تحويل البيانات باستخدام جداول Delta Live
توضح هذه المقالة كيفية استخدام Delta Live Tables للإعلان عن التحويلات على مجموعات البيانات وتحديد كيفية معالجة السجلات من خلال منطق الاستعلام. كما يحتوي على بعض الأمثلة على أنماط التحويل الشائعة التي يمكن أن تكون مفيدة عند إنشاء خطوط أنابيب Delta Live Tables.
يمكنك تعريف مجموعة بيانات مقابل أي استعلام يقوم بإرجاع DataFrame. يمكنك استخدام العمليات المضمنة في Apache Spark وUDFs والمنطق المخصص ونماذج MLflow كتحويلات في مسار Delta Live Tables. بمجرد استيعاب البيانات في مسار Delta Live Tables، يمكنك تحديد مجموعات بيانات جديدة مقابل المصادر الأولية لإنشاء جداول تدفق جديدة وطرق عرض مجسدة وطرق عرض.
لمعرفة كيفية إجراء معالجة ذات حالة فعالة باستخدام Delta Live Tables، راجع تحسين المعالجة ذات الحالة في Delta Live Tables باستخدام العلامات المائية.
متى تستخدم طرق العرض وطرق العرض المجسدة وجداول الدفق
لضمان كفاءة البنية الأساسية لبرنامج ربط العمليات التجارية الخاصة بك وصيانتها، اختر أفضل نوع مجموعة بيانات عند تنفيذ استعلامات البنية الأساسية لبرنامج ربط العمليات التجارية الخاصة بك.
ضع في اعتبارك استخدام طريقة عرض عندما:
- لديك استعلام كبير أو معقد تريد تقسيمه إلى استعلامات أسهل لإدارة.
- تريد التحقق من صحة النتائج الوسيطة باستخدام التوقعات.
- تريد تقليل تكاليف التخزين والحوسبة ولا تتطلب تجسيد نتائج الاستعلام. نظرا لتجسيد الجداول، فإنها تتطلب موارد حسابية وتخزينية إضافية.
ضع في اعتبارك استخدام طريقة عرض مجسدة عندما:
- تستهلك استعلامات انتقال البيانات من الخادم المتعددة الجدول. نظرا إلى أنه يتم حساب طرق العرض عند الطلب، تتم إعادة حساب طريقة العرض في كل مرة يتم فيها الاستعلام عن طريقة العرض.
- تستهلك المسارات أو المهام أو الاستعلامات الأخرى الجدول. نظرا لعدم تطابق طرق العرض، يمكنك استخدامها فقط في نفس المسار.
- تريد عرض نتائج استعلام أثناء التطوير. نظرا لتجسيد الجداول ويمكن عرضها والاستعلامات خارج المسار، يمكن أن يساعد استخدام الجداول أثناء التطوير في التحقق من صحة الحسابات. بعد التحقق من الصحة، قم بتحويل الاستعلامات التي لا تتطلب التجسيد إلى طرق عرض.
ضع في اعتبارك استخدام جدول دفق عندما:
- يتم تعريف استعلام مقابل مصدر بيانات ينمو بشكل مستمر أو متزايد.
- يجب حساب نتائج الاستعلام بشكل متزايد.
- مطلوب معدل نقل عال وزمن انتقال منخفض للبنية الأساسية لبرنامج ربط العمليات التجارية.
إشعار
يتم تعريف جداول الدفق دائما مقابل مصادر البث. يمكنك أيضا استخدام مصادر الدفق مع APPLY CHANGES INTO لتطبيق التحديثات من موجزات CDC. راجع واجهات برمجة تطبيقات APPLY CHANGES: تبسيط التقاط بيانات التغيير باستخدام Delta Live Tables.
الجمع بين جداول الدفق وطرق العرض المجسدة في مسار واحد
ترث جداول الدفق ضمانات المعالجة ل Apache Spark Structured Streaming ويتم تكوينها لمعالجة الاستعلامات من مصادر بيانات الإلحاق فقط، حيث يتم دائما إدراج صفوف جديدة في الجدول المصدر بدلا من تعديلها.
إشعار
على الرغم من أن جداول الدفق، بشكل افتراضي، تتطلب مصادر بيانات إلحاقية فقط، عندما يكون مصدر البث جدول دفق آخر يتطلب تحديثات أو حذفا، يمكنك تجاوز هذا السلوك باستخدام علامة skipChangeCommits.
