تشغيل مشاريع MLflow على Azure Databricks
مشروع MLflow هو تنسيق لتغليف تعليمة علم البيانات البرمجية بطريقة قابلة لإعادة الاستخدام وقابلة للتكرار. يتضمن مكون MLflow Projects واجهة برمجة التطبيقات وأدوات سطر الأوامر لتشغيل المشاريع، والتي تتكامل أيضا مع مكون التعقب لتسجيل المعلمات وتثبيت git للتعليمات البرمجية المصدر تلقائيا للتكرار.
توضح هذه المقالة تنسيق مشروع MLflow وكيفية تشغيل مشروع MLflow عن بعد على مجموعات Azure Databricks باستخدام MLflow CLI، ما يجعل من السهل تغيير حجم التعليمات البرمجية لعلوم البيانات عموديا.
تنسيق مشروع MLflow
يمكن التعامل مع أي دليل محلي أو مستودع Git كمشروع MLflow. تحدد الاصطلاحات التالية مشروعا:
- اسم المشروع هو اسم الدليل.
- يتم تحديد بيئة البرنامج في
python_env.yaml، إذا كانت موجودة. إذا لم يكن هناكpython_env.yamlملف موجود، يستخدم MLflow بيئة virtualenv تحتوي على Python فقط (على وجه التحديد، أحدث Python متاح ل virtualenv) عند تشغيل المشروع. - يمكن أن يكون أي
.pyملف أو.shفي المشروع نقطة إدخال، مع عدم الإعلان عن أي معلمات بشكل صريح. عند تشغيل مثل هذا الأمر مع مجموعة من المعلمات، يمرر MLflow كل معلمة على سطر الأوامر باستخدام--key <value>بناء الجملة.
يمكنك تحديد المزيد من الخيارات عن طريق إضافة ملف MLproject، وهو ملف نصي في بناء جملة YAML. مثال على ملف MLproject يبدو كما يلي:
name: My Project
python_env: python_env.yaml
entry_points:
main:
parameters:
data_file: path
regularization: {type: float, default: 0.1}
command: "python train.py -r {regularization} {data_file}"
validate:
parameters:
data_file: path
command: "python validate.py {data_file}"
تشغيل مشروع MLflow
لتشغيل مشروع MLflow على مجموعة Azure Databricks في مساحة العمل الافتراضية، استخدم الأمر :
mlflow run <uri> -b databricks --backend-config <json-new-cluster-spec>
حيث <uri> هو URI مستودع Git أو مجلد يحتوي على مشروع MLflow وهو <json-new-cluster-spec> مستند JSON يحتوي على بنية new_cluster. يجب أن يكون Git URI بالشكل: https://github.com/<repo>#<project-folder>.
مثال على مواصفات نظام المجموعة هو:
{
"spark_version": "7.3.x-scala2.12",
"num_workers": 1,
"node_type_id": "Standard_DS3_v2"
}
إذا كنت بحاجة إلى تثبيت المكتبات على العامل، فاستخدم تنسيق "مواصفات نظام المجموعة". لاحظ أنه يجب تحميل ملفات عجلة Python إلى DBFS وتحديدها كتبعيات pypi . على سبيل المثال:
{
"new_cluster": {
"spark_version": "7.3.x-scala2.12",
"num_workers": 1,
"node_type_id": "Standard_DS3_v2"
},
"libraries": [
{
"pypi": {
"package": "tensorflow"
}
},
{
"pypi": {
"package": "/dbfs/path_to_my_lib.whl"
}
}
]
}
هام
.eggوالتبعيات.jarغير مدعومة لمشاريع MLflow.- تنفيذ مشاريع MLflow مع بيئات Docker غير مدعوم.
- يجب استخدام مواصفات نظام مجموعة جديدة عند تشغيل مشروع MLflow على Databricks. تشغيل المشاريع مقابل المجموعات الموجودة غير مدعوم.
استخدام SparkR
لاستخدام SparkR في تشغيل مشروع MLflow، يجب أولا تثبيت التعليمات البرمجية للمشروع واستيراد SparkR كما يلي:
if (file.exists("/databricks/spark/R/pkg")) {
install.packages("/databricks/spark/R/pkg", repos = NULL)
} else {
install.packages("SparkR")
}
library(SparkR)
يمكن لمشروعك بعد ذلك تهيئة جلسة SparkR واستخدام SparkR كالمعتاد:
sparkR.session()
...
