إشعار
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
تتضمن هذه المقالة مثالين لنماذج التوصية المستندة إلى التعلم العميق على Azure Databricks. بالمقارنة مع نماذج التوصية التقليدية، يمكن لنماذج التعلم العميق تحقيق نتائج ذات جودة أعلى وتوسيع نطاقها إلى كميات أكبر من البيانات. مع استمرار تطور هذه النماذج، توفر Databricks إطار عمل للتدريب الفعال لنماذج التوصية واسعة النطاق القادرة على التعامل مع مئات الملايين من المستخدمين.
يمكن عرض نظام التوصية العام على أنه قمع مع المراحل الموضحة في الرسم التخطيطي.
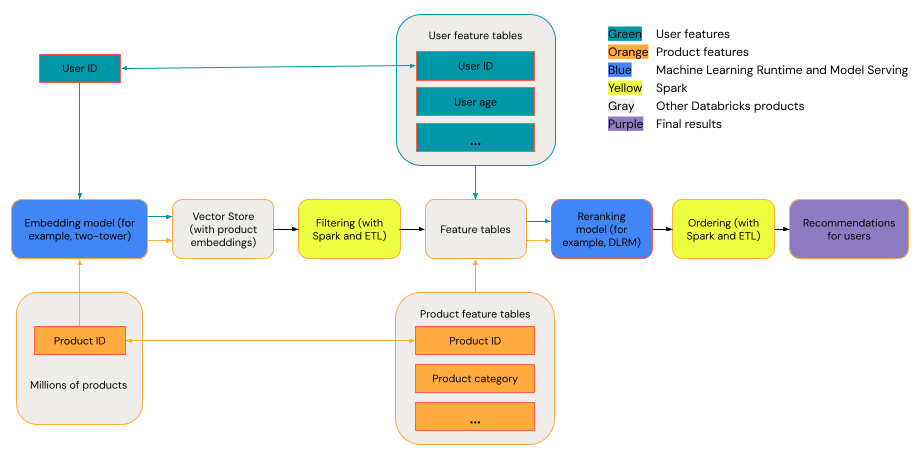
تعمل بعض النماذج، مثل نموذج البرجين، بشكل أفضل كنماذج استرداد. هذه النماذج أصغر ويمكن أن تعمل بشكل فعال على ملايين نقاط البيانات. تعمل النماذج الأخرى، مثل DLRM أو DeepFM، بشكل أفضل مع إعادة تعيين النماذج. يمكن أن تأخذ هذه النماذج المزيد من البيانات، وهي أكبر، ويمكن أن توفر توصيات دقيقة.
المتطلبات
Databricks Runtime 14.3 LTS ML
الأدوات
توضح الأمثلة الواردة في هذه المقالة الأدوات التالية:
- TorchDistributor: TorchDistributor هو إطار عمل يسمح لك بتشغيل تدريب نموذج PyTorch على نطاق واسع على Databricks. يستخدم Spark للتنسيق ويمكنه التوسع إلى عدد وحدات معالجة الرسومات المتوفرة في مجموعتك.
- مجموعة بيانات دفق الفسيفساء: تعمل StreamingDataset على تحسين الأداء وقابلية التوسع للتدريب على مجموعات البيانات الكبيرة على Databricks باستخدام ميزات مثل الإحضار المسبق والتداخل.
- MLflow: يسمح لك Mlflow بتعقب المعلمات والمقاييس ونقاط التحقق النموذجية.
- TorchRec: تستخدم أنظمة التوصية الحديثة تضمين جداول البحث للتعامل مع ملايين المستخدمين والعناصر لإنشاء توصيات عالية الجودة. تعمل أحجام التضمين الأكبر على تحسين أداء النموذج ولكنها تتطلب ذاكرة GPU كبيرة وإعدادات متعددة وحدات معالجة الرسومات. يوفر TorchRec إطار عمل لتوسيع نطاق نماذج التوصية وجداول البحث عبر وحدات معالجة الرسومات المتعددة، ما يجعلها مثالية للتضمينات الكبيرة.
مثال: توصيات الأفلام باستخدام تصميم نموذج من برجين
تم تصميم النموذج المكون من برجين للتعامل مع مهام التخصيص واسعة النطاق من خلال معالجة بيانات المستخدم والعنصر بشكل منفصل قبل دمجها. وهي قادرة على توليد بكفاءة مئات أو الآلاف من توصيات الجودة اللائقة. يتوقع النموذج بشكل عام ثلاثة مدخلات: ميزة user_id، وميزة product_id، وتسمية ثنائية تحدد ما إذا كان <المستخدم، تفاعل المنتج> إيجابيا (اشترى المستخدم المنتج) أو سالبا (منح المستخدم المنتج تصنيفا نجميا واحدا). مخرجات النموذج هي تضمينات لكل من المستخدمين والعناصر، والتي يتم دمجها بعد ذلك بشكل عام (غالبا باستخدام منتج نقطة أو تشابه تمام التمام) للتنبؤ بتفاعلات عنصر المستخدم.
