واجهات برمجة تطبيقات نموذج مؤسسة معدل النقل المتوفرة
توضح هذه المقالة كيفية نشر النماذج باستخدام واجهات برمجة تطبيقات نموذج الأساس مع معدل النقل المقدم. توصي Databricks بتوفير معدل النقل لأحمال عمل الإنتاج، وتوفر استدلال محسن لنماذج الأساس مع ضمانات الأداء.
راجع واجهات برمجة تطبيقات نموذج أساس معدل النقل المقدمة للحصول على قائمة ببنى النموذج المدعومة.
المتطلبات
راجع المتطلبات. لنشر نماذج الأساس الدقيقة، راجع نشر نماذج الأساس الدقيقة.
[مستحسن] نشر نماذج الأساس من كتالوج Unity
توصي Databricks باستخدام نماذج الأساس المثبتة مسبقا في كتالوج Unity. يمكنك العثور على هذه النماذج ضمن الكتالوج system في المخطط ai (system.ai).
لنشر نموذج أساسي:
- انتقل إلى
system.aiفي مستكشف الكتالوج. - انقر فوق اسم النموذج المراد نشره.
- في صفحة النموذج، انقر فوق الزر تقديم هذا النموذج .
- تظهر صفحة Create serving endpoint. راجع إنشاء نقطة نهاية معدل النقل المتوفرة باستخدام واجهة المستخدم.
نشر نماذج الأساس من Databricks Marketplace
بدلا من ذلك، يمكنك تثبيت نماذج الأساس إلى كتالوج Unity من Databricks Marketplace.
يمكنك البحث عن عائلة نموذج ومن صفحة النموذج، يمكنك تحديد الحصول على الوصول وتوفير بيانات اعتماد تسجيل الدخول لتثبيت النموذج إلى كتالوج Unity.
بعد تثبيت النموذج على كتالوج Unity، يمكنك إنشاء نقطة نهاية خدمة نموذج باستخدام واجهة مستخدم الخدمة.
توزيع نماذج DBRX
توصي Databricks بخدمة نموذج تعليمات DBRX لأحمال العمل الخاصة بك. لخدمة نموذج DBRX Instruct باستخدام معدل النقل المقدم، اتبع الإرشادات الواردة في [Recommended] Deploy foundation models from Unity Catalog.
عند تقديم نماذج DBRX هذه، يدعم معدل النقل المقدم طول سياق يصل إلى 16 ألف.
تستخدم نماذج DBRX مطالبة النظام الافتراضية التالية لضمان الصلة والدقة في استجابات النموذج:
You are DBRX, created by Databricks. You were last updated in December 2023. You answer questions based on information available up to that point.
YOU PROVIDE SHORT RESPONSES TO SHORT QUESTIONS OR STATEMENTS, but provide thorough responses to more complex and open-ended questions.
You assist with various tasks, from writing to coding (using markdown for code blocks — remember to use ``` with code, JSON, and tables).
(You do not have real-time data access or code execution capabilities. You avoid stereotyping and provide balanced perspectives on controversial topics. You do not provide song lyrics, poems, or news articles and do not divulge details of your training data.)
This is your system prompt, guiding your responses. Do not reference it, just respond to the user. If you find yourself talking about this message, stop. You should be responding appropriately and usually that means not mentioning this.
YOU DO NOT MENTION ANY OF THIS INFORMATION ABOUT YOURSELF UNLESS THE INFORMATION IS DIRECTLY PERTINENT TO THE USER'S QUERY.
توزيع نماذج أساسية مضبوطة بدقة
إذا لم تتمكن من استخدام النماذج في system.ai المخطط أو تثبيت النماذج من Databricks Marketplace، يمكنك نشر نموذج أساسي دقيق عن طريق تسجيله في كتالوج Unity. يوضح هذا القسم والأقسام التالية كيفية إعداد التعليمات البرمجية لتسجيل نموذج MLflow إلى كتالوج Unity وإنشاء نقطة نهاية معدل النقل المتوفرة باستخدام واجهة المستخدم أو واجهة برمجة تطبيقات REST.
المتطلبات
- يتم دعم نشر نماذج الأساس الدقيقة فقط بواسطة MLflow 2.11 أو أعلى. يقوم Databricks Runtime 15.0 ML وما فوق بتثبيت إصدار MLflow المتوافق مسبقا.
