إشعار
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
تنفيذ الاستعلام التكيفي (AQE) هو إعادة تحسين الاستعلام الذي يحدث أثناء تنفيذ الاستعلام.
الدافع لإعادة تحسين وقت التشغيل هو أن Azure Databricks لديه أحدث الإحصائيات الدقيقة في نهاية تبادل التبديل والبث (يشار إليه باسم مرحلة الاستعلام في AQE). ونتيجة لذلك، يمكن ل Azure Databricks اختيار استراتيجية فعلية أفضل، أو اختيار حجم ورقم قسم ما بعد التبديل الأمثل، أو إجراء تحسينات كانت تتطلب تلميحات، على سبيل المثال، معالجة انحراف الانضمام.
يمكن أن يكون هذا مفيدا جدا عندما لا يتم تشغيل جمع الإحصائيات أو عندما تكون الإحصائيات قديمة. كما أنه مفيد في الأماكن التي تكون فيها الإحصائيات المشتقة بشكل ثابت غير دقيقة، مثل في منتصف استعلام معقد، أو بعد حدوث انحراف البيانات.
القدرات
يتم تمكين AQE بشكل افتراضي. يحتوي على 4 ميزات رئيسية:
- تغيير ربط دمج الفرز ديناميكيا إلى صلة تجزئة البث.
- دمج الأقسام ديناميكيا (دمج الأقسام الصغيرة في أقسام بحجم معقول) بعد تبديل التبادل. المهام الصغيرة جدا لديها معدل نقل الإدخال/إخراج أسوأ وتميل إلى المعاناة أكثر من جدولة النفقات العامة ونفقات إعداد المهمة. يؤدي الجمع بين المهام الصغيرة إلى حفظ الموارد وتحسين معدل نقل نظام المجموعة.
- يعالج الانحراف ديناميكيا في ربط دمج الفرز وربط تجزئة التبديل عن طريق تقسيم المهام (والنسخ المتماثل إذا لزم الأمر) إلى مهام متساوية الحجم تقريبا.
- يكتشف العلاقات الفارغة وينشرها ديناميكيا.
التطبيق
ينطبق AQE على جميع الاستعلامات التي هي:
- عدم الدفق
- تحتوي على تبادل واحد على الأقل (عادة عندما يكون هناك صلة أو تجميع أو نافذة) أو استعلام فرعي واحد أو كليهما.
لا تتم بالضرورة إعادة تحسين جميع الاستعلامات المطبقة على AQE. قد تأتي إعادة التحسين أو لا تأتي بخطة استعلام مختلفة عن تلك التي تم تجميعها بشكل ثابت. لتحديد ما إذا كان قد تم تغيير خطة استعلام بواسطة AQE، راجع القسم التالي، خطط الاستعلام.
خطط الاستعلام
يناقش هذا القسم كيفية فحص خطط الاستعلام بطرق مختلفة.
في هذا القسم:
Spark UI
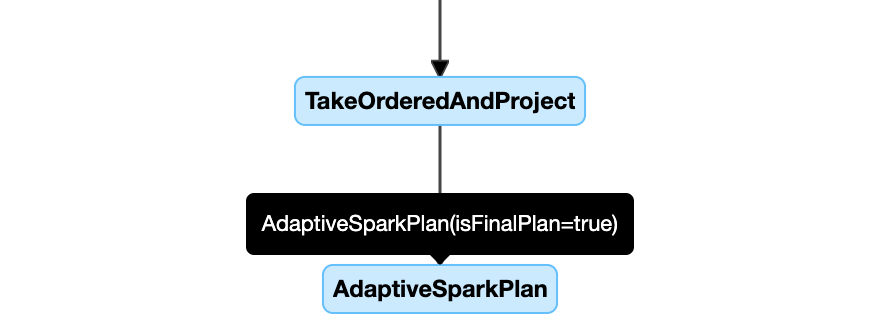
AdaptiveSparkPlan عقدة
تحتوي الاستعلامات المطبقة على AQE على عقدة واحدة أو أكثر AdaptiveSparkPlan ، عادة كعقدة جذر لكل استعلام رئيسي أو استعلام فرعي.
قبل تشغيل الاستعلام أو عند تشغيله، isFinalPlan تظهر علامة العقدة المقابلة AdaptiveSparkPlan ك false؛ بعد اكتمال تنفيذ الاستعلام، تتغير العلامة isFinalPlan إلى true.
خطة متطورة
يتطور الرسم التخطيطي لخطة الاستعلام مع تقدم التنفيذ ويعكس الخطة الأحدث التي يتم تنفيذها. لن تتغير العقد التي تم تنفيذها بالفعل (التي تتوفر فيها المقاييس)، ولكن العقد التي لم تتغير بمرور الوقت نتيجة لإعادة التحسين.
