كيفية إنشاء فهرس بحث متجه والاستعلام عنه
توضح هذه المقالة كيفية إنشاء فهرس بحث متجه والاستعلام عنه باستخدام الفسيفساء الذكاء الاصطناعي Vector Search.
يمكنك إنشاء مكونات البحث عن المتجهات وإدارتها، مثل نقطة نهاية بحث المتجه ومؤشرات البحث عن المتجهات، باستخدام واجهة المستخدم أو Python SDK أو واجهة برمجة تطبيقات REST.
المتطلبات
- مساحة عمل ممكنة كتالوج Unity.
- تم تمكين الحوسبة بلا خادم. للحصول على الإرشادات، راجع الاتصال بالحوسبة بلا خادم.
- يجب تمكين تغيير موجز البيانات للجدول المصدر. للحصول على إرشادات، راجع استخدام موجز بيانات تغيير Delta Lake على Azure Databricks.
- لإنشاء فهرس، يجب أن يكون لديك امتيازات CREATE TABLE على مخطط (مخططات) الكتالوج لإنشاء فهارس. للاستعلام عن فهرس مملوك لمستخدم آخر، يجب أن يكون لديك امتيازات إضافية. راجع الاستعلام عن نقطة نهاية بحث متجه.
- إذا كنت ترغب في استخدام الرموز المميزة للوصول الشخصي (غير مستحسن لأحمال عمل الإنتاج)، فتحقق من تمكين رموز الوصول الشخصية المميزة. لاستخدام رمز مميز أساسي للخدمة بدلا من ذلك، قم بتمريره بشكل صريح باستخدام استدعاءات SDK أو API.
لاستخدام SDK، يجب تثبيته في دفتر الملاحظات. استخدم التعليمات البرمجية التالية:
%pip install databricks-vectorsearch
dbutils.library.restartPython()
from databricks.vector_search.client import VectorSearchClient
إنشاء نقطة نهاية بحث متجه
يمكنك إنشاء نقطة نهاية بحث متجه باستخدام واجهة مستخدم Databricks أو Python SDK أو واجهة برمجة التطبيقات.
إنشاء نقطة نهاية بحث متجه باستخدام واجهة المستخدم
اتبع هذه الخطوات لإنشاء نقطة نهاية بحث متجه باستخدام واجهة المستخدم.
في الشريط الجانبي الأيسر، انقر فوق حساب.
انقر فوق علامة التبويب بحث متجه وانقر فوق إنشاء.

يتم فتح نموذج Create endpoint. أدخل اسما لنقطة النهاية هذه.
انقر فوق تأكيد.
إنشاء نقطة نهاية بحث متجه باستخدام Python SDK
يستخدم المثال التالي الدالة create_endpoint() SDK لإنشاء نقطة نهاية بحث متجه.
# The following line automatically generates a PAT Token for authentication
client = VectorSearchClient()
# The following line uses the service principal token for authentication
# client = VectorSearch(service_principal_client_id=<CLIENT_ID>,service_principal_client_secret=<CLIENT_SECRET>)
client.create_endpoint(
name="vector_search_endpoint_name",
endpoint_type="STANDARD"
)
إنشاء نقطة نهاية بحث متجه باستخدام واجهة برمجة تطبيقات REST
راجع POST /api/2.0/vector-search/endpoints.
(اختياري) إنشاء نقطة نهاية وتكوينها لخدمة نموذج التضمين
إذا اخترت أن تقوم Databricks بحساب عمليات التضمين، يمكنك استخدام نقطة نهاية واجهات برمجة تطبيقات نموذج الأساس المكونة مسبقا أو إنشاء نقطة نهاية خدمة نموذج لخدمة نموذج التضمين الذي تختاره. راجع واجهات برمجة تطبيقات نموذج أساس الدفع لكل رمز مميز أو إنشاء نموذج الذكاء الاصطناعي إنشاء يخدم نقاط النهاية للحصول على الإرشادات . على سبيل المثال دفاتر الملاحظات، راجع أمثلة دفتر الملاحظات لاستدعاء نموذج تضمينات.
عند تكوين نقطة نهاية تضمين، توصي Databricks بإزالة التحديد الافتراضي للمقياس إلى الصفر. قد يستغرق عرض نقاط النهاية بضع دقائق للتهيئة، وقد تنتهي مهلة الاستعلام الأولي على فهرس بنقطة نهاية متدرجة.