يتضمن نمط البث الشائع استيعاب بيانات المصدر لإنشاء مجموعات البيانات الأولية في البنية الأساسية لبرنامج ربط العمليات التجارية. تسمى مجموعات البيانات الأولية هذه عادة الجداول البرونزية وغالبا ما تقوم بإجراء تحويلات بسيطة.
وعلى النقيض من ذلك، غالبا ما تتطلب الجداول النهائية في البنية الأساسية لبرنامج ربط العمليات التجارية، والتي يشار إليها عادة باسم الجداول الذهبية ، تجميعات معقدة أو قراءة من مصادر هي أهداف APPLY CHANGES INTO العملية. نظرا لأن هذه العمليات تنشئ التحديثات بطبيعتها بدلا من الإلحاقات، فهي غير مدعومة كمدخلات لجداول البث. هذه التحولات أكثر ملاءمة لطرق العرض المجسدة.
من خلال خلط جداول الدفق وطرق العرض المجسدة في مسار واحد، يمكنك تبسيط البنية الأساسية لبرنامج ربط العمليات التجارية الخاصة بك، وتجنب إعادة استيعاب البيانات الأولية أو إعادة معالجتها المكلفة، ولديك القوة الكاملة ل SQL لحساب التجميعات المعقدة عبر مجموعة بيانات مرمزة ومصفاة بكفاءة. يوضح المثال التالي هذا النوع من المعالجة المختلطة:
إشعار
تستخدم هذه الأمثلة "التحميل التلقائي" لتحميل الملفات من التخزين السحابي. لتحميل الملفات باستخدام أداة التحميل التلقائي في البنية الأساسية لبرنامج ربط العمليات التجارية الممكنة لكتالوج Unity، يجب استخدام مواقع خارجية. لمعرفة المزيد حول استخدام كتالوج Unity مع Delta Live Tables، راجع استخدام كتالوج Unity مع خطوط أنابيب Delta Live Tables.
Python
@dlt.table
def streaming_bronze():
return (
# Since this is a streaming source, this table is incremental.
spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "json")
.load("abfss://path/to/raw/data")
)
@dlt.table
def streaming_silver():
# Since we read the bronze table as a stream, this silver table is also
# updated incrementally.
return dlt.read_stream("streaming_bronze").where(...)
@dlt.table
def live_gold():
# This table will be recomputed completely by reading the whole silver table
# when it is updated.
return dlt.read("streaming_silver").groupBy("user_id").count()
SQL
CREATE OR REFRESH STREAMING TABLE streaming_bronze
AS SELECT * FROM cloud_files(
"abfss://path/to/raw/data", "json"
)
CREATE OR REFRESH STREAMING TABLE streaming_silver
AS SELECT * FROM STREAM(LIVE.streaming_bronze) WHERE...
CREATE OR REFRESH MATERIALIZED VIEW live_gold
AS SELECT count(*) FROM LIVE.streaming_silver GROUP BY user_id
تعرف على المزيد حول استخدام "المحمل التلقائي" لقراءة ملفات JSON بكفاءة من تخزين Azure للمعالجة المتزايدة.
الصلات الثابتة للبث
تعد الصلات الثابتة للبث خيارا جيدا عند نشر تكرار دفق مستمر من البيانات الملحقة فقط مع جدول أبعاد ثابت في المقام الأول.
مع كل تحديث للبنية الأساسية لبرنامج ربط العمليات التجارية، يتم ربط السجلات الجديدة من الدفق بأحدث لقطة للجدول الثابت. إذا تمت إضافة السجلات أو تحديثها في الجدول الثابت بعد معالجة البيانات المقابلة من جدول الدفق، فلن تتم إعادة حساب السجلات الناتجة ما لم يتم إجراء تحديث كامل.
في البنية الأساسية لبرنامج ربط العمليات التجارية التي تم تكوينها للتنفيذ الذي تم تشغيله، يقوم الجدول الثابت بإرجاع النتائج اعتبارا من وقت بدء التحديث. في البنية الأساسية لبرنامج ربط العمليات التجارية التي تم تكوينها للتنفيذ المستمر، في كل مرة يعالج فيها الجدول تحديثا، يتم الاستعلام عن أحدث إصدار من الجدول الثابت.