المثال
يوضح هذا المثال كيفية إنشاء تجربة، وتشغيل مشروع البرنامج التعليمي MLflow على مجموعة Azure Databricks، وعرض إخراج تشغيل المهمة، وعرض التشغيل في التجربة.
المتطلبات
- تثبيت MLflow باستخدام
pip install mlflow. - تثبيت وتكوين Databricks CLI. مطلوب آلية مصادقة Databricks CLI لتشغيل المهام على نظام مجموعة Azure Databricks.
الخطوة 1: إنشاء تجربة
في مساحة العمل، حدد Create > MLflow Experiment.
في حقل الاسم، أدخل
Tutorial.انقر فوق Create. لاحظ معرف التجربة. في هذا المثال، هو
14622565.
الخطوة 2: تشغيل مشروع البرنامج التعليمي MLflow
تقوم الخطوات التالية بإعداد MLFLOW_TRACKING_URI متغير البيئة وتشغيل المشروع، وتسجيل معلمات التدريب والمقاييس والنموذج المدرب إلى التجربة المذكورة في الخطوة السابقة:
MLFLOW_TRACKING_URIتعيين متغير البيئة إلى مساحة عمل Azure Databricks.export MLFLOW_TRACKING_URI=databricksقم بتشغيل مشروع البرنامج التعليمي MLflow، وتدريب نموذج النبيذ. استبدل
<experiment-id>بمعرف التجربة الذي لاحظته في الخطوة السابقة.mlflow run https://github.com/mlflow/mlflow#examples/sklearn_elasticnet_wine -b databricks --backend-config cluster-spec.json --experiment-id <experiment-id>=== Fetching project from https://github.com/mlflow/mlflow#examples/sklearn_elasticnet_wine into /var/folders/kc/l20y4txd5w3_xrdhw6cnz1080000gp/T/tmpbct_5g8u === === Uploading project to DBFS path /dbfs/mlflow-experiments/<experiment-id>/projects-code/16e66ccbff0a4e22278e4d73ec733e2c9a33efbd1e6f70e3c7b47b8b5f1e4fa3.tar.gz === === Finished uploading project to /dbfs/mlflow-experiments/<experiment-id>/projects-code/16e66ccbff0a4e22278e4d73ec733e2c9a33efbd1e6f70e3c7b47b8b5f1e4fa3.tar.gz === === Running entry point main of project https://github.com/mlflow/mlflow#examples/sklearn_elasticnet_wine on Databricks === === Launched MLflow run as Databricks job run with ID 8651121. Getting run status page URL... === === Check the run's status at https://<databricks-instance>#job/<job-id>/run/1 ===انسخ عنوان URL
https://<databricks-instance>#job/<job-id>/run/1في السطر الأخير من إخراج تشغيل MLflow.
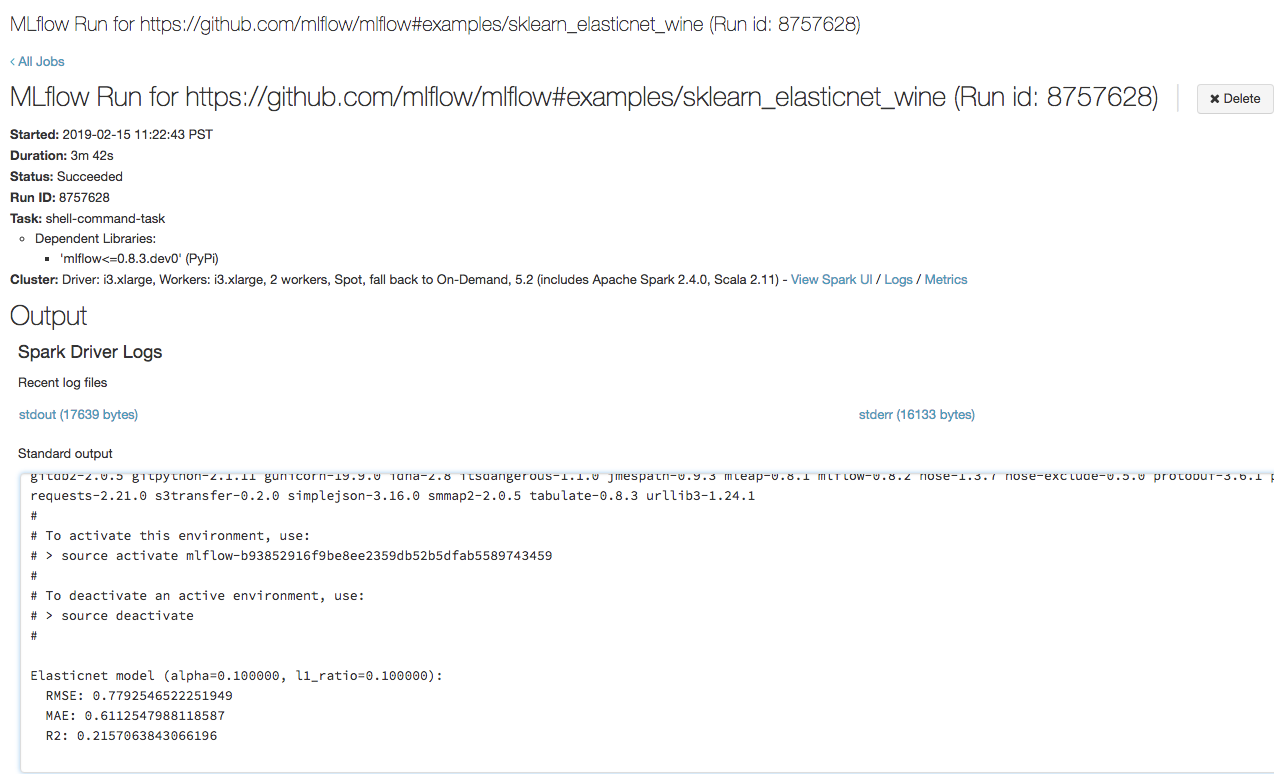
الخطوة 3: عرض تشغيل مهمة Azure Databricks
افتح عنوان URL الذي نسخته في الخطوة السابقة في مستعرض لعرض إخراج تشغيل مهمة Azure Databricks:
الخطوة 4: عرض تفاصيل تشغيل التجربة وMLflow
انتقل إلى التجربة في مساحة عمل Azure Databricks.
انقر فوق التجربة.
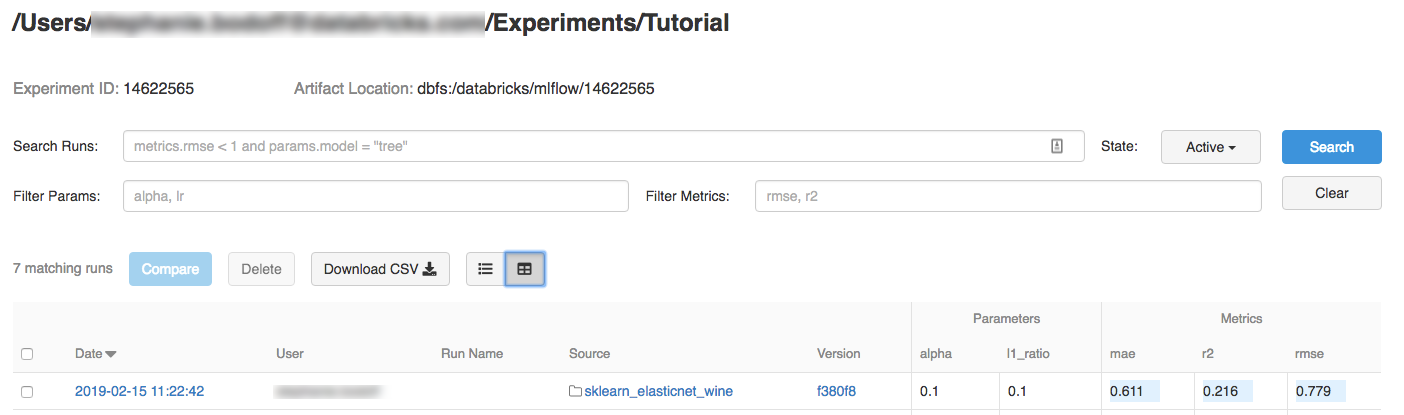
لعرض تفاصيل التشغيل، انقر فوق ارتباط في عمود التاريخ.