إشعار
قد تنتهي مهلة تهيئة فهرس البحث المتجه إذا لم يتم تكوين نقطة نهاية التضمين بشكل مناسب لمجموعة البيانات. يجب عليك استخدام نقاط نهاية وحدة المعالجة المركزية فقط لمجموعات البيانات الصغيرة والاختبارات. بالنسبة لمجموعات البيانات الأكبر حجما، استخدم نقطة نهاية GPU للحصول على الأداء الأمثل.
إنشاء فهرس بحث متجه
يمكنك إنشاء فهرس بحث متجه باستخدام واجهة المستخدم أو Python SDK أو REST API. واجهة المستخدم هي أبسط نهج.
هناك نوعان من الفهارس:
- تتم مزامنة Delta Sync Index تلقائيا مع جدول Delta المصدر، ويتم تحديث الفهرس تلقائيا وتدريجيا مع تغير البيانات الأساسية في Delta Table.
- يدعم Direct Vector Access Index القراءة والكتابة المباشرة للخطوط المتجهة وبيانات التعريف. المستخدم مسؤول عن تحديث هذا الجدول باستخدام واجهة برمجة تطبيقات REST أو Python SDK. لا يمكن إنشاء هذا النوع من الفهرس باستخدام واجهة المستخدم. يجب استخدام واجهة برمجة تطبيقات REST أو SDK.
إنشاء فهرس باستخدام واجهة المستخدم
في الشريط الجانبي الأيسر، انقر فوق كتالوج لفتح واجهة مستخدم مستكشف الكتالوج.
انتقل إلى جدول Delta الذي تريد استخدامه.
انقر فوق الزر Create في الزاوية العلوية اليسرى، وحدد Vector search index من القائمة المنسدلة.
استخدم المحددات في مربع الحوار لتكوين الفهرس.
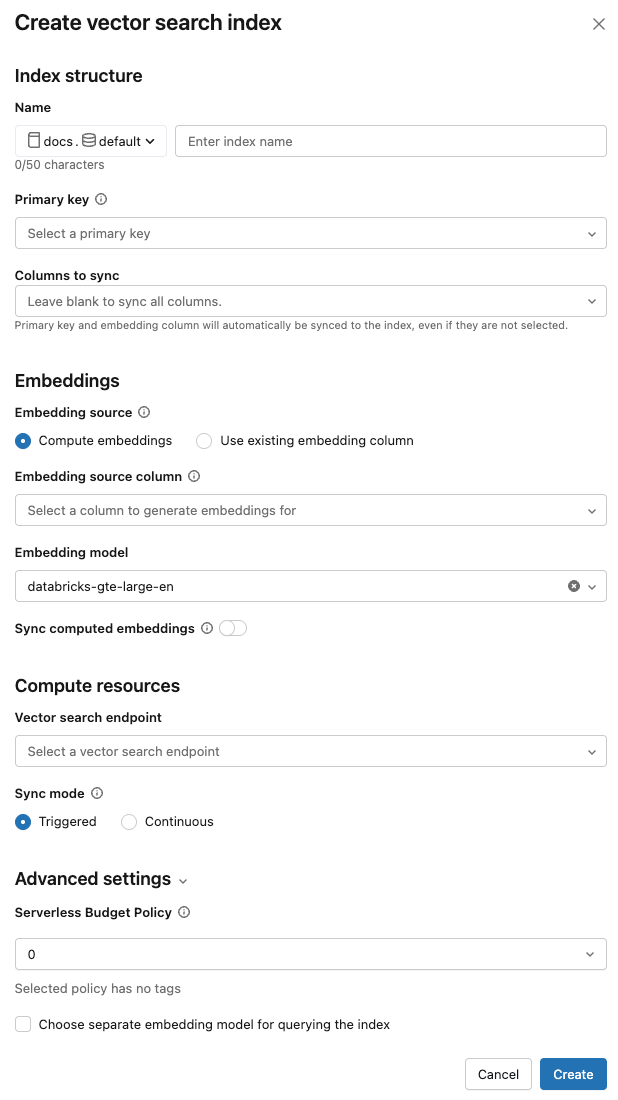
الاسم: الاسم المراد استخدامه للجدول عبر الإنترنت في كتالوج Unity. يتطلب الاسم مساحة اسم من ثلاثة مستويات،
<catalog>.<schema>.<name>. يسمح فقط بالأحرف الأبجدية الرقمية والتسطير السفلي.المفتاح الأساسي: عمود لاستخدامه كمفتاح أساسي.