فيما يلي مثال على رسم تخطيطي لخطة الاستعلام:
DataFrame.explain()
AdaptiveSparkPlan عقدة
تحتوي الاستعلامات المطبقة على AQE على عقدة واحدة أو أكثر AdaptiveSparkPlan ، عادة كعقدة جذر لكل استعلام رئيسي أو استعلام فرعي. قبل تشغيل الاستعلام أو عند تشغيله، isFinalPlan تظهر علامة العقدة المقابلة AdaptiveSparkPlan ك false؛ بعد اكتمال تنفيذ الاستعلام، تتغير العلامة isFinalPlan إلى true.
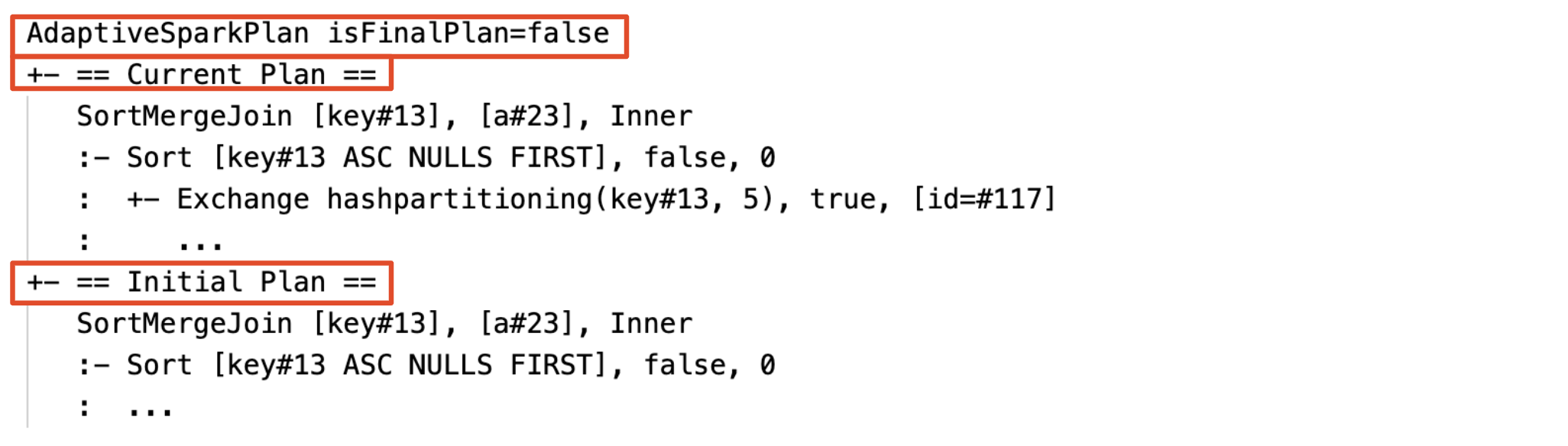
الخطة الحالية والاستهلالية
تحت كل AdaptiveSparkPlan عقدة سيكون هناك كل من الخطة الأولية (الخطة قبل تطبيق أي تحسينات AQE) والخطة الحالية أو النهائية، اعتمادا على ما إذا كان التنفيذ قد اكتمل. ستتطور الخطة الحالية مع تقدم التنفيذ.
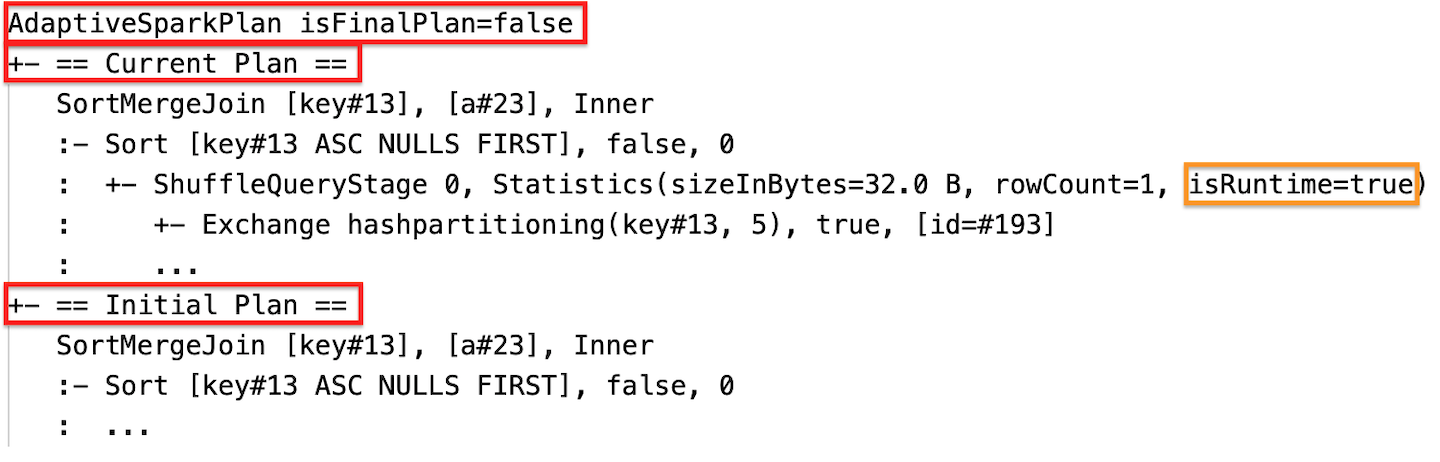
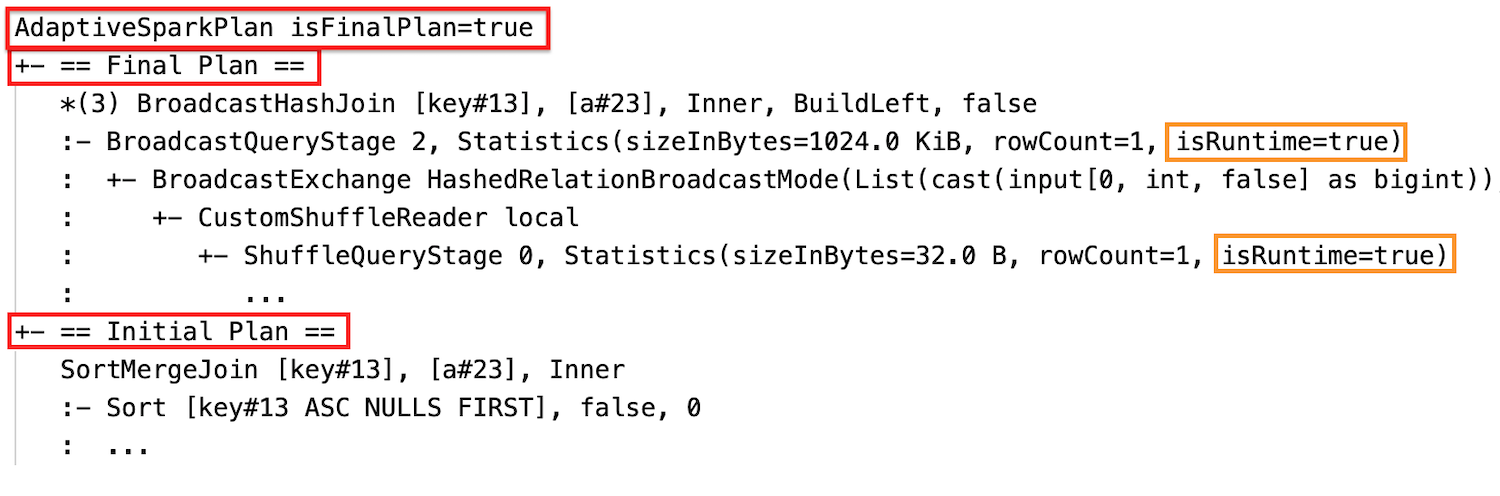
إحصائيات وقت التشغيل
تحتوي كل مرحلة تبديل وبث على إحصائيات البيانات.
قبل تشغيل المرحلة أو عند تشغيل المرحلة، تكون الإحصائيات تقديرات وقت التحويل البرمجي، والعلامة isRuntime هي false، على سبيل المثال: Statistics(sizeInBytes=1024.0 KiB, rowCount=4, isRuntime=false);
