ملاحظة
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
يتضمن إطار عمل العامل مجموعة من الأدوات على Databricks المصممة لمساعدة المطورين على بناء وتوزيع وتقييم عوامل الذكاء الاصطناعي عالية الجودة للإنتاج مثل تطبيقات Retrieval Augmented Generation (RAG).
تتناول هذه المقالة ما هي RAG وفوائد تطوير تطبيقات RAG على Azure Databricks.
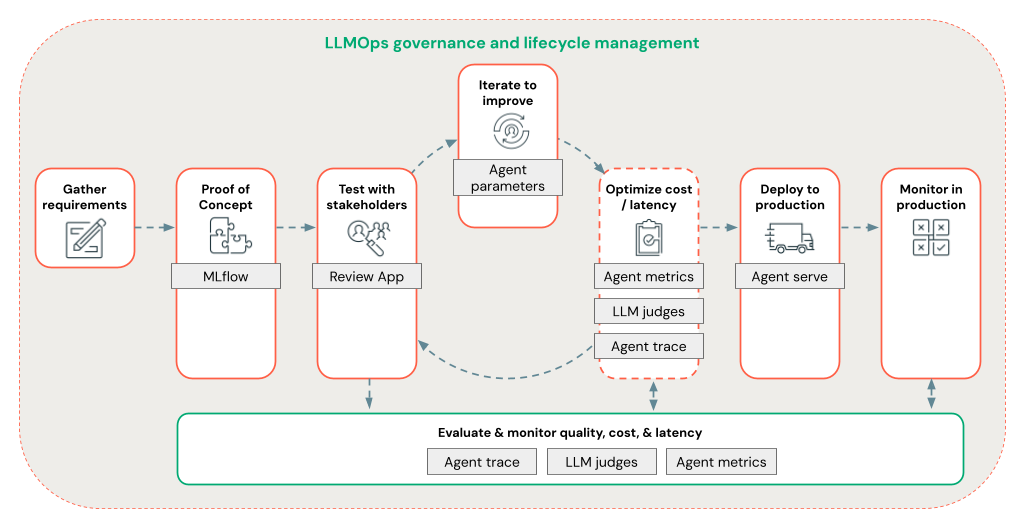
يسمح إطار عمل العامل للمطورين بالتكرار بسرعة على جميع جوانب تطوير RAG باستخدام سير عمل LLMOps من طرف إلى طرف.
المتطلبات
- يجب تمكين الميزات المساعدة الذكاء الاصطناعي المدعومة من Azure الذكاء الاصطناعي لمساحة العمل الخاصة بك.
- يجب أن تكون جميع مكونات تطبيق عامل في مساحة عمل واحدة. على سبيل المثال، في حالة تطبيق RAG، يجب أن يكون نموذج الخدمة ومثيل البحث المتجه في نفس مساحة العمل.
ما هو RAG؟
RAG هي تقنية تصميم الذكاء الاصطناعي توليدية تعزز نماذج اللغة الكبيرة (LLM) مع المعرفة الخارجية. تعمل هذه التقنية على تحسين LLMs بالطرق التالية:
- المعرفة الخاصة: يمكن أن تتضمن RAG معلومات خاصة لم يتم استخدامها في البداية لتدريب LLM، مثل المذكرات ورسائل البريد الإلكتروني والمستندات للإجابة على الأسئلة الخاصة بالمجال.
- معلومات محدثة: يمكن لتطبيق RAG تزويد LLM بمعلومات من مصادر البيانات المحدثة.
- نقل المصادر: تمكن RAG LLMs من اقتباس مصادر محددة، مما يسمح للمستخدمين بالتحقق من الدقة الواقعية للردود.
- قوائم أمان البيانات والتحكم في الوصول (ACL): يمكن تصميم خطوة الاسترداد لاسترداد المعلومات الشخصية أو الخاصة بشكل انتقائي استنادا إلى بيانات اعتماد المستخدم.
أنظمة الذكاء الاصطناعي المركبة
تطبيق RAG هو مثال على نظام الذكاء الاصطناعي مركب: فهو يتوسع في قدرات اللغة ل LLM من خلال الجمع بينه والأدوات والإجراءات الأخرى.
في أبسط شكل، يقوم تطبيق RAG بتنفيذ ما يلي:
- الاسترداد: يتم استخدام طلب المستخدم للاستعلام عن مخزن بيانات خارجي، مثل مخزن متجهات أو بحث عن كلمة أساسية نصية أو قاعدة بيانات SQL. الهدف هو الحصول على بيانات داعمة لاستجابة LLM.
- الزيادة: يتم دمج البيانات المستردة مع طلب المستخدم، وغالبا ما تستخدم قالب بتنسيق وإرشادات إضافية، لإنشاء مطالبة.