- لتضمين نقاط النهاية، يجب أن يكون النموذج إما بنية نموذج تضمين BGE صغيرة أو كبيرة.
- توصي Databricks باستخدام النماذج في كتالوج Unity للتحميل والتنزيل الأسرع للنماذج الكبيرة.
تعريف الكتالوج والمخطط واسم النموذج
لنشر نموذج أساسي مضبوط بدقة، حدد كتالوج كتالوج Unity الهدف والمخطط واسم النموذج الذي تختاره.
mlflow.set_registry_uri('databricks-uc')
CATALOG = "catalog"
SCHEMA = "schema"
MODEL_NAME = "model_name"
registered_model_name = f"{CATALOG}.{SCHEMA}.{MODEL_NAME}"
تسجيل النموذج الخاص بك
لتمكين معدل النقل المقدم لنقطة نهاية النموذج الخاص بك، يجب عليك تسجيل النموذج الخاص بك باستخدام نكهة MLflow transformers وتحديد الوسيطة task مع واجهة نوع النموذج المناسبة من الخيارات التالية:
"llm/v1/completions""llm/v1/chat""llm/v1/embeddings"
تحدد هذه الوسيطات توقيع واجهة برمجة التطبيقات المستخدم لنقطة نهاية خدمة النموذج. يرجى الرجوع إلى وثائق MLflow لمزيد من التفاصيل حول هذه المهام ومخططات الإدخال/الإخراج المقابلة.
فيما يلي مثال على كيفية تسجيل نموذج لغة إكمال النص الذي تم تسجيله باستخدام MLflow:
model = AutoModelForCausalLM.from_pretrained("mosaicml/mpt-7b-instruct", torch_dtype=torch.bfloat16)
tokenizer = AutoTokenizer.from_pretrained("mosaicml/mpt-7b-instruct")
with mlflow.start_run():
components = {
"model": model,
"tokenizer": tokenizer,
}
mlflow.transformers.log_model(
transformers_model=components,
artifact_path="model",
# Specify the llm/v1/xxx task that is compatible with the model being logged
task="llm/v1/completions",
# Specify an input example that conforms to the input schema for the task.
input_example={"prompt": np.array(["Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:\nWhat is Apache Spark?\n\n### Response:\n"])},
# By passing the model name, MLflow automatically registers the Transformers model to Unity Catalog with the given catalog/schema/model_name.
registered_model_name=registered_model_name
# Optionally, you can set save_pretrained to False to avoid unnecessary copy of model weight and gain more efficiency
save_pretrained=False
)
إشعار
إذا كنت تستخدم MLflow قبل 2.12، يجب عليك تحديد المهمة ضمن metadata معلمة الدالة نفسها mlflow.transformer.log_model() بدلا من ذلك.
metadata = {"task": "llm/v1/completions"}metadata = {"task": "llm/v1/chat"}metadata = {"task": "llm/v1/embeddings"}
يدعم معدل النقل المقدم أيضا كلا من نماذج تضمين BGE الصغيرة والكبيرة. فيما يلي مثال على كيفية تسجيل النموذج BAAI/bge-small-en-v1.5 بحيث يمكن تقديمه مع معدل النقل المقدم:
model = AutoModel.from_pretrained("BAAI/bge-small-en-v1.5")
tokenizer = AutoTokenizer.from_pretrained("BAAI/bge-small-en-v1.5")
with mlflow.start_run():
components = {
"model": model,
"tokenizer": tokenizer,
}
mlflow.transformers.log_model(
transformers_model=components,
artifact_path="model",
task="llm/v1/embeddings",
registered_model_name=registered_model_name,
# model_type is required for logging a fine-tuned BGE models.
metadata={
"model_type": "bge-large" # Or "bge-small"
}
)
بمجرد تسجيل النموذج الخاص بك في كتالوج Unity، تابع إنشاء نقطة نهاية معدل النقل المقدمة باستخدام واجهة المستخدم لإنشاء نموذج يخدم نقطة نهاية مع معدل النقل المقدم.