بعد اكتمال تنفيذ المرحلة، تكون الإحصائيات هي تلك التي تم جمعها في وقت التشغيل، وستصبح trueالعلامة isRuntime ، على سبيل المثال:Statistics(sizeInBytes=658.1 KiB, rowCount=2.81E+4, isRuntime=true)
فيما يلي مثال DataFrame.explain :
قبل التنفيذ
أثناء التنفيذ
بعد التنفيذ
SQL EXPLAIN
AdaptiveSparkPlan عقدة
تحتوي الاستعلامات المطبقة على AQE على عقدة AdaptiveSparkPlan واحدة أو أكثر، وعادة ما تكون العقدة الجذر لكل استعلام رئيسي أو استعلام فرعي.
لا توجد خطة حالية
نظرا لعدم SQL EXPLAIN تنفيذ الاستعلام، فإن الخطة الحالية هي دائما نفس الخطة الأولية ولا تعكس ما سيتم تنفيذه في نهاية المطاف بواسطة AQE.
فيما يلي مثال شرح SQL:

فعاليه
ستتغير خطة الاستعلام إذا تم تطبيق تحسين AQE واحد أو أكثر. يظهر تأثير تحسينات AQE هذه من خلال الفرق بين الخطط الحالية والنهائية والخطة الأولية وعقد الخطة المحددة في الخطط الحالية والنهائية.