- Generation: يتم تمرير المطالبة إلى LLM، والذي يقوم بعد ذلك بإنشاء استجابة للاستعلام.
بيانات RAG غير منظمة البنية مقابل بيانات RAG المنظمة
يمكن أن تعمل بنية RAG مع البيانات الداعمة غير المنظمة أو المنظمة. تعتمد البيانات التي تستخدمها مع RAG على حالة الاستخدام الخاصة بك.
بيانات غير منظمة: بيانات بدون بنية أو مؤسسة محددة. المستندات التي تتضمن نصا وصورا أو محتوى وسائط متعددة مثل الصوت أو مقاطع الفيديو.
- ملفات PDF
- مستندات Google/Office
- Wikis
- الصور
- ملفات الفيديو
البيانات المنظمة: البيانات الجدولية المرتبة في صفوف وأعمدة ذات مخطط معين، مثل الجداول في قاعدة بيانات.
- سجلات العملاء في نظام BI أو Data Warehouse
- بيانات المعاملة من قاعدة بيانات SQL
- البيانات من واجهات برمجة التطبيقات للتطبيق (مثل SAP وSalesforce وما إلى ذلك)
تصف الأقسام التالية تطبيق RAG للبيانات غير المنظمة.
مسار بيانات RAG
يقوم مسار بيانات RAG بمعالجة المستندات مسبقا وفهرستها للاسترداد السريع والدقيق.
يوضح الرسم التخطيطي أدناه نموذج مسار بيانات لمجموعة بيانات غير منظمة باستخدام خوارزمية بحث دلالية. تنسق وظائف Databricks كل خطوة.
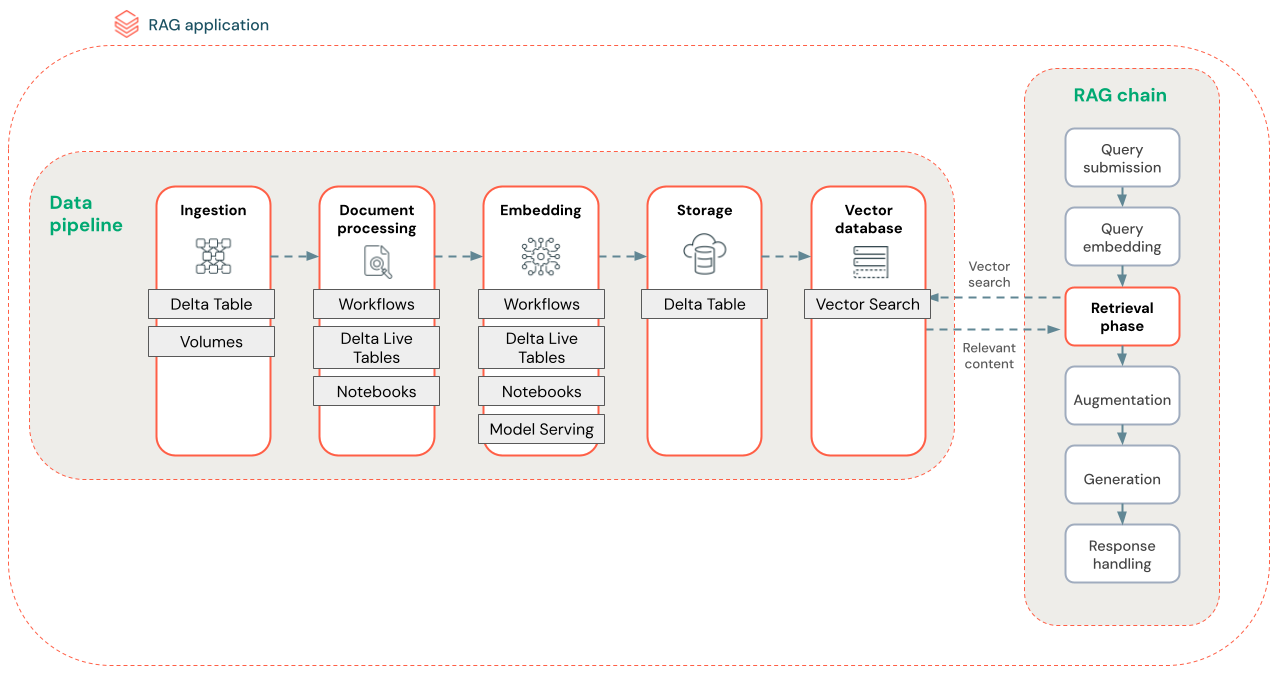
- استيعاب البيانات - استيعاب البيانات من مصدر الملكية الخاص بك. قم بتخزين هذه البيانات في جدول Delta أو وحدة تخزين كتالوج Unity.
- معالجة المستندات: يمكنك تنفيذ هذه المهام باستخدام وظائف Databricks ودفاتر ملاحظات Databricks وجداول Delta Live.