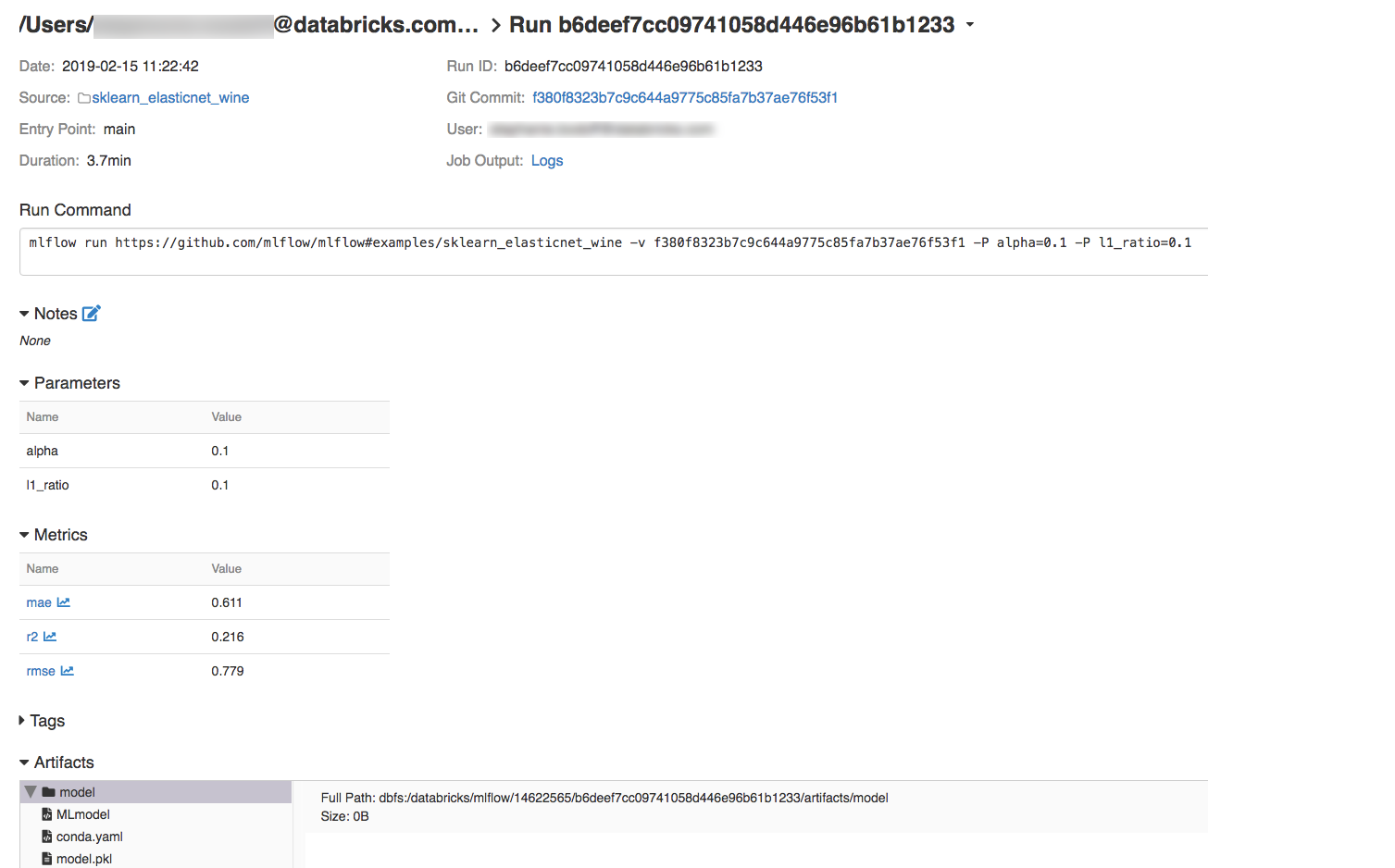
يمكنك عرض السجلات من التشغيل بالنقر فوق الارتباط Logs في حقل Job Output.
الموارد
للحصول على بعض الأمثلة على مشاريع MLflow، راجع مكتبة تطبيقات MLflow، التي تحتوي على مستودع للمشاريع الجاهزة للتشغيل التي تهدف إلى تسهيل تضمين وظائف التعلم الآلي في التعليمات البرمجية الخاصة بك.
الملاحظات
قريبًا: خلال عام 2024، سنتخلص تدريجيًا من GitHub Issues بوصفها آلية إرسال ملاحظات للمحتوى ونستبدلها بنظام ملاحظات جديد. لمزيد من المعلومات، راجع https://aka.ms/ContentUserFeedback.
إرسال الملاحظات وعرضها المتعلقة بـ