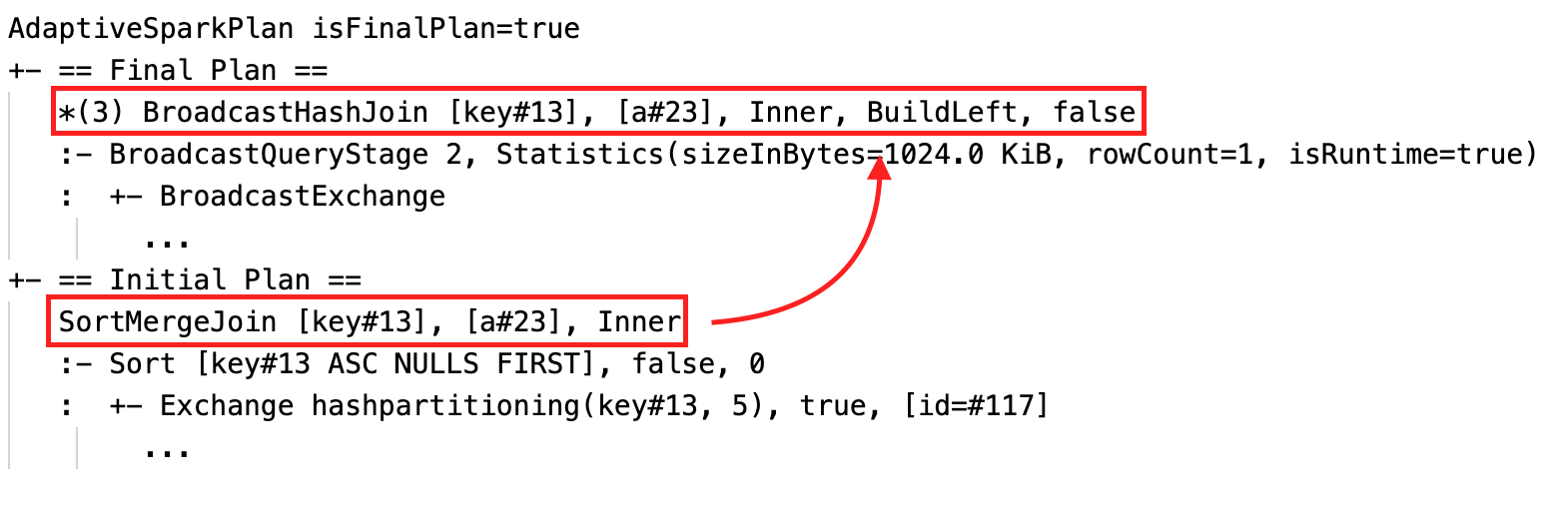
تغيير ربط دمج الفرز ديناميكيا في صلة تجزئة البث: عقد صلة فعلية مختلفة بين الخطة الحالية/النهائية والخطة الأولية
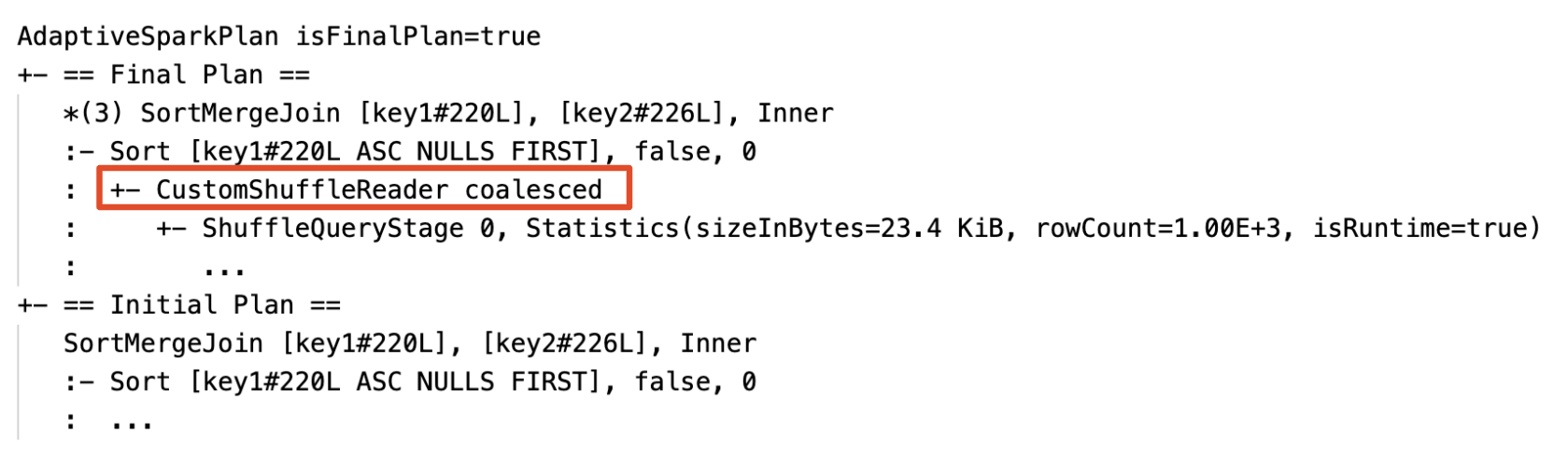
دمج الأقسام ديناميكيا: عقدة