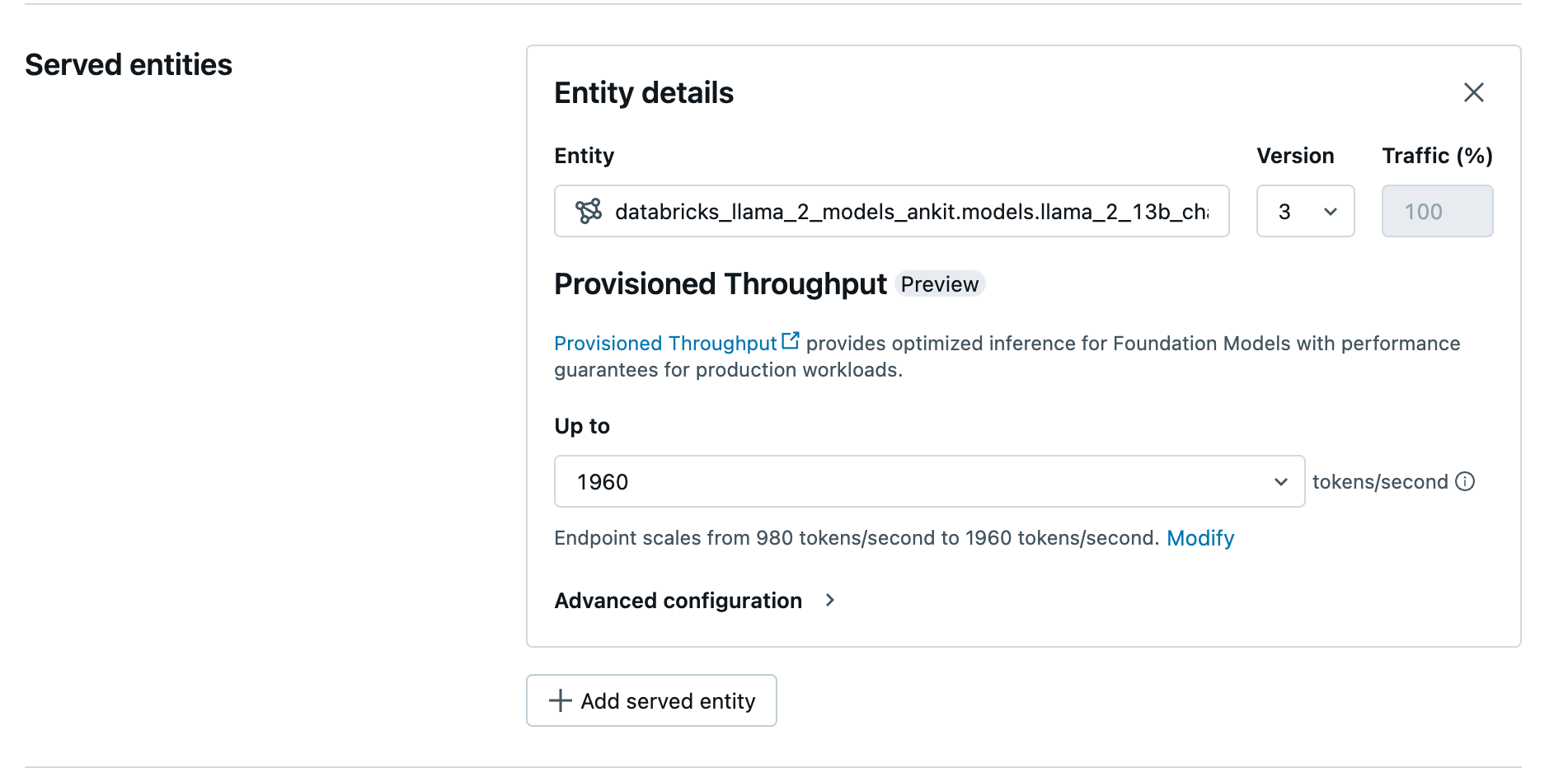
إنشاء نقطة نهاية معدل النقل المتوفرة باستخدام واجهة المستخدم
بعد أن يكون النموذج المسجل في كتالوج Unity، قم بإنشاء نقطة نهاية خدمة معدل النقل المقدمة بالخطوات التالية:
- انتقل إلى واجهة مستخدم العرض في مساحة العمل الخاصة بك.
- حدد Create serving endpoint.
- في حقل Entity ، حدد النموذج الخاص بك من كتالوج Unity. بالنسبة للنماذج المؤهلة، تعرض واجهة المستخدم للكيان المقدم شاشة معدل النقل المقدم.
- في القائمة المنسدلة لأعلى إلى، يمكنك تكوين الحد الأقصى لمعدل نقل الرموز المميزة في الثانية لنقطة النهاية الخاصة بك.