فيما يلي مثال على صلة ثابتة دفق:
Python
@dlt.table
def customer_sales():
return dlt.read_stream("sales").join(dlt.read("customers"), ["customer_id"], "left")
SQL
CREATE OR REFRESH STREAMING TABLE customer_sales
AS SELECT * FROM STREAM(LIVE.sales)
INNER JOIN LEFT LIVE.customers USING (customer_id)
حساب التجميعات بكفاءة
يمكنك استخدام جداول الدفق لحساب التجميعات التوزيعية البسيطة بشكل متزايد مثل العد أو الحد الأدنى أو الحد الأقصى أو المجموع، والمجاميع الجبرية مثل المتوسط أو الانحراف المعياري. توصي Databricks بالتجميع التزايدي للاستعلامات ذات عدد محدود من المجموعات، على سبيل المثال، استعلام مع عبارة GROUP BY country . تتم قراءة بيانات الإدخال الجديدة فقط مع كل تحديث.
لمعرفة المزيد حول كتابة استعلامات Delta Live Tables التي تقوم بإجراء تجميعات تزايدية، راجع تنفيذ التجميعات ذات النوافذ باستخدام العلامات المائية.
استخدام نماذج MLflow في مسار Delta Live Tables
إشعار
لاستخدام نماذج MLflow في مسار تمكين كتالوج Unity، يجب تكوين البنية الأساسية لبرنامج ربط العمليات التجارية لاستخدام القناة preview . لاستخدام القناة current ، يجب تكوين البنية الأساسية لبرنامج ربط العمليات التجارية للنشر إلى Hive metastore.
يمكنك استخدام النماذج المدربة على MLflow في خطوط أنابيب Delta Live Tables. يتم التعامل مع نماذج MLflow على أنها تحويلات في Azure Databricks، ما يعني أنها تعمل بناء على إدخال Spark DataFrame وإرجاع النتائج ك Spark DataFrame. نظرا لأن Delta Live Tables تحدد مجموعات البيانات مقابل DataFrames، يمكنك تحويل أحمال عمل Apache Spark التي تستفيد من MLflow إلى Delta Live Tables مع بضعة أسطر فقط من التعليمات البرمجية. لمزيد من الاطلاع على MLflow، راجع إدارة دورة حياة التعلم الآلي باستخدام MLflow.
إذا كان لديك بالفعل دفتر ملاحظات Python يستدعي نموذج MLflow، يمكنك تكييف هذه التعليمة البرمجية مع Delta Live Tables باستخدام @dlt.table مصمم الديكور وضمان تعريف الوظائف لإرجاع نتائج التحويل. لا تقوم Delta Live Tables بتثبيت MLflow بشكل افتراضي، لذا تأكد من استيرادك %pip install mlflow mlflow وفي dlt أعلى دفتر الملاحظات. للحصول على مقدمة حول بناء جملة Delta Live Tables، راجع تنفيذ مسار Delta Live Tables باستخدام Python.
لاستخدام نماذج MLflow في Delta Live Tables، أكمل الخطوات التالية:
- احصل على معرف التشغيل واسم النموذج لنموذج MLflow. يتم استخدام معرف التشغيل واسم النموذج لإنشاء URI لنموذج MLflow.
- استخدم URI لتعريف Spark UDF لتحميل نموذج MLflow.
- استدعاء UDF في تعريفات الجدول لاستخدام نموذج MLflow.
يوضح المثال التالي بناء الجملة الأساسي لهذا النمط:
%pip install mlflow
import dlt
import mlflow
run_id= "<mlflow-run-id>"
model_name = "<the-model-name-in-run>"
model_uri = f"runs:/{run_id}/{model_name}"
loaded_model_udf = mlflow.pyfunc.spark_udf(spark, model_uri=model_uri)
@dlt.table
def model_predictions():
return dlt.read(<input-data>)
.withColumn("prediction", loaded_model_udf(<model-features>))
كمثال كامل، تعرف التعليمات البرمجية التالية Spark UDF المسمى loaded_model_udf الذي يحمل نموذج MLflow المدرب على بيانات مخاطر القرض. يتم تمرير أعمدة البيانات المستخدمة لإجراء التنبؤ كوسيطة إلى UDF. يحسب الجدول loan_risk_predictions التنبؤات لكل صف في loan_risk_input_data.