CustomShuffleReaderمع خاصيةCoalesced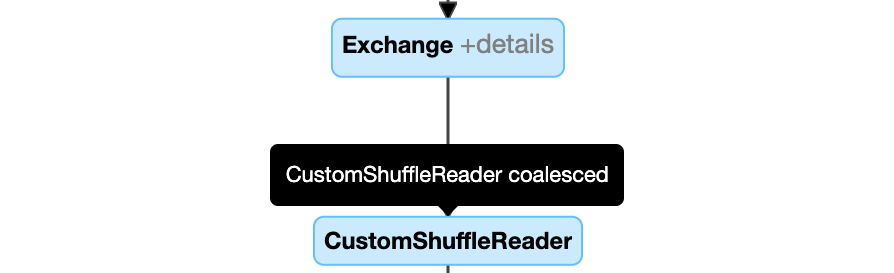
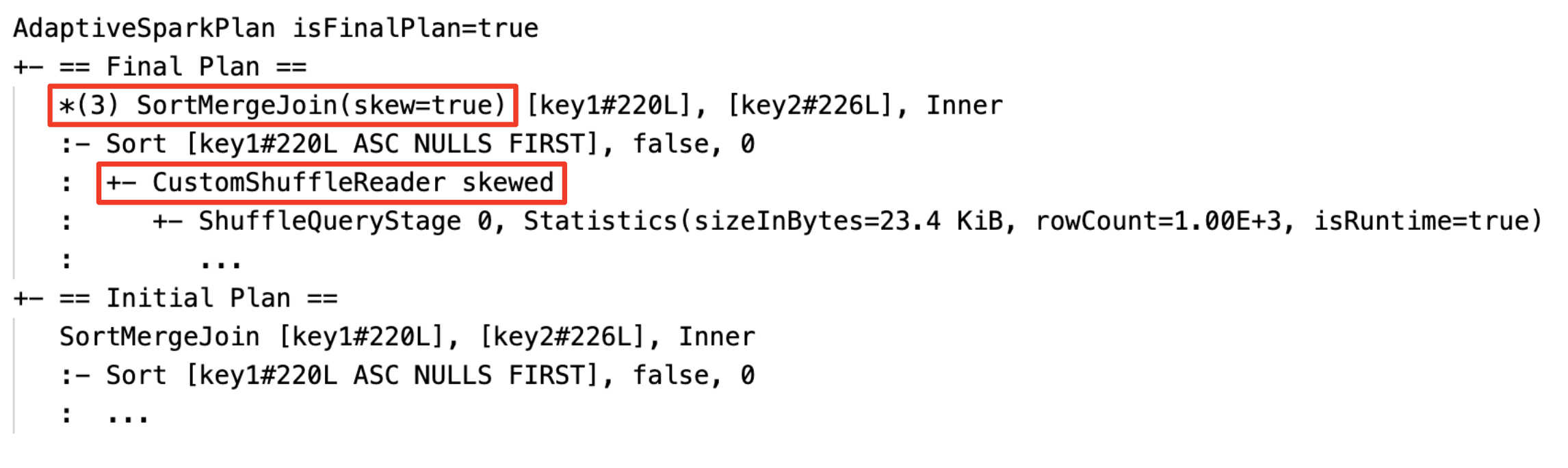
معالجة الصلة المنحرفة ديناميكيا: عقدة
SortMergeJoinمع حقلisSkewعلى أنه صحيح.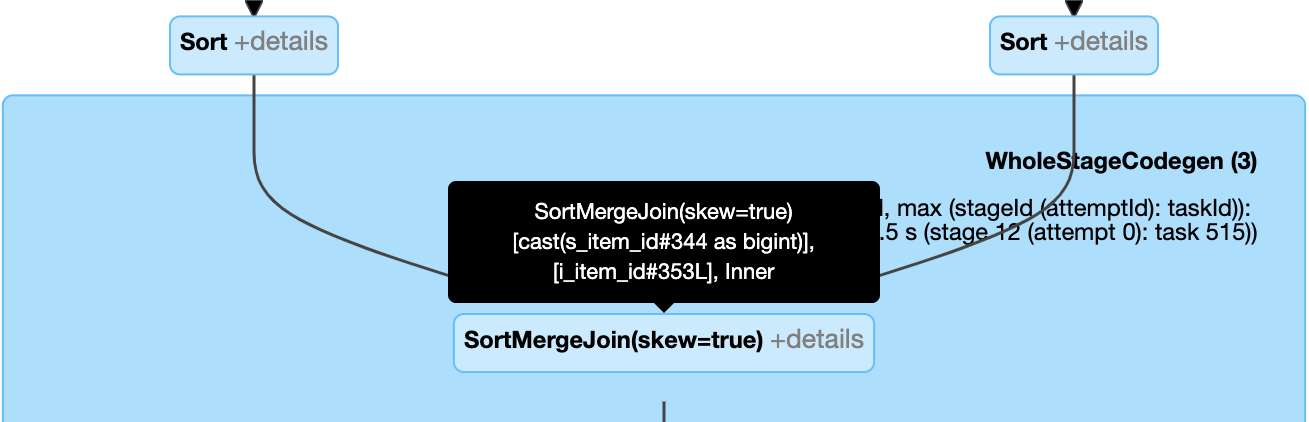