نقطة النهاية: حدد نقطة نهاية بحث المتجه التي تريد استخدامها.
الأعمدة المراد مزامنتها: حدد الأعمدة التي تريد مزامنتها مع فهرس المتجهات. إذا تركت هذا الحقل فارغا، فستتم مزامنة كافة الأعمدة من الجدول المصدر مع الفهرس. تتم دائما مزامنة عمود المفتاح الأساسي وتضمين عمود المصدر أو تضمين عمود متجه.
مصدر التضمين: حدد ما إذا كنت تريد أن يحسب Databricks عمليات التضمين لعمود نص في جدول Delta (عمليات تضمين الحساب)، أو إذا كان جدول Delta يحتوي على تضمينات تم حسابها مسبقا (استخدم عمود التضمين الموجود).
- إذا حددت Compute embeddings، فحدد العمود الذي تريد تضمينه محسوبا له ونقطة النهاية التي تخدم نموذج التضمين. يتم اعتماد أعمدة النص فقط.
- إذا حددت استخدام عمود التضمين الموجود، فحدد العمود الذي يحتوي على التضمينات المحوسبة مسبقا وبعد التضمين. يجب أن يكون
array[float]تنسيق عمود التضمين المحسوب مسبقا .
مزامنة عمليات التضمين المحسوبة: قم بتبديل هذا الإعداد لحفظ عمليات التضمين التي تم إنشاؤها في جدول كتالوج Unity. لمزيد من المعلومات، راجع حفظ جدول التضمين الذي تم إنشاؤه.
وضع المزامنة: يحافظ Continuous على مزامنة الفهرس مع ثوان من زمن الانتقال. ومع ذلك، فإنه يحتوي على تكلفة أعلى مرتبطة به منذ توفير نظام مجموعة حساب لتشغيل تدفق المزامنة المستمرة. المشغل أكثر فعالية من حيث التكلفة، ولكن يجب البدء يدويا باستخدام واجهة برمجة التطبيقات. بالنسبة لكل من Continuous و Triggered، يكون التحديث تزايديا - فقط البيانات التي تغيرت منذ معالجة المزامنة الأخيرة.
عند الانتهاء من تكوين الفهرس، انقر فوق إنشاء.
إنشاء فهرس باستخدام Python SDK
ينشئ المثال التالي فهرس مزامنة دلتا مع تضمينات محسوبة بواسطة Databricks.
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name="vector_search_demo_endpoint",
source_table_name="vector_search_demo.vector_search.en_wiki",
index_name="vector_search_demo.vector_search.en_wiki_index",
pipeline_type="TRIGGERED",
primary_key="id",
embedding_source_column="text",
embedding_model_endpoint_name="e5-small-v2"
)
ينشئ المثال التالي فهرس مزامنة دلتا مع تضمينات مدارة ذاتيا. يوضح هذا المثال أيضا استخدام المعلمة columns_to_sync الاختيارية لتحديد مجموعة فرعية فقط من الأعمدة لاستخدامها في الفهرس.
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name="vector_search_demo_endpoint",
source_table_name="vector_search_demo.vector_search.en_wiki",
index_name="vector_search_demo.vector_search.en_wiki_index",
pipeline_type="TRIGGERED",
primary_key="id",
embedding_dimension=1024,
embedding_vector_column="text_vector"
)
بشكل افتراضي، تتم مزامنة جميع الأعمدة من الجدول المصدر مع الفهرس. لمزامنة مجموعة فرعية فقط من الأعمدة، استخدم columns_to_sync. يتم تضمين المفتاح الأساسي وأعمدة التضمين دائما في الفهرس.
لمزامنة المفتاح الأساسي وعمود التضمين فقط ، يجب تحديدهما كما columns_to_sync هو موضح:
index = client.create_delta_sync_index(
...
columns_to_sync=["id", "text_vector"] # to sync only the primary key and the embedding column
)
لمزامنة أعمدة إضافية، حددها كما هو موضح. لا تحتاج إلى تضمين المفتاح الأساسي وعمود التضمين، حيث تتم مزامنتهما دائما.
index = client.create_delta_sync_index(
...
columns_to_sync=["revisionId", "text"] # to sync the `revisionId` and `text` columns in addition to the primary key and embedding column.