%pip install mlflow
import dlt
import mlflow
from pyspark.sql.functions import struct
run_id = "mlflow_run_id"
model_name = "the_model_name_in_run"
model_uri = f"runs:/{run_id}/{model_name}"
loaded_model_udf = mlflow.pyfunc.spark_udf(spark, model_uri=model_uri)
categoricals = ["term", "home_ownership", "purpose",
"addr_state","verification_status","application_type"]
numerics = ["loan_amnt", "emp_length", "annual_inc", "dti", "delinq_2yrs",
"revol_util", "total_acc", "credit_length_in_years"]
features = categoricals + numerics
@dlt.table(
comment="GBT ML predictions of loan risk",
table_properties={
"quality": "gold"
}
)
def loan_risk_predictions():
return dlt.read("loan_risk_input_data")
.withColumn('predictions', loaded_model_udf(struct(features)))
الاحتفاظ بالحذف اليدوي أو التحديثات
تسمح لك Delta Live Tables بحذف السجلات أو تحديثها يدويا من جدول والقيام بعملية تحديث لإعادة حساب جداول انتقال البيانات من الخادم.
بشكل افتراضي، تعيد Delta Live Tables حساب نتائج الجدول استنادا إلى بيانات الإدخال في كل مرة يتم فيها تحديث البنية الأساسية لبرنامج ربط العمليات التجارية، لذلك يجب التأكد من عدم إعادة تحميل السجل المحذوف من بيانات المصدر. pipelines.reset.allowed يؤدي تعيين خاصية الجدول إلى false منع التحديث إلى جدول ولكن لا يمنع عمليات الكتابة التزايدية إلى الجداول أو يمنع تدفق البيانات الجديدة إلى الجدول.
يوضح الرسم التخطيطي التالي مثالا باستخدام جدولي دفق:
raw_user_tableاستيعاب بيانات المستخدم الخام من مصدر.bmi_tableيحسب بشكل متزايد درجات مؤشر كتلة الجسم باستخدام الوزن والارتفاع منraw_user_table.
تريد حذف سجلات المستخدمين أو تحديثها يدويا من raw_user_table وإعادة حساب bmi_table.
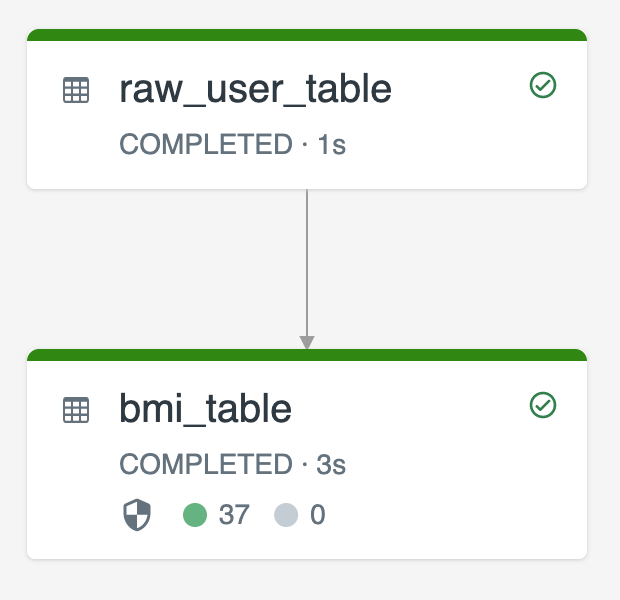
توضح التعليمات البرمجية التالية تعيين pipelines.reset.allowed خاصية الجدول لتعطيل false التحديث الكامل ل raw_user_table بحيث يتم الاحتفاظ بالتغييرات المقصودة بمرور الوقت، ولكن تتم إعادة حساب جداول انتقال البيانات من الخادم عند تشغيل تحديث البنية الأساسية لبرنامج ربط العمليات التجارية:
CREATE OR REFRESH STREAMING TABLE raw_user_table
TBLPROPERTIES(pipelines.reset.allowed = false)
AS SELECT * FROM cloud_files("/databricks-datasets/iot-stream/data-user", "csv");
CREATE OR REFRESH STREAMING TABLE bmi_table
AS SELECT userid, (weight/2.2) / pow(height*0.0254,2) AS bmi FROM STREAM(LIVE.raw_user_table);
الملاحظات
قريبًا: خلال عام 2024، سنتخلص تدريجيًا من GitHub Issues بوصفها آلية إرسال ملاحظات للمحتوى ونستبدلها بنظام ملاحظات جديد. لمزيد من المعلومات، راجع https://aka.ms/ContentUserFeedback.
إرسال الملاحظات وعرضها المتعلقة بـ