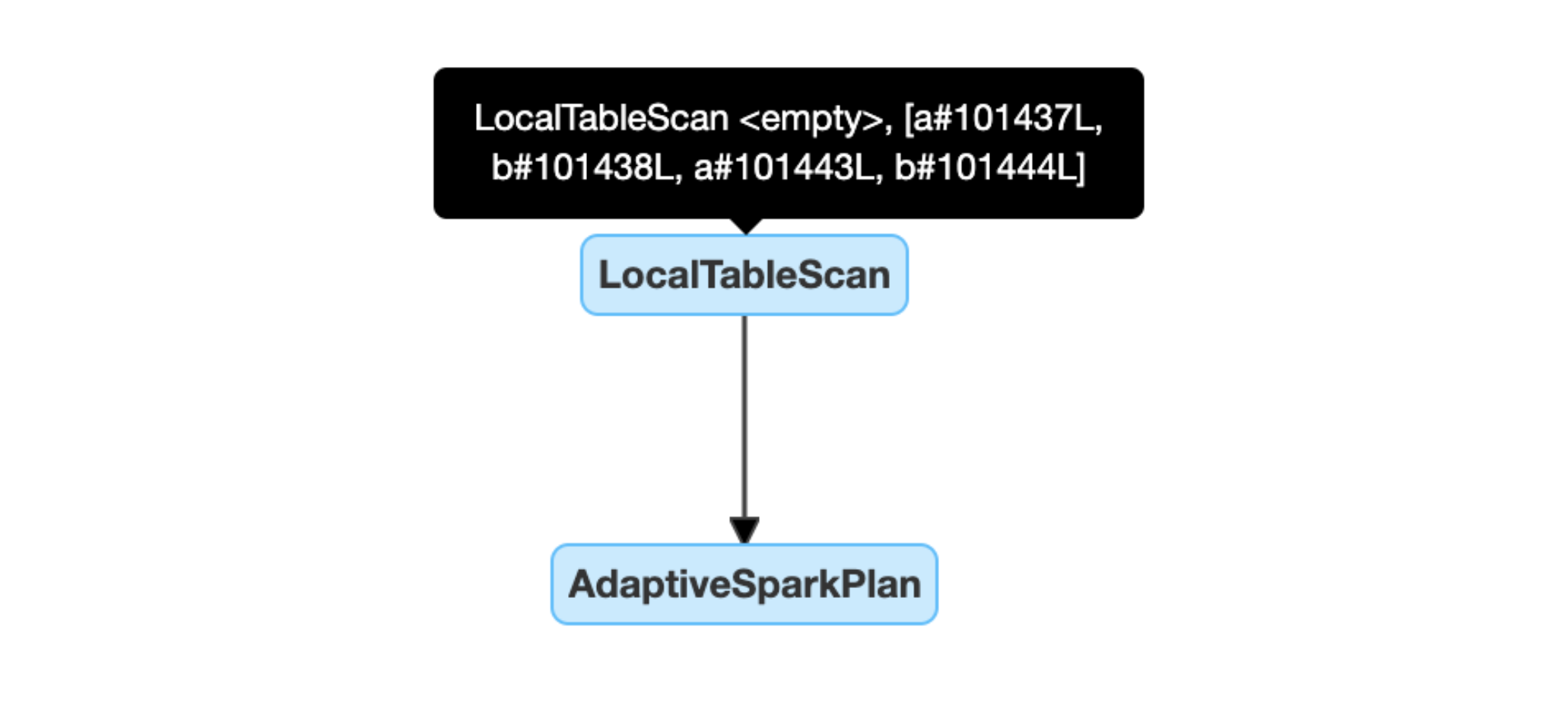
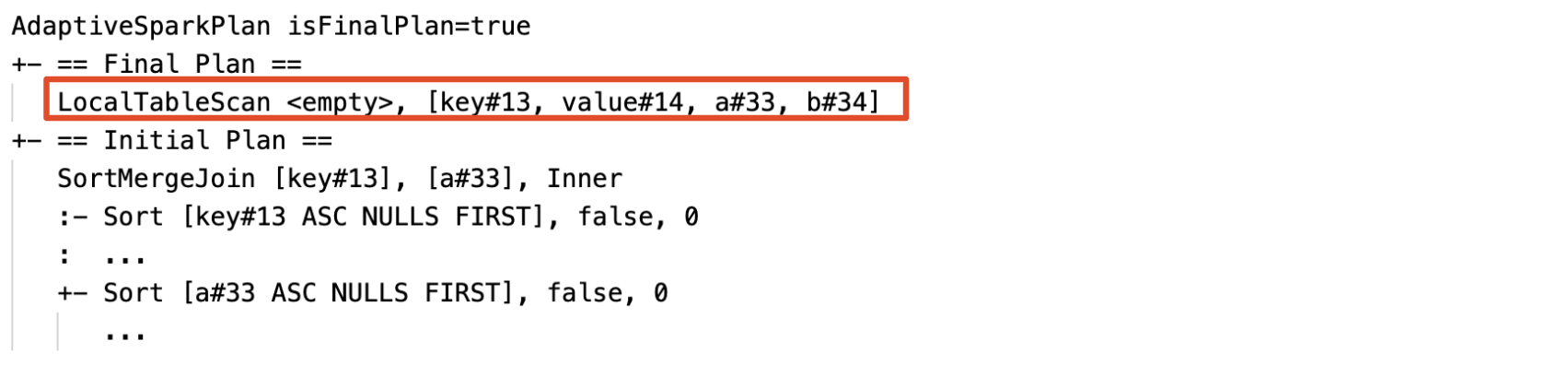
الكشف عن العلاقات الفارغة ونشرها ديناميكيا: يتم استبدال جزء من (أو كامل) الخطة بالعقدة LocalTableScan مع حقل العلاقة كفارغ.