- توزيع المستندات الأولية: تحويل البيانات الأولية إلى تنسيق قابل للاستخدام. على سبيل المثال، استخراج النص والجداول والصور من مجموعة من ملفات PDF أو استخدام تقنيات التعرف البصري على الأحرف لاستخراج النص من الصور.
- استخراج بيانات التعريف: استخراج بيانات تعريف المستند مثل عناوين المستندات وأرقام الصفحات وعناوين URL للمساعدة في استعلام خطوة الاسترداد بشكل أكثر دقة.
- مستندات المجموعة: تقسيم البيانات إلى مجموعات تتناسب مع نافذة سياق LLM. يؤدي استرداد هذه المجموعات المركز عليها، بدلا من المستندات بأكملها، إلى منح LLM محتوى أكثر استهدافا لإنشاء استجابات.
- تضمين المجموعات - يستهلك نموذج التضمين المجموعات لإنشاء تمثيلات رقمية للمعلومات التي تسمى تضمينات المتجهات. تمثل المتجهات المعنى الدلالي للنص، وليس فقط الكلمات الأساسية على مستوى السطح. في هذا السيناريو، يمكنك حساب التضمينات واستخدام خدمة النموذج لخدمة نموذج التضمين.
- تخزين التضمين - قم بتخزين تضمينات المتجه ونص المجموعة في جدول Delta تمت مزامنته مع Vector Search.
- قاعدة بيانات المتجهات - كجزء من "البحث عن المتجهات"، تتم فهرسة عمليات التضمين وبيانات التعريف وتخزينها في قاعدة بيانات متجهة للاستعلام بسهولة من قبل عامل RAG. عندما يقوم مستخدم بإجراء استعلام، يتم تضمين طلبه في متجه. ثم تستخدم قاعدة البيانات فهرس المتجه للعثور على المجموعات الأكثر مشابهة وإرجاعها.
تتضمن كل خطوة قرارات هندسية تؤثر على جودة تطبيق RAG. على سبيل المثال، يضمن اختيار حجم المجموعة الصحيح في الخطوة (3) تلقي LLM معلومات محددة ولكنها سياقية، بينما تحديد نموذج تضمين مناسب في الخطوة (4) يحدد دقة المجموعات التي تم إرجاعها أثناء الاسترداد.
Databricks Vector Search
غالبا ما يكون تشابه الحوسبة مكلفا حسابيا، ولكن فهارس المتجهات مثل Databricks Vector Search تحسن هذا من خلال تنظيم التضمينات بكفاءة. تقوم عمليات البحث المتجهة بترتيب النتائج الأكثر صلة بسرعة دون مقارنة كل تضمين باستعلام المستخدم بشكل فردي.
يقوم Vector Search تلقائيا بمزامنة عمليات التضمين الجديدة المضافة إلى جدول Delta وتحديث فهرس Vector Search.
ما هو وكيل RAG؟
يعد عامل Retrieval Augmented Generation (RAG) جزءا أساسيا من تطبيق RAG الذي يعزز قدرات نماذج اللغات الكبيرة (LLMs) من خلال دمج استرداد البيانات الخارجية. يعالج عامل RAG استعلامات المستخدم، ويسترد البيانات ذات الصلة من قاعدة بيانات متجهة، ويمرر هذه البيانات إلى LLM لإنشاء استجابة.
ترتبط أدوات مثل LangChain أو Pyfunc بهذه الخطوات عن طريق توصيل مدخلاتها ومخرجاتها.
يوضح الرسم التخطيطي أدناه عامل RAG لروبوت الدردشة وميزات Databricks المستخدمة لإنشاء كل عامل.
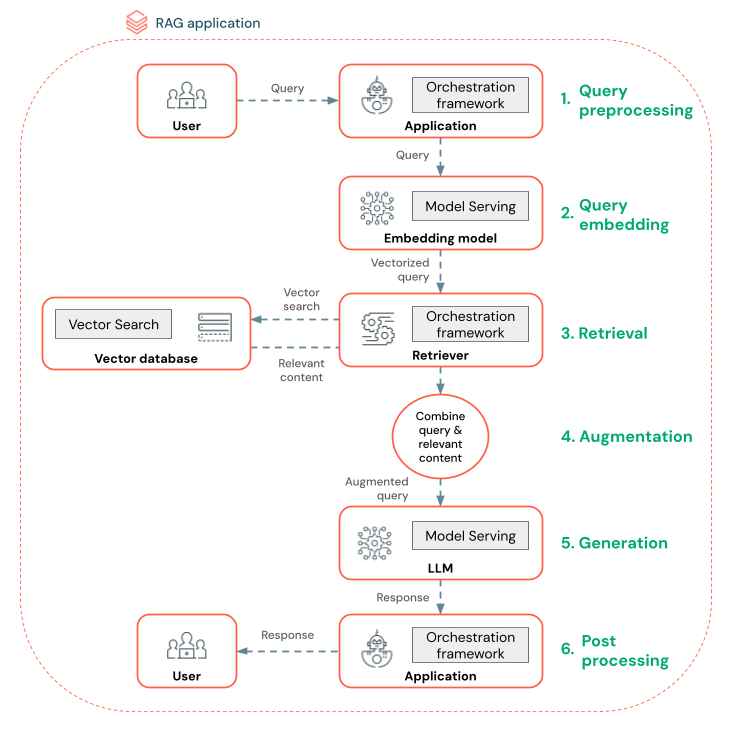
- المعالجة المسبقة للاستعلام - يرسل المستخدم استعلاما، ثم تتم معالجته مسبقا لجعله مناسبا للاستعلام عن قاعدة بيانات المتجهات. قد يتضمن ذلك وضع الطلب في قالب أو استخراج الكلمات الأساسية.