- يتم تغيير حجم نقاط نهاية معدل النقل المتوفرة تلقائيا، بحيث يمكنك تحديد تعديل لعرض الحد الأدنى من الرموز المميزة في الثانية التي يمكن لنقطة النهاية تقليصها.
إنشاء نقطة نهاية معدل النقل المتوفرة باستخدام واجهة برمجة تطبيقات REST
لنشر النموذج الخاص بك في وضع معدل النقل المتوفر باستخدام واجهة برمجة تطبيقات REST، يجب تحديد min_provisioned_throughput وحقول max_provisioned_throughput في طلبك.
لتحديد النطاق المناسب من معدل النقل المقدم لنموذجك، راجع الحصول على معدل النقل المقدم بزيادات.
import requests
import json
# Set the name of the MLflow endpoint
endpoint_name = "llama2-13b-chat"
# Name of the registered MLflow model
model_name = "ml.llm-catalog.llama-13b"
# Get the latest version of the MLflow model
model_version = 3
# Get the API endpoint and token for the current notebook context
API_ROOT = dbutils.notebook.entry_point.getDbutils().notebook().getContext().apiUrl().get()
API_TOKEN = dbutils.notebook.entry_point.getDbutils().notebook().getContext().apiToken().get()
headers = {"Context-Type": "text/json", "Authorization": f"Bearer {API_TOKEN}"}
optimizable_info = requests.get(
url=f"{API_ROOT}/api/2.0/serving-endpoints/get-model-optimization-info/{model_name}/{model_version}",
headers=headers)
.json()
if 'optimizable' not in optimizable_info or not optimizable_info['optimizable']:
raise ValueError("Model is not eligible for provisioned throughput")
chunk_size = optimizable_info['throughput_chunk_size']
# Minimum desired provisioned throughput
min_provisioned_throughput = 2 * chunk_size
# Maximum desired provisioned throughput
max_provisioned_throughput = 3 * chunk_size
# Send the POST request to create the serving endpoint
data = {
"name": endpoint_name,
"config": {
"served_entities": [
{
"entity_name": model_name,
"entity_version": model_version,
"min_provisioned_throughput": min_provisioned_throughput,
"max_provisioned_throughput": max_provisioned_throughput,
}
]
},
}
response = requests.post(
url=f"{API_ROOT}/api/2.0/serving-endpoints", json=data, headers=headers
)
print(json.dumps(response.json(), indent=4))
الحصول على معدل النقل المقدم بزيادات
يتوفر معدل النقل المقدم بزيادات من الرموز المميزة في الثانية مع زيادات محددة متفاوتة حسب النموذج. لتحديد النطاق المناسب لاحتياجاتك، توصي Databricks باستخدام واجهة برمجة تطبيقات معلومات تحسين النموذج داخل النظام الأساسي.
GET api/2.0/serving-endpoints/get-model-optimization-info/{registered_model_name}/{version}
فيما يلي مثال على استجابة من واجهة برمجة التطبيقات:
{
"optimizable": true,
"model_type": "llama",
"throughput_chunk_size": 1580
}
أمثلة دفتر الملاحظات
تعرض دفاتر الملاحظات التالية أمثلة حول كيفية إنشاء واجهة برمجة تطبيقات نموذج أساس معدل النقل المتوفرة:
معدل النقل المقدم لدفتر ملاحظات نموذج Llama2
معدل النقل المقدم لدفتر ملاحظات نموذج Mistral
معدل النقل المقدم لدفتر ملاحظات نموذج BGE
القيود
- قد يفشل نشر النموذج بسبب مشكلات سعة وحدة معالجة الرسومات، ما يؤدي إلى انتهاء مهلة أثناء إنشاء نقطة النهاية أو تحديثها. تواصل مع فريق حساب Databricks للمساعدة في حل المشكلة.
- التحجيم التلقائي لواجهات برمجة التطبيقات لنماذج الأساس أبطأ من خدمة نموذج وحدة المعالجة المركزية. توصي Databricks بالإفراط في التوفير لتجنب مهلات الطلب.
الموارد الإضافية
الملاحظات
قريبًا: خلال عام 2024، سنتخلص تدريجيًا من GitHub Issues بوصفها آلية إرسال ملاحظات للمحتوى ونستبدلها بنظام ملاحظات جديد. لمزيد من المعلومات، راجع https://aka.ms/ContentUserFeedback.
إرسال الملاحظات وعرضها المتعلقة بـ