التكوين
في هذا القسم:
- تمكين وتعطيل تنفيذ الاستعلام التكيفي
- تمكين التبديل العشوائي المحسن تلقائيا
- تغيير صلة دمج الفرز ديناميكيا إلى صلة تجزئة البث
- دمج الأقسام ديناميكيا
- معالجة الانضمام المنحرف ديناميكيا
- الكشف عن العلاقات الفارغة ونشرها ديناميكيا
تمكين وتعطيل تنفيذ الاستعلام التكيفي
| الخاصية |
|---|
| spark.databricks.optimizer.adaptive.enabled النوع: Booleanما إذا كنت تريد تمكين تنفيذ الاستعلام التكيفي أو تعطيله. قيمة افتراضية: true |
تمكين التبديل العشوائي المحسن تلقائيا
| الخاصية |
|---|
| spark.sql.shuffle.partitions النوع: Integerالعدد الافتراضي للأقسام التي يجب استخدامها عند تبديل البيانات للصلات أو التجميعات. يؤدي تعيين القيمة auto إلى تمكين التبديل العشوائي المحسن تلقائيا، والذي يحدد هذا الرقم تلقائيا استنادا إلى خطة الاستعلام وحجم بيانات إدخال الاستعلام.ملاحظة: بالنسبة إلى Structured Streaming، لا يمكن تغيير هذا التكوين بين إعادة تشغيل الاستعلام من نفس موقع نقطة التحقق. القيمة الافتراضية: 200 |
تغيير صلة دمج الفرز ديناميكيا إلى صلة تجزئة البث
| الخاصية |
|---|
| spark.databricks.adaptive.autoBroadcastJoinThreshold النوع: Byte Stringحد تشغيل التبديل إلى الانضمام إلى البث في وقت التشغيل. قيمة افتراضية: 30MB |
دمج الأقسام ديناميكيا
| الخاصية |
|---|
| spark.sql.adaptive.coalescePartitions.enabled النوع: Booleanما إذا كنت تريد تمكين دمج القسم أو تعطيله. قيمة افتراضية: true |
| spark.sql.adaptive.advisoryPartitionSizeInBytes النوع: Byte Stringالحجم المستهدف بعد الاندماج. ستكون أحجام الأقسام المدمجة قريبة من ولكن ليس أكبر من هذا الحجم المستهدف. قيمة افتراضية: 64MB |
| spark.sql.adaptive.coalescePartitions.minPartitionSize النوع: Byte Stringالحد الأدنى لحجم الأقسام بعد الاندماج. لن تكون أحجام الأقسام المدمجة أصغر من هذا الحجم. قيمة افتراضية: 1MB |
| spark.sql.adaptive.coalescePartitions.minPartitionNum النوع: Integerالحد الأدنى لعدد الأقسام بعد الاندماج. غير مستحسن، لأن الإعداد يتجاوز بشكل صريح spark.sql.adaptive.coalescePartitions.minPartitionSize.القيمة الافتراضية: 2x no. من مراكز نظام المجموعة |
معالجة الانضمام المنحرف ديناميكيا
| الخاصية |
|---|
| spark.sql.adaptive.skewJoin.enabled النوع: Booleanما إذا كنت تريد تمكين معالجة الانضمام المنحرف أو تعطيلها. قيمة افتراضية: true |
| spark.sql.adaptive.skewJoin.skewedPartitionFactor النوع: Integerعامل عند ضربه بحجم القسم الوسيط يساهم في تحديد ما إذا كان القسم منحرفا أم لا. قيمة افتراضية: 5 |
| spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes النوع: Byte Stringحد يساهم في تحديد ما إذا كان القسم منحرفا أم لا. قيمة افتراضية: 256MB |
يعتبر القسم منحرفا عندما يكون trueكل من (partition size > skewedPartitionFactor * median partition size) و (partition size > skewedPartitionThresholdInBytes) .