- تحويل الاستعلام - استخدم Model Serving لتضمين الطلب باستخدام نفس نموذج التضمين المستخدم لتضمين المجموعات في مسار البيانات. تتيح هذه التضمينات مقارنة التشابه الدلالي بين الطلب والأجزاء المعالجة مسبقا.
- مرحلة الاسترداد - يأخذ المسترد، وهو تطبيق مسؤول عن جلب المعلومات ذات الصلة، الاستعلام المتجه وينفذ بحث تشابه متجه باستخدام Vector Search. يتم تصنيف مجموعات البيانات الأكثر صلة واستردادها استنادا إلى تشابهها مع الاستعلام.
- زيادة المطالبة - يجمع المسترد بين مجموعات البيانات المستردة والاستعلام الأصلي لتوفير سياق إضافي ل LLM. يتم تنظيم المطالبة بعناية للتأكد من أن LLM يفهم سياق الاستعلام. غالبا ما يكون لدى LLM قالب لتنسيق الاستجابة. تعرف عملية ضبط المطالبة هذه باسم هندسة المطالبة.
- مرحلة إنشاء LLM - ينشئ LLM استجابة باستخدام الاستعلام المعزز الذي تم إثرائه من خلال نتائج الاسترداد. يمكن أن يكون LLM نموذجا مخصصا أو نموذجا تأسيسيا.
- ما بعد المعالجة - قد تتم معالجة استجابة LLM لتطبيق منطق عمل إضافي أو إضافة اقتباسات أو تحسين النص الذي تم إنشاؤه استنادا إلى قواعد أو قيود محددة مسبقا
يمكن تطبيق معايير حماية مختلفة خلال هذه العملية لضمان الامتثال لسياسات المؤسسة. قد يتضمن ذلك تصفية الطلبات المناسبة، والتحقق من أذونات المستخدم قبل الوصول إلى مصادر البيانات، واستخدام تقنيات con وضع الخيمة ration على الاستجابات التي تم إنشاؤها.
تطوير عامل RAG على مستوى الإنتاج
التكرار بسرعة على تطوير العامل باستخدام الميزات التالية:
إنشاء وتسجيل العوامل باستخدام أي مكتبة وMLflow. قم بوضع معلمات لوكلاءك للتجربة والتكرار على تطوير العامل بسرعة.
انشر العوامل في الإنتاج مع الدعم الأصلي لتدفق الرمز المميز وتسجيل الطلب/الاستجابة، بالإضافة إلى تطبيق مراجعة مضمن للحصول على ملاحظات المستخدم لوكيلك.
يتيح لك تتبع العامل تسجيل التتبعات وتحليلها ومقارنتها عبر التعليمات البرمجية للعامل لتصحيح وفهم كيفية استجابة وكيلك للطلبات.
التقييم والمراقبة
يساعد التقييم والمراقبة في تحديد ما إذا كان تطبيق RAG يلبي متطلبات الجودة والتكلفة وزمن الانتقال. يحدث التقييم أثناء التطوير، بينما تحدث المراقبة بمجرد نشر التطبيق في الإنتاج.
تحتوي RAG على البيانات غير المنظمة على العديد من المكونات التي تؤثر على الجودة. على سبيل المثال، يمكن أن تؤثر تغييرات تنسيق البيانات على المجموعات المستردة وقدرة LLM على إنشاء استجابات ذات صلة. لذلك، من المهم تقييم المكونات الفردية بالإضافة إلى التطبيق الكلي.
لمزيد من المعلومات، راجع ما هو الفسيفساء الذكاء الاصطناعي تقييم العامل؟.
توافر المناطق
للحصول على التوفر الإقليمي لإطار عمل العامل، راجع الميزات ذات التوفر الإقليمي المحدود