السابق.
show() يستخدم المنطقة الزمنية لجلسة العمل أثناء تحويل الطوابع الزمنية إلى سلاسل، ويجمع السلاسل الناتجة على برنامج التشغيل.
في واجهات برمجة تطبيقات Java و Scala، يقوم Spark بإجراء التحويلات التالية بشكل افتراضي:
- يتم تحويل قيم Spark SQL
DATEإلى مثيلات .java.sql.Date - يتم تحويل قيم Spark SQL
TIMESTAMPإلى مثيلات .java.sql.Timestamp
يتم تنفيذ كلا التحويلين في المنطقة الزمنية الافتراضية ل JVM على برنامج التشغيل. بهذه الطريقة، للحصول على نفس حقول التاريخ والوقت التي يمكنك الحصول عليها باستخدام Date.getDay()، getHour()وهكذا، واستخدام وظائف DAYSpark SQL ، HOURيجب أن تكون المنطقة الزمنية الافتراضية ل JVM على برنامج التشغيل والمنطقة الزمنية لجلسة العمل على المنفذين هي نفسها.
على غرار إنشاء التواريخ/الطوابع الزمنية من java.sql.Date/Timestamp، يقوم Databricks Runtime 7.0 بإعادة التوجيه من التقويم الميلادي Proleptic إلى التقويم المختلط (Julian + ميلادي). هذه العملية مجانية تقريبا للتواريخ الحديثة (بعد عام 1582) والطوابع الزمنية (بعد عام 1900)، ولكن يمكن أن تجلب بعض النفقات العامة للتواريخ والطوابع الزمنية القديمة.
يمكنك تجنب مثل هذه المشكلات المتعلقة بالتقويم، واطلب من Spark إرجاع java.time الأنواع، التي تمت إضافتها منذ Java 8. إذا قمت بتعيين تكوين spark.sql.datetime.java8API.enabled SQL إلى صحيح، يرجع Dataset.collect() الإجراء:
-
java.time.LocalDateلنوع Spark SQLDATE -
java.time.Instantلنوع Spark SQLTIMESTAMP
الآن لا تعاني التحويلات من المشكلات المتعلقة بالتقويم لأن أنواع Java 8 وDatabricks Runtime 7.0 والإصدارات الأحدث تستند إلى التقويم الميلادي Proleptic.
collect() لا يعتمد الإجراء على المنطقة الزمنية الافتراضية ل JVM. لا تعتمد تحويلات الطابع الزمني على المنطقة الزمنية على الإطلاق. تستخدم تحويلات التاريخ المنطقة الزمنية لجلسة العمل من تكوين spark.sql.session.timeZoneSQL . على سبيل المثال، ضع في اعتبارك DatasetDATE مع وأعمدة TIMESTAMP ، مع تعيين المنطقة الزمنية الافتراضية JVM إلى Europe/Moscow وتعيين المنطقة الزمنية لجلسة العمل إلى America/Los_Angeles.
java.util.TimeZone.getDefault
res1: java.util.TimeZone = sun.util.calendar.ZoneInfo[id="Europe/Moscow",...]
spark.conf.get("spark.sql.session.timeZone")
res2: String = America/Los_Angeles
df.show
+-------------------+----------+
| timestamp| date|
+-------------------+----------+
|2020-07-01 00:00:00|2020-07-01|
+-------------------+----------+
يطبع show() الإجراء الطابع الزمني في وقت America/Los_Angelesالجلسة ، ولكن إذا قمت بجمع Dataset، يتم تحويله إلى java.sql.Timestamp ويطبع toStringEurope/Moscowالأسلوب :
df.collect()
res16: Array[org.apache.spark.sql.Row] = Array([2020-07-01 10:00:00.0,2020-07-01])
df.collect()(0).getAs[java.sql.Timestamp](0).toString
res18: java.sql.Timestamp = 2020-07-01 10:00:00.0
في الواقع، الطابع الزمني المحلي 2020-07-01 00:00:00 هو 2020-07-01T07:00:00Z في التوقيت العالمي المتفق عليه. يمكنك ملاحظة أنه إذا قمت بتمكين واجهة برمجة تطبيقات Java 8 وجمع مجموعة البيانات:
df.collect()
res27: Array[org.apache.spark.sql.Row] = Array([2020-07-01T07:00:00Z,2020-07-01])
يمكنك تحويل كائن java.time.Instant إلى أي طابع زمني محلي بشكل مستقل عن المنطقة الزمنية العمومية ل JVM. هذه إحدى مزايا أكثر java.sql.Timestampمن java.time.Instant . يتطلب الأول تغيير إعداد JVM العمومي، والذي يؤثر على الطوابع الزمنية الأخرى على نفس JVM. لذلك، إذا كانت تطبيقاتك تعالج التواريخ أو الطوابع الزمنية في مناطق زمنية مختلفة، ويجب ألا تتعارض التطبيقات مع بعضها البعض أثناء جمع البيانات إلى برنامج التشغيل باستخدام Java أو Scala Dataset.collect() API، نوصي بالتبديل إلى Java 8 API باستخدام تكوين spark.sql.datetime.java8API.enabledSQL .