نظرا لأن النموذج المكون من برجين يوفر تضمينات لكل من المستخدمين والمنتجات، يمكنك وضع هذه التضمينات في قاعدة بيانات متجهة، مثل Databricks Vector Store، وإجراء عمليات مشابهة للبحث عن التشابه على المستخدمين والعناصر. على سبيل المثال، يمكنك وضع جميع العناصر في مخزن متجهات، ولكل مستخدم، استعلم عن مخزن المتجهات للعثور على أفضل مائة عنصر تتشابه تضميناته مع عناصر المستخدم.
يقوم دفتر الملاحظات المثال التالي بتنفيذ تدريب النموذج المكون من برجين باستخدام مجموعة بيانات "التعلم من مجموعات العناصر" للتنبؤ باحتمال أن يقوم المستخدم بتقييم فيلم معين بدرجة عالية. ويستخدم Mosaic StreamingDataset لتحميل البيانات الموزعة، TorchDistributor لتدريب النموذج الموزع، وMlflow لتتبع النموذج وتسجيله.
دفتر الملاحظات النموذجي للموصي ذو البرجين
يتوفر دفتر الملاحظات هذا أيضا في Databricks Marketplace: دفتر الملاحظات النموذجي ذو البرجين
إشعار
- غالبا ما تكون المدخلات لنموذج البرجين هي الميزات الفئوية user_id product_id. يمكن تعديل النموذج لدعم ناقلات ميزات متعددة لكل من المستخدمين والمنتجات.
- عادة ما تكون مخرجات نموذج البرجين قيما ثنائية تشير إلى ما إذا كان المستخدم سيكون له تفاعل إيجابي أو سلبي مع المنتج. يمكن تعديل النموذج للتطبيقات الأخرى مثل الانحدار والتصنيف متعدد الفئات والاحتمالات لإجراءات مستخدم متعددة (على سبيل المثال، تجاهل أو شراء). وينبغي تنفيذ المخرجات المعقدة بعناية، حيث يمكن للأهداف المتنافسة أن تقلل من جودة عمليات التضمين التي ينشئها النموذج.
مثال: تدريب بنية DLRM باستخدام مجموعة بيانات اصطناعية
DLRM هي بنية شبكة عصبية حديثة مصممة خصيصا لنظم التخصيص والتوصية. فهو يجمع بين المدخلات الفئوية والرقمية لنمذجة تفاعلات عنصر المستخدم بشكل فعال والتنبؤ بتفضيلات المستخدم. تتوقع DLRMs بشكل عام إدخالات تتضمن ميزات متفرقة (مثل معرف المستخدم أو معرف العنصر أو الموقع الجغرافي أو فئة المنتج) والميزات الكثيفة (مثل عمر المستخدم أو سعر العنصر). عادة ما يكون ناتج DLRM تنبؤا بتفاعل المستخدم، مثل معدلات النقر أو احتمال الشراء.
توفر DLRMs إطار عمل قابل للتخصيص بدرجة كبيرة يمكنه التعامل مع البيانات واسعة النطاق، ما يجعلها مناسبة لمهام التوصية المعقدة عبر مختلف المجالات. نظرا لأنه نموذج أكبر من تصميم البرجين، غالبا ما يستخدم هذا النموذج في مرحلة إعادة النسخ.
ينشئ دفتر الملاحظات المثال التالي نموذج DLRM للتنبؤ بالتسميات الثنائية باستخدام ميزات كثيفة (رقمية) وميزات متفرقة (فئوية). ويستخدم مجموعة بيانات اصطناعية لتدريب النموذج، وSysysy StreamingDataset لتحميل البيانات الموزعة، TorchDistributor لتدريب النموذج الموزع، وMlflow لتتبع النموذج وتسجيله.
دفتر ملاحظات DLRM
يتوفر دفتر الملاحظات هذا أيضا في دفتر ملاحظات Databricks Marketplace: DLRM.
مقارنة بين طرازي البرجين وDLRM
يعرض الجدول بعض الإرشادات لتحديد نموذج التوصية الذي يجب استخدامه.
| نوع النموذج | حجم مجموعة البيانات المطلوبة للتدريب | حجم النموذج | أنواع الإدخال المدعومة | أنواع المخرجات المدعومة | حالات الاستخدام |
|---|---|---|---|---|---|
| برجان | أصغر | أصغر | عادة ما تكون هناك ميزتان (user_id، product_id) | إنشاء التصنيف والتضمين الثنائي بشكل رئيسي | إنشاء مئات أو آلاف التوصيات المحتملة |
| DLRM | أكبر | أكبر | ميزات مختلفة فئوية وكثيفة (user_id، ونوع الجنس، geographic_location، product_id، product_category، ...) | التصنيف متعدد الفئات والانحدار وغيرها | استرداد دقيق (التوصية بعشرات العناصر ذات الصلة للغاية) |
باختصار، يتم استخدام نموذج البرجين بشكل أفضل لتوليد الآلاف من التوصيات ذات الجودة الجيدة بكفاءة كبيرة. قد يكون أحد الأمثلة على ذلك توصيات الأفلام من موفر الكبل. يتم استخدام نموذج DLRM بشكل أفضل لإنشاء توصيات محددة جدا استنادا إلى المزيد من البيانات. قد يكون أحد الأمثلة على ذلك بائع التجزئة الذي يريد تقديم عدد أقل من العناصر التي من المرجح أن يشتريها العميل إلى العميل.