الكشف عن العلاقات الفارغة ونشرها ديناميكيا
| الخاصية |
|---|
| spark.databricks.adaptive.emptyRelationPropagation.enabled النوع: Booleanما إذا كنت تريد تمكين نشر العلاقة الفارغة الديناميكية أو تعطيلها. قيمة افتراضية: true |
الأسئلة الشائعة (FAQ)
في هذا القسم:
- لماذا لم تبث AQE جدول صلة صغير؟
- هل يجب علي الاستمرار في استخدام تلميح استراتيجية الانضمام إلى البث مع تمكين AQE؟
- ما الفرق بين تلميح الانضمام المنحرف وتحسين الانضمام إلى انحراف AQE؟ أي حزم تطوير برمجيات SDK ينبغي لي استخدامها؟
- لماذا لم يضبط AQE ترتيب الانضمام تلقائيا؟
- لماذا لم يكتشف AQE انحراف بياناتي؟
لماذا لم تبث AQE جدول صلة صغير؟
إذا كان حجم العلاقة المتوقع بثها يقع ضمن هذا الحد ولكنه لا يزال غير مبث:
- تحقق من نوع الصلة. البث غير معتمد لأنواع صلة معينة، على سبيل المثال، لا يمكن بث العلاقة اليسرى ل
LEFT OUTER JOIN. - قد يكون أيضا أن العلاقة تحتوي على الكثير من الأقسام الفارغة، وفي هذه الحالة يمكن أن تنتهي غالبية المهام بسرعة مع ربط دمج الفرز أو يمكن تحسينها مع معالجة انحراف الصلة. يتجنب AQE تغيير عمليات ربط دمج الفرز هذه لبث عمليات ربط التجزئة إذا كانت النسبة المئوية للأقسام غير الفارغة أقل من
spark.sql.adaptive.nonEmptyPartitionRatioForBroadcastJoin.
هل يجب علي الاستمرار في استخدام تلميح استراتيجية الانضمام إلى البث مع تمكين AQE؟
نعم. عادة ما يكون ربط البث المخطط له بشكل ثابت أكثر أداء من الصلة المخطط لها ديناميكيا بواسطة AQE حيث قد لا يتحول AQE إلى ربط البث حتى بعد إجراء التبديل العشوائي لكلا جانبي الصلة (في الوقت الذي يتم فيه الحصول على أحجام العلاقة الفعلية). لذلك يمكن أن يكون استخدام تلميح البث خيارا جيدا إذا كنت تعرف الاستعلام جيدا. سيحترم AQE تلميحات الاستعلام بنفس الطريقة التي يحترمها التحسين الثابت، ولكن لا يزال بإمكانه تطبيق تحسينات ديناميكية لا تتأثر بالتلميحات.
ما الفرق بين تلميح الانضمام المنحرف وتحسين الانضمام إلى انحراف AQE؟ أي حزم تطوير برمجيات SDK ينبغي لي استخدامها؟
من المستحسن الاعتماد على التعامل مع انحراف الانضمام إلى AQE بدلا من استخدام تلميح الانضمام المنحرف، لأن انضمام انحراف AQE تلقائي تماما وأداء أفضل بشكل عام من نظير التلميح.
لماذا لم يضبط AQE ترتيب الانضمام تلقائيا؟
إعادة ترتيب الصلة الديناميكية ليست جزءا من AQE.
لماذا لم يكتشف AQE انحراف بياناتي؟
هناك شرطان للحجم يجب استيفاءهما ل AQE للكشف عن قسم كقسم منحرف:
- حجم القسم أكبر من
spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes(الافتراضي 256 ميغابايت) - حجم القسم أكبر من الحجم الوسيط لكافة الأقسام مرات عامل
spark.sql.adaptive.skewJoin.skewedPartitionFactorالقسم المنحرف (الافتراضي 5)
بالإضافة إلى ذلك، يقتصر دعم التعامل مع الانحراف على أنواع معينة من الصلات، على سبيل المثال، في LEFT OUTER JOIN، يمكن تحسين الانحراف فقط على الجانب الأيسر.
قديم
يوجد مصطلح "التنفيذ التكيفي" منذ Spark 1.6، ولكن AQE الجديد في Spark 3.0 مختلف بشكل أساسي. من حيث الوظائف، يقوم Spark 1.6 فقط بجزء "دمج الأقسام ديناميكيا". من حيث البنية التقنية، يعد AQE الجديد إطارا للتخطيط الديناميكي وإعادة تخطيط الاستعلامات استنادا إلى إحصائيات وقت التشغيل، والتي تدعم مجموعة متنوعة من التحسينات مثل تلك التي وصفناها في هذه المقالة ويمكن توسيعها لتمكين المزيد من التحسينات المحتملة.