)
ينشئ المثال التالي فهرس وصول متجه مباشر.
client = VectorSearchClient()
index = client.create_direct_access_index(
endpoint_name="storage_endpoint",
index_name="{catalog_name}.{schema_name}.{index_name}",
primary_key="id",
embedding_dimension=1024,
embedding_vector_column="text_vector",
schema={
"id": "int",
"field2": "str",
"field3": "float",
"text_vector": "array<float>"}
)
إنشاء فهرس باستخدام واجهة برمجة تطبيقات REST
راجع POST /api/2.0/vector-search/indexes.
حفظ جدول التضمين الذي تم إنشاؤه
إذا قام Databricks بإنشاء عمليات التضمين، يمكنك حفظ عمليات التضمين التي تم إنشاؤها إلى جدول في كتالوج Unity. يتم إنشاء هذا الجدول في نفس المخطط مثل فهرس المتجه ويتم ربطه من صفحة فهرس المتجه.
اسم الجدول هو اسم فهرس البحث المتجه، الملحق ب _writeback_table. الاسم غير قابل للتحرير.
يمكنك الوصول إلى الجدول والاستعلام عليه مثل أي جدول آخر في كتالوج Unity. ومع ذلك، يجب عدم إسقاط الجدول أو تعديله، لأنه غير مخصص ليتم تحديثه يدويا. يتم حذف الجدول تلقائيا إذا تم حذف الفهرس.
تحديث فهرس بحث متجه
تحديث فهرس مزامنة دلتا
يتم تحديث الفهارس التي تم إنشاؤها باستخدام وضع المزامنة المستمرة تلقائيا عند تغيير جدول Delta المصدر. إذا كنت تستخدم وضع المزامنة المشغلة ، يمكنك استخدام Python SDK أو REST API لبدء المزامنة.
Python SDK
index.sync()
واجهة برمجة تطبيقات REST
راجع واجهة برمجة تطبيقات REST (POST /api/2.0/vector-search/indexes/{index_name}/sync).
تحديث فهرس الوصول المتجه المباشر
يمكنك استخدام Python SDK أو REST API لإدراج البيانات أو تحديثها أو حذفها من فهرس الوصول المتجه المباشر.
Python SDK
index.upsert([{"id": 1,
"field2": "value2",
"field3": 3.0,
"text_vector": [1.0, 2.0, 3.0]
},
{"id": 2,
"field2": "value2",
"field3": 3.0,
"text_vector": [1.1, 2.1, 3.0]
}
])
واجهة برمجة تطبيقات REST
راجع واجهة برمجة تطبيقات REST (POST /api/2.0/vector-search/indexes).
الاستعلام عن نقطة نهاية بحث متجه
يمكنك الاستعلام فقط عن نقطة نهاية البحث المتجه باستخدام Python SDK أو REST API أو وظيفة الذكاء الاصطناعي SQL vector_search() .
إشعار
إذا لم يكن المستخدم الذي يقوم بالاستعلام عن نقطة النهاية هو مالك فهرس البحث المتجه، فيجب أن يكون لدى المستخدم امتيازات UC التالية:
- استخدم CATALOG على الكتالوج الذي يحتوي على فهرس البحث المتجه.
- استخدم SCHEMA على المخطط الذي يحتوي على فهرس البحث عن المتجهات.
- حدد فهرس البحث المتجه.
لإجراء بحث تشابه الكلمات الأساسية المختلط، قم بتعيين المعلمة query_type إلى hybrid. القيمة الافتراضية هي ann (أقرب جار تقريبي).
Python SDK
# Delta Sync Index with embeddings computed by Databricks
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
num_results=2
)
# Delta Sync Index using hybrid search, with embeddings computed by Databricks
results3 = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
num_results=2,
query_type="hybrid"
)
# Delta Sync Index with pre-calculated embeddings
results2 = index.similarity_search(
query_vector=[0.2, 0.33, 0.19, 0.52],
columns=["id", "text"],
num_results=2
)
واجهة برمجة تطبيقات REST
راجع POST /api/2.0/vector-search/indexes/{index_name}/query.
SQL
لاستخدام هذه الدالة الذكاء الاصطناعي، راجع الدالة vector_search.
استخدام عوامل التصفية على الاستعلامات
يمكن للاستعلام تعريف عوامل التصفية استنادا إلى أي عمود في جدول Delta. similarity_search إرجاع الصفوف التي تطابق عوامل التصفية المحددة فقط. عوامل التصفية التالية مدعومة:
| عامل تصفية | سلوك | الأمثلة |
|---|---|---|
NOT |
ينفي عامل التصفية. يجب أن ينتهي المفتاح ب "NOT". على سبيل المثال، يتطابق "color NOT" مع القيمة "red" مع المستندات التي يكون اللون فيها غير أحمر. | {"id NOT": 2} {“color NOT”: “red”} |
< |
التحقق مما إذا كانت قيمة الحقل أقل من قيمة عامل التصفية. يجب أن ينتهي المفتاح ب " <". على سبيل المثال، يتطابق "price <" مع القيمة 200 مع المستندات حيث يكون السعر أقل من 200. | {"id <": 200} |
<= |
التحقق مما إذا كانت قيمة الحقل أقل من قيمة عامل التصفية أو مساوية لها. يجب أن ينتهي المفتاح ب " <=". على سبيل المثال، يتطابق "price <=" مع القيمة 200 مع المستندات حيث يكون السعر أقل من أو يساوي 200. | {"id <=": 200} |
> |
التحقق مما إذا كانت قيمة الحقل أكبر من قيمة عامل التصفية. يجب أن ينتهي المفتاح ب " >". على سبيل المثال، يتطابق "price >" مع القيمة 200 مع المستندات حيث يكون السعر أكبر من 200. | {"id >": 200} |
>= |
التحقق مما إذا كانت قيمة الحقل أكبر من قيمة عامل التصفية أو مساوية لها. يجب أن ينتهي المفتاح ب " >=". على سبيل المثال، يتطابق "price >=" مع القيمة 200 مع المستندات حيث يكون السعر أكبر من أو يساوي 200. | {"id >=": 200} |
OR |
التحقق مما إذا كانت قيمة الحقل تطابق أي من قيم عامل التصفية. يجب أن يحتوي OR المفتاح على لفصل مفاتيح فرعية متعددة. على سبيل المثال، color1 OR color2 مع القيمة ["red", "blue"] تطابق المستندات حيث إما color1 هي red أو color2 هي blue. |
{"color1 OR color2": ["red", "blue"]} |
LIKE |
يطابق السلاسل الجزئية. | {"column LIKE": "hello"} |
| لم يتم تحديد عامل تصفية | يتحقق عامل التصفية من وجود تطابق تام. إذا تم تحديد قيم متعددة، فإنه يطابق أي من القيم. | {"id": 200} {"id": [200, 300]} |
راجع أمثلة التعليمات البرمجية التالية:
Python SDK
# Match rows where `title` exactly matches `Athena` or `Ares`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters={"title": ["Ares", "Athena"]},
num_results=2
)
# Match rows where `title` or `id` exactly matches `Athena` or `Ares`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters={"title OR id": ["Ares", "Athena"]},
num_results=2
)
# Match only rows where `title` is not `Hercules`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters={"title NOT": "Hercules"},
num_results=2
)
واجهة برمجة تطبيقات REST
راجع POST /api/2.0/vector-search/indexes/{index_name}/query.
أمثلة على دفاتر الملاحظات
توضح الأمثلة في هذا القسم استخدام SDK للبحث المتجه Python.
أمثلة على LangChain
راجع كيفية استخدام LangChain مع الفسيفساء الذكاء الاصطناعي Vector Search لاستخدام البحث عن متجهات الذكاء الاصطناعي الفسيفساء كما هو الحال في التكامل مع حزم LangChain.
يوضح دفتر الملاحظات التالي كيفية تحويل نتائج البحث عن التشابه إلى مستندات LangChain.
البحث عن المتجهات باستخدام دفتر ملاحظات Python SDK
أمثلة دفتر الملاحظات لاستدعاء نموذج تضمينات
توضح دفاتر الملاحظات التالية كيفية تكوين نقطة نهاية خدمة نموذج الفسيفساء الذكاء الاصطناعي لإنشاء